
12.Linux进程管理
12.Linux进程管理
1.进程基本概述
1.1 程序与进程
- 什么是程序:开发编写的源代码,封装为产品,比如
(微信、钉钉、等等)都称为程序(硬盘); - 什么是进程:程序运行的过程,我们称为进程,它主
要是用来控制计算机硬件运行我们的程序; - 程序与进程区别:
- 程序:程序是数据+指令的集合,是一个静态的概
念,同时程序可以长期存在系统中; - 进程:进程是程序运行的过程,是一个动态的概
念,在进程运行的过程中,系统会有各种指标来表
示当前运行的状态,同时进程会随着程序的终止而
销毁,不会永久存在系统中;
- 程序:程序是数据+指令的集合,是一个静态的概
1.2 进程与线程
-
假设需要运行”360安全卫士“程序,会进行资源申请,
首先系统申请一块内存空间、然后从硬盘中将代码读
取到内存、最后进行其他资源的申请,这个申请资源
的过程,我们称为进程(资源单位); -
当运行该进程中的"病毒扫描、漏洞查找、垃圾清
理"等功能,通常我们会将该功能称为进程中的线程,
线程是运行代码的过程,它是一个(执行单位),是
进程中的更细的单位,如果该进程有多个线程,线程与线程之间互相不受影响,同时多线程之间可以实现
数据共享;工厂流水线例子:工厂(操作系统)-->进程(车
间)-->线程(流水线作业)
1.3 并发与并行
- 并发:多个任务看起来是同时运行,这是一种假并行(CPU在任务中来回切换);
- 并行:多个任务是真正的同时运行(并行必须有多核CPU才可以实现);

1.4 进程运行的状态
- 一般来说,进程有三个状态,即就绪状态,运行状态,阻塞状态;
- 运行态:进程占用 CPU ,并在 CPU 上运行;
- 就绪态:进程已经具备运行条件,但需要等待 CPU 的调度才可运行;
- 阻塞态:进程因等待某件事发生而暂时不能运行;

上述三种状态之间转换分为如下几种情况;
- 运行-->阻塞:进程发生 I/O 操作,需等待事件,而继
续无法执行,则进程由运行状态变为阻塞状态; - 阻塞-->就绪:进程所等待的事件已经完成,但没办法
直接运行,需要进入就绪队列,等待调度; - 就绪-->运行:运行的进程时间片已经用完, CPU 会从
就绪队列中选择合适的进程分配 CPU - 运行-->就绪:
- 1、进程占用 CPU 的时间过长,而系统分配给该进
程占用 CPU 的时间是有限的; - 2、当有更高优先级的进程要运行时,该进程需要
让出 CPU ,由运行状态转变为就绪状态;
- 1、进程占用 CPU 的时间过长,而系统分配给该进
- 就绪态-x->阻塞: 已经就绪了,跟阻塞毫无关系;
- 阻塞-->运行:阻塞状态结束,它必须进入就绪队列中,然后等待cpu从队列中挑选进程分配资源;
1.5 进程的生命周期
- 生命周期就是指一个对象的生老病死。用处很广

当父进程接收到任务调度时,会通过fock派生子进程来
处理,那么子进程会继承父进程属性。
1.子进程在处理任务代码时,父进程其实不会进入等
待,其运行过程是由linux系统进行调度的。
2.子进程在处理任务代码后,会执行退出,然后唤醒父
进程来回收子进程的资源。
3.如果子进程在处理任务代码过程中异常退出,而父进
程却没有回收子进程资源,会导致子进程虽然运行实体
已经消失,但仍然在内核的进程表中占据一条记录,长
期下去对于系统资源是一个浪费。(僵尸进程)
4.如果子进程在处理任务过程中,父进程退出了,子进
程没有退出,那么这些子进程就没有父进程来管理了,
由系统的system进程管理。(孤儿进程)
PS: 每个进程都父进程的PPID,子进程则叫PID。
2. 进程运行状态监控
- 程序在运行后,我们需要了解进程的运行状态。查看进程的状态分为:
- 静态查看
- 动态查看
2.1 静态监控进程
- ps -aux 常用组合,查看进程 用户、PID、占用cpu百
分比、占用内存百分比、状态、执行的命令等
2.1.1 每列指标详解
- USER :启动进程的用户
- PID :进程运行的 ID 号
- %CPU :进程占用 CPU 百分比
- %MEM :进程占用内存百分比
- VSZ :进程占用虚拟内存大小 (单位KB)
- RSS :进程占用物理内存实际大小 (单位KB)
- TTY :进程是由哪个终端运行启动的 tty1、pts/0 等? 表示内核程序与终端无关
- STAT :进程运行过程中的状态 man ps (/STATE)
- START :进程的启动时间
- TIME :进程占用 CPU 的总时间(为0表示还没超过秒)
- COMMAND :程序的运行指令, [ ] 属于内核态的进程。 没有 [ ] 属于用户态进程。
2.1.2 查看进程ppid
ppid 指定的是父进程;
[root@node ~]# ps -ef |grep sshd
root 1425 1 0 7月19 ?
00:00:00 /usr/sbin/sshd -D
root 32067 1425 0 7月19 ?
00:00:02 sshd: root@pts/1
root 52604 1425 0 15:53 ?
00:00:01 sshd: root@pts/0
2.1.3 查看进程树结构
通过 pstree 可以查看进程树状结构
-p :选项指定查看某个进程的树状结构
[root@node ~]# pstree -p 1425
sshd(1425)─┬─sshd(32067)───bash(32069)
└─sshd(52604)───bash(52606)─┬─pstree(67809)
├─sleep(67440)
└─sleep(67506)
2.1.4 查看用户进程
1.使用普通用户运行进程
[root@node ~]# su - oldxu -c "sleep 10000" &
[3] 68021
2.使用 pgrep 过滤用户运行进程名称,以及进程ID
[root@node ~]# pgrep -l -u oldxu
68022 sleep
# -a:表示列出进程pid以及详细命令
[root@node ~]# pgrep -a -u oldxu
68022 sleep 10000
2.1.5 STAT运行状态
- STAT 状态的 S、Ss、S+、R、R+、S+ 等等,都是什么
意思?
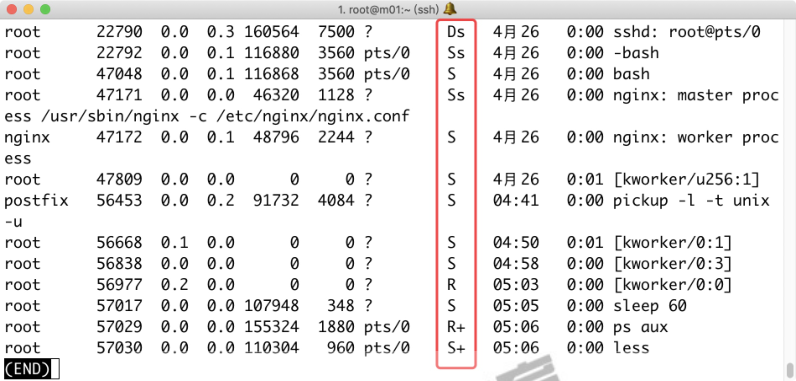
| STAT基本状态 | 描述 | STAT状态+符号 | 描述 |
|---|---|---|---|
| R | 进程运行 | s | 进程是控制进程,Ss是父进程 |
| S | 就绪状态 | < | 进程运行在高优先级上S< |
| T | 进程被暂停 | N | 进程运行在低优先级上SN |
| D | 不可中断进程 | + | 当前进程运行在前台,R+ |
| Z | 僵尸进程 | l | 进程是多线程的,Sl表示进程是以线程方式运行 |
2.2 进程状态模拟实践
2.2.1 运行进程状态R
1.编写如下脚本
[root@node ~]# cat > while.sh <<EOF
while true;do ((1+1));done
EOF
2.运行该脚本,检查运行状态是否为 R
[root@node ~]# sh while.sh
[root@node ~]# ps -aux |grep while
root 58784 93.8 0.2 113172 1192
pts/0 R+ 13:30 0:08 sh while.sh
2.2.2 暂停进程状态T
1.在终端1上运行 vim
[root@node ~]# vim new_file
2.在终端2上运行 ps 命令查看状态
[root@node ~]# ps aux|grep new_file # S
表示睡眠模式,+表示前台运行
root 58118 0.4 0.2 151788 5320
pts/1 S+ 22:11 0:00 new_file
root 58120 0.0 0.0 112720 996
pts/0 R+ 22:12 0:00 grep --
color=auto new_file
# 在终端1上挂起vim命令,按下:ctrl+z
3.回到终端2再次运行 ps 命令查看状态
[root@node ~]# ps aux|grep new_file # T表示停止状态
root 58118 0.1 0.2 151788 5320
pts/1 T 22:11 0:00 vim new_file
2.2.3 不可中断进程D
1.使用 tar 打包文件时,可以通过终端不断查看状态,
由 S+,R+、D+
[root@node ~]# tar -czf etc.tar.gz /etc/
/usr/ /var/
[root@node ~]# ps aux|grep tar|grep -v
grep
root 58467 5.5 0.2 127924 5456
pts/1 R+ 22:22 0:04 tar -czf
etc.tar.gz /etc/
[root@node ~]# ps aux|grep tar|grep -v
grep
root 58467 5.5 0.2 127088 4708
pts/1 S+ 22:22 0:03 tar -czf
etc.tar.gz /etc/
[root@node ~]# ps aux|grep tar|grep -v
grep
root 58467 5.6 0.2 127232 4708
pts/1 D+ 22:22 0:03 tar -czf
etc.tar.gz /etc/
2.使用 dd 命令创建磁盘空间,状态会由 R+、D+
[root@node ~]# dd if=/dev/zero
of=/dev/null bs=1000M count=100
# 观察状态
[root@oldxu ~]# ps -aux |grep "/dev/null"
root 5813 40 71.7 113 344 pts/0 D+ 13:32
0:13 dd if=/dev/zero of=/dev/null bs=1000M
count=100
2.2.4 实践僵尸进程Z
1.编写 Python 脚本,模拟僵尸进程;
[root@node ~]# cat zombie.py
#!/usr/bin/env python
# encoding: utf-8
from multiprocessing import Process
import time
import os
def task():
print("子进程ID --> %s" % os.getpid())
time.sleep(10)
if __name__ == "__main__":
for i in range(3):
p=Process(target=task)
p.start()
print("父进程ID --> %s" % os.getpid())
time.sleep(100000)
2.运行 python 脚本
[root@node ~]# python zombile.py
父进程ID --> 59220
子进程ID --> 59221
子进程ID --> 59222
子进程ID --> 59223
3.通过 ps aux 查看进程状态;
[root@node ~]# ps -aux |grep python
root 59220 0.0 1.2 151200 5772
pts/0 S+ 13:36 0:00 python
zombile.py
root 59221 0.0 0.0 0 0
pts/0 Z+ 13:36 0:00 [python]
<defunct>
root 59222 0.0 0.0 0 0
pts/0 Z+ 13:36 0:00 [python]
<defunct>
root 59223 0.0 0.0 0 0
pts/0 Z+ 13:36 0:00 [python]
<defunct>
4.僵尸进程无法杀死,只能通过杀父进程,从而回收掉
僵尸进程
# kill僵尸进程没有反应,所以直接kill父进程
[root@node ~]# kill -9 59220
2.2.5 实践孤儿进程
1.在窗口1执行如下命令
[root@node ~]# ping www.baidu.com
&>/dev/null &
[1] 52428
2.在窗口2过滤 ping 进程,杀死其父进程
[root@node ~]# ps -ef | grep ping | grep -
v grep
root 52428 52407 0 20:45 pts/0
00:00:00 ping www.baidu.com
# 强制杀死父进程
[root@node ~]# kill -9 52407
3.再次查看进程,会发现该进程被系统最高进程 pid 1接管
# 孤儿进程被PID为1的父进程接管
[root@node ~]# ps -ef | grep ping
root 52428 1 0 20:45 ?
00:00:00 ping 10.0.0.2
# 直接kill进程即可关闭
[root@node ~]# kill 52428
2.2.6 实践多线程SI
1.使用 python 脚本编写多线程程序
[root@node ~]# cat multi_thread.py
#!/usr/bin/env python
from threading import Thread
import time
import os
def task():
time.sleep(200)
if __name__ == "__main__":
print(os.getpid())
for i in range(10):
s=Thread(target=task)
s.start()
2.运行 python 脚本程序
[root@node ~]# python multi_thread.py
59691
3.检查 python 程序状态
# sl表示多线程
[root@node ~]# ps aux|grep python
root 59691 0.0 1.0 740280 5000
pts/1 Sl+ 13:43 0:00 python
multi_thread.py
# 通过pstree查看线程
[root@node ~]# pstree -p 59691
python(59691)─┬─{python}(59692)
├─{python}(59693)
├─{python}(59694)
├─{python}(59695)
├─{python}(59696)
├─{python}(59697)
├─{python}(59698)
├─{python}(59699)
├─{python}(59700)
└─{python}(59701)
2.2.7 高优先级进程S<
1.执行如下命令,让进程在高优先级下运行
[root@node ~]# nice -n -20 sleep 30000 &
[1] 67440
2.查看进程状态,看是否在高优先级下运行
[root@node ~]# ps -aux |grep sleep
root 67440 0.0 0.0 107948 352
pts/0 S< 20:20 0:00 sleep 30000
2.2.8 低优先级进程SN
1.执行如下命令,让进程在低优先级下运行
[root@node ~]# nice -n 20 sleep 50000 &
[2] 67506
2.查看进程状态,看是否在低优先级下运行
[root@node ~]# ps -aux |grep sleep
root 67506 0.0 0.0 107948 352
pts/0 SN 20:21 0:00 sleep 50000
2.3 动态监控进程top
- 使用 top 命令查看当前的进程状态(动态)
2.3.1 top命令选项
- 执行 top 命令时可以指定的命令选项
- -d :刷新时间
- -p :指定 pid
- -u :指定用户
- 示例用法:
# 仅查看指定进程动态详情
[root@node ~]# top -d 1 -p pid
[root@node ~]# top -d 1 -p $(pgrep nginx)
# 动态查看oldxu运行的进程
[root@node ~]# top -d 1 -u oldxu
2.3.2 top内部选项
- 执行 top 后可使用的选项
- c :改变top刷新频率(一般不建议设定)
- P :按CPU进行排序;
- M :以内存进行排序;
- R :对排序后的结果进行倒序;
- f :自定义显示的字段,比如打印ppid
- k :指定杀死某个id
- 1 :显示cpu核心数
- z :以高亮显示数据
- b :高亮显示处于R状态的进程
2.3.3 top字段含义

- top 字段含义
- Tasks: 129 total :当然进程的总数
- 1 running :正在运行的进程数量
- 128 sleeping :睡眠的进程数量
- 0 stopped :停止的进程数量
- 0 zombie :僵尸进程数量
- %Cpu(s) 含义
- 0.7 us : 系统用户进程使用 CPU 百分比
- 0.7 sy :内核中的进程占用 CPU 百分比,通常内核是于硬件进行交互
- 98.7 id :空闲 CPU 的百分比
- 0.0 wa : CPU 等待IO完成的时间
- 0.0 hi :硬中断,占的 CPU 百分比
- 0.0 si :软中断,占的 CPU 百分比
- 0.0 st :比如虚拟机占用物理 CPU 的时间
2.3.4 如何理解中断
- 内存计算公式:
- buffer/cache 是否可以释放: 手动释放:
total: 总内存计算公式:used + free + buffer
+ cache = total
used: 已使用内存计算公式:total - free -
buffers - cache = used(包含share)
free: 未被使用的内存计算公式:total - used -
buffer - cache = free
available: 可获得内存计算公式: free +
(buffer+cache可释放的空间) = available 启
动新的程序能用的内存
buffer: 写缓冲;
cache: 读缓存;
share: 共享内存,属于被分配的内存
需要注意:
free表示的是当前完全没有被程序使用的内存;
而cache在有需要时,是可以被释放出来以供其它
进程使用的;
而available才真正表明系统目前可以提供给应用
程序使用的内存;
# 内存清理 手动释放
sync
echo 3>/proc/sys/vm/drop_caches 改变了文件最后修改时间;
3.管理进程状态
当程序运行为进程,如果需要关闭进程,则需要使用
kill、killall,pkill 等命令对进程ID发送关闭信号
3.1系统支持的信号
- 使用 kill -l 列出当前系统所支持的信号、虽然支持
的信号很多,但我们仅以最常用的3个信号为例- 1(SIGHUP) :通常用来重新加载配置文件
- 9(SIGKILL) :强制杀死进程
- 15(SIGTERM) :终止进程,默认kill信号
3.2 关闭进程kill
1.安装 vsftpd 服务,然后启动;
[root@node ~]# yum -y install vsftpd
[root@node ~]# systemctl start vsftpd
2.修改 vsftpd 的配置文件,然后发送重载信号;
# 改变路径
[root@node ~]# echo "anon_root=/data" >> /etc/vsftpd/vsftpd.conf
# 重载服务
[root@node ~]# kill -1 81379
3.发送停止进程信号
[root@node ~]# kill -15 9160
4.发送强制停止信号,当无法停止服务时,可强制终止信号(慎用.对于'不可中断状态的进程' 强行结束会出问题)
[root@node ~]# kill -9 9160
3.3 关闭进程pkill
1.通过 pkill、killall 指定进程服务名称,然后将其进程关闭
[root@node ~]# pkill nginx
[root@node ~]# killall nginx
2.使用 pkill 将远程连接用户 t 下线
[root@node ~]# pkill -9 -t pts/0
4.进程优先级
4.1 什么是进程优先级
- 优先级指的是优先享受资源,比如排队买票时,军人优先、老人优先。等等
- 系统优先级:优先使用cpu资源;
4.2 为何需要优先级
- 举个例子:海底捞火锅正常情况下响应就特别慢,那
么当节假日时人员突增会导致处理请求特别慢;- 那假设我是海底捞VIP客户(最高优先级),无论多么繁忙,我都无需排队,海底捞人员会直接服务于我,满足我的需求。
- 如果我不是VIP的人员(较低优先级)则进入排队等待状态;
4.3 进程如何配置优先级
- 在启动进程时,为不同的进程使用不同的调度策略。
- nice 值越高: 表示优先级越低,例如 +19 ,该进程容易将 CPU 使用量让给其他进程;
- nice 值越低: 表示优先级越高,例如 -20 ,该进程不倾向于让出 CPU ;
4.4 进程优先级如何查看
1.使用 top 命令查看优先级;
# NI:显示nice值,默认是0。
# PR: 显示nice值,-20映射到0,+19映射到39
PID USER PR NI VIRT RES SHR
S %CPU %MEM TIME+ COMMAND
1083 root 20 0 298628 2808 1544
S 0.3 0.1 2:49.28 vmtoolsd
5 root 0 -20 0 0 0
S 0.0 0.0 0:00.00 kworker/0:+
2.使用 ps 命令查看进程优先级;
[root@node ~]# vim
[root@node ~]# ps axo command,nice |grep
vim|grep -v grep
vim
4.5 指定进程启动优先级nice
1.启动 vim 并且指定程序优先级为 -5
[root@node ~]# nice -n -5 vim &
[1] 98417
2.查看当前 vim 进程的优先级
[root@node ~]# ps axo pid,command,nice
|grep 98417
98417 vim -5
4.6 修改进程优先级renice
1.查看当前正在运行的 sshd 进程优先级状态
[root@node ~]# ps axo pid,command,nice |grep [s]shd
70840 sshd: root@pts/2 0
98002 /usr/sbin/sshd -D 0
2.调整 sshd 主进程的优先级
[root@node ~]# renice -n -20 98002
98002 (process ID) old priority 0, new
priority -20
3.调整之后需要退出终端,重新打开一个新终端
[root@node ~]# ps axo pid,command,nice
|grep [s]shd
70840 sshd: root@pts/2 0
98002 /usr/sbin/sshd -D -20
[root@node ~]# exit
4.再次登陆 sshd 服务,会由主进程 fork 子 sshd 进程(那么子进程会继承主进程的优先级)
[root@node ~]# ps axo pid,command,nice
|grep [s]shd
98002 /usr/sbin/sshd -D -20
98122 sshd: root@pts/0 -20
5. 后台进程管理
5.1 什么是后台进程
通常进程都会在终端前台运行,一旦关闭终端,进程也
会随着结束;
那么此时我们就希望进程能在后台运行,就是将在前台
运行的进程放入后台运行,这样及时我们关闭了终端也
不影响进程的正常运行。
5.2 为什么需要后台运行
比如:我们此前在国内服务器往国外服务器传输大文件
时,由于网络的问题需要传输很久,如果在传输的过程
中出现网络抖动或者不小心关闭了终端则会导致传输失
败,如果能将传输的进程放入后台,是不是就能解决此
类问题了。
5.3 如何将进程转为后台
早期的时候大家都选择使用 nohup + & 符号将进程放入
后台,然后在使用 jobs、bg、fg 等方式查看进程状
态,但太麻烦了 也不直观,所以我们推荐使用
screen
5.3.1 nohup方式
1.使用 nohup 将前台进程转换后台运行
[root@node ~]# nohup sleep 3000 &
2.查看进程运行情况
[root@node ~]# ps aux |grep sleep
root 75118 74766 0 11:10 pts/0
00:00:00 sleep 3000
3.使用 job bg fg 等方式查看后台作业
[root@node ~]# jobs # 查看后台作业
[1]+ Running sleep 3000 &
[root@ansible ~]# fg %1 # 转为前台运行
[root@ansible ~]# bg %1 # 转为后台运行
5.3.2 screen方式
1.安装 screen 工具
[root@web ~]# yum install screen -y
2.开启一个 screen 子窗口,可以通过 -S 为其指定名称
[root@web ~]# screen -S wget_soft
3.在 screen 窗口中执行任务,可以执行前台运行的任务
4.平滑退出 screen ,但不会终止 screen 中的前台任务
# ctrl+a+d
5.查看当前有多少 screen 正在运行
[root@web ~]# screen -list
There is a screen on:
22058.wget_soft (Detached)
1 Socket in /var/run/screen/S-root.
6.可以通过 screen 的id 或 screen 的标签名称进入
[root@web ~]# screen -r wget_soft
[root@web ~]# screen -r 22058
[root@web ~]# exit # 退出进程,结束screen
6.系统平均负载
- 每次发现系统变慢时,通常做的第一件事,就是执行
top 或 uptime 来了解系统的负载情况。 - 比如像下面这样,我在命令行里输入了 uptime 命
令,系统也随即给出了结果
[root@node ~]# uptime
04:49:26 up 2 days, 2:33, 2 users, load
average: 0.70, 0.04, 0.05
# 前面几列,它们分别是当前时间、系统运行时间以及正在
登录用户数。
# 而最后三个数字呢,依次则是过去 1 分钟、5 分钟、15
分钟的平均负载(Load Average)
6.1 什么是平均负载
- 平均负载是单位时间内的 CPU 使用率吗;
- 上面的 0.70 代表 CPU 使用率是 70% 其实不是;
- 那如何理解平均负载:
- 平均负载是指单位时间内,系统处于 可运行状态 和
不可中断状态 的平均进程数,也就是平均活跃进程
数;或者理解"平均负载"是"单位时间内的活跃进程数"; - 平均负载与 CPU 使用率并没有直接关系;
- 平均负载是指单位时间内,系统处于 可运行状态 和
6.1.1 可运行状态
- 可运行状态进程:
- 指正在使用 CPU 或者正在等待 CPU 的进程,也就是
我们 ps 命令看到处于 R,S 状态的进程
6.1.2 不可中断状态
- 不可中断进程:
- 系统中最常见的是等待硬件设备的 I/O 响应,通过
ps 命令中看到 D(Disk Sleep) 的进程。 - 例如:当一个进程向磁盘读写数据时,为了保证数据
的一致性,在得到磁盘回复前,它是不能被其他进程
或者中断打断的,这个时候的进程就处于不可中断状
态。如果此时的进程被打断了,就容易出现磁盘数据
与进程数据不一致的问题; - 所以,不可中断状态实际上是系统对进程和硬件设备
的一种保护机制;
6.2 平均负载为多少时合理
- 理想的状态是每个 CPU 上都刚好运行着一个进程,这
样每个 CPU 都得到了充分利用。 - 所以在评判平均负载时,首先你要知道系统有几个
CPU 通过 top 命令获取,或 /proc/cpuinfo - 示例:假设现在在 4、2、1 核的 CPU 上,如果平均负
载为 2 时,意味着什么;- 1.在4个 CPU 的系统上,意味着 CPU 有 50% 的空
闲; - 2.在2个 CPU 的系统上,意味着所有的 CPU 都刚好
被完全占用; - 3.而1个 CPU 的系统上,则意味着有一半的进程竞
争不到 CPU ;
- 1.在4个 CPU 的系统上,意味着 CPU 有 50% 的空
- 平均负载有三个数值,我们应该关注哪个呢?
- 实际上,平均负载中的三个指标我们其实都需要关
注。(就好比一天的天气要结合起来看;) - 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相
差不大,那就说明系统负载很平稳; - 1分钟的值小于15分钟的值,说明系统最近1分钟的负
载在减少,而过去 15 分钟内却有很大的负载; - 如果 1 分钟的值远大于 15 分钟的值,就说明最近 1
分钟的负载在增加,这种增加有可能只是临时性的,
也有可能还会持续上升,所以就需要持续观察。 - 一旦 1 分钟的平均负载接近或超过了 CPU 的个数,
就意味着系统正在发生过载的问题,这时就得分析问
题,并要想办法优化了; - 例:假设我们在有2个 CPU 系统上看到平均负载为
2.73,6.90,12.98- 那么说明在过去1分钟内,系统有 136% 的超载
(2.73/2=136%) - 而在过去5分钟内,有 345% 的超载
(6.90/2=345%) - 而在过去15分钟内,有 649% 的超载
(12.98/2=649%) - 但从整体趋势来看,系统的负载是在逐步的降低。
- 那么说明在过去1分钟内,系统有 136% 的超载
6.3 平均负载与CPU使用率
- 在实际工作中,我们经常容易把平均负载和 CPU 使
用率混淆,所以在这里,我也做一个区分; - 既然平均负载代表的是活跃进程数,那平均负载高
了,不就意味着 CPU 使用率高吗? - 我们回到平均负载的含义上来,平均负载是指单位时
间内,处于可运行状态和不可中断状态的进程数; - 所以,它不仅包括了正在使用 CPU 的进程,还包括等
待 CPU 和等待 I/O 的进程; - 而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,
跟平均负载并不一定完全对应。比如:- CPU 密集型进程,使用大量 CPU 计算会导致平均负
载升高,此时这两者是一致的; - I/O 密集型进程,等待 I/O 也会导致平均负载升
高,但 CPU 使用率不一定很高; - 大量的 CPU 进程调度也会导致平均负载升高,此时
的 CPU 使用率也会比较高;
- CPU 密集型进程,使用大量 CPU 计算会导致平均负
6.4 平均负载案例分析实战
- 演示这三种常场景,并用 stress、mpstat、
pidstat 等工具,找出平均负载升高的根源; - stress 是 Linux 系统压力测试工具,这里我们用作
异常进程模拟平均负载升高的场景; - mpstat 是多核 CPU 性能分析工具,用来实时查看每
个 CPU 的性能指标,及所有 CPU 的平均指标; - pidstat 是一个常用的进程性能分析工具,用来实时
查看进程的 CPU、Mem、I/O 等性能指标;
# yum install stress sysstat -y
#如果出现无法使用mpstat、pidstat命令查看%wait指标建议更新下软件包
wget http://pagesperso-orange.fr/sebastien.godard/sysstat-11.7.3-1.x86_64.rpm
rpm -Uvh sysstat-11.7.3-1.x86_64.rpm
6.4.1 场景1-CPU密集型进程
1.第一个终端运行 stress 命令,模拟一个 CPU 使用率
100% 的场景:
[root@node ~]# stress --cpu 1 --timeout
600
2.第二个终端运行 uptime 查看平均负载的变化情况
# 使用watch -d 参数表示高亮显示变化的区域(注意负载会持续升高)
[root@node ~]# watch -d uptime
17:27:44 up 2 days, 3:11, 3 users, load
average: 1.10, 0.30, 0.17
3.在第三个终端运行 mpstat 查看 CPU 使用率的变化情况
# -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5秒后输出一组数据
[root@node ~]# mpstat -P ALL 5
Linux 3.10.0-957.1.3.el7.x86_64 (m01)
2019年04月29日 _x86_64_ (1 CPU)
17时32分03秒 CPU %usr %nice %sys
%iowait %irq %soft %steal %guest
%gnice %idle
17时32分08秒 all 99.80 0.00 0.20
0.00 0.00 0.00 0.00 0.00
0.00 0.00
17时32分08秒 0 99.80 0.00 0.20
0.00 0.00 0.00 0.00 0.00
0.00 0.00
#单核CPU所以只有一个all和0
4.从终端二中可以看到,1分钟的平均负载会慢慢增加到
1.00 ,而从终端三中还可以看到,正好有一个 CPU 的
使用率为 100% ,但它的 iowait 为0。这说明,平均负
载的升高正是由于 CPU 使用率为 100% 。那么,到底是
哪个进程导致了 CPU 使用率为 100% 呢?可以使用
pidstat 来查询
# 间隔 5 秒后输出一组数据
[root@node ~]# pidstat -u 5 1
Linux 3.10.0-957.1.3.el7.x86_64 (m01)
2019年04月29日 _x86_64_(1 CPU)
17时33分21秒 UID PID %usr %system
%guest %CPU CPU Command
17时33分26秒 0 110019 98.80 0.00
0.00 98.80 0 stress
#从这里可以明显看到,stress 进程的 CPU 使用率为
100%。
6.4.2 场景2 -I/O密集型进程
1.在第一个终端运行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync
[root@node ~]# stress --io 1 --timeout
600s
2.在第二个终端运行 uptime 查看平均负载的变化情况:
[root@node ~]# watch -d uptime
18:43:51 up 2 days, 4:27, 3 users, load
average: 1.12, 0.65, 0.00
3.最后第三个终端运行 mpstat 查看 CPU 使用率的变化情况:
# 显示所有 CPU 的指标,并在间隔 5 秒输出一组数据
[root@node ~]# mpstat -P ALL 5
Linux 3.10.0-693.2.2.el7.x86_64 (bgx.com)
2019年05月07日 _x86_64_ (1 CPU)
14时20分07秒 CPU %usr %nice %sys
%iowait %irq %soft %steal %guest
%gnice %idle
14时20分12秒 all 0.20 0.00 82.45
17.35 0.00 0.00 0.00 0.00
0.00 0.00
14时20分12秒 0 0.20 0.00 82.45
17.35 0.00 0.00 0.00 0.00
0.00 0.00
#会发现cpu的与内核打交道的sys占用非常高
4.导致 iowait 高,我们需要用 pidstat 来查询
# 间隔 5 秒后输出一组数据,-u 表示 CPU 指标
[root@node ~]# pidstat -u 5 1
Linux 3.10.0-957.1.3.el7.x86_64 (m01)
2019年04月29日 _x86_64_(1 CPU)
18时29分37秒 UID PID %usr %system
%guest %wait %CPU CPU Command
18时29分42秒 0 127259 32.60 0.20
0.00 67.20 32.80 0 stress
18时29分42秒 0 127261 4.60 28.20
0.00 67.20 32.80 0 stress
18时29分42秒 0 127262 4.20 28.60
0.00 67.20 32.80 0 stress
#可以发现,还是 stress 进程导致的。
6.4.3 场景3-大量的进程
1.在第一个终端使用 stress ,但这次模拟的是 4 个进程
[root@node ~]# stress -c 4 --timeout 600
2.由于系统只有 1 个 CPU ,明显比 4 个进程要少得多,因而,系统的 CPU 处于严重过载状态*
[root@node ~]# watch -d uptime
19:11:07 up 2 days, 4:45, 3 users, load
average: 4.65, 2.65, 4.65
3.最后通过 pidstat 查询进程的情况:可以看出 4 个进程在争抢 1 个 CPU 每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达 75% 。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。
# 间隔 5 秒后输出一组数据
[root@node ~]# pidstat -u 5 1
平均时间: UID PID %usr %system
%guest %wait %CPU CPU Command
平均时间: 0 130290 24.55 0.00
0.00 75.25 24.55 - stress
平均时间: 0 130291 24.95 0.00
0.00 75.25 24.95 - stress
平均时间: 0 130292 24.95 0.00
0.00 75.25 24.95 - stress
平均时间: 0 130293 24.75 0.00
0.00 74.65 24.75 - stress
6.4.4 总结
- 分析完这三个案例,我再来归纳一下平均负载与CPU
- 平均负载提供了一个快速查看系统整体性能的手段,
反映了整体的负载情况。但只看平均负载本身,我们
并不能直接发现,到底是哪里出现了瓶颈。所以,在
理解平均负载时,也要注意: - 平均负载高有可能是 CPU 密集型进程导致的;
- 平均负载高并不一定代表 CPU 使用率高,还有可能
是 I/O 更繁忙了; - 当发现负载高的时候,你可以使用 mpstat、pidstat
等工具,辅助分析负载的来源
本文来自博客园,作者:GaoBeier,转载请注明原文链接:https://www.cnblogs.com/gao0722/p/15086962.html

