

Kettle操作学习笔记
许多操作建议去找个视频教程学来的清晰。下面的仅仅是做的重点笔记。
推荐一个很好的视频教程:
尚硅谷 大数据技术之Kettle视频教程
下述笔记基于此教程。
概念
Kettle中有转换和作业。
转换负责数据输入、转换、校验和输出工作,使用转换完成数据ETL(Extract-Transform-Load)的全部工作。转换由步骤构成,如文本文件输入、过滤输出、执行sql脚本等。步骤之间使用Hop连接。Hop定义了一个数据流通道,即数据由一个步骤流跳向下一个步骤。Kettle中数据的最小单位是数据行row,数据流中流动的是缓存的行集Rowset.
作业负责定义一个完成整个工作流的控制。
Kettle是图形界面,主要的操作通过拖拽完成。
kettle转换
输入控件
csv文件输入
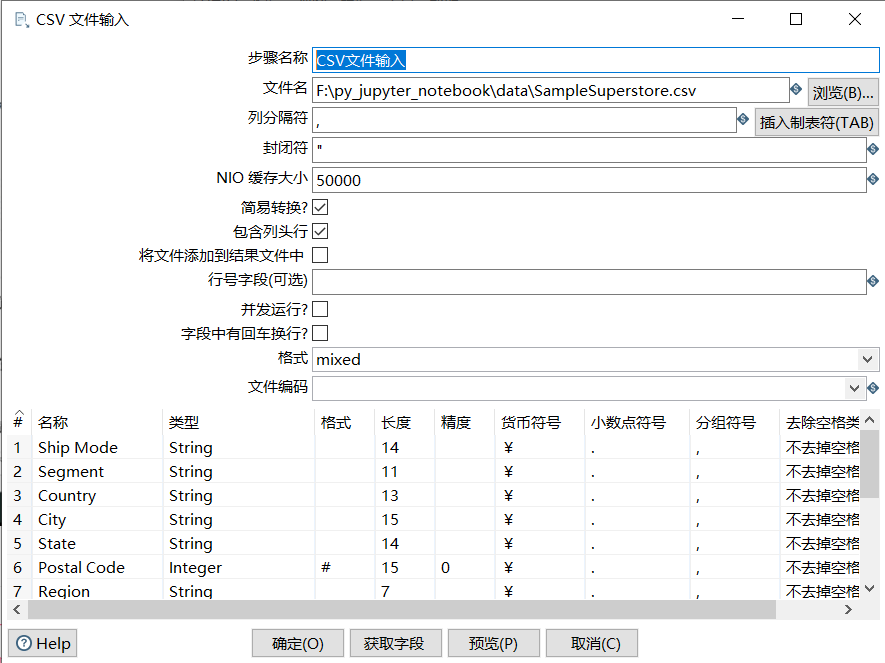
步骤名称:可以修改,但是在同一个转换里面要保证唯一性;
文件名:选择对应的csv文件;
列分隔符:默认是逗号;
封闭符:结束行数据的读写;
NIO缓存大小:文件如果行数过多,需要调整此参数;
包含列头行:意思是文件中第一行是字段名称行,表头不进行读写;
行号字段:如果文件第一行不是字段名称或者需要从某行开始读写,可在此输入行号。
并发运行?:选择并发,可提高读写速度;
字段中有回车换行?:不要选择,会将换行符做数据读出;
文件编码:如果预览数据出现乱码,可更换文件编码;
操作步骤:
- 在Kettle中新建一个转换,然后选择转换下面的“csv文件输入”和“Excel输出”控件。
- 双击CSV文件输入文件控件,在弹出的设置框里找到对应路径里的的csv文件,设置好分隔符、列头行等信息,然后点击下面的获取字段按钮,将我们需要的字段加载到kettle中。
- 按住键盘SHIFT键,并且点击鼠标左键将两个控件链接起来,链接时选择“主输出步骤”。
- 双击Excel输出控件,在弹出的设置框里设置文件输出路径和文件名称,然后点击上面的字段框,依次点击下面的获取字段和最小宽度,获取到输出字段。
- 点击左上角的启动按钮,在弹出的设置框里点击启动,执行该转换。
tips:
kettle下方有执行结果日志。如果报错日志图标下的第一个图标可以查看错误原因。
文本文件输入
例如提取服务器上的日志信息是公司里ETL开发很常见的操作,日志信息基本上都是文本类型。操作步骤:
1.添加需要转换的日志文件。浏览找到目标文件后要点增加!
2.按照日志文件格式,指定分隔符 。
3.获取字段,并给字段设置合适的格式。
4.最后点预览记录,看看能否读到数据。
tips:
- 如果输出的时候,没有选定路径,只是设置了输出文件名,那么这个文件输出位置在启动spoon的文件夹里。(让我好找,本来它提示的文件夹叫LOCAL)
- 输入、输出等一应的设置,不要漏掉其中任何一个操作步骤,不然会报奇怪的错误。尤其是输出时的 内容-获取字段!
excel文件输入
要注意的点:
- 如果是xlsx文件的话,选择Excel 2007 XLSX (Apache POI).在路径中选择好文件以后点击添加。
- 在工作表中选择sheet。如果不做选取则默认全部。
- 获取字段。 就我目前的理解是,字段代表的是输出的新表的表头。
xml输入
<?xml version="1.0" encoding="UTF-8"?>
<students Description="students of atguigu">
<group groupID="1">
<student>
<name>孙悟空</name>
<gender>男</gender>
<age>500</age>
</student>
<student>
<name>猪八戒</name>
<gender>男</gender>
<age>250</age>
</student>
<student>
<name>沙和尚</name>
<gender>男</gender>
<age>150</age>
</student>
</group>
<group groupID="2">
<student>
<name>武大郎</name>
<gender>男</gender>
<age>48</age>
</student>
<student>
<name>潘金莲</name>
<gender>女</gender>
<age>18</age>
</student>
</group>
</students>
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。
XPath 使用路径表达式在 XML 文档中选取节点。

拖入Get data from XML,选取好路径目标文件并增加。
重点在于循环读取路径,/students/group/student
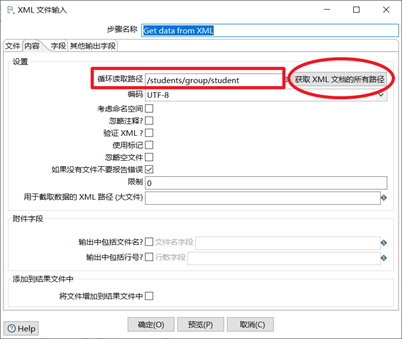
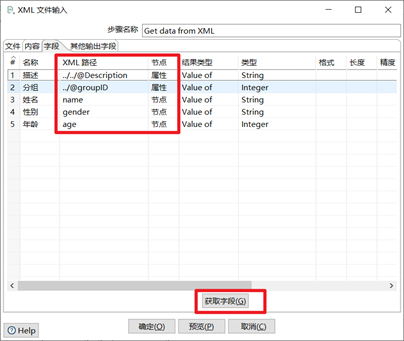
添加描述和分组:
JSON输入
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。JSON对象本质上就是一个JS对象,但是这个对象比较特殊,它可以直接转换为字符串,在不同语言中进行传递,通过工具又可以转换为其他语言中的对象。
JSON核心概念:数组:[ ] 对象:{ } 属性:key:value
JSONPath类似于XPath在xml文档中的定位,JsonPath表达式通常是用来路径检索或设置Json的。其表达式可以接受“dot–notation”(点记法)和“bracket–notation”(括号记法)格式.
点记法:$.store.book[0].title
括号记法:$[‘store’][‘book’][0][‘title’]
文件路径尽量不要有中文,会出现无法读取等错误。
获取字段
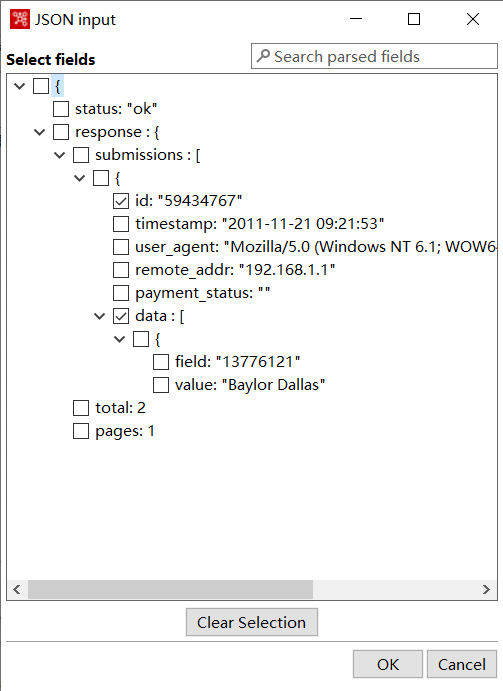
进一步进行第二次剖析:
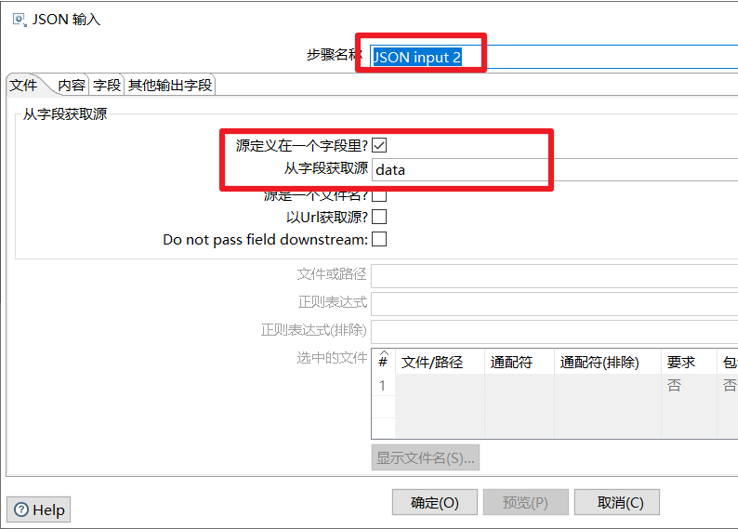
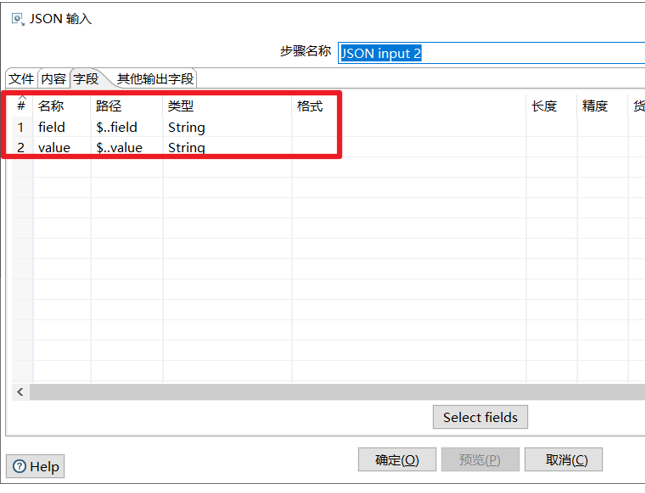
表输入
首先需要完成与mysql的连接。具体可以查看我的另一篇博文:
https://www.cnblogs.com/ganwong/p/17643271.html
数据库连接创建以后,它默认连接仅针对当前转换,可以右键连接,选择共享。当然,不想继续共享可以同样方式取消共享。
表输入里面填入mysql查询语句。
输出控件
xlsx输出
一个奇怪的情况(可能是翻译等的原因):
通过多次尝试,输出里面的Microsoft Excel output输出xls格式,而如果想要输出xlsx格式的,则使用Microsoft Excel writer.
注意后缀不要重复了。
文本文件输出
设置合适的扩展名,比如txt,csv等。
在内容框里设置合适的分隔符,比如分号,逗号,TAB等。
SQL文件输出
SQL文件输出一般跟表输入做连接,然后将数据库表的表结构和数据以sql文件的形式导出,然后做数据库备份的工作。
勾选增加创建表语句,勾选每个语句另起一行,这样更易于阅读。
扩展名默认为sql,不需要更改。
表输入的语句实际上是更具体地操作命令,指定要输出表里的哪些内容。表输出里选择目标表即你需要进行备份输出的表。
表输出
表输出控件可以将kettle数据行中的数据直接写入到数据库中的表中。
选择目标表,目标表可以提前在数据库中手动创建好,也可以输入一个数据库不存在的表,然后点击下面的SQL按钮,利用kettle现场创建。
如果目标表的表结构和输入的数据结构不一致,还可以自己指定数据库字段。
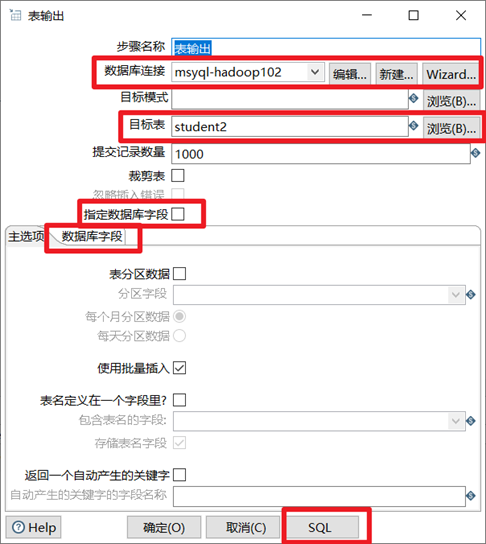
注意勾选指定数据库字段,这样才能获取字段。
更新&插入/更新
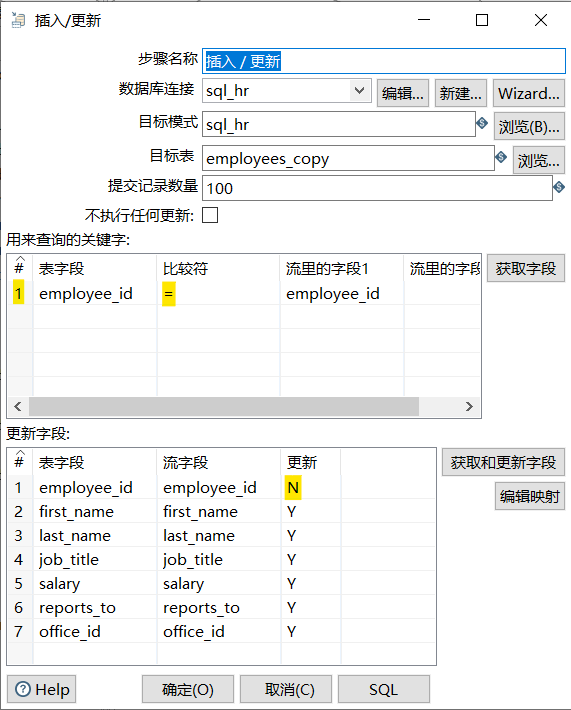
更新和插入/更新,这两个控件是kettle提供的将数据库已经存在的记录与数据流里面的记录进行对比的控件。企业级ETL经常会用到这两个控件来进行数据库更新的操作
两者区别:
更新是将数据库表中的数据和数据流中的数据做对比,如果不同就更新,如果数据流中的数据比数据库表中的数据多,那么就报错。
插入/更新的功能和更新一样,只不过优化了数据不存在就插入的功能,因此企业里更多的也是使用插入/更新。
如果目标表不存在,点击右下角SQL,会创建一个新的目标表。
删除
删除控件可以删除数据库表中指定条件的数据,企业里一般用此控件做数据库表数据删除或者跟另外一个表数据做对比,然后进行去重的操作。
- 选择数据库连接
- 选择目标表
- 设置数据流跟目标表要删除数据的对应字段
例如,表输入里的是表1,在删除步骤的表是表2,那么删除控件是通过对比,将表2中符合条件的数据删除。
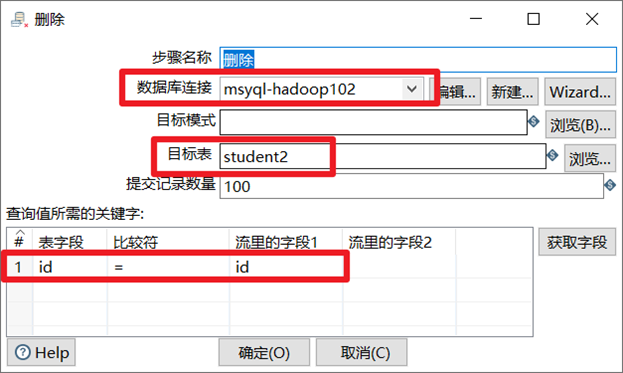
↑删除id相同的数据
转换控件
转换控件是转换里面的第四个分类,转换控件也是转换中的第三大控件,用来转换数据。转换是ETL里面的T(Transform),主要做数据转换,数据清洗的工作。ETL整个过程中,Transform的工作量最大,耗费的时间也比较久,大概可以占到整个ETL的三分之二。
由于Kettle中自带的转换控件比较多,本文只挑出开发中经常使用的几个转换控件来进行学习。
Concat fields
转换控件Concat fields,顾名思义,就是将多个字段连接起来形成一个新的字段。
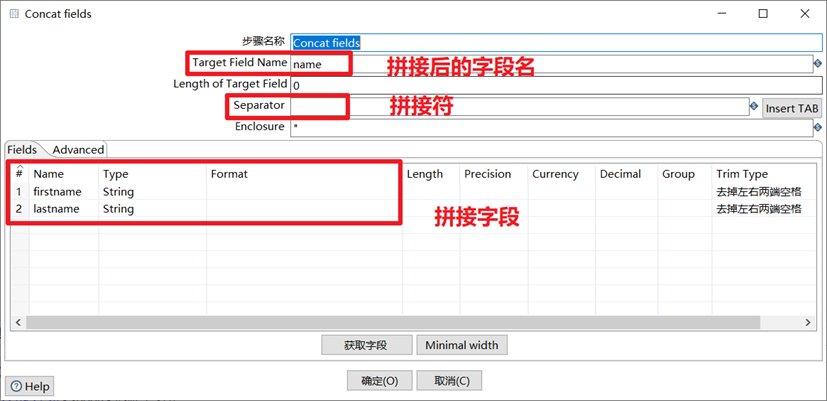
tips:
- 在连接字段时,字段排列顺序决定了连接的顺序。比如firstname bai,lastname li,照此排列顺序即为baili
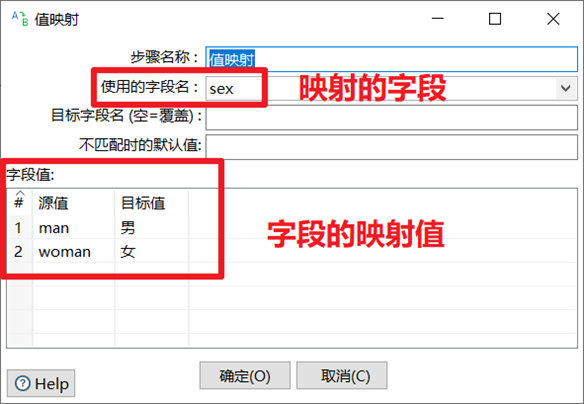
值映射Value mapper
值映射就是把字段的一个值映射成其他的值。在数据质量规范上使用非常多,比如很多系统对应性别sex字段的定义不同。所以我们需要利用此控件,将同一个字段的不同的值,映射转换成我们需要的值。
- 选择映射的字段
- 还可以自定义映射完以后的新字段名
- 可以设置不匹配时的默认值
- 设置映射的值
tips:
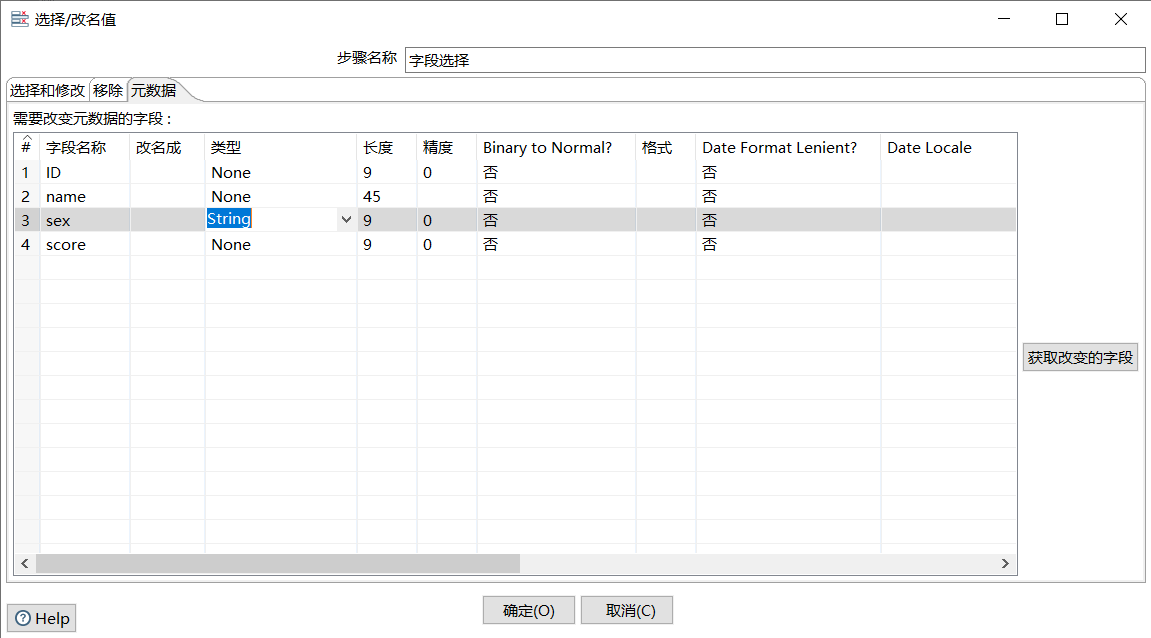
如果遇到数据类型问题,如我在表中以1表示男,0表示女,进行映射时报错:string String : couldn't convert String to Integer.
可以在转换过程中加入一个字段选择,进行数据类型转化即可解决。
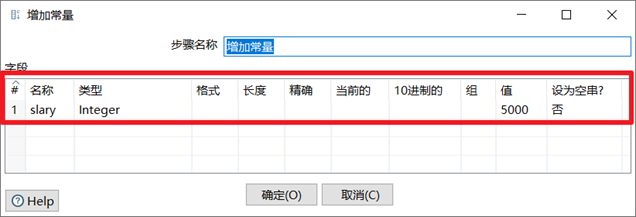
增加常量/增加序列
增加常量就是在本身的数据流里面添加一列数据,该列的数据都是相同的值。
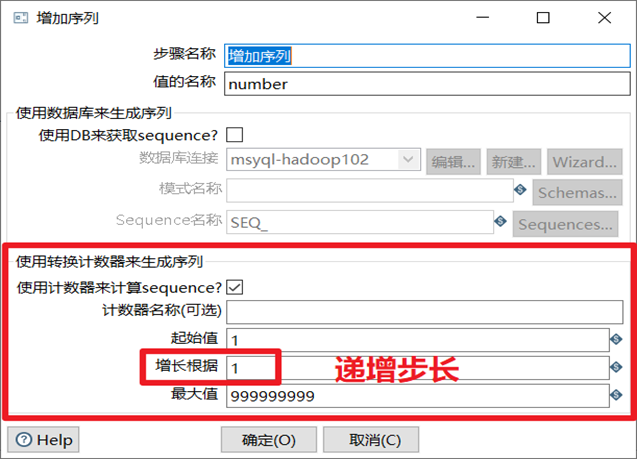
增加序列是给数据流添加一个序列字段,可以自定义该序列字段的递增步长。
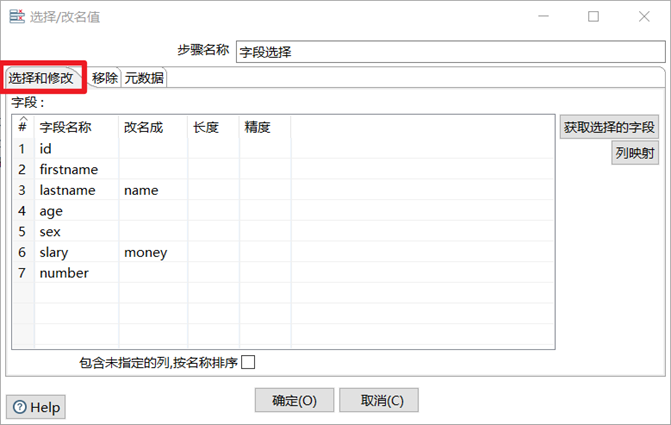
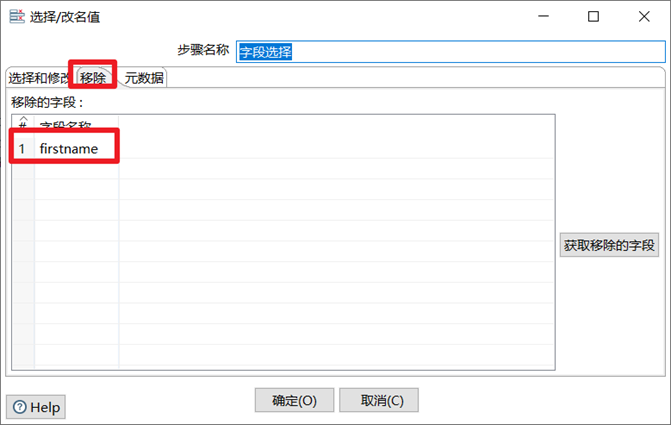
字段选择
字段选择是从数据流中选择字段、改变名称、修改数据类型。
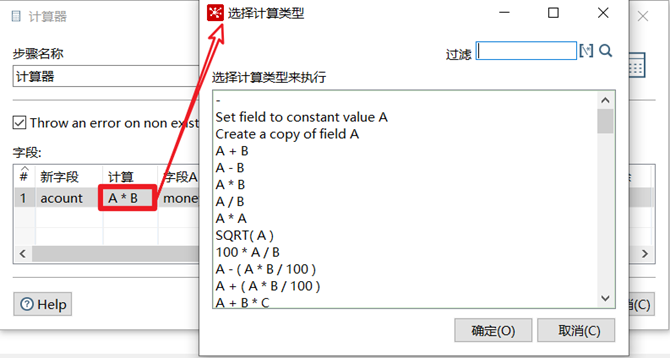
计算器
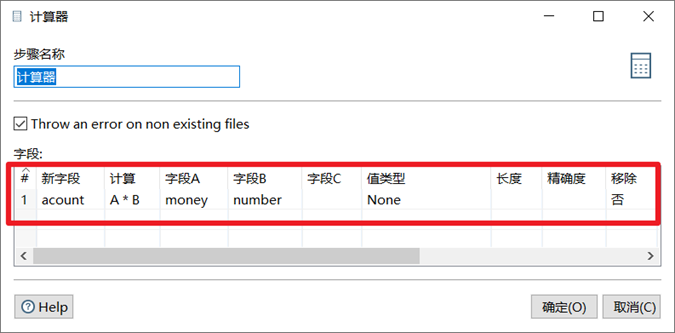
计算器是一个函数集合来创建新的字段,还可以设置字段是否移除(临时字段)。我们可以通过计算器里面的多个计算函数对已有字段进行计算,得出新字段。
tips:
kettle里很多操作如果能够使用sql完成就尽量直接使用sql,kettle受限于效率等问题并不适合大型计算。
字符串剪切/替换/操作
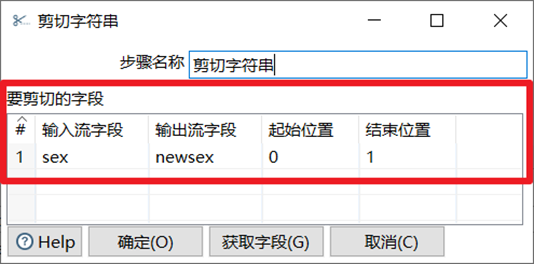
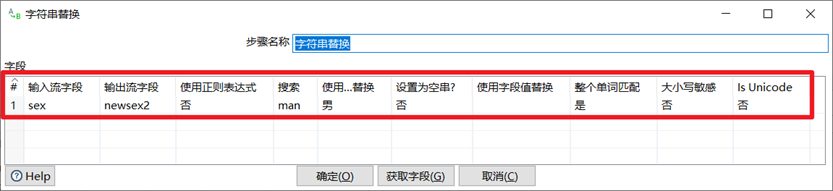
转换控件中有三个关于字符串的控件,分别是剪切字符串,字符串操作,字符串替换。
剪切字符串是指定输入流字段裁剪的位置剪切出新的字段。
字符串替换是指定搜索内容和替换内容,如果输入流的字段匹配上搜索内容就进行替换生成新字段。
字符串操作是去除字符串两端的空格和大小写切换,并生成新的字段。

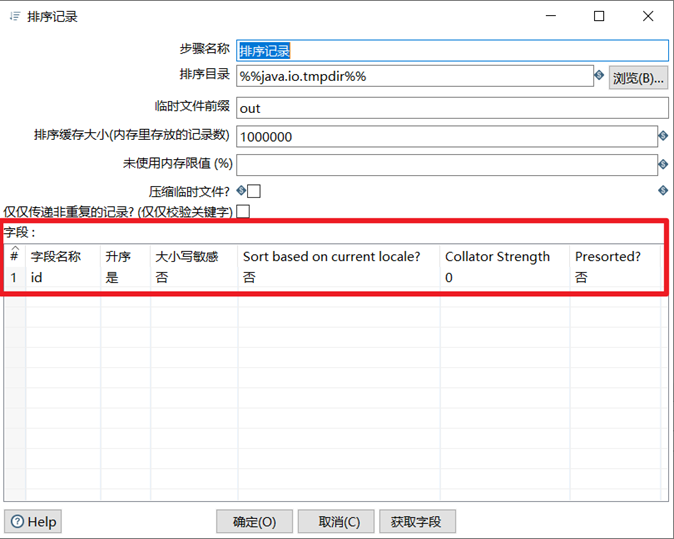
排序记录/去除重复记录
去除重复记录是去除数据流里面相同的数据行。但是此控件使用之前要求必须先对数据进行排序,对数据排序用的控件是排序记录,排序记录控件可以按照指定字段的升序或者降序对数据流进行排序。因此排序记录+去除重复记录控件常常配合组队使用。
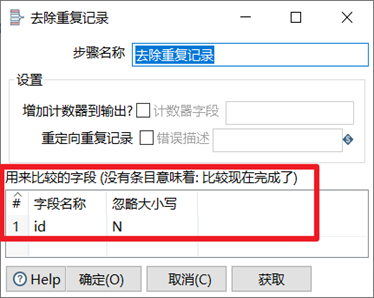
唯一行(哈希值)
唯一行(哈希值)就是删除数据流重复的行。此控件的效果和(排序记录+去除重复记录)的效果是一样的,但是实现的原理不同。排序记录+去除重复记录对比的是每两行之间的数据,而唯一行(哈希值)是给每一行的数据建立哈希值,通过哈希值来比较数据是否重复,因此唯一行(哈希值)去重效率比较高,也更建议使用。
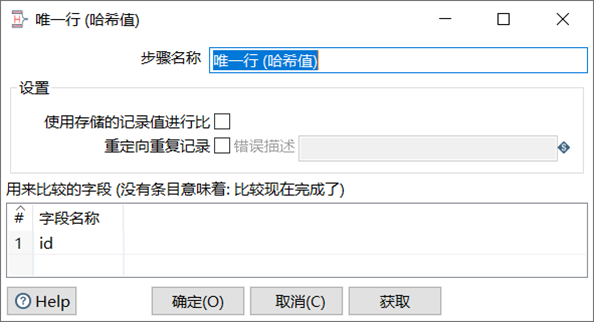
拆分字段
拆分字段是把字段按照分隔符拆分成两个或多个字段。需要注意的是,字段拆分以后,原字段就会从数据流中消失。
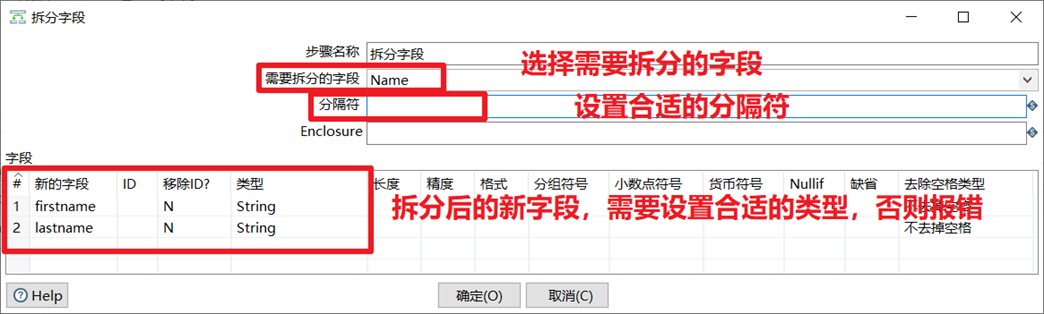
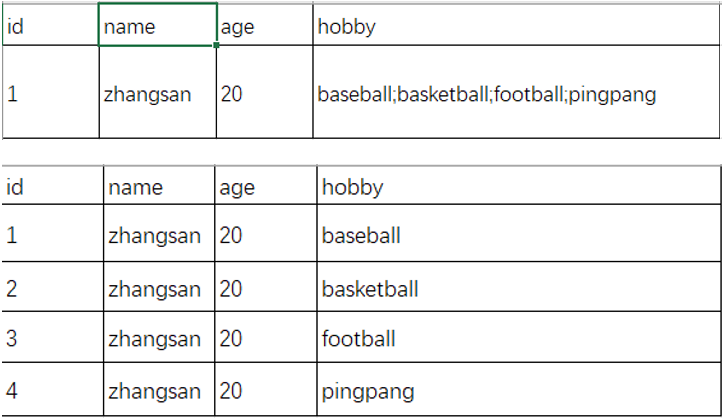
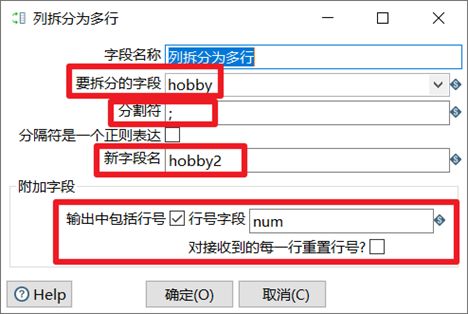
列拆分为多行
列拆分为多行就是把指定字段按指定分隔符进行拆分为多行,然后其他字段直接复制。
- 选择要拆分的字段
- 设置合适的分割符
- 设置分割以后的新字段名
- 选择是否输出新数据的排列行号,行号是否重置
行扁平化
行扁平化就是把同一组的多行数据合并成为一行,可以理解为列拆分为多行的逆向操作。但是需要注意的是行扁平化控件使用有两个条件:
- 使用之前需要对数据进行排序;
- 每个分组的数据条数要保证一致,否则数据会有错乱。
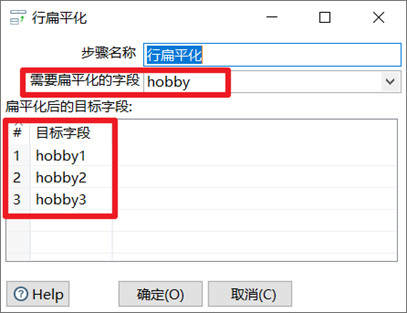
- 选择扁平化的字段
- 填写目标字段,字段个数跟每个分组的数据一致
列转行
注意:列转行之前数据流必须按照分组字段进行排序,否则数据会错乱!
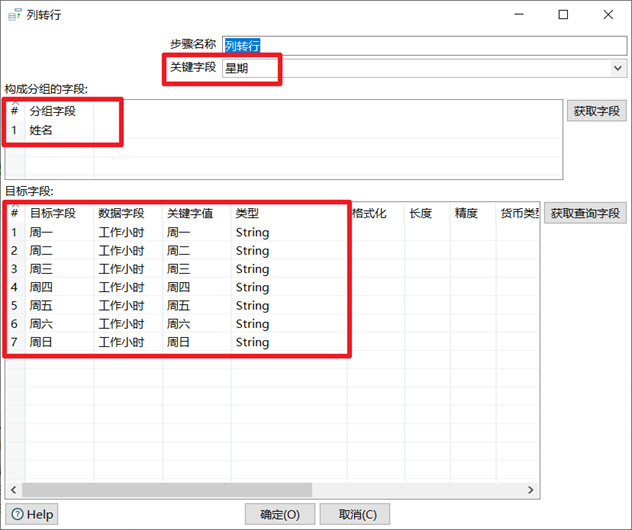
- 关键字段:从数据内容变成列名的字段
- 分组字段:列转行,转变以后的分组字段
- 目标字段:增加的列的列名字段
- 数据字段:目标字段的数据字段
- 关键字值:数据字段查询时的关键字,也可以理解为key
- 类型:要给目标字段设置合适的类型,否则会报错
行转列
可以简单理解为行转列控件是列转行控件的逆向操作。
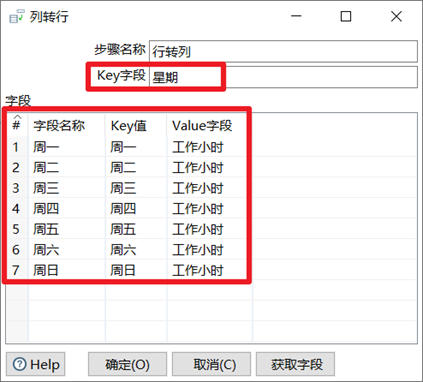
- Key字段:行转列,生成的列名字段名
- 字段名称:原本数据流中的字段名
- Key值:Key字段的值,这个是自己自定义的,一般都跟前面的字段名称一样
- Value字段:对应的Key值的数据列的列名
应用控件
替换NULL值
替换NULL值,顾名思义就是将数据里面的null值替换成其他的值,此控件比较简单,但是在企业里面也会经常用到。
- 可以选择替换数据流中所有字段的null值
- 也可以选择字段,在下面的字段框里面,根据不同的字段,将null值替换成不同的值
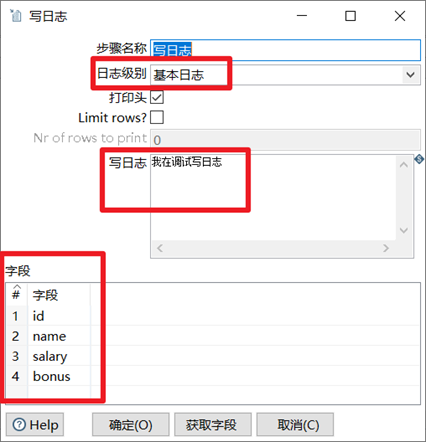
写日志
写日志控件主要是调试的时候使用,此控件可以将数据流的每行数据打印到控制台,方便我们调试整个程序。
- 选择日志级别
- 可以输入自定义输出的语句
- 选择要输出打印的字段
流程控件
流程分类下的控件主要用来控制数据流程和数据流向.
Switch/case
Switch/case控件,最典型的数据分类控件,可以利用某一个字段的数据的不同的值,让数据流从一路到多路。
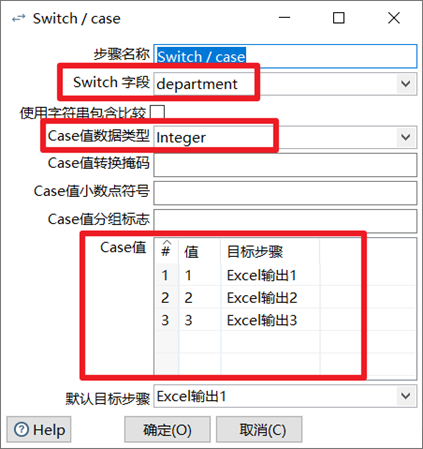
- 选择需要判断的字段
- 选择判断字段的值的类型
- 填写分类数据的判断条件和目标步骤
过滤记录
和Switch/case做对比的话,过滤记录相当于if-else,可以自定义输入一个判断条件,然后将数据流中的数据一路分为两路。仅能两路true/false
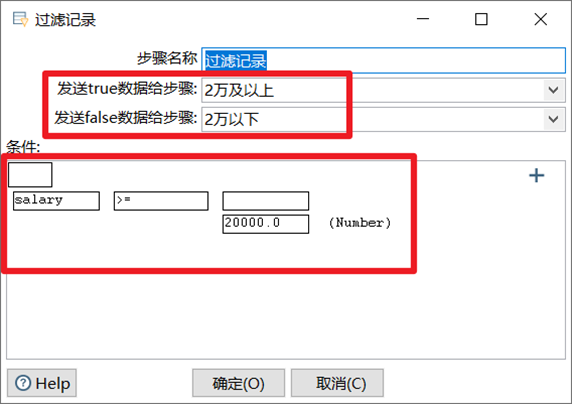
- 在下面先填写数据的判断条件
- 然后再上面选择下判断条件为true或者false的输出步骤
空操作
空操作,顾名思义就是什么也不做,此控件一般作为数据流的终点。
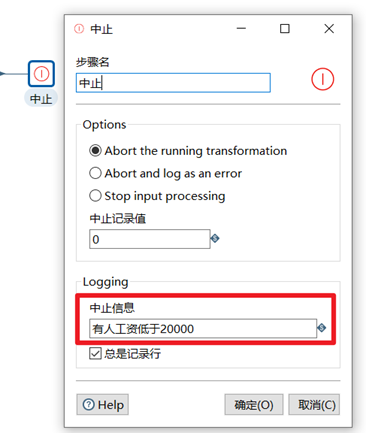
中止
中止是数据流的终点,如果有数据流到此控件处,整个转换程序将中止,并且在控制台输出报错信息。此控件一般用来校验数据,或者调试程序。
查询控件
查询控件是用来查询数据源里面的数据,并合并到主数据流中。
数据库查询
数据库查询就是从数据库里面查询出数据,然后跟数据流中的数据进行左连接的一个过程。左连接的意思是数据流中原本的数据全部有,但是数据库查询控件查询出来的数据不一定全部会列出,只能按照输入的匹配条件来进行关联。
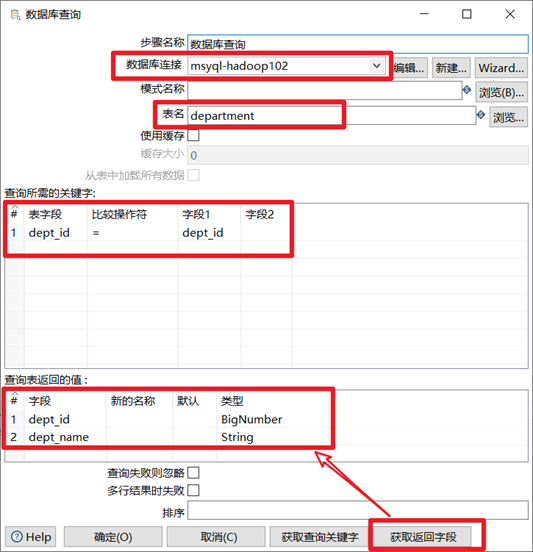
前面的表字段是流里的字段,后面的字段1是查询字段。查询所需的关键字理解为ON
- 选择合适的数据库链接
- 输入要去数据库里面查询的表名
- 输入两个表进行左连接的连接条件
- 获取返回字段,得到查询表返回的值
流查询
流查询控件就是查询两条数据流中的数据,然后按照指定的字段做等值匹配。注意:流查询在查询前把数据都加载到内存中,并且只能进行等值查询。
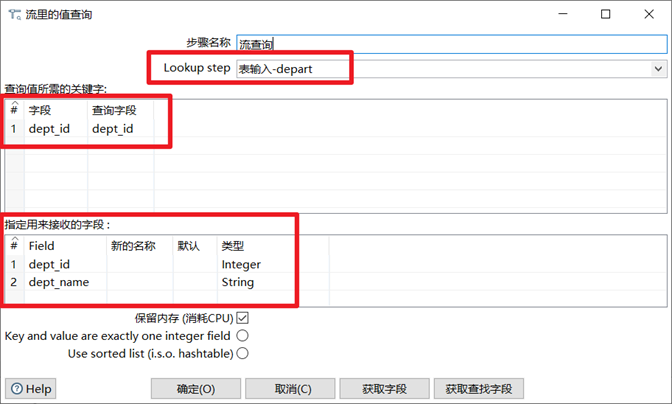
- 输入查询的数据流
- 输入两个流进行匹配的字段(等值匹配)
- 输入查询出的字段
连接控件
连接分类下的控件一般都是将多个数据集通过关键字进行连接起来,形成一个数据集的过程。
合并记录
合并记录是用于将两个不同来源的数据合并,这两个来源的数据分别为旧数据和新数据,该步骤将旧数据和新数据按照指定的关键字匹配、比较、合并。注意旧数据和新数据需要事先按照关键字段排序,并且旧数据和新数据要有相同的字段名称。
合并后的数据将包括旧数据来源和新数据来源里的所有数据,对于变化的数据,使用新数据代替旧数据,同时在结果里用一个标示字段,来指定新旧数据的比较结果。
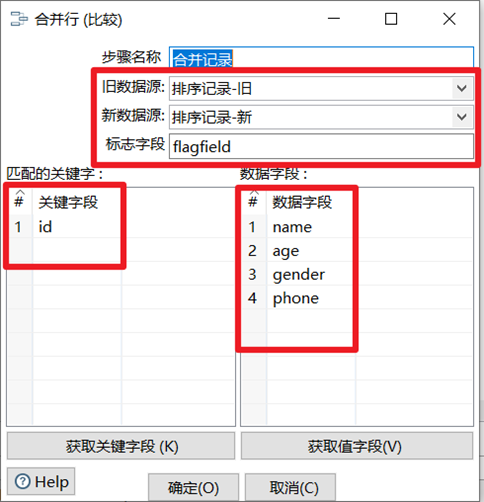
- 旧数据源:选择旧数据来源的步骤
- 新数据源:选择新数据来源的步骤
- 标志字段:设置标志字段的名称,标志字段用于保存比较的结果,比较结果有下列几种
“identical” – 旧数据和新数据一样
“changed” – 数据发生了变化;
“new” – 新数据中有而旧数据中没有的记录
“deleted” –旧数据中有而新数据中没有的记录 - 关键字段:用于定位判断两个数据源中的同一条记录的字段。
- 比较字段:对于两个数据源中的同一条记录,指定需要比较的字段
记录集连接
记录集连接可以对两个步骤中的数据流进行左连接,右连接,内连接,外连接。此控件功能比较强大,企业做ETL开发会经常用到此控件,但是需要注意在进行记录集连接之前,需要对记录集的数据进行排序,并且排序的字段还一定要选两个表关联的字段,否则数据错乱,出现null值。
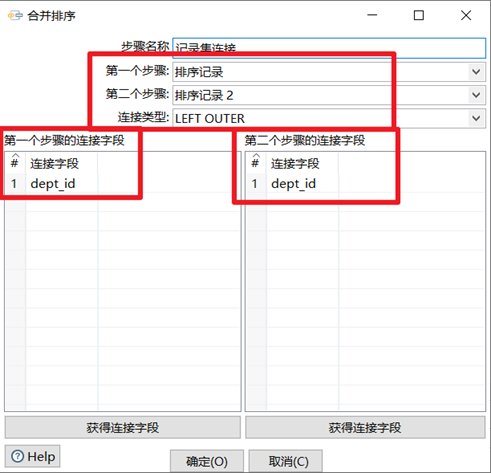
- 选择需要连接的两个数据流的步骤
- 选择连接类型,一共有四个:INNER,LEFT OUTER,RIGHT OUTER,FULL OUTER
- 从两个数据流步骤里面选出连接字段
统计控件
统计控件可以提供数据的采样和统计功能。
分组
分组控件的功能类似于GROUP BY,可以按照指定的一个或者几个字段进行分组,然后其余字段可以按照聚合函数进行合并计算。注意,在进行分组之前,数据最好先进行排序。
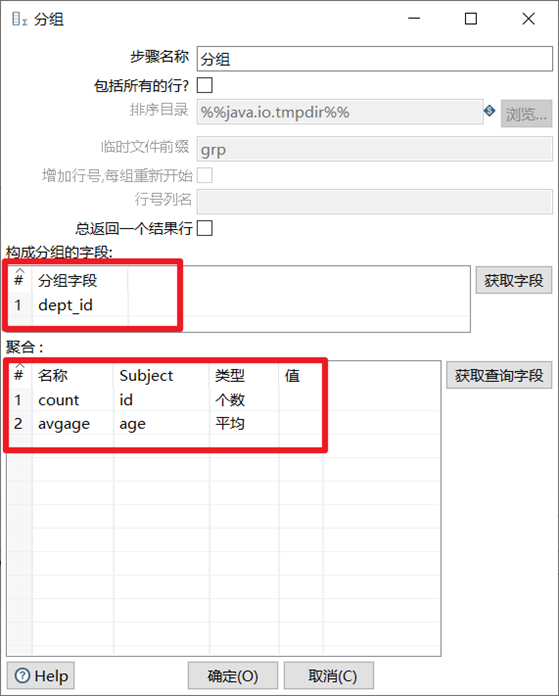
- 选择分组字段
- 给其余字段选择合适的聚合函数进行计算
映射控件
映射可以用来定义子转换,方便代码封装和重用。
映射
映射(子转换)是用来配置子转换,对子转换进行调用的步骤。
映射输入规范是输入字段,由调用的转换输入。
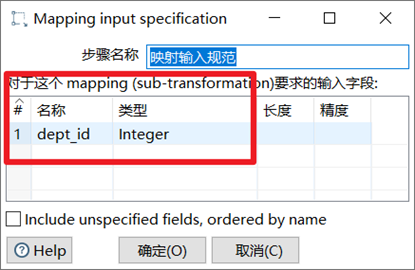
映射输出规范是向调用的转换输出所有列,不做任何处理。
脚本控件
脚本就是直接通过写程序代码完成一些复杂的操作。
执行SQL脚本
执行sql脚本控件就是连接到数据库里面,然后执行自己写的一些sql语句。
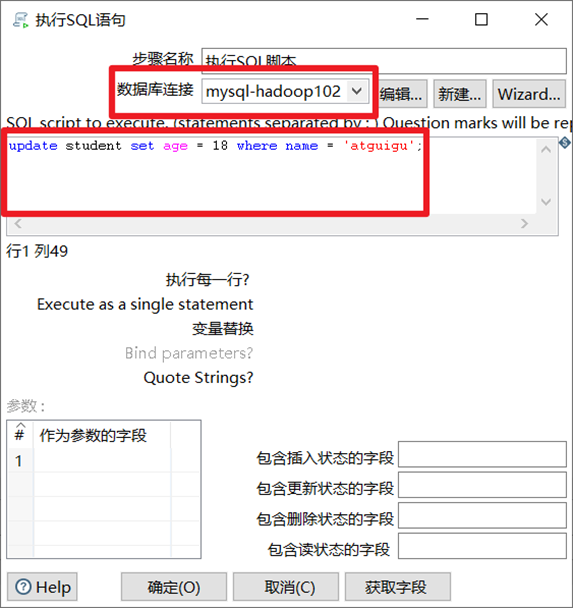
- 选择合适的数据库连接
- 填入要执行的sql语句

