

KMP算法及模板
KMP算法及模板
1.字符串匹配问题
所谓字符串匹配问题就是指:给定一个父串S,有子串p,从父串中找到子串,返回子串在父串的起始位置。若找不到则返回-1。
2.解决上述问题的暴力匹配算法
首先,我们可以利用暴力匹配算法来解决此问题。过程如下:
1. 首先,指针i指向父串S的起始位置
2. 指针j指向子串p的起止位置。
3. 将两个指针指向的字符进行比较,如果匹配成功,则指针i和j继续下移。如果匹配失败,则退出子串比较,将指针i移到新的起点,继续比较。
4. 在匹配过程中,如果子串全部比较完成,那么就找到了子串在父串的起始位置。如果在匹配结束后,子串仍然没有比较完成,那么就代表子串并不存在于主串中,返回-1。
上述过程的代码如下:
for(int i=1;i<=n;i++){
bool flag = true;
for(int j=1;j<=m;j++){
if(S[i+j-1] != p[j]{
flag = false;
break;
})
}
}
3. KMP算法引入及思想
我们发现,上述算法的时间复杂度是很高的,O(nm)。因此,为了解决时间复杂度高的问题,我们引入了KMP算法。需要注意的是:应用了KMP算法,字符串匹配的时间复杂度就为O(n+m)。

我们以上图为例,来阐述一下KMP算法的匹配过程,及背后的思想。
在上图中:蓝色代表父串,红色代表模板串(子串)。在字符串的匹配过程中,我们假设子串和父串在绿色边界前都是匹配的(这意味着)子串和父串在绿色边界前相等。但是,在绿色边界的下一个位置就不相等了(在图中就代表绿色圈和红色圈)。
如果采用暴力匹配的话,那么子串往后移动一位,继续匹配即可。但是,从之前的时间复杂度分析中,我们可以发现这样做的时间复杂度太高了。那么,如何进行优化?
我们可以发现,在当前情况下,子串和父串在绿色边界前相等。我们能否利用这样的特性,使得可以尽量减少子串与父串的匹配次数。因此,这就是KMP算法的目的。
那么,上述的优化如何实现?

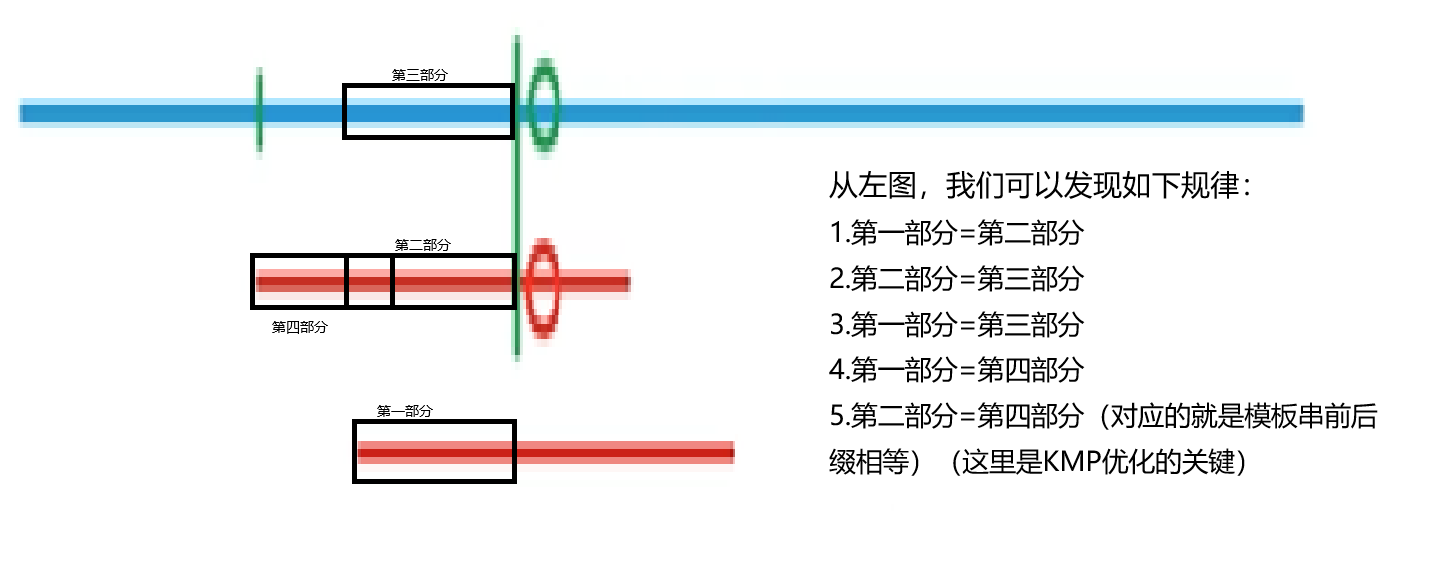
我们以上图为例,来阐述KMP算法优化的具体过程(思想)。
假设,当匹配失败后,我们让子串移动若干位置(移动到上图所示的位置)。使得:
1. 移动后的子串在绿色边界前的部分与移动前的子串当中与其相对应的部分相等。(对应上图的1和2)
2. 由于父串和移动前的子串在绿色边界前都是相等的。因此,移动后的子串在绿色边界前的部分也与父串当中于其相对应的部分相等。(对应上图中的1和3)
3. 根据上图,我们可以发现移动后的子串在绿色边界前的部分,刚好就是模板串的前缀部分(绿色边界前)。而根据上述的2,我们又可以发现它跟模板串的后缀部分也相等。(绿色边界前)注意:这里模板串的前后缀部分都是在绿色边界之前。(对应上图中的1和4)
因此,我们就可以发现,减少子串与父串的匹配次数关键不在于父串,而在于子串的前后缀部分。得到了上述的结论,我们就可以从子串下手来进行匹配过程的优化。
假设我们可以使模板串进行这样的移动,同时也可以确保移动的距离尽可能的小(这样就使得绿色边界前的部分更长,匹配的次数尽可能的少),那么我们就可以进行匹配过程的优化。
为什么?
1. 由于第二部分与第三部分相等,那么就代表:子串的后缀部分与父串中相对应的部分相等。
2. 第二部分与第四部分相等。那么就代表子串的前后缀部分相等(绿色边界前)。
3. 根据1和2,我们就可以把移动后子串的前缀部分(第一部分)与移动前子串的后缀部分(第二部分)对齐(不用重新比较了,因为一定相等)(这样做也是跟父串的第三部分对齐)。对齐之后,再从下一个位置跟父串继续比较即可。
这样就实现了优化,也是KMP算法的精髓所在。(即:通过寻找子串本身的规律,利用这样的规律来实现最大程度上减少与父串的匹配次数)。
根据上述的规律,我们发现KMP是通过在某个点父串与子串失配的情况下,寻找子串最大的前后缀部分来尽可能的减少匹配次数。那么,在某个点父串与子串失配的情况下,子串最大的前后缀部分是怎么寻找出来的?因此,我们引入了next数组。
4. next数组作用、含义
换句话说,next数组的作用就是:当父串与子串在某个点失配时(我们假设i和j当前都指向这个点,其中i代表父串指针,j代表子串指针),子串指针j将要移动的位置(使得子串的前缀部分可以跟子串的后缀部分对齐/父串的第三部分对齐)。用语言表示的话:j = next[j]。(其实,仔细想想就可以发现next[j]实际上就是子串前缀部分的下一个位置)。
那么,next数组的深层含义是什么呢?
实际上,next[i] = j。实际上就是指:在子串p中,以i为终点的后缀和以1为起点的前缀它们之间相等的最大值(前后缀的长度最大)是多少。
我们假设p为子串:
则上述内容用语言表示:
p[1,j] = p[i-j+1,i]

上图为求解next数组的案例。
5. KMP算法的执行过程
1. 根据模板串,推导出next数组。
2. 进行匹配,当父串与子串在某个点i失配时,让子串指针移动到next[i]的位置即可。继续往下匹配。
3. 继续往下匹配后,如果成功匹配,则继续往下,直到子串全部匹配完成即可。如果没有成功匹配,则递归执行2即可。
6. KMP算法模板
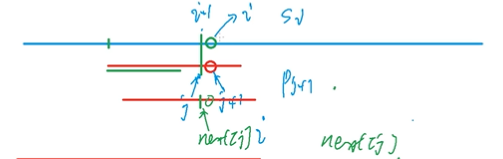
在代码实现时:
1. 父串和子串都从下标1开始。
2. 在绿色边界处,对于父串来讲指针为i-1,而对子串来讲指针为j。
3. 在失配处,父串的指针为i,而子串的指针为j+1。换句话说,父串和子串的指针相差一位。
// s[]是长文本,p[]是模式串,n是s的长度,m是p的长度,ne[]代表next数组。
//求模式串的Next数组:默认next[1] = 0
//next数组的求解过程跟KMP的父子串匹配过程类似,只不过将父串也改为子串。
for (int i = 2, j = 0; i <= m; i ++ )
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++ ;
//记录next数组
ne[i] = j;
}
// 匹配
for (int i = 1, j = 0; i <= n; i ++ )
{
//当j为0时,(已经到达了退无可退的地步),那么就代表从头开始匹配。
//s[i] != p[j+1] 代表失配
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j ++ ;
if (j == m)
{
//如果匹配成功后,还需要继续匹配,如果不需要,下面这句话可以删掉。
j = ne[j];
// 匹配成功后的逻辑
}
}
7. 例题
https://www.acwing.com/problem/content/833/
#include <iostream>
#include <cstdio>
using namespace std;
int main(){
int n,m;
char S[1000010],P[100010];
int ne[100010];
cin >> n >> P+1 >> m >> S+1;
for(int i=2,j=0;i<=n;i++){
while(j && P[i] != P[j+1]){
j = ne[j];
}
if(P[i] == P[j+1]){
j++;
}
ne[i] = j;
}
for(int i=1,j=0;i<=m;i++){
while(j && S[i] != P[j+1]){
j = ne[j];
}
if(S[i] == P[j+1]){
j++;
}
if(j == n){
//如果下标从1开始:i-n+1
//本题下标从0开始:i-n
printf("%d ",i-n);
j = ne[j];
}
}
return 0;
}
作者:gao79138
链接:https://www.acwing.com/
来源:本博客中的截图、代码模板及题目地址均来自于Acwing。其余内容均为作者原创。
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现