

spark structured streaming (结构化流) join 操作( 官方文档翻译)
spark 结构化流 join 连接
结构化流支持将流dataset/DataFrame与静态dataset/DataFrame,或者另一个流数据集-DataFrame连接起来。流式连接的结果是增量生成的,与流式聚合(streaming aggregation)的结果类似。请注意,在所有支持的连接类型中,与流dataset/DataFrame的连接结果将与与流中包含相同数据的静态dataset/DataFrame的连接完全相同。
1, 流-静态连接
自从在 Spark 2.0 中引入以来,Structured Streaming 就支持流和静态 DataFrame/Dataset 之间的连接(内部连接和某种类型的外部连接)。
staticDf = spark.read. ...
streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type") # inner equi-join with a static DF
streamingDf.join(staticDf, "type", "left_outer") # left outer join with a static DF
注意: 流静态连接不是有状态的,因此不需要状态管理。
2,流-流连接
在 Spark 2.3 中,我们增加了对流-流join的支持,即你可以连接两个流式 Datasets/DataFrames。在两个数据流之间生成连接结果的挑战在于,在任何时间点,连接两侧的数据集都是不完整的,这使得在输入之间找到匹配变得更加困难。从一个输入流接收到的任何行都可以与来自另一个输入流的任何未来的、尚未接收到的行相匹配。因此,对于两个输入流,我们将过去的输入缓冲为流状态( streaming state),这样我们就可以将每个未来的输入与过去的输入进行匹配,并相应地生成连接结果。此外,与流式聚合类似,我们会自动处理延迟的、乱序的数据,并可以使用水印(watermarking)来限制状态。让我们讨论支持的流-流连接的不同类型以及如何使用它们。
2.1 有水印选项的内连接 inner join with watermarking option
为避免无限大小的state, 需要定义额外的连接条件, 超出期限的老数据不能和新的输入匹配,从而从状态中清除。
为此需要;
1,在2个流上定义 水印延迟 ,让计算引擎知道如何 该数据的延迟程度,是否该被清除。(类似流聚合)
2,在2个流上对事件时间 定义限制。以此,引擎知道,哪些老数据不在被需要和新输入数据连接匹配。
限制有以下2中类型:
1,时间范围连接限制 举例, leftTime between rightTime and rightTime + interval 1 hour
2, event-time 窗口上连接 举例, join on leftTimeWindow = rightTimeWindow
举个例子:
假设我们想要加入一个广告展示流(当显示广告时)与另一个用户点击广告流,以便在广告导致可获利点击时关联起来。要允许在此流-流连接中进行状态清理,您必须指定水印延迟和时间限制,如下所示。
为了在流流连接中允许状态清除,必须指定 水印和时间限制。
1, 水印延迟; 广告展示 和相关点击可以 延迟或者乱序, 最多分别为2 小时和3小时,依据 event-time .
2, event-time 限制; 一次点击可以发生在看到广告后的 0秒 到1小时之间。
代码:
from pyspark.sql.functions import expr
impressions = spark.readStream. ...
clicks = spark.readStream. ...
# Apply watermarks on event-time columns
impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours") # 2个流定义watermarking,超时的数据不再处理,也不会保存到流状态
clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
# Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour # 2个流的时间范围内的限制
""")
)
注:以上过程类似 使用水印的流数据聚合 操作。
2.2 有水印的流流外连接 stream-stream outter join with watermarking
水印+ event-time 限制对内连接是可选的,然后在外连接是必须的。因为,为了确定连接不到的情况,产生NULL 结果, 引擎必须知道哪些输入行不再需要匹配连接。
代码:
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
"leftOuter" # can be "inner", "leftOuter", "rightOuter", "fullOuter", "leftSemi"
)
必须注意:
1, NULL 结果的产生有一个延迟。因为 引擎需要等待一段时间,确认没有匹配,以及未来也没有匹配。
2,如果任何一个流没有新数据进入, 外连接的输出可能会延迟。因为只会在有新数据 进入时,触发一个微批。
2.3 半连接 semi-join wtih watermarking :(semi-join含义是类似 子查询,通过右表提供的逻辑筛选左表的记录。)
类似外连接
支持的连接类型:
表格(见官方文档的表格)
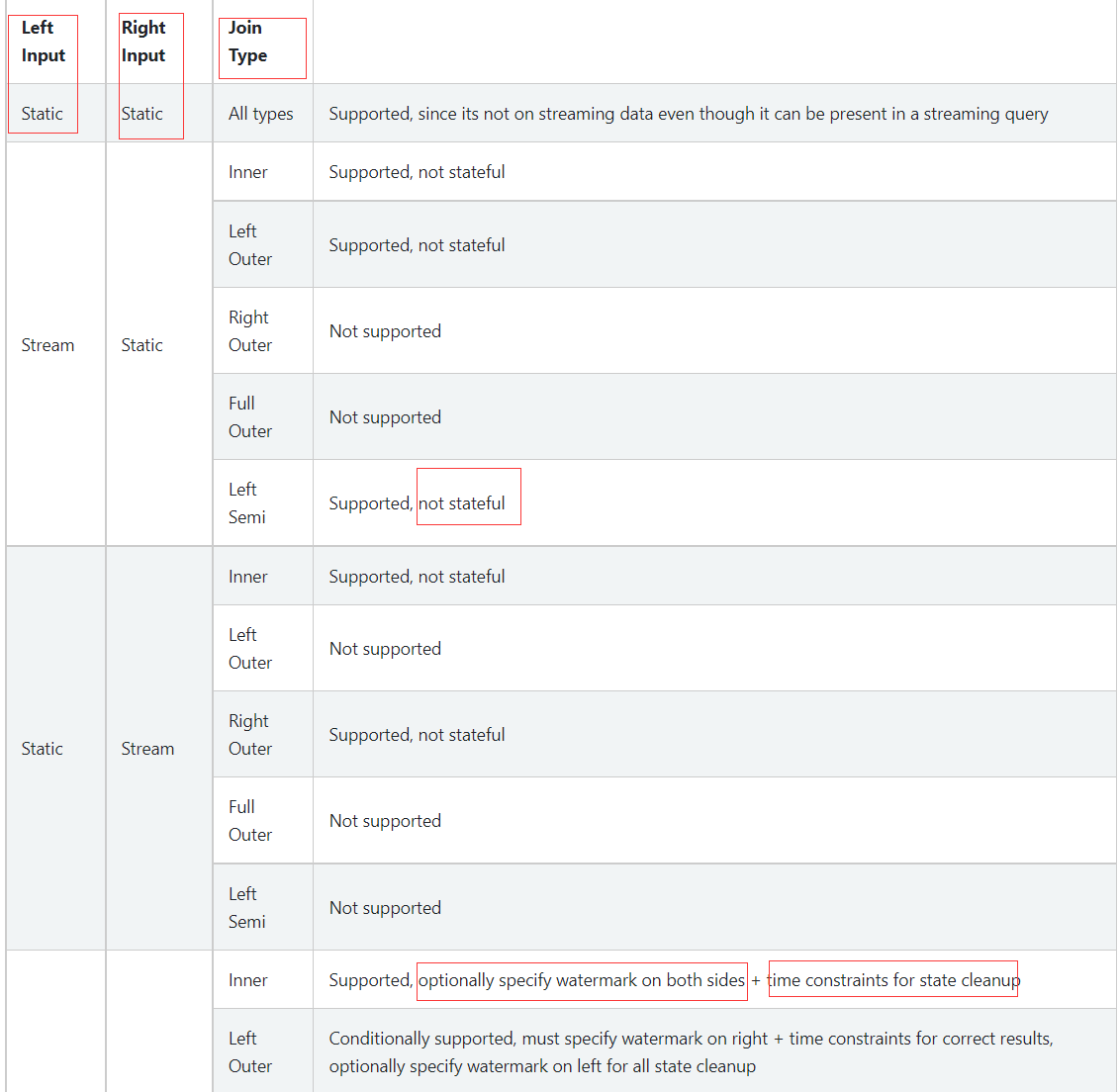
重点关注: 左右表的数据特性(流 / 静态), 是否支持, 以及连接类型 和 连接额外限制
说明:
1, 连接可以 串联 类似 df1.join(df2, ...).join(df3, ...).join(df4, ....).。
2,spark 2.4 , join 只能在 Append输出模式 的查询下适用. 不能在 join 操作之前使用 类非map操作算子。
a, 不能使用 流聚合
b, 不能 mapGroupsWithState and flatMapGroupsWithState
3,流聚合以及水印处理延迟数据
因为 流join 操作和 流的聚合操作 都需要处理延迟数据,都需要保存流状态。所以在一个章节内说明,方便对比学习。
滑动event-time窗口上的聚合与结构化流式处理非常简单,与分组聚合 grouped aggregation非常相似。在分组聚合中,为用户指定的分组列中的每个唯一值维护聚合值(例如计数)。对于基于窗口的聚合,将为输入数据的event-time所在的每个窗口维护聚合值。让我们用一个例子来理解这一点。
(解释:在窗口聚合中,为每一个 时间窗口维护聚合值 (和分组列的值),类似对时间窗口和列 等2个字段进行分组)
举例: 一个word count 流式数据输入例子, 做在10分钟内的 单词统计,每5分钟更新一次。
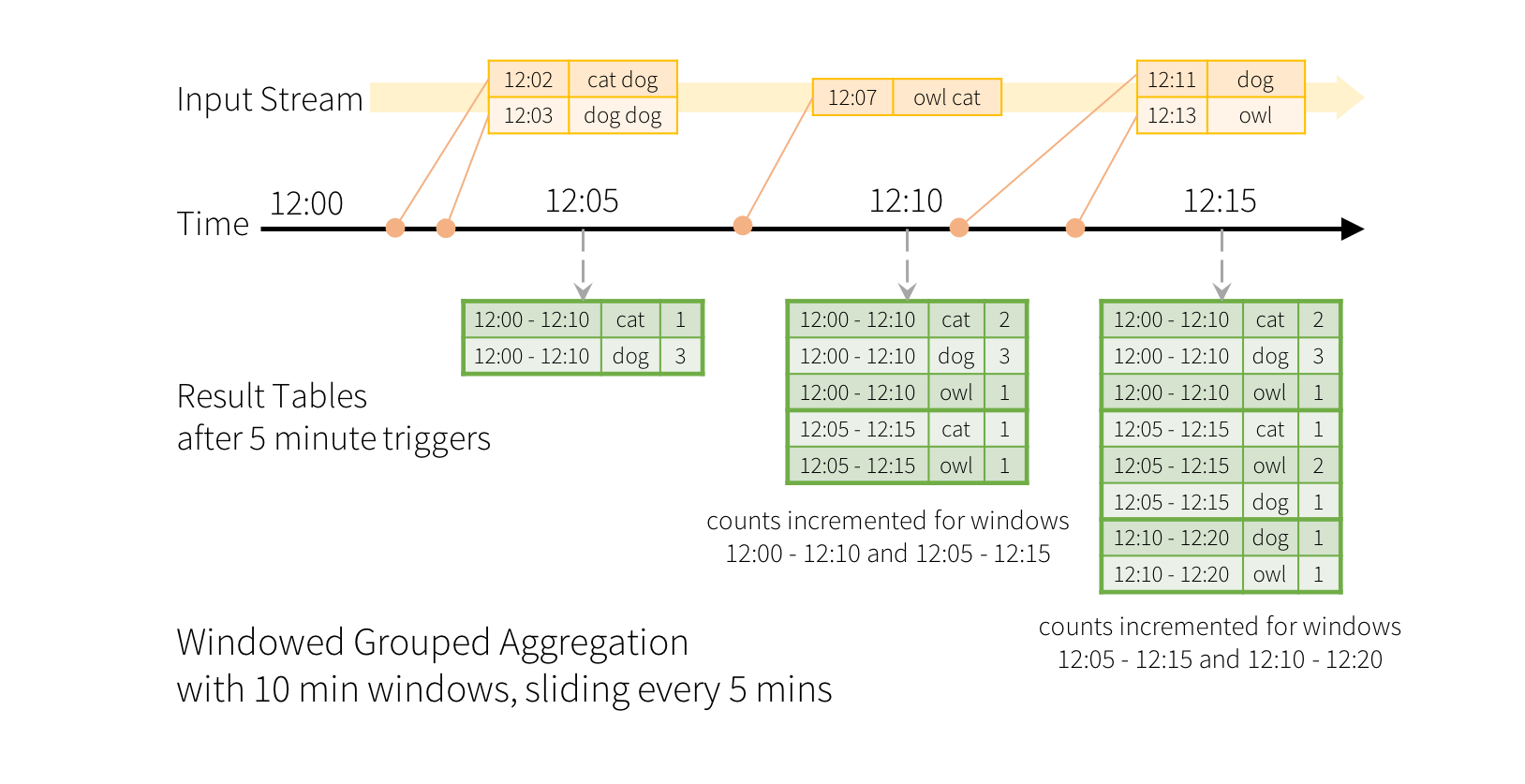
图片说明:
1,每5分钟触发计算一次 ,时间窗口从12:00开始。
2,对时间窗口和 输入数据中的word(单词)进行分组统计数量。
3,在12:07 来了新数据,在12:10计算一次,在 12:05 - 12:15窗口输出 2行结果。 因为 12;07 新数据同时在 12:00 - 12:10 窗口内,因此同时更新了之前触发点trigger(12:05)的输出数据。
代码:
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word
).count()
在上述计算中,并没有处理迟到数据 (delay input row ) .
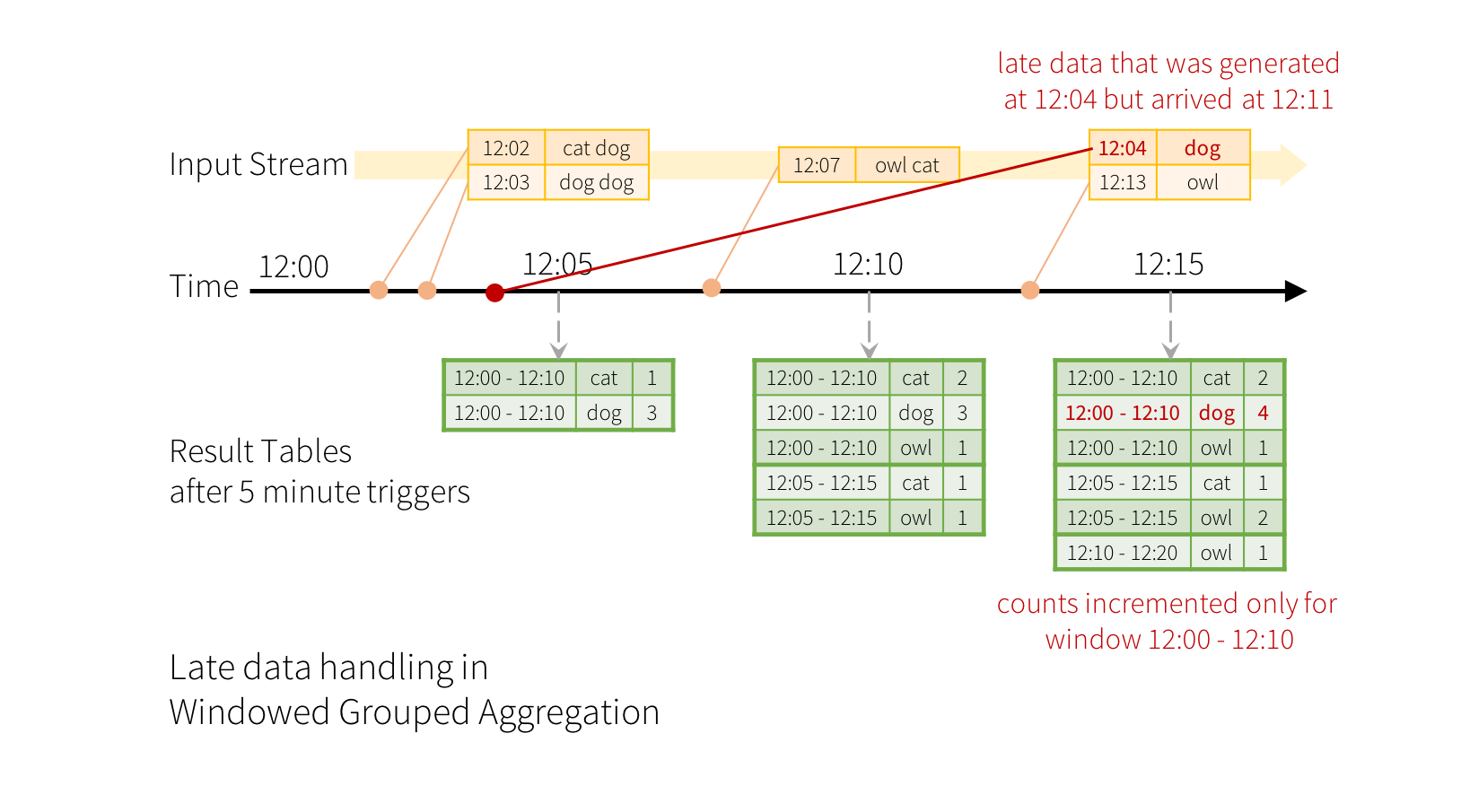
现在 增加水印watermarking 如何解决了 迟到数据,做个简单说明。
举例,如果一个数据事件事件是 12:04 ,但是却在 12:11到达系统处理。迟到数据 在12:11到达, 在12:15开始计算, 然后会被分组到之前的窗口(00-10).所以可以正确处理延迟数据。
这里的水印事件设置为10分钟。
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# 对窗口和 单词进行分组统计 数量
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \ #设置 10分钟的水印
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()
水印的设置可以 限制 引擎在内存中保存的内存中的聚合数据状态。超过水印时间的延迟数据将不会处理, 太老的中间聚合数据状态也会被清理。
参考:
1,spark 3.3.1 官方文档 结构化流- join操作

