

spark 流处理实例
开发环境:
系统:win 11 java : 1.8 scala:2.13 spark : 3.3.2
一, 使用 spark 结构化流读取文件数据,并做分组统计。
功能:spark 以结构化流形式从文件夹读取 csv 后缀数据文件,并进行连表分组统计。每次触发计算后,结果表输出到console控制板。
代码:

package org.example;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.streaming.OutputMode;
import org.apache.spark.sql.streaming.StreamingQuery;
import org.apache.spark.sql.streaming.StreamingQueryException;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import java.util.concurrent.TimeoutException;
public class Main {
/*
例子:从文件中读取流, 被定义模式,生成dataset ,使用sql api 进行分析。
*/
public static void main(String[] args) throws TimeoutException, StreamingQueryException {
System.out.println("Hello world!");
SparkSession spark = SparkSession.builder().appName("spark streaming").config("spark.master", "local")
.config("spark.sql.warehouse.dir", "file:///app/")
.getOrCreate();
spark.sparkContext().setLogLevel("ERROR");
StructType schema =
new StructType().add("empId", DataTypes.StringType).add("empName", DataTypes.StringType)
.add("department", DataTypes.StringType);
Dataset<Row> rawData = spark.readStream().option("header", false).format("csv").schema(schema)
.csv("D:/za/spark_data/*.csv");
rawData.createOrReplaceTempView("empData");
Dataset<Row> result = spark.sql("select count(*), department from empData group by department");
StreamingQuery query = result.writeStream().outputMode("complete").format("console").start(); // 每次触发,全表输出
query.awaitTermination();
}
}
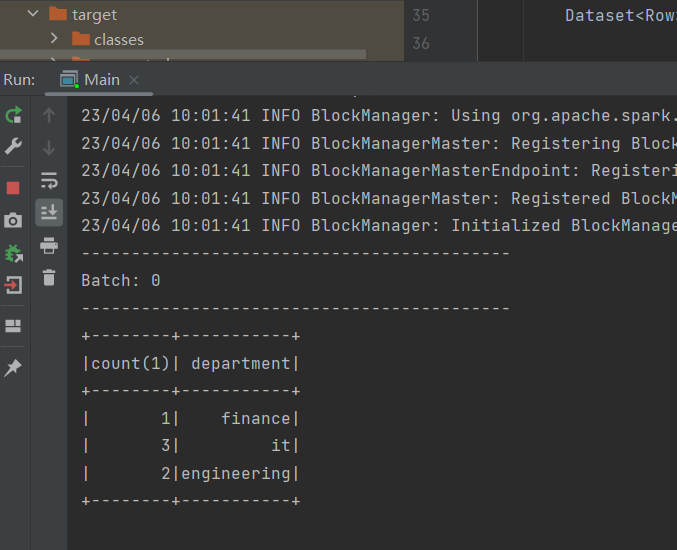
输出:
二, 使用 spark 结构化流读取socket流,做单词统计,使用Java编程
功能:spark 读取本地机器的网络流数据,并统计。
代码:
package org.example;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.streaming.StreamingQuery;
import org.apache.spark.sql.streaming.StreamingQueryException;
import java.util.Arrays;
import java.util.concurrent.TimeoutException;
public class SocketStreaming_wordcount {
/*
* 从socket 读取字符流,并做word count分析
*
* */
public static void main(String[] args) throws TimeoutException, StreamingQueryException {
SparkSession spark = SparkSession
.builder()
.appName("JavaStructuredNetworkWordCount")
.config("spark.master", "local")
.getOrCreate();
// dataframe 表示 socket 字符流
Dataset<Row> lines = spark
.readStream()
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load();
// 把一行字符串切分为 单词
Dataset<String> words = lines
.as(Encoders.STRING())
.flatMap((FlatMapFunction<String, String>) x -> Arrays.asList(x.split(" ")).iterator(), Encoders.STRING());
// 对单词分组计数
Dataset<Row> wordCounts = words.groupBy("value").count();
// 开始查询并打印输出到console
StreamingQuery query = wordCounts.writeStream()
.outputMode("complete")
.format("console")
.start();
query.awaitTermination();
}
}
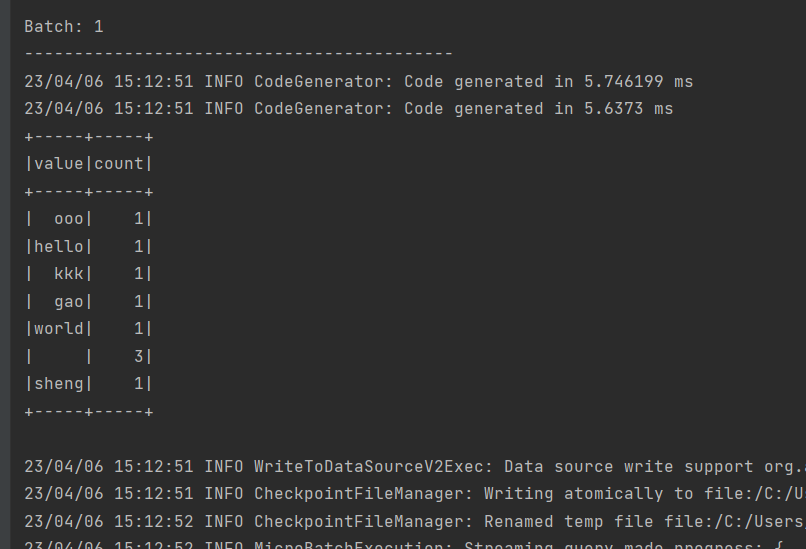
输出:
二, 使用 spark 结构化流读取socket流,做单词统计,使用scala 编程
功能:同上
代码:
import org.apache.spark.sql.SparkSession
object Main {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("streaming_socket_scala")
.config("spark.master", "local")
.getOrCreate()
import spark.implicits._
// 创建datafram 象征从网络socket 接收流
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// 切分一行成单词
val words = lines.as[String].flatMap(_.split(" "))
// 进行单词统计
val wordCounts = words.groupBy("value").count()
// 开始查询并输出
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
}
}
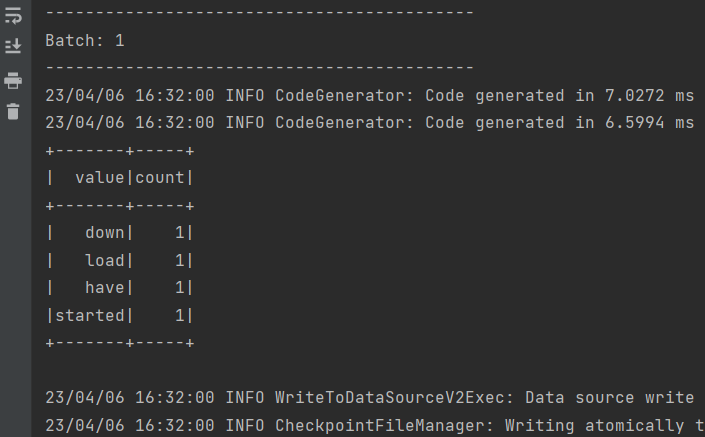
输出:
---一------步-----一 ------个-----脚--------印----------


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】