14 Linux网络管理

14 Linux网络管理
1. 网络基本概述
1.1 为何需要网络
- 假设没有网络:(也就是将所有的计算机网络都关闭)
- 如果我的计算机上有非常不错的电影,想要进行传
输,就比较的费劲了; - 因为我们可能处在不同的城市、或者不同的国家;
- 如果我的计算机上有非常不错的电影,想要进行传
- 但如果有了网络:(也就是将所有计算机通过网线连
接在一起)- 1.打破了地域上数据传输的限制;
- 2.提高信息之间的传输效率,以便更好的实现”资源
的共享“;
1.2 什么是网络
- 网络是由"若干节点"和"连接这些节点"的链路构成,
表示诸多对象及其相互联系。 - 网络是信息传输、接收、共享的虚拟平台,通过它把
各个信息联系到一起,从而实现这些资源的共享。 - 网络将节点连接在一起,需要实现 ”信息传输“(信息
通信)有几个大前提:- 1.使用物理连接的介质将所有计算机连接在一起
(网卡、网线、交换机、路由器); - 2.双方在通信过程中,必须使用统一的通信标准,
也就是通讯协议(互联网通讯协议);
- 1.使用物理连接的介质将所有计算机连接在一起

2.互联网通讯协议
- 协议其实就是规定了一堆标准,用来定义计算机如何
接入 internet 以及接入 internet 的计算机通信的
标准;所以计算机都需要学习此标准、遵循此标准来
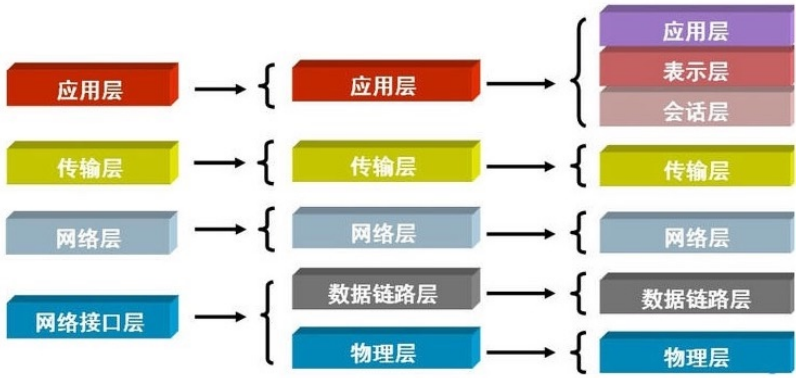
进行信息传输(信息通信); - 国际标准化组织:推出了 OSI 七层参考模型,将互联
网通讯协议分成了不同的层,每一层都有专门的标
准,以及组织数据的格式;- (应、表、会、传、网、数、物)
- 对于写程序来说,通常会将七层归纳为五层协议;
- (应、传、网、数、物)
- 所以我们需要学习协议的规定了哪些标准;
2.1 物理层
物理层:定义物理设备的标准,如网卡网线,传输速
率;最终实现数据转成电信号传输;
问题:如果只是单纯发送电信号是没有意义的,因为没
有规定开头也没有规定结尾;要想变得有意义就必须对
电信号进行分组;比如:xx位为一组、这样的方式去传
输,这就需要“数据链路层”来完成了;

2.2 数据链路层
- 数据链路层定义:定义了电信号的分组的标准方式,
一组数据称之为一个数据帧,这个标准遵循
ethernet 以太网协议,以太网规定了如下几件事; - 1.数据帧分为 head 和 data 两部分组成;其中 head
长度固定18字节;- head :发送者/源地址、接收者/目标地址(源地址
6字节、目标地址6字节、数据类型6字节)- 源地址: MAC 地址
- 目标地址: MAC 地址
- data :主要存放是网络层整体的数据,最长1500
字节,超过最大限制就分片发送;
- head :发送者/源地址、接收者/目标地址(源地址
- 2.但凡接入互联网的主机必须有一块网卡,网卡烧制
了全世界唯一的 MAC 地址; - 3.有了以太网协议规定以后,它能对数据分组、也可
以区分数据的意义,还能找到目标主机的地址、就可
以实现计算机通信;但是计算机是瞎的,所以以太网
通信采用的是"广播"方式;

- 那什么是广播:
- 假设我们都在一个小黑屋里面,大家互相通信靠
吼,假设 oldxu 让 laowang 买包烟;- 1.数据:买烟(类型:干粮)
- 2.源地址: oldxu
- 3.目标地址: laowang
- 此时屋子里所有人都收到了该数据包,但只有
laowang 会接收执行,其他人收到后会丢弃;
- 假设我们都在一个小黑屋里面,大家互相通信靠
- 如果我们将全世界的计算机都接入在一起,理论上是
不是就可以实现全世界通信:- 首先:无法将全世界计算机放在一个交换机上,因
为没有这样的设备; - 其次:就算放在同一设备上,每台计算机都广播一
下,那设备也无法正常工作; - 所以:我们应该将主机划区域,隔离在一个又一个
的区域中,然后将多个区域通过"网关/路由"连接在
一起;
- 首先:无法将全世界计算机放在一个交换机上,因
2.3 网络层
-
网络层定义:用来划分广播域,如果广播域内主机要
往广播域外的主机发送数据,一定要有一个"网关/路
由"帮其将数据转发到外部计算机;网关和外界通信走
的是路由协议(这个我们不做详细阐述)。其次网络
层协议规定了如下几件事;- 规定1:数据包分成: head 和 data 两部分组成;
- head :发送者/源地址、接收者/目标地址,该
地址为IP地址; - data :主要存放是传输层整体的数据;
- head :发送者/源地址、接收者/目标地址,该
- 规定2: IP 地址来划分广播域,主要用来判断两台
主机是否在同一广播域中;- 一个合法 IPV4 地址组成部分= ip地址/子网掩
码 ,在线子网计算器 - 172.16.1.100/24、172.16.1.1/24、
172.16.1.2/24 - 172.16.1.200/24
- 网段:172.16.1.0
- 主机:100台
- 广播地址:172.16.1.255
- 如果计算出两台地址的广播域一样,说明两台
计算机处在同一个区域中;
- 一个合法 IPV4 地址组成部分= ip地址/子网掩
- 规定1:数据包分成: head 和 data 两部分组成;
- 计算两台计算机是否在同一局域网(牵扯到如何发送数据):
- 假设:现在计算机1要与计算机2通信,计算机1必须
拿到计算机2的ip地址;- 如果它们处于同一网络(局域网) 10.0.0.1-->10.0.0.100 :
- 1.本地电脑根据数据包检查目标 IP 如果为本地
局域网; - 2.直接通过交换机广播MAC寻址;将数据包转
发过去;
- 1.本地电脑根据数据包检查目标 IP 如果为本地
- 如果它们处于不同网络(跨局域网) 10.0.0.1--
39.104.16.126 :- 1.本地根据数据包检查目标 IP 如果不为本地局
域网,则尝试获取网关的 MAC 地址; - 2.本地封装数据转发给交换机,交换机拆解发现
目标 MAC 是网关,则送往网关设备; - 3.网关收到数据包后,拆解至二层后发现请求目
标 MAC 是网关本机 MAC ; - 4.网关则会继续拆解数据报文到三层,发现目标
地址不为网关本机; - 5.网关会重新封装数据包,将源地址替换为网关
的 WAN 地址,目标地址不变; - 6.出口路由器根据自身“路由表”信息将数据包发
送出去,直到送到目标的网关 ;
- 1.本地根据数据包检查目标 IP 如果不为本地局
- 如果它们处于同一网络(局域网) 10.0.0.1-->10.0.0.100 :
2.4 传输层
- 传输层的由来:网络层帮我们区分子网,数据链路层
帮我们找到主机,但一个主机有多个进程,进程之间
进行不同的网络通信,那么当收到数据时,如何区分
数据是那个进程的呢;其实是通过端口来区分;端口
即应用程序与网卡关联的编号。 - 传输层的定义:提供进程之间的逻辑通信;
- 传输层也分成: head 和 data 两部分组成;
- head :源端口、目标端口、协议(TCP、
UDP); - data :主要存放是应用层整体的数据;
- 80:http
- 443:https
- mysql:3306
- tomcat:8080
- redis:6379
- dns:53
- dhcp:67 68
- head :源端口、目标端口、协议(TCP、

2.5 应用层
- 应用层定义:为终端应用提供的服务,如我们的浏览
器交互时候需要用到的 HTTP 协议,邮件发送的
SMTP,文件传输的 FTP 等。 - 浏览器:
- 请求百度的内容: 请求包; 请求的协议;
http 源断口: 1234 目标端口:80
- 请求百度的内容: 请求包; 请求的协议;
3.TCP协议
- tcp可靠数据传输协议;为了实现可靠传输,在通信之
前需要先建立连接,也叫"双向通路",就是说客户端
与服务端要建立连接,服务端与客户端也需要建立连
接,当然建立的这个双向通路它只是一个虚拟的链
路,不是用网线将两个设备真实的捆绑在一起; - 虚拟链路的作用:由于每次通信都需要拿到IP和
Port,那就意味着每次都需要查找,建立好虚拟通
路,下次两台主机之间就可以直接传递数据;
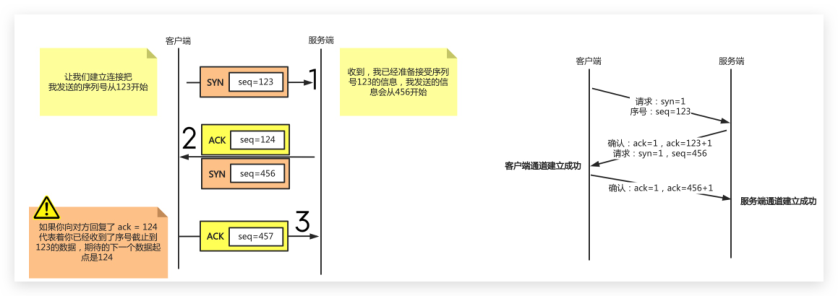
3.1 三次握手
- 第一次:客户端要与服务端建立连接,需要发送请求
连接消息; - 第二次:服务端接收到数据后,返回一个确认操作
(至此客户端到服务端链路建立成功); - 第三次:服务端还需要发送要与客户端建立连接的请求;
- 第四次:客户端接收到数据后,返回一个确认的操作
(至此服务端到客户端的链路建立成功); - 由于建立连接时没有数据传输,所以第二次确认和第
三次请求可以合并为一次发送

- TCP协议为了实现可靠传输,通信双方需要判断自已
经发送的数据包是否都被接收方收到,如果没收到,
就需要重发。为了实现这个需求,就引出序号
(seq)和确认号(ack)的使用。 - 举例:发送方在发送数据包时,序列号(假设为
123),那么接收方收到这个数据包以后, 就可以回复
一个确认号(124=123+1)告诉发送方 “我已经收到
了你的数据包,你可以发送下一个数据包,序号从
124 开始”,这样发送方就可以知道哪些数据被接收
到,哪些数据没被接收到,需要重发。
3.2 四次挥手
- 第一次挥手:客户端(服务端也可以主动断开)向服
务端说明想要关闭连接; - 第二次挥手:服务端会回复确认。但不是立马关闭,
因为此时服务端可能还有数据在传输中; - 第三次挥手:待到服务端数据传输都结束后,服务端
向客户端发出消息,我要断开连接了; - 第四次挥手:客户端收到服务端的断开信息后,给予
确认。服务端收到确认后正式关闭。

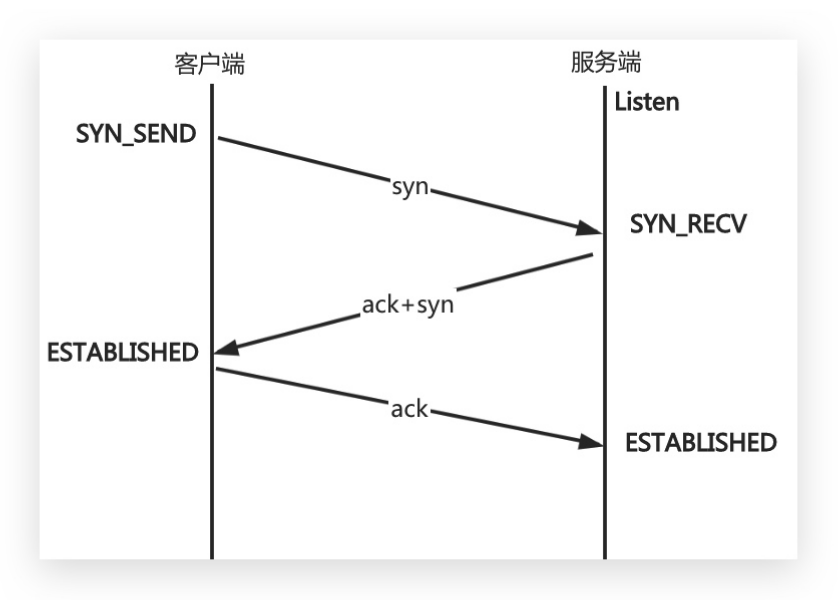
3.3 转换状态
- 三次握手状态转换:
- 1.客户端发送syn包向服务端请求建立 TCP 连接,客户
端进入 SYN_SEND 状态; - 2.服务端收到请求之后,向客户端发送 SYN+ACK 的合
成包,同时自身进入 SYN_RECV 状态; - 3.客户端收到回复之后,发送 ACK 信息,自身进入
ESTABLISHED 状态; - 4.服务端收到ACK数据之后,进入 ESTABLISHED 状
态。
-
四次挥手过状态转换:
-
1.客户端发送完数据之后,向服务器请求断开连接,
自身进入 FIN_WAIT_1 状态; -
2服务端收到 FIN 包之后,回复 ACK 包表示已经收到,
但此时服务端可能还有数据没发送完成,自身进入
CLOSE_WAIT 状态,表示对方已发送完成且请求关闭
连接,自身发送完成之后可以关闭连接; -
3.服务端数据发送完成后,发送 FIN 包给客户端,自
身进入 LAST_ACK 状态,等待客户端 ACK 确认; -
4.客户端收到 FIN 包之后,回复一个 ACK 包,并进入
TIME_WAIT 状态; -
注意: TIME_WAIT 状态比较特殊,当客户端收到服务
端的 FIN 包时,理想状态下,是可以直接关闭连接
了;但是有几个问题:- 问题1:网络是不稳定的,可能服务端发送的一些
数据包,比服务端发送的 FIN 包还晚到; - 问题2:.如果客户端回复的ACK包丢失了,服务端
就会一直处于 LAST_ACK 状态,如果客户端没有关
闭,那么服务端还会重传 FIN 包,然后客户端继续
确认;
- 问题1:网络是不稳定的,可能服务端发送的一些
-
所以客户端如果 ACK 后立即关闭连接,会导致数据不
完整、也可能造成服务端无法释放连接。所以此时客
户端需要等待2个报文生存最大时长,确保网络中没
有任何遗留报文了,再关闭连接;期间客户端不断给
服务端发送ACK确认,防止服务端收不到一直处于LAST_ACK状态 -
如果机器 TIME_WAIT 过多,会造成端口会耗尽,可以
修改内核参数 tcp_tw_reuse=1 端口重用;

- 为什么必须要等待2MSL?而不是4MSL?8MSL?
- 一个MSL就是报文在网络中的最长生存时间,大白话
的话,就是如果存在丢包的话,在MSL时间内也会触
发重传了,这里2MSL,就相当于两次丢包,一次丢
包概率是百分之一,连续两次丢包的概率是万分之
一,这个概率实在是太小了,所以2MSL是足够的。
3.4 UDP协议
- udp 是不可靠传输协议;不可靠指的是传输数据时不
可靠; - udp 协议不需要先建立连接,只需要获取服务端的
ip+port ,发送完毕也无需服务器返回 ack - udp 协议如果在发送在数据的过程中丢了,那就丢
了; - 场景:直播;弹幕; DNS 采用; QQ早起UDP;
4. 网络配置
4.1 查询网络信息
1.使用 ifconfig 当前处于活动状态的网络接口
[root@node ~]# yum install net-tools -y
[root@node ~]# ifconfig
#仅查看eth0网卡状态信息
[root@node ~]# ifconfig eth0
#查看所有网卡状态信息, 包括禁用和启用
[root@node ~]# ifconfig -a
#UP: 网卡处于活动状态 BROADCAST: 支持广播
RUNNING: 网线已接入
#MULTICAST: 支持组播 #MTU: 最大传输单元(字节),接
口一次所能传输的最大包
eth0:
flags=4163<UP,BROADCAST,RUNNING,MULTICAST>
mtu 1500
#inet: 显示IPv4地址行
inet 10.0.0.100 netmask
255.255.255.0 broadcast 10.0.0.255
#inet6: 显示IPv6地址行
inet6 fe80::a879:62cf:396c:e7d9
prefixlen 64 scopeid 0x20<link>
inet6 fe80::22a2:cb:8a69:bf63
prefixlen 64 scopeid 0x20<link>
#enther: 硬件(MAC)地址
#txqueuelen: 传输缓存区长度大小
ether 00:0c:29:5f:6b:8a txqueuelen
1000 (Ethernet)
#RX packets: 接收的数据包
RX packets 3312643 bytes
4698753634 (4.3 GiB)
RX errors 0 dropped 0 overruns 0
frame 0
#TX packets: 发送的数据包
TX packets 235041 bytes 20504297
(19.5 MiB)
TX errors 0 dropped 0 overruns 0
carrier 0 collisions 0
#errors: 总的收包的错误数量
#dropped: 拷贝中发生错误被丢弃
#collisions: 网络信号冲突情况, 值不为0则可能存在
网络故障
2.使用 ip 命令查看当前地址
[root@node ~]# ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,①UP,LOWER_UP>
mtu 1500 qdisc pfifo_fast state UP qlen
1000
②link/ether 00:0c:29:5f:6b:8a
ff:ff:ff:ff:ff:ff
③inet 10.0.0.100/24 brd④ 192.168.69.255
scope global ens32
valid_lft forever preferred_lft
forever
⑤inet6 fe80::bd23:46cf:a12e:c0a1/64
scope link
valid_lft forever preferred_lft
forever
#①: 活动接口为UP
#②: Link行指定设备的MAC地址
#③: inet行显示IPv4地址和前缀
#④: 广播地址、作用域和设备名称在此行
#⑤: inet6行显示IPv6信息
3.使用 ip -s link show eth0 命令查看网络性能的统
计信息, 比如: 发送和传送的数据包、错误、丢弃
[root@node ~]# ip -s link show eth0
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc mq state UP mode DEFAULT
qlen 1000
link/ether 14:18:77:35:0d:f5 brd
ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped
overrun mcast
518292951 4716385 0 0 0
709280
TX: bytes packets errors dropped
carrier collsns
23029861512 15391427 0 0 0
0
4.2 修改网卡名称
- Centos6 网卡名称是 eth0、eth1....
- Centos7 网卡名称是 ens32、ens33...
- 由于这种无规则的命名方式给后期维护带来了困难,
所以需要将网卡名称修改为 eth0、eth1..
场景示例1:已经安装完操作系统,修改网卡命名规
则为 eth0 eth1
1.修改网卡配置文件
[root@node ~]# cd /etc/sysconfig/network-scripts/
[root@node network-scripts]# mv ifcfg-ens32 ifcfg-eth0
[root@node network-scripts]# vim ifcfg-eth0
NAME=eth0
DEVICE=eth0
2.修改内核启动参数,禁用预测命名规则方案,将
net.ifnames=0 biosdevname=0 参数关闭
[root@node~]# vim /etc/sysconfig/grub
GRUB_CMDLINE_LINUX="...net.ifnames=0 biosdevname=0 quiet"
[root@node~]# grub2-mkconfig -o /boot/grub2/grub.cfg
3.重启系统,然后检查网卡名称是否修改成功
[root@node~]# reboot
[root@node~]# ifconfig
- 场景示例2:在新安装系统时,修改网卡名称规则
1.在安装系统选择 Install Centos7 按下 Tab 设定
kernel 内核参数;
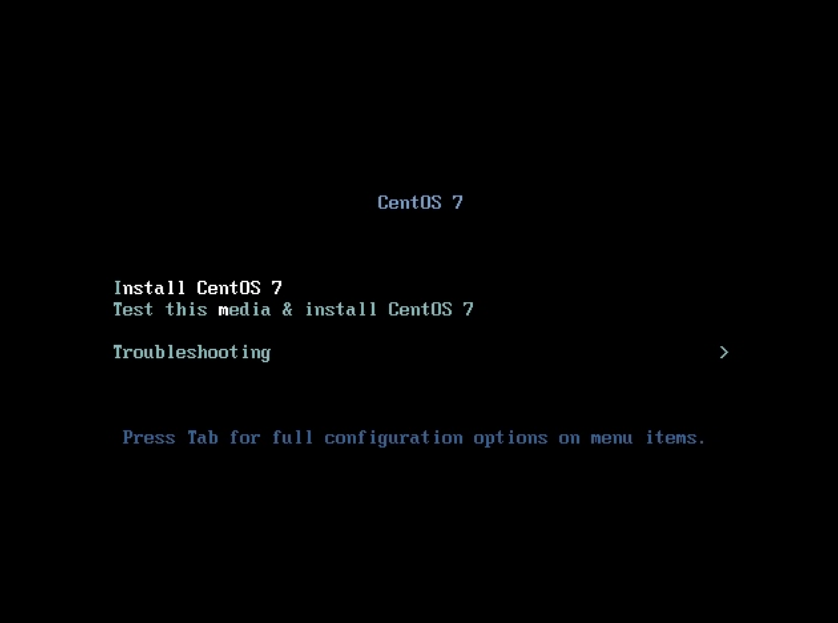
2.增加内核参数: net.ifnames=0 biosdevname=0 ;
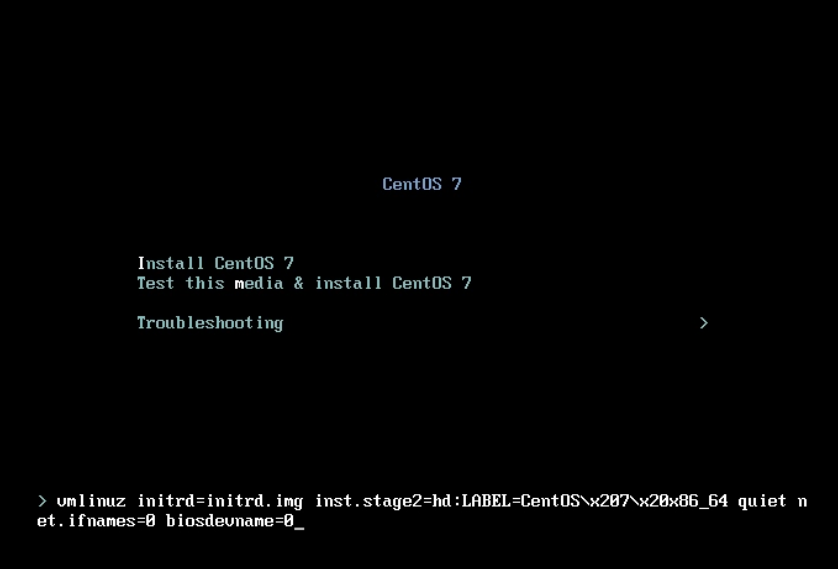
3.检查是否修改成功,成功后可继续安装系统;
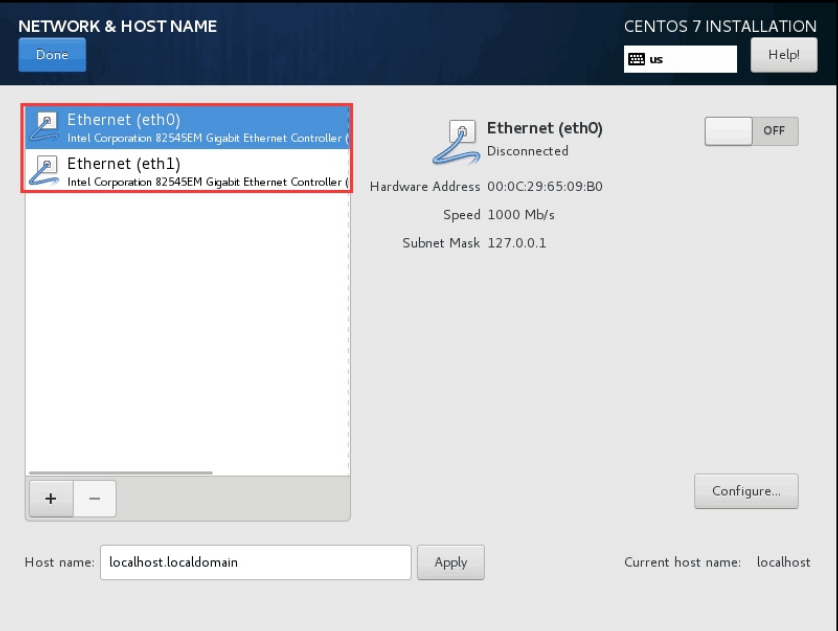
4.3 配置网络地址
- CentOS7 系统默认采用 NetworkManager 来提供网
络服务,这是一种动态管理网络配置的守护进程,能
够让网络设备保持连接状态。 NetworkManager 提供
的命令行和图形配置工具对网络进行设定,设定保存
的配置文件在 /etc/sysconfig/network-scripts
目录下,工具有 nmcli、nmtui - NetworkManager 有如下两个概念需要了解:
- device 物理设备,例如: enp2s0,virbr0,team0
- connection 连接设置,具体网络配置方案
- 一个物理设备 device 可以有多套逻辑连接配置,
但同一时刻只能使用一个 connection 连接配置;
4.3.1 nmcli查看网络状态
1.使用 nmcli device 命令查看设备情况
# 查看所有设备
[root@node ~]# nmcli device
DEVICE TYPE STATE CONNECTION
eth0 ethernet connected eth0
lo loopback unmanaged --
# 指定查看某个设备的详细状态
[root@node ~]# nmcli dev show eth0
2.使用 nmcli connection 命令查看连接状态
#查看连接状态
[root@node ~]# nmcli connection
NAME UUID
TYPE DEVICE
eth0 a4319b27-80dc-4d63-a693-2927ea1018e7
802-3-ethernet eth0
# 查看所有活动连接的状态
[root@node ~]# nmcli con show --active
# 查看指定连接状态
[root@node ~]# nmcli con show "eth0"
4.3.2 nmcli配置IP地址
- 使用 nmcli 创建一个 static 的连接,配置IP、掩
码、网关等- 1、添加一个连接配置,并指定连接配置名称
- 2、将连接配置绑定物理网卡设备
- 3、配置网卡的类型,网卡是否开机启动
- 4、网卡使用什么模式配置IP地址(静态、dhcp)
- 5、配置网卡的IP地址、掩码、网关、DNS等等
[root@node ~]# nmcli connection add \
con-name eth0-static \
ifname eth0 \
type ethernet \
autoconnect yes \
ipv4.addresses 10.0.0.222/24 \
ipv4.gateway 10.0.0.2 \
ipv4.dns 223.5.5.5 \
ipv4.method manual
[root@oldxu ~]# nmcli connection add con-
name eht0-static ifname eth0 \
type ethernet autoconnect yes \
ipv4.method manual \
ipv4.addresses 10.0.0.222/24 \
ipv4.gateway 10.0.0.254 \
ipv4.dns 233.5.5.5.5 \
+ipv4.dns 8.8.8.8
#激活eht1-static的连接
[root@node ~]# nmcli connection up eht0-static
[root@node ~]# nmcli connection show
NAME UUID
TYPE DEVICE
eht0-static 6fdebe6e-5ef0-4a05-8235-
57e317fdada0 802-3-ethernet eth0
4.3.3 nmcli修改IP地址
1.取消 eht1-static 连接开机自动激活网络
[root@node ~]# nmcli connection modify eht0-static \
autoconnect no
2.修改 eht1-static 连接的 dns 配置
[root@node ~]# nmcli connection modify
eht0-static \
ipv4.dns 8.8.8.8
3.给连接再增加 dns 有些设定值通过 +/- 可以增加或则移除设定
[root@node ~]# nmcli connection modify
eht0-static \
+ipv4.dns 8.8.8.8
4.替换连接的静态IP和默认网关
[root@node ~]# nmcli connection modify
eht0-static \
ipv4.addresses 10.0.0.111/24 ipv4.gateway
10.0.0.254
5.nmlci 仅仅修改并保存了配置,要激活更改,需要重激活连接
[root@node ~]# nmcli connection down eht1-
static && \
nmcli connection up eht1-static
6.删除自建的 connection
[root@node ~]# nmcli connection delete
eht1-static
4.3.4 nmcli管理配置文件
-
使用 nmcli 管理 /etc/sysconfig/network-
scripts/ 配置文件,其实就是自定义一个网卡的配
置文件,然后加入至 NetworkManager 服务进行管
理;- 1、新增物理网卡
- 2、拷贝配置文件(可以和设备名称一致)
- 3、修改配置,UUID、连接名称、设备名称、IP地址
- 4、重新加载网络配置
- 5、启用连接,并检查
1.添加一个物理设备,进入 /etc/sysconfig/network-
script/ 目录拷贝一份网卡配置文件;[root@node network-scripts]# cp ifcfg- eth0-static ifcfg-eth1-static2.修改网卡配置文件如下
[root@node network-scripts]# cat ifcfg- eth1-static TYPE=Ethernet BOOTPROTO=none # 网卡类型 none; static;dhcp; 硬件服务器都选择static、云主机、 docker容器实例一般都是dhcp IPADDR=10.0.0.222 # IP地址 PREFIX=24 # 子网掩码 DEFROUTE=yes # 默认路由(明天讲 路由) NAME=eth1-static # 链接的配置名称 DEVICE=eth2 # 设备名称 ONBOOT=yes # 开机是否启动3.重载 connetction 连接,让 NetworkManager 服务能够识别添加自定义网卡配置;
[root@node network-scripts]# nmcli connection reload NAME UUID TYPE DEVICE eth0 5fb06bd0-0bb0-7ffb-45f1- d6edd65f3e03 ethernet eth0 eth1-static 8f105ed6-1361-8e14-51fd- dedb8ef3510a ethernet eth14.eth1-static 连接配置已经关联了 eth1 物理设备,如果希望修改 IP 地址,可以用如下两种方式;
# 方式一、nmcli modify方式修改然后重载配置 [root@node ~]# nmcli modify eth1-static ipv4.address 10.0.0.233/24 [root@node ~]# nmcli down eth1-static && nmcli up eth1-static # 方式二、vim修改,先reload,然后重载 [root@node network-scripts]# cat ifcfg- eth1-static ... IPADDR=10.0.0.234 ... [root@node ~]# nmcli connection reload [root@node ~]# nmcli connection down eth1- static && nmcli connection up eth1-static #重启网卡 systemctl restart network
5. 网卡绑定
- 网卡绑定 Bonding
- 1、可以实现网络冗余,避免单点故障;
- 2、可以实现负载均衡,以提升网络的传输能力;
- 网卡绑定实现模式:
- 模式0 balance-rr 负载轮询:两网卡单独是
100MB ,聚合为1个网络传输,则可提升为 200MB - 模式1 active-backup 高可用:两块网卡,其中一
条若断线,另外的线路将会自动顶替
- 模式0 balance-rr 负载轮询:两网卡单独是
5.1 配置round-robin
5.1.1 eth0网卡配置
[root@node ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth0
TYPE=Ethernet
DEVICE=eth0
NAME=eth0
ONBOOT=yes
MASTER=bond0
SLAVE=yes
5.1.2 eth1网卡配置
[root@node ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth1
TYPE=Ethernet
DEVICE=eth1
NAME=eth1
ONBOOT=yes
MASTER=bond0
SLAVE=yes
5.1.3 bond网卡配置
[root@node ~]# cat /etc/sysconfig/network-
scripts/ifcfg-bond0
TYPE=Bond
BOOTPROTO=none
ONBOOT=yes
DEVICE=bond0
NAME=bond0
IPADDR=10.0.0.100
PREFIX=24
GATEWAY=10.0.0.2
DNS1=223.5.5.5
DEFROUTE=yes
BONDING_MASTER=yes
BONDING_OPTS="miimon=200 mode=0" # 检查间
隔时间ms
5.1.4 bond状态检查
[root@node ~]# cat /proc/net/bonding/bond0
Ethernet Channel Bonding Driver: v3.7.1
(April 27, 2011)
Bonding Mode: load balancing (round-robin)
# 模式
MII Status: up
MII Polling Interval (ms): 200
Up Delay (ms): 0
Down Delay (ms): 0
Slave Interface: eth0
MII Status: up
Speed: 1000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: 00:0c:29:aa:8d:2e
Slave queue ID: 0
Slave Interface: eth1
MII Status: up
Speed: 1000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: 00:0c:29:aa:8d:42
Slave queue ID: 0
使用 ethtool 检查网卡传输速率
[root@node ~]# ethtool bond0
Settings for bond0:
Speed: 2000Mb/s # 每秒传输速度
Duplex: Full
5.1.5 bond网卡删除
删除 bond 可以使用 nmcli 命令
[root@node ~]# nmcli connection delete
bond0
5.2 配置active-backup
5.2.1 eth0 网卡配置
[root@node ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth0
TYPE=Ethernet
DEVICE=eth0
NAME=eth0
ONBOOT=yes
MASTER=bond1
SLAVE=yes
5.2.2 eth1网卡配置
[root@node ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth1
TYPE=Ethernet
BOOTPROTO=none
DEVICE=eth1
NAME=eth1
ONBOOT=yes
MASTER=bond1
SLAVE=yes
5.2.3 bond 网卡配置
[root@node ~]# cat /etc/sysconfig/network-scripts/ifcfg-bond1
TYPE=Bond
BOOTPROTO=none
ONBOOT=yes
DEVICE=bond1
NAME=bond1
IPADDR=10.0.0.200
PREFIX=24
GATEWAY=10.0.0.2
DNS1=223.5.5.5
BONDING_MASTER=yes
BONDING_OPTS="miimon=200 mode=1 fail_over_mac=1"
# bond1获取mac地址有两种方式
#1、从第一个活跃网卡中获取mac地址,然后其余的
SLAVE网卡的mac地址都使用该mac地址;
#2、使用fail_over_mac参数,是bond0使用当前
活跃网卡的mac地址,mac地址随着活跃网卡的转换而变。
# fail_over_mac参数在VMWare上是必须配置,物理机
可不用配置;
5.2.4 bond状态检查
[root@node ~]# cat /proc/net/bonding/bond1
Ethernet Channel Bonding Driver: v3.7.1
(April 27, 2011)
Bonding Mode: fault-tolerance (active-
backup) (fail_over_mac active)
Primary Slave: None
Currently Active Slave: eth0
MII Status: up
MII Polling Interval (ms): 200
Up Delay (ms): 0
Down Delay (ms): 0
Slave Interface: eth0
MII Status: up
Speed: 1000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: 00:50:56:38:85:72
Slave queue ID: 0
Slave Interface: eth1
MII Status: up
Speed: 1000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: 00:50:56:25:33:ee
Slave queue ID: 0
5.2.5 bond故障模式
关闭活跃网卡 eth0
[root@node ~]# ifdown eth0
成功断开设备 'eth0'
再次检查状态,会发现备用网卡 eth1 切换为活跃网卡
[root@node ~]# cat /proc/net/bonding/bond1
Ethernet Channel Bonding Driver: v3.7.1
(April 27, 2011)
Bonding Mode: fault-tolerance (active-
backup) (fail_over_mac active)
Primary Slave: None
Currently Active Slave: eth1
MII Status: up
MII Polling Interval (ms): 200
Up Delay (ms): 0
Down Delay (ms): 0
Slave Interface: eth1
MII Status: up
Speed: 1000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: 00:50:56:25:33:ee
Slave queue ID: 0
尝试 ping 该主机,一切正常
64 bytes from 10.0.0.220: icmp_seq=173
ttl=64 time=0.512 ms
64 bytes from 10.0.0.220: icmp_seq=174
ttl=64 time=0.512 ms
64 bytes from 10.0.0.220: icmp_seq=175
ttl=64 time=2.11 ms
6. 网关/路由
6.1 什么是路由
- 路由是指路由器从一个LAN接口上收到数据包,根据
数据包的"目的地址"进行定向并转发到另一个WAN接
口的过程。(跨网络访问的路径选择) - 路由工作包含两个基本的动作:
- 1、确定最佳路径 user ---> LNA-- >route -->WAN -->选最近路线--》 传输
- 2、通过网络传输信息
- 在路由的过程中,后者也称为(数据)交换。交换相
对来说比较简单,而选择路径很复杂。
6.2 为什么需要路由
如果没有路由,就没有办法实现,不同地域的主机互联互通了;
6.3 如何配置路由
- linux系统配置路由使用 route 命令;可以使用
route 命令来显示和管理路由表; - route 命令语法示例:
- route [add|del] [-host|-net|default]
[address[/mask]] [netmask] [gw] [dev]- [add|del] :增加或删除路由条目;
- -host :添加或删除主机路由;
- -net :添加或删除网络路由;
- default :添加或删除默认路由;
- address :添加要去往的网段地址 由
ip+netmask 组成; - gw :指定下一跳地址,要求下一跳地址必须是能
到达的,且一般是和本网段直连的接口。 - dev :将添加路由与对应的接口关联,一般内核额
会自动判断路由应该关联哪个接口;
- route 添加路由命令示例:
[root@node ~]# route add -host 1.1.1.1/32
dev eth0
[root@node ~]# route add -net 1.1.1.1/32
dev eth1
[root@node ~]# route add -net 1.1.1.1/32
gw 1.1.1.2
[root@node ~]# route add default gw
1.1.1.2
6.4 路由的分类
6.4.1 主机路由
- 主机路由作用:指明到某台主机具体应该怎么走;
Destination 精确到某一台主机 - Linux上如何配置主机路由:
# 去往1.1.1.1主机,从eth0接口出
[root@node ~]# route add -host 1.1.1.1/32
dev eth0
# 去往1.1.1.1主机,都交给10.0.0.2转发
[root@node ~]# route add -host 1.1.1.1/32
gw 10.0.0.2
6.4.2 网络路由
- 网络路由作用:指明到某类网络怎么走;
Destination 精确到某一个网段的主机 - Linux上如何配置网络路由:
# 去往2.2.2.0/24网段,从eth0接口出
[root@node ~]# route add -net 2.2.2.0/24
dev eth0
# 去往2.2.2.0/24网段,都交给10.0.0.2转发
[root@node ~]# route add -net 2.2.2.0/24
gw 10.0.0.2
6.4.3 默认路由
- 默认路由:如果匹配不到主机路由、网络路由的,全
部都走默认路由(网关); - Linux上如何配置网络路由:
[root@node ~]# route add -net 0.0.0.0 gw
10.0.0.2
[root@node ~]# route add default gw
10.0.0.2
6.4.4 永久路由
- 使用 route 命令添加的路由,属于临时添加;那如
何添加永久路由条目; - 在 /etc/sysconfig/network-scripts 目录下创建
route-ethx 的网卡名称,添加路由条目
[root@dns-master ~]# cat
/etc/sysconfig/network-scripts/route-eth0
1.1.1.0/24 dev eth0
1.1.1.0/24 via 1.1.1.2
[root@dns-master ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
1.1.1.0 0.0.0.0
255.255.255.0 U 100 0 0
eth0
1.1.1.0 1.1.1.2
255.255.255.0 UG 100 0 0
eth0
6.5 路由项目案例
- 一台Linux主机能够被当成路由器用需要三大前提:
- 1.至少有两块网卡分别连接两个不同的网段;
- 2.开启路由转发功能 /proc/sys/net/ipv4/ip_forward ;
- 3.在 linux 主机添加网关指向该服务器(路由);
6.5.1 环境准备
- 实验环境

- 虚拟机网段配置

6.5.2 虚拟机1网卡配置
1.eth0网卡
[root@vm1 ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth0
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
NAME=eth0
DEVICE=eth0
ONBOOT=yes
IPADDR=10.0.0.100
PREFIX=24
2.eth1网卡
[root@vm1 ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth1
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
NAME=eth1
DEVICE=eth1
ONBOOT=yes
IPADDR=1.1.1.1
PREFIX=24
3.路由信息
[root@vm1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
1.1.1.0 0.0.0.0
255.255.255.0 U 101 0 0
eth1
10.0.0.0 0.0.0.0
255.255.255.0 U 100 0 0
eth0
6.5.3 虚拟机2网卡配置
1.eth0网卡配置
[root@vm2 ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth0
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
NAME=eth0
DEVICE=eth0
ONBOOT=yes
IPADDR=1.1.1.2
PREFIX=24
2.eth1网卡配置
[root@vm2 ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth1
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
NAME=eth1
DEVICE=eth1
ONBOOT=yes
IPADDR=2.2.2.2
PREFIX=24
3.路由信息
[root@vm2 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
1.1.1.0 0.0.0.0
255.255.255.0 U 100 0 0
eth0
2.2.2.0 0.0.0.0
255.255.255.0 U 101 0 0
eth1
6.5.4 虚拟机3网卡配置
1.eth0网卡配置
[root@vm3 ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth0
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
NAME=eth0
DEVICE=eth0
ONBOOT=yes
IPADDR=2.2.2.3
PREFIX=24
2.eth1网卡配置
[root@vm3 ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth1
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
NAME=eth1
DEVICE=eth1
ONBOOT=yes
IPADDR=3.3.3.3
PREFIX=24
3.路由信息
[root@vm3 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
2.2.2.0 0.0.0.0
255.255.255.0 U 100 0 0
eth0
3.3.3.0 0.0.0.0
255.255.255.0 U 101 0 0
eth1
6.5.5 虚拟机4网卡配置
1.eth0网卡配置
[root@vm4 ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth0
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
NAME=eth0
DEVICE=eth0
ONBOOT=yes
IPADDR=3.3.3.4
PREFIX=24
2.eth1网卡配置
[root@vm4 ~]# cat /etc/sysconfig/network-
scripts/ifcfg-eth1
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
NAME=eth1
DEVICE=eth1
ONBOOT=yes
IPADDR=4.4.4.4
PREFIX=24
3.路由信息
[root@vm4 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
3.3.3.0 0.0.0.0
255.255.255.0 U 100 0 0
eth0
4.4.4.0 0.0.0.0
255.255.255.0 U 101 0 0
eth1
6.5.6 场景示例1
-
问:1.1.1.1地址能否与1.1.1.2 互通;
-
可以通,因为本机1.1.1.1与目标主机1.1.1.2 两台机器
处于一个LAN中,并且两台机器上的路由表里具有
Destination指向对方的网段路由条目[root@vm1 ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 10.0.0.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0 1.1.1.0 0.0.0.0 255.255.255.0 U 101 0 0 eth1 [root@vm2 ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 1.1.1.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0 2.2.2.0 0.0.0.0 255.255.255.0 U 101 0 0 eth1- 问:1.1.1.1地址能否与2.2.2.2地址互通
- 答:不能;因为数据包只能送到1.1.1.2,而无法送达
2.2.2.2 - 所以需要添加一条去往2.2.2.0/24网段的路由,从
eth1接口发出即可;
[root@vm1 ~]# route add -net 2.2.2.0/24 dev eth1 [root@vm1 ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 1.1.1.0 0.0.0.0 255.255.255.0 U 101 0 0 eth1 2.2.2.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1 10.0.0.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0 [root@vm1 ~]# ping 2.2.2.2 PING 2.2.2.2 (2.2.2.2) 56(84) bytes of data. 64 bytes from 2.2.2.2: icmp_seq=1 ttl=64 time=0.602 ms 64 bytes from 2.2.2.2: icmp_seq=2 ttl=64 time=1.60 ms
6.5.7 场景示例2
- 问:1.1.1.1地址能否与2.2.2.3地址互通;
- 答:不能;因为数据包只能送到vmnet2交换机,送
不到vmnet3交换机 - 解决方案:将去往2.2.2.0/24网段的数据包交给
1.1.1.2这台主机帮我们转发给2.2.2.3这台主机;
# vm1添加路由
[root@vm1 ~]# route add -net 2.2.2.0/24 gw
1.1.1.2
[root@vm1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
1.1.1.0 0.0.0.0
255.255.255.0 U 101 0 0
eth1
2.2.2.0 1.1.1.2
255.255.255.0 UG 0 0 0
eth1
# vm2开启内核转发(由于vm2上有去往2.2.2.0/24网段
路由,所以添加)
[root@vm2 ~]# echo "1" > /proc/sys/net/ipv4/ip_forward
[root@vm2 ~]# sysctl -p
# vm1测试是否能ping通
[root@vm1 ~]# ping 2.2.2.3
PING 2.2.2.3 (2.2.2.3) 56(84) bytes of
data.
64 bytes from 2.2.2.3: icmp_seq=1 ttl=63
time=0.690 ms
6.5.8 场景示例3
- 问:1.1.1.1地址能否与3.3.3.3地址互通;
- 答:不能;因为数据包只能送到vmnet2交换机,送
不到vmnet3交换机 - 解决方案:
- 1.在vm1主机上将去往3.3.3.0/24网段的数据包交
给1.1.1.2,由这台主机帮我们转发给3.3.3.3; - 2.在vm2上需要添加到3.3.3.0/24网段的路由,然
后开启转发功能,否则数据包无法转发,会被丢弃; - 3.数据包到达vm3主机,但是无法送回来,所以还
需要在vm3主机上添加去往1.1.1.0/24网段的数据
包走2.2.2.2这台主机转发
- 1.在vm1主机上将去往3.3.3.0/24网段的数据包交
# vm1添加路由
[root@vm1 ~]# route add -net 3.3.3.0/24 gw
1.1.1.2
[root@vm1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
3.3.3.0 1.1.1.2
255.255.255.0 UG 0 0 0
eth1
# vm2开启转发,添加路由
[root@vm2 ~]# echo "1" >
/proc/sys/net/ipv4/ip_forward
[root@vm2 ~]# sysctl -p
[root@vm2 ~]# route add -net 3.3.3.0/24
eth1
[root@vm2 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
3.3.3.0 0.0.0.0
255.255.255.0 U 0 0 0
eth1
# vm3添加回包路由
[root@vm3 ~]# route add -net 1.1.1.0/24 gw
2.2.2.2
[root@vm3 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
1.1.1.0 2.2.2.2
255.255.255.0 UG 0 0 0
eth0
#vm1主机测试
[root@vm1 ~]# ping 3.3.3.3
PING 3.3.3.3 (3.3.3.3) 56(84) bytes of data.
64 bytes from 3.3.3.3: icmp_seq=1 ttl=63 time=0.788 ms
6.5.9 场景示例4
- 问:1.1.1.1地址能否与3.3.3.4地址互通;
- 答:不能;因为数据包只能从vmnet2交换机送往
vmnet3交换机,无法达到vmnet4交换机; - 解决方案:
- 1.在vm1主机上将去往3.3.3.0/24网段的数据包交
给1.1.1.2,由这台主机帮我们转发给3.3.3.4; - 2.在vm2上开启转发功能,然后添加到3.3.3.0/24
网段的路由,由2.2.2.3帮我们转发给3.3.3.4; - 3.在vm3上开启转发功能;
- 4.数据包到达vm4主机,但是无法送回来,所以还
需要在vm4主机上添加去往1.1.1.0/24网段的数据
包走3.3.3.3这台主机转发;
- 1.在vm1主机上将去往3.3.3.0/24网段的数据包交
#vm1添加路由
[root@vm1 ~]# route add -net 3.3.3.0/24
gw 1.1.1.2
[root@vm1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
3.3.3.0 1.1.1.2
255.255.255.0 UG 0 0 0
eth1
#vm2开启转发,添加路由规则
[root@vm2 ~]# echo "1" >
/proc/sys/net/ipv4/ip_forward
[root@vm2 ~]# sysctl -p
[root@vm2 ~]# route add -net 3.3.3.0/24
gw 2.2.2.3
[root@vm2 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
3.3.3.0 2.2.2.3
255.255.255.0 UG 0 0 0
eth1
#vm3开启转发
[root@vm3 ~]# echo "1" >
/proc/sys/net/ipv4/ip_forward
[root@vm3 ~]# sysctl -p
#vm4添加回包路由
[root@centos7 ~]# route add -net
1.1.1.0/24 gw 3.3.3.3
[root@centos7 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
1.1.1.0 3.3.3.3
255.255.255.0 UG 0 0 0
eth0
#vm1测试
[root@vm1 ~]# ping 3.3.3.4
PING 3.3.3.4 (3.3.3.4) 56(84) bytes of
data.
64 bytes from 3.3.3.4: icmp_seq=80 ttl=62
time=0.506 ms
64 bytes from 3.3.3.4: icmp_seq=81 ttl=62
time=0.594 ms
6.6 路由条目优化
- 以虚拟机1为例,除了第一个路由条目外,其他的路
由条目其实都需要由1.1.1.2来转发; - 所以我们可以统一用一条路由规则;(配置默认路由)
1.删除vm1上无用的路由;
[root@vm1 ~]# route del -net 2.2.2.0/24
[root@vm1 ~]# route del -net 2.2.2.0/24
# 需要删除两次;因为添加了两次;
[root@vm1 ~]# route del -net 3.3.3.0/24
[root@vm1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
1.1.1.0 0.0.0.0
255.255.255.0 U 101 0 0
eth1
10.0.0.0 0.0.0.0
255.255.255.0 U 100 0 0
eth0
2.配置默认路由
[root@vm1 ~]# route add -net 0.0.0.0/0 gw
1.1.1.2
[root@vm1 ~]# #route add default gw 1.1.1.2
[root@vm1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask
Flags Metric Ref Use Iface
0.0.0.0 1.1.1.2 0.0.0.0
UG 0 0 0 eth1
3.测试效果
[root@vm1 ~]# ping 1.1.1.2
[root@vm1 ~]# ping 2.2.2.2
[root@vm1 ~]# ping 2.2.2.3
[root@vm1 ~]# ping 3.3.3.3
[root@vm1 ~]# ping 3.3.3.4
[root@vm1 ~]# ping 4.4.4.4
4.其他虚拟机按如上方式进行优化即可;
7. Ubuntu网络配置
7.1 配置静态IP地址
- 单网卡配置地址
root@example:~# cat /etc/netplan/00-installer-config.yaml
network:
ethernets:
ens33:
dhcp4: no
dhcp6: no
addresses: [10.0.0.130/24]
gateway4: 10.0.0.2
nameservers:
addresses: [223.5.5.5]
routes: # 静态路由,去往172.100.0.0/24
下一跳是10.0.0.2
- to: 172.100.0.0/24
via: 10.0.0.2
version: 2
root@example:~# sudo netplan apply
- 多网卡配置地址
root@example:~# cat /etc/netplan/00-installer-config.yaml
network:
ethernets:
ens33:
dhcp4: no
dhcp6: no
addresses: [10.0.0.130/24]
gateway4: 10.0.0.2
nameservers:
addresses: [223.5.5.5]
routes:
- to: 172.100.0.0/24
via: 10.0.0.2
ens38:
dhcp4: no
dhcp6: no
addresses: [10.0.0.140/24]
gateway4: 10.0.0.2
nameservers:
addresses: [223.5.5.5]
version: 2
7.2 配置round-robin
root@example:~# cat /etc/netplan/00-
installer-config.yaml
# This is the network config written by
'subiquity'
network:
version: 2
ethernets:
ens33:
dhcp4: no
dhcp6: no
ens38:
dhcp4: no
dhcp6: no
bonds:
bond0:
interfaces:
- ens33
- ens38
addresses: [10.0.0.133/24]
gateway4: 10.0.0.2
nameservers:
addresses: [223.5.5.5,223.6.6.6]
parameters:
mode: balance-rr
mii-monitor-interval: 100
#查看状态
root@example:~# cat /proc/net/bonding/bond0
# 查看速率
root@example:~# ethtool bond0
7.3 配置active-backup
root@example:~# cat /etc/netplan/00-installer-config.yaml
# This is the network config written by
'subiquity'
network:
version: 2
ethernets:
ens33:
dhcp4: no
dhcp6: no
ens38:
dhcp4: no
dhcp6: no
bonds:
bond1:
interfaces:
- ens33
- ens38
addresses: [10.0.0.133/24]
gateway4: 10.0.0.2
nameservers:
addresses: [223.5.5.5,223.6.6.6]
parameters:
mode: active-backup
mii-monitor-interval: 100
# 应用配置
root@example:~# netplan apply
# 尝试关闭正在使用的网卡
root@example:~# ifconfig ens33 down
# 再次查看bond状态
root@example:~# cat /proc/net/bonding/bond1
Bonding Mode: fault-tolerance (active-
backup)
Primary Slave: None
Currently Active Slave: ens38 # ens38
网卡顶替
MII Status: up
MII Polling Interval (ms): 100
Up Delay (ms): 0
Down Delay (ms): 0
Peer Notification Delay (ms): 0
Slave Interface: ens38
MII Status: up
Speed: 1000 Mbps
Duplex: full
Link Failure Count: 1
Permanent HW addr: 00:0c:29:de:3b:6f
Slave queue ID: 0
Slave Interface: ens33
MII Status: down # 接口已经被down
Speed: 1000 Mbps
Duplex: full
Link Failure Count: 2
Permanent HW addr: 00:0c:29:de:3b:65
Slave queue ID: 0
8. 内核参数调优
- 内核参数的调整是为了更好的利用系统资源,以便程序更好的运行;
8.1 ip_local_port_range (必调)
主动连接方(客户端)会占用本地随机端口,
TIME_WAIT 状态会占用本地端口,如果占用过多导致本
地端口不足,TCP连接不能成功建立,可以通过调整参
数来增加本地端口的范围;
1.查看客户端默认可用端口范围
[root@client ~]# sysctl -a |grep
"net.ipv4.ip_local_port_range"
net.ipv4.ip_local_port_range = 32768 60999
2.调整端口数量,测试端口不够用情况;
[root@client ~]# sysctl -w
net.ipv4.ip_local_port_range="10000 10002"
3.准备两台服务器,一台 nginx 服务器,客户端使用
curl 来访问服务器并主动关闭连接,在客户端产生
TIME_WAIT 状态的;服务器: 10.0.0.100 nginx 、客户端: 10.0.0.99 client
# 客户端脚本
[root@client ~]# cat test.sh
#!/usr/bin/bash
ip=10.0.0.100
date
for i in `seq 1 3`
do
echo "第 $i 次 curl "
curl -s http://$ip/ -o /dev/null
echo "RETURN: " $?
ss -ant |grep TIME
done
# 只有当 socket 距离上次收到数据包已经超过1秒时,
端口才会被重用
sleep 2
echo "第 4 次 curl "
date
curl -s http://$ip/ -o /dev/null
echo "RETURN: " $?
ss -ant|grep TIME
4.执行脚本,从结果可见第4次 curl 时的状态为7,失
败,无法正常 curl ,说明端口已经被占用完。
[root@client ~]# sh test.sh
2021年 07月 28日 星期三 14:21:52 CST
第 1 次 curl
RETURN: 0
TIME-WAIT 0 0 10.0.0.99:10000
10.0.0.100:80
第 2 次 curl
RETURN: 0
TIME-WAIT 0 0 10.0.0.99:10002
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:10000
10.0.0.100:80
第 3 次 curl
RETURN: 0
TIME-WAIT 0 0 10.0.0.99:10001
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:10002
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:10000
10.0.0.100:80
第 4 次 curl
2021年 07月 28日 星期三 14:21:54 CST
RETURN: 7
TIME-WAIT 0 0 10.0.0.99:10001
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:10002
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:10000
10.0.0.100:80
5.通过调整端口效果有限,因为 TIME_WAIT 需要等待
2MSL 时长,在这个时长内,最多也就能使用
ip_local_port_range 定义的端口范围,其实这些是
不够的,所以我们还可以使用 tcp_tw_reuse 参数来重
用 TIME_WAIT
8.2 tcp_tw_reuse
tw_reuse 表示端口重用,只有当
net.ipv4.tcp_timestamps = 1 ,
net.ipv4.tcp_tw_reuse = 1 两个选项同时开启时,
并且只有当 socket 距离上次收到数据包已经超过1秒
时, tcp_tw_reuse 端口重用才会有效
1.开启 tcp_tw_reuse 以及 tcp_timestamps 内核参数
[root@client ~]# sysctl -w
net.ipv4.tcp_timestamps=1
[root@client ~]# sysctl -w
net.ipv4.tcp_tw_reuse=1
2.再次执行脚本测试
[root@client ~]# sh test.sh
2021年 07月 28日 星期三 14:46:50 CST
第 1 次 curl
RETURN: 0
TIME-WAIT 0 0 10.0.0.99:10001
10.0.0.100:80
第 2 次 curl
RETURN: 0
TIME-WAIT 0 0 10.0.0.99:10003
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:10001
10.0.0.100:80
第 3 次 curl
RETURN: 0
TIME-WAIT 0 0 10.0.0.99:10003
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:10001
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:10002
10.0.0.100:80
第 4 次 curl
2021年 07月 28日 星期三 14:46:52 CST
RETURN: 0 # 这里发现第4次已经return 为0了,代
表端口已经被重用;
TIME-WAIT 0 0 10.0.0.99:10003
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:10001
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:10002
10.0.0.100:80
8.3 tcp_max_tw_buckets
net.ipv4.tcp_max_tw_buckets 参数表示操作系统允
许 TIME_WAIT 数量的最大值,如果超过这个数字,
TIME_WAIT 套接字将立刻被清除,该参数默认为
180000 ,可以对其进行调整,确保 time-wait 状态不消
耗太多的连接,以保证新连接可以正常请求;
1.参数调整
[root@client ~]# sysctl -w
net.ipv4.tcp_max_tw_buckets=2
2.测试验证
[root@client ~]# sh test.sh
2021年 07月 28日 星期三 15:20:40 CST
第 1 次 curl
RETURN: 0
TIME-WAIT 0 0 10.0.0.99:12792
10.0.0.100:80
第 2 次 curl
RETURN: 0
TIME-WAIT 0 0 10.0.0.99:12794
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:12792
10.0.0.100:80
第 3 次 curl
RETURN: 0
TIME-WAIT 0 0 10.0.0.99:12794
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:12792
10.0.0.100:80
第 4 次 curl
2021年 07月 28日 星期三 15:20:42 CST
RETURN: 0
TIME-WAIT 0 0 10.0.0.99:12794
10.0.0.100:80
TIME-WAIT 0 0 10.0.0.99:12792
10.0.0.100:80
TCP: time wait bucket table overflow
TCP: time wait bucket table overflow
TCP: time wait bucket table overflow
8.4 tcp_max_syn_backlog
一般我们将 ESTABLISHED 状态的连接称为全连接,而将
SYN_RCVD 状态的连接称为半连接, backlog 定义了处
于 SYN_RECV 的 TCP 最大连接数,当处于 SYN_RECV 状态
的 TCP 连接数超过 tcp_max_syn_backlog 后,会丢弃后
续的 SYN 报文(也就是半连接池最大可接受的请求)关
闭cookies,否则容易干扰,造成不生效的情况。

当服务器收到一个 SYN 后,它创建一个子连接加入到
SYN_RCVD 队列。在收到 ACK 后,它将这个子连接移动到
ESTABLISHED 队列。最后当用户调用 accept() 时,会
将连接从 ESTABLISHED 队列取出。
1.调整服务端参数
[root@oldxu ~]# sysctl -w
net.ipv4.tcp_max_syn_backlog=2
2.客户端执行如下操作
# 禁止客户端返回ack,模拟服务端SYN_RECV状态
[root@client ~]# iptables -t filter -I
OUTPUT -p tcp --sport 22 -j ACCEPT
[root@client ~]# iptables -t filter -A
OUTPUT -p tcp -m tcp --tcp-flag SYN,ACK ACK
-j DROP
# 使用telnet连接远程主机
[root@client ~]# telnet 10.0.0.100 22 &
[1] 11913
[root@client ~]# telnet 10.0.0.100 22 &
[2] 11916
[root@client ~]# telnet 10.0.0.100 22 &
[3] 11917
[root@client ~]# telnet 10.0.0.100 22 &
[4] 12012
[root@client ~]# Trying 10.0.0.100...
3.检查服务端连接状态
[root@web01 ~]# netstat -tn
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address
Foreign Address State
tcp 0 0 10.0.0.100:22
10.0.0.99:17304 SYN_RECV
tcp 0 0 10.0.0.100:22
10.0.0.99:17302 SYN_RECV
tcp 0 0 10.0.0.100:22
10.0.0.99:17300 SYN_RECV
# 内核会提示丢弃了一些请求
[root@web01 ~]# dmesg
[31204.380052] TCP: drop open request from
10.0.0.99/17320
[31205.382226] TCP: drop open request from
10.0.0.99/17320
-
注意: SYN_RECV 有3条记录,我们调整的限制2,怎
么多出了一条;是因为系统的判断条件是 > 而不是>= ,所以当达到3条记录时才算超过限制,所以有3
条 SYN_RECV 记录;
8.5 core_somaxconn
net.core.somaxconn 用于定义服务端全连接队列的大
小,默认为128,对于生产环境而言,肯定是不够用;

1.调整服务端全连接队列大小为3
[root@server ~]# sysctl -w
net.core.somaxconn=2
2.服务端脚本
[root@server ~]# cat server.c
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
#define BACKLOG 200
int main(int argc, char **argv)
{
int listenfd;
int connfd;
struct sockaddr_in servaddr;
listenfd = socket(PF_INET, SOCK_STREAM,
0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr =
htonl(INADDR_ANY);
servaddr.sin_port = htons(50001);
bind(listenfd, (struct sockaddr
*)&servaddr, sizeof(servaddr));
listen(listenfd, BACKLOG);
while(1)
{
sleep(1);
}
return 0;
}
3.编译并启动服务端脚本
[root@server ~]# gcc server.c -o server
[root@server ~]# ./server
4.编写客户端脚本
[root@client ~]# cat client.c
#include <stdio.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
int main(int argc, char **argv)
{
int sockfd;
struct sockaddr_in servaddr;
sockfd = socket(PF_INET, SOCK_STREAM,
0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(50001);
servaddr.sin_addr.s_addr =
inet_addr("10.0.0.100");
if (0 != connect(sockfd, (struct
sockaddr *)&servaddr, sizeof(servaddr)))
{
printf("connect failed!\n");
}
else
{
printf("connect succeed!\n");
}
sleep(30);
return 1;
}
5.编译并启动客户端脚本
[root@client ~]# gcc client.c -o client
[root@client ~]# ./client &
[1] 16368
[root@client ~]# connect succeed!
./client &
[2] 16370
[root@client ~]# connect succeed!
./client &
[3] 16371
[root@client ~]# connect succeed!
./client &
[4] 16372
[root@client ~]# connect succeed!
./client &
[5] 16375
[root@client ~]# connect succeed!
5.检查服务端状态(会发现已建立连接队列就3条,其余
都在半连接池中无法进入连接队列)
[root@server ~]# netstat -nt | grep 50001
tcp 0 0 10.0.0.100:50001
10.0.0.99:17405 SYN_RECV
tcp 0 0 10.0.0.100:50001
10.0.0.99:17407 SYN_RECV
tcp 0 0 10.0.0.100:50001
10.0.0.99:17399 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17403 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17401 ESTABLISHED
6.调整全连接队列大小,然后再次启动多次客户端进行查看
[root@server ~]# sysctl -w
net.core.somaxconn=10
[root@web01 ~]# ./server
# 查看服务端连接状态
[root@server ~]# netstat -nt | grep 50001
tcp 0 0 10.0.0.100:50001
10.0.0.99:17431 SYN_RECV
tcp 0 0 10.0.0.100:50001
10.0.0.99:17433 SYN_RECV
tcp 0 0 10.0.0.100:50001
10.0.0.99:17425 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17417 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17419 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17415 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17421 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17409 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17429 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17411 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17413 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17427 ESTABLISHED
tcp 0 0 10.0.0.100:50001
10.0.0.99:17423 ESTABLISHED
# 全连接队列11条记录,之所以会这样,是因为系统采用>
而>=所以条目会+1
[root@server ~]# netstat -nt | grep 50001
|wc -l
13
8.6 tcp_syn_retries
net.ipv4.tcp_syn_retries 表示应用程序进行发送
SYN 包时,在对方不返回 SYN + ACK 的情况下,内核默
认重试发送 6 次 SYN 包,也就是说如果一直收不到对方返
回 SYN + ACK 那么应用程序最大的超时时间就是
(1+2+4+8+16+32+64=127 秒) 这对于很多客户端而言
是很难以接受的;
- 第 1 次发送 SYN 报文后等待 1s(2^0) ,如果超
时,则重试 - 第 2 次发送后等待 2s(2^1) ,如果超时,则重试
- 第 3 次发送后等待 4s(2^2) ,如果超时,则重试
- 第 4 次发送后等待 8s(2^3) ,如果超时,则重试
- 第 5 次发送后等待 16s(2^4) ,如果超时,则重试
- 第 6 次发送后等待 32s(2^5) ,如果超时,则重试
- 第 7 次发送后等待 64s(2^6) ,如果超时,则超时
失败
1.服务端配置 iptables 来丢弃指定端口的 SYN 报文
# 进来流量如果syn标志位为1则拒绝
[root@server ~]# iptables -A INPUT -p tcp -
-dport 22 --syn -j DROP
# 服务端使用tcpdump抓包
[root@server ~]# tcpdump -i eth0 -n src
10.0.0.99 and dst 10.0.0.100 and port 22
2.然后客户端使用 telnet 连接服务端指定端口
[root@client ~]# date '+ %F %T'; telnet
10.0.0.100 22; date '+ %F %T';
2021-07-29 23:32:57 # 开始时间
Trying 10.0.0.100...
telnet: connect to address 10.0.0.100:
Connection timed out
2021-07-29 23:35:05 # 结束时间
3.最后分析抓包结果,从 tcpdump 的输出也可以看到,一
共发了7次SYN包(都是同一个seq号码),第一次是正常请
求,后面6次是重试,正是该内核参数设置的值.
[root@server ~]# tcpdump -i eth0 -n src
10.0.0.7 and dst 10.0.0.100 and port 22
23:32:57.809282 IP 10.0.0.99.ndmp >
10.0.0.100.ssh: Flags [S], seq 2633109385,
23:32:58.812226 IP 10.0.0.99.ndmp >
10.0.0.100.ssh: Flags [S], seq 2633109385,
23:33:00.816151 IP 10.0.0.99.ndmp >
10.0.0.100.ssh: Flags [S], seq 2633109385,
23:33:04.820449 IP 10.0.0.99.ndmp >
10.0.0.100.ssh: Flags [S], seq 2633109385,
23:33:12.837846 IP 10.0.0.99.ndmp >
10.0.0.100.ssh: Flags [S], seq 2633109385,
23:33:28.884418 IP 10.0.0.99.ndmp >
10.0.0.100.ssh: Flags [S], seq 2633109385,
23:34:00.942801 IP 10.0.0.99.ndmp >
10.0.0.100.ssh: Flags [S], seq 2633109385,
4.修改客户后端重试次数,在测试
[root@client ~]# sysctl -w
net.ipv4.tcp_syn_retries=2
# 再次测试
[root@client ~]# date '+ %F %T'; telnet
10.0.0.100 22; date '+ %F %T';
2021-07-29 23:39:15 # 起始时间
Trying 10.0.0.100...
2021-07-29 23:39:22 # 结束时间
- 注意:作为代理服务器这个值就应该调整
8.7 内核参数示例
[root@oldxu ~]# vim /etc/sysct.conf
# tcp优化
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1 # 防止
SYN Flood攻击,开启后max_syn_backlog理论上没有
最大值
net.ipv4.tcp_max_syn_backlog = 8192 # SYN半
连接队列可存储的最大值
net.core.somaxconn = 32768 # SYN全
连接队列可存储的最大值
# 修改TCP TIME-WAIT超时时间
https://help.aliyun.com/document_detail/155
470.html
# net.ipv4.tcp_tw_timeout = 5
# 重试
net.ipv4.tcp_syn_retries=2 # 发送
SYN包重试次数,默认6
net.ipv4.tcp_synack_retries = 2 # 返回
syn+ack重试次数,默认5
# 其他
# net.ipv4.ip_forward = 1 # 支持转
发功能;
# net.ipv4.ip_nonlocal_bind = 1 # 如果我
的应用程序需要绑定端口,需要指明具体的IP地址
# net.ipv4.tcp_keepalive_time = 600 # 当
keepalive启动时,TCP发送keepalive消息的频度;默
认是2小时,将其设置为10分钟,可更快的清理无效链接
# 系统中允许存在文件句柄最大数目(系统级)
fs.file-max = 204800
#
vm.swappiness = 0
本文来自博客园,作者:GaoBeier,转载请注明原文链接:https://www.cnblogs.com/gao0722/p/15087005.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号