

Uber纽约地区订单数据分析
数据来源:https://www.kaggle.com/fivethirtyeight/uber-pickups-in-new-york-city/home
数据及其含义
1.2014年4-9月的数据集
命名如下:
uber-raw-data-apr14.csv
uber-raw-data-may14.csv
uber-raw-data-jun14.csv
uber-raw-data-jul14.csv
uber-raw-data-apr14.csv
uber-raw-data-sep14.csv
数据包含以下信息:
Date/Time: 优步接送的日期和时间
Lat: 优步接送的纬度
Lon: Uber接送的经度
Base: 和优步有关的 TLC 基地公司代码
2.雇佣基地2015年1月和2月的订单表
命名如下:
Uber-Jan-Feb-FOIL.csv
数据包含以下信息:
dispatching_base_number:基地代码
date:日期
active_vehicles:活跃车辆数
trips:行程数
3.非雇佣基地2015年1-8月的订单表
命名如下:
other-FHV-data-jan-aug-2015.csv
数据包含以下信息:
Base_Number:基地代码
Base_Name:基地名
PickUpDate:接送时间
NumberofTrips:行程数
NumberofVehicles:车辆数
4. Federal基地订单表(含订单状态)
命名为:
other-Federal_02216.csv
数据包含以下信息:
Date:日期
Time:时间
PU_Address:接地点
DO_Address:送地点
Routing Details:细节
Status:订单状态
分析目的
项目旨在进一步理解sql的相关知识与实际应用。
使用工具
Mysql,PowerBI,Excel
数据处理
1.2014年的数据集
1.初步处理csv数据,创建数据库并导入CSV数据。
use uber;
LOAD DATA INFILE 'C:/ProgramData/MySQL/MySQL Server 8.0/Uploads/uber-raw-data-apr14.csv'
INTO TABLE uber_raw_data_apr
FIELDS TERMINATED BY ',' -- 以','为分隔符
ENCLOSED BY '"' -- 去掉字符串中包裹的符号'"'
LINES TERMINATED BY '\n' -- 以'\n'为行间分隔符
IGNORE 1 ROWS; -- 忽略第一行,因为第一行往往是表头

2.将源数据中的部分信息规范化。
ALTER TABLE uber_raw_data_apr ADD uberdate date;
UPDATE uber_raw_data_apr SET uberdate = STR_TO_DATE(Date,'%m/%d/%Y');-- 将导入的时间数据规范化,这里将字符串转化为日期值

3.将2014年4-9月的数据整合在一个视图中。数据总和4534327条。
create view uber_raw_data as
(
SELECT
Time,Lat,Lon,Base,uberdate
FROM uber_raw_data_apr
UNION ALL
SELECT
Time,Lat,Lon,Base,uberdate
FROM uber_raw_data_may
UNION ALL
SELECT
Time,Lat,Lon,Base,uberdate
FROM uber_raw_data_jun
UNION ALL
SELECT
Time,Lat,Lon,Base,uberdate
FROM uber_raw_data_jul
UNION ALL
SELECT
Time,Lat,Lon,Base,uberdate
FROM uber_raw_data_aug
UNION ALL
SELECT
Time,Lat,Lon,Base,uberdate
FROM uber_raw_data_sep
)
从中提取出月、周、时等信息,
CREATE VIEW uber_order_2014 AS
SELECT
Base,Lat,Lon,uberdate,
month(uberdate) as m,
(weekday(uberdate)+1) as w, --函数返回一个日期的工作日索引值,即星期一为0,星期二为1,星期日为6。要适应习惯所以要+1
Time,
HOUR(Time) as h
FROM uber_raw_data
视图数据如下:
数据分析
基于2014年4-9月的数据集
2014年4-9月订单增长情况
SELECT
*,
ROUND((m_num - lead_m_num)/lead_m_num,4) as '环比增长率' -- 计算环比增长率,保留四位小数
FROM(
SELECT
m,m_num,lead(m_num,1) over(ORDER BY m DESC) as lead_m_num -- 为了方便求环比,将下一月数据利用窗口函数向上移一格
FROM (
SELECT
m, -- 月份
COUNT(m) as m_num -- 计算月订单数
FROM uber_order_2014
GROUP BY m
) t
) s;-- 按月计算环比增长率
得到月环比增长率,结果如下:
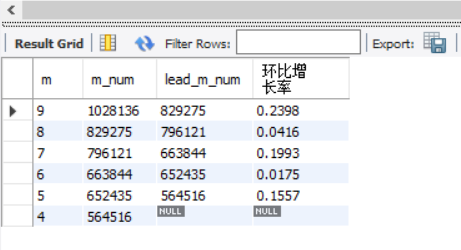
导出到csv文件中:
SELECT '月份', '当月订单数', '上月订单数', '环比增长率'
UNION ALL
SELECT *
FROM growth_rate_2014
INTO OUTFILE 'C:/ProgramData/MySQL/MySQL Server 8.0/Uploads/growth_rate_2014.csv'
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'; -- 导出的文件注意格式转化
在POWERBI中画图:

可以看uber在4-9月月订单数持续增长,且在7月和9月订单数环比增长达到峰值,9月环比增长率达到23.98%.
2014年4-9月基地订单数构成
USE uber;
SELECT
DISTINCT base, -- 基地名
count(base) AS base_sum-- 基地订单数
FROM uber_order_2014
GROUP BY base
得到结果:

在POWERBI中画饼图如下:

数据显示,在2014年4-9月期间,基地B02617、B02598、B02682订单量更多,业务量排名第一的基地B02617贡献了32.17%的订单。
2014年4-9月基地订单变化趋势
USE uber;
SELECT
Base,apr,may,jun,jul,aug,sep
FROM
(
SELECT
Base,COUNT(Base) AS apr
FROM uber_order_2014
WHERE m=4
GROUP BY Base
) t4
JOIN (
SELECT
Base b5,COUNT(Base) AS may
FROM uber_order_2014
WHERE m=5
GROUP BY b5
) t5
ON t4.Base=t5.b5
JOIN (
SELECT
Base b6,
COUNT(Base) AS jun
FROM uber_order_2014
WHERE m=6
GROUP BY b6
) t6
ON t4.Base=t6.b6
JOIN (
SELECT
Base b7,
COUNT(Base) AS jul
FROM uber_order_2014
WHERE m=7
GROUP BY b7
) t7
ON t4.Base=t7.b7
JOIN (
SELECT
Base b8,
COUNT(Base) AS aug
FROM uber_order_2014
WHERE m=8
GROUP BY b8
) t8
ON t4.Base=t8.b8
JOIN (
SELECT
Base b9,
COUNT(Base) AS sep
FROM uber_order_2014
WHERE m=9
GROUP BY b9
) t9
ON t4.Base=t9.b9
--有点长是因为执着于要把这些数据一次性弄在一个表里面,如果觉得这个太复杂其实可以分开运行多次的,也算是一次有趣的尝试。使用了连接JOIN来实现把这些结果放在一起,后面的Base使用别名是为了在查询中更好的呈现结果(不使用别名的话结果中会出现多个Base)
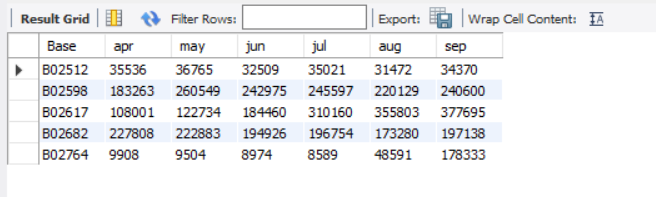
在POWERBI中画图:
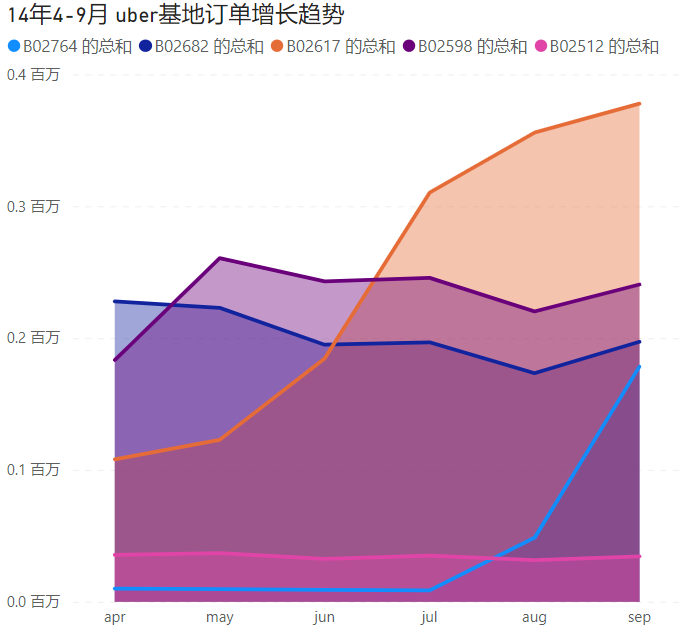
可以看到:基地B02617和B02764九月相较于4月订单数出现大幅增长,基地B02512和B02598订单数几乎不变,基地B02682出现了较大幅度下滑。这些需要在实际情况中分析原因。
2014年4-9月订单区域分布
USE uber;
SELECT Lat,Lon,m AS month
FROM uber_order_2014
WHERE m=4
导出数据并在POWERBI中作图,4月份分布:
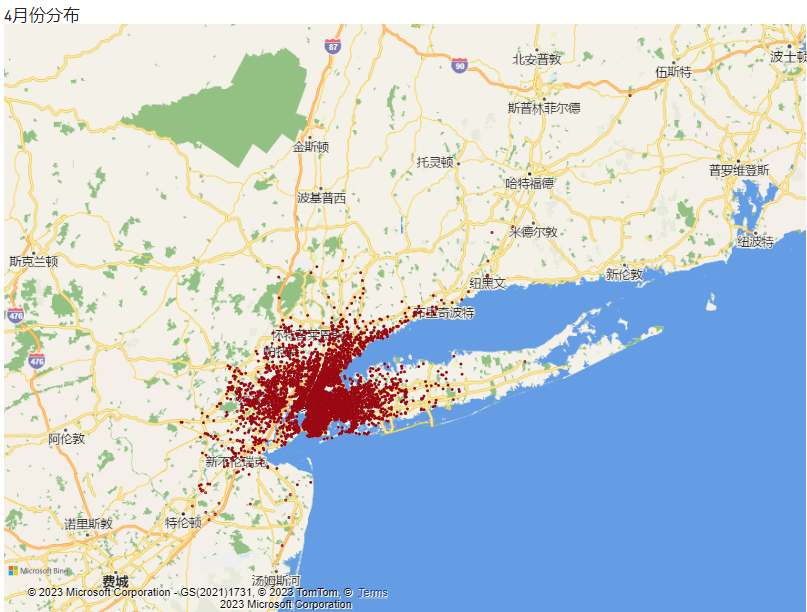
同样的,可以得到5-9月的分布,将4-9月的分布放在一起以便分析查看:
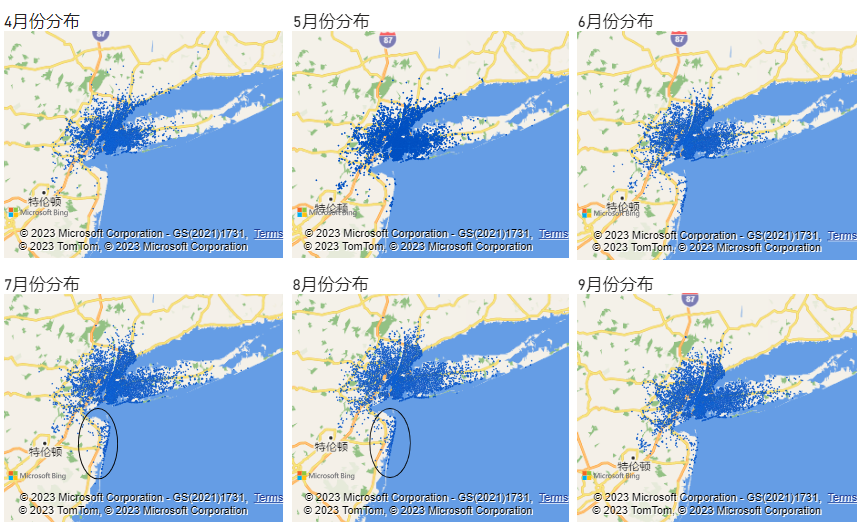
观察到图中椭圆框选区域7月、8月订单量急剧增长:
结合该区域地理位置(位于海岸线)及业务实际情况,推测是由于旅游带来的业务增长。实际业务中可根据旅游行业相关数据对旅游旺季及区域进行预测,并采取与商家合作等业务策略,提升业务量并对车辆进行合理调度。
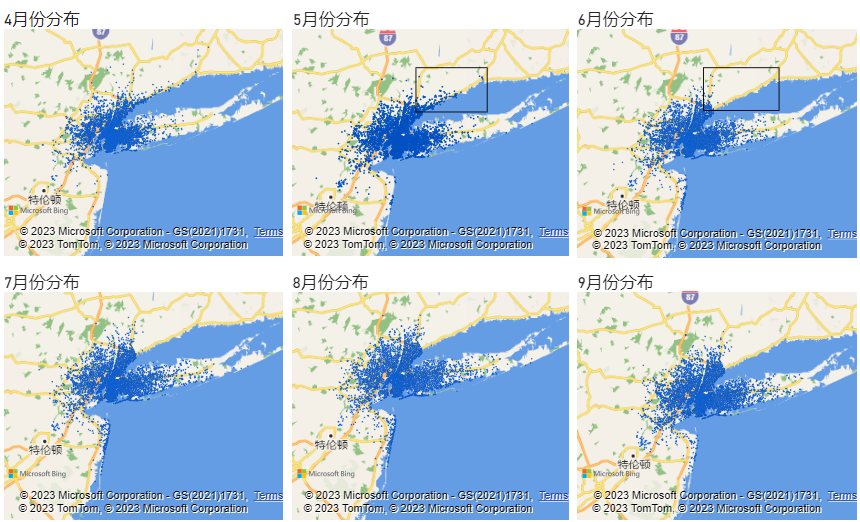
观察到图中矩形框选区域6月开始无订单出现:
对6月的订单分布进行进一步分析,分别查看5个下属基地的订单分布,均未在此区域产生订单,结合该区域行政及地理位置,推断可能是优步的业务策略调整(跨城订单),由于数据集中缺少这部分数据,暂无法分析。

从整体订单区域分布看,4-9月uber的业务一直在扩张。
基于2015年1-2月数据集
uber日车均订单
由数据集给出的数据:
--uber基地的日均车接单量(2015年1-2月)
SELECT
date,
ROUND((trips/active_vehicles),2) as avg_tv --保留两位小数
FROM uber_jan_feb_foil
HAVING avg_tv<25 --日均车接单量超过25视为异常数据
ORDER BY avg_tv DESC
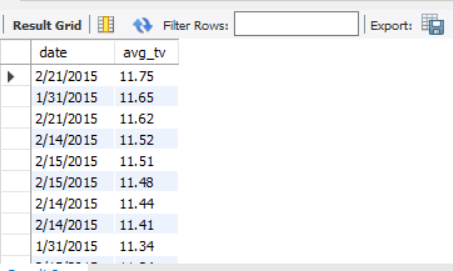
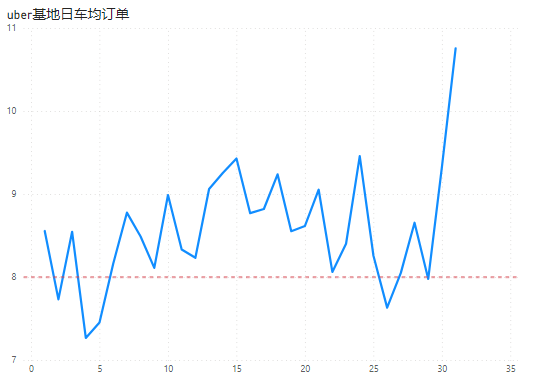
可以看到:2015年1-2月Uber下属基地每辆车平均每天接单量大部分都在8单以上。
2015年1-2月基地运营效率
通过行程数、活跃车辆数分析各基地的运营效率:
SELECT
dispatching_base_number,
SUM(trips) AS trips, -- 基地行程数
SUM(active_vehicles) AS active_vehicles, --活跃车辆数
SUM(trips)/SUM(active_vehicles) as avg_tv -- 车均接单数
FROM uber_jan_feb_foil
GROUP BY dispatching_base_number
ORDER BY avg_tv DESC;
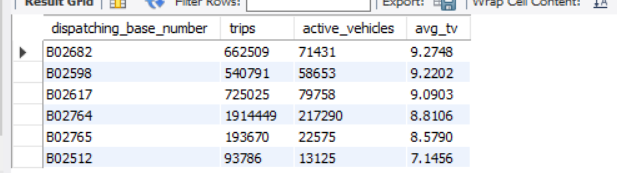
在POWERBI中画图:

从中可以看到:基地B02764的订单数最多,运营效率相较而言偏低,应当结合实际地理位置分配车辆数目达到车辆利用率最大化。基地B02682每日车均接单数最多,分配相对合理。基地B02512的订单数最少。
2015年1-2月订单变化趋势
汇总2015年1-2月各基地的订单数据:
--采用的也是JOIN
use uber;
SELECT base,jan,feb
FROM
(SELECT
dispatching_base_number AS base,
SUM(trips) AS jan
FROM uber_jan_feb_foil
WHERE date LIKE '1%'-- 1月汇总数据,这里的date在导入的时候是字符串类型,可以用STR_TO_DATE进行转化,但是这里为了方便就直接用LIKE了
GROUP BY base
) t1
JOIN
(
SELECT
dispatching_base_number AS base2,
SUM(trips) AS feb
FROM uber_jan_feb_foil
WHERE date LIKE '2%'-- 2月汇总数据
GROUP BY base2
) t2
ON t1.base=t2.base2
导出数据并在POWERBI中画图:
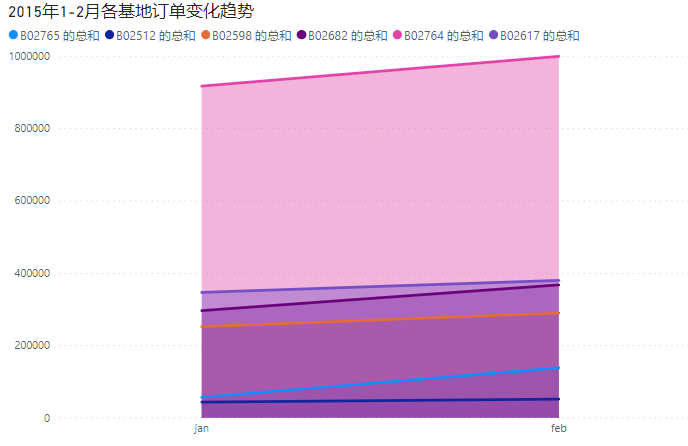
对比2014年4-9月的数据,原本订单数下滑较为严重的基地B02682的订单量已回升。
基地B02764订单数仍然保持遥遥领先。
基于Federal基地订单表(含订单状态)
订单满足情况
SELECT Status,COUNT(Status) AS num_status,COUNT(Status)/276 AS percent
FROM other_federal_02216
GROUP BY Status
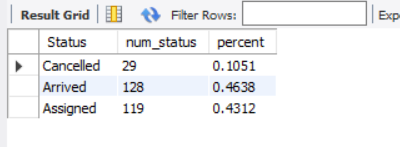
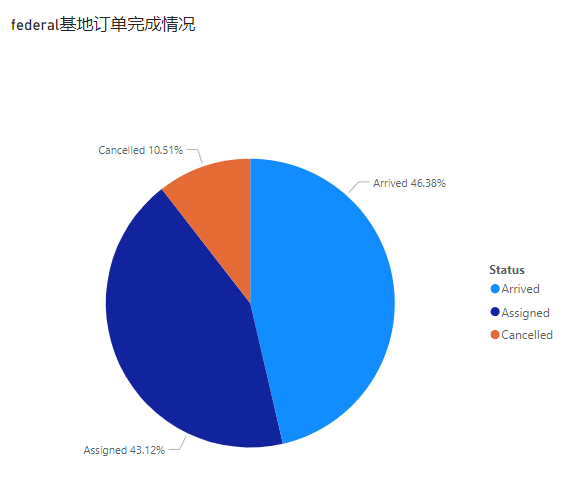
结合饼图可得:federal基地的完成订单占46.38%,订单取消率为10.51%,需优化调度策略,提升订单满足率,降低订单取消率。
订单取消分析
CREATE VIEW other_federal_cancelled AS --为了方便创建了视图
SELECT
*,
LEFT(Time,2) as h -- 返回字符串Time左侧的2个字符,这里即小时h
FROM other_federal_02216
WHERE Status REGEXP 'Cancelled'
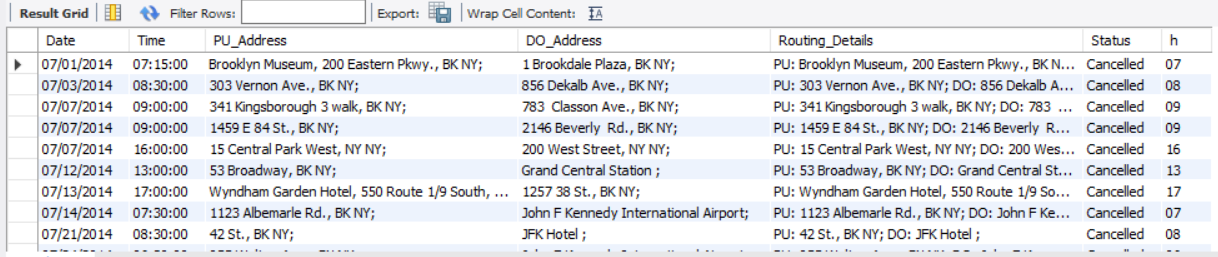
进一步地,对取消订单时间分类:
SELECT
h,
COUNT(h) AS num_h
FROM other_federal_cancelled
GROUP BY h
ORDER BY h
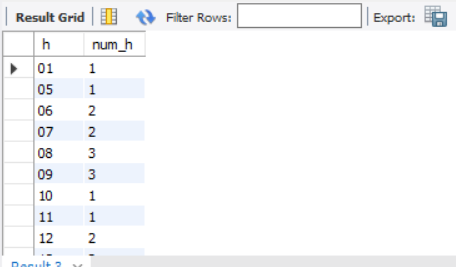
导出数据POWERBI可视化:

可以看到订单取消时间集中于6-9点,可能这段时间属于上班早高峰,订单难以得到满足,需结合地方活跃车辆数、交通拥堵情况等合理调度并采取相应措施。
SELECT DO_Address,COUNT(DO_Address) AS num_cancelled--取消订单的目的地及取消订单数
FROM other_federal_02216
WHERE Status REGEXP 'Cancelled'
GROUP BY DO_Address
ORDER BY num_cancelled DESC
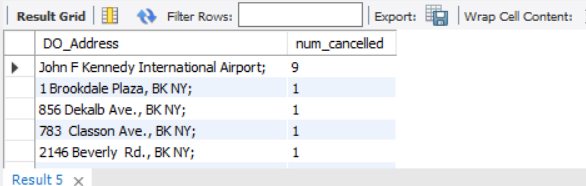

取消订单主要目的地都是机场(La Guardia Airport、John F Kennedy International Airport),这说明夜间前往机场的订单难以得到满足,需结合业务对凌晨及上午的活跃车辆进行合理调度并采取相关措施(如夜间补贴、空车费等)引导司机接前往机场的订单。
用户出行偏好分析
时间偏好
按小时
SELECT
h,
COUNT(h)
FROM uber_order_2014 -- 是从2014年数据中中提取出月、周、时等信息并创建的视图
GROUP BY h
ORDER BY h
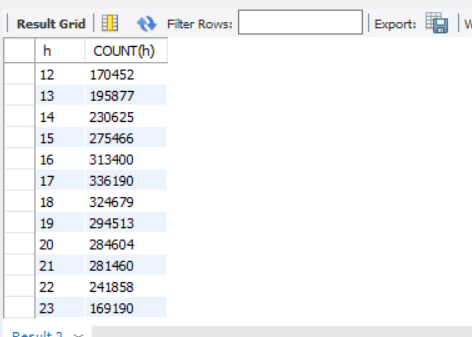
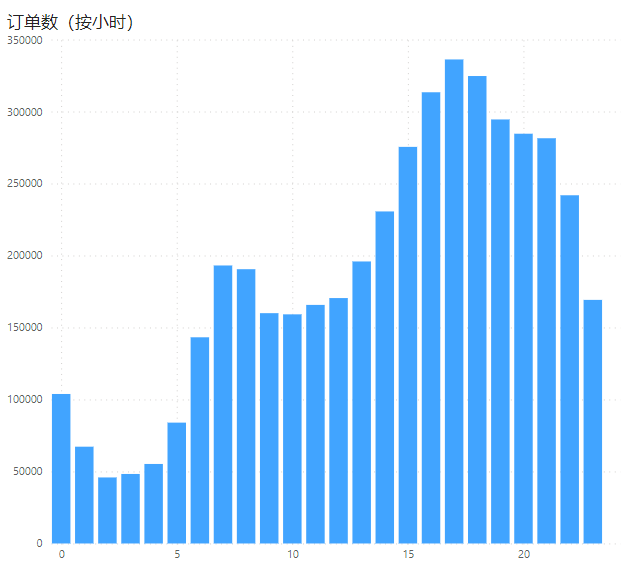
可以得到:一天中乘客的出行高峰出现在早上7点和下午5点,考虑主要为上下班高峰,针对上下班高峰需提前调度车辆,以满足高峰期出行订单需求。
按周几
SELECT
w,
COUNT(w)
FROM uber_order_2014
GROUP BY w
ORDER BY w
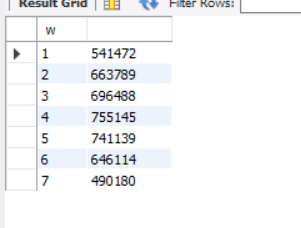
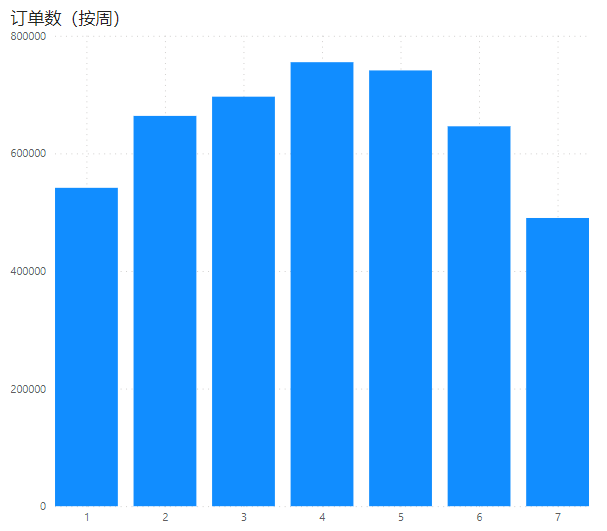
可以得到:在周四和周五达到出行高峰。
按月
SELECT
m,
COUNT(m)
FROM uber_order_2014
GROUP BY m
ORDER BY m

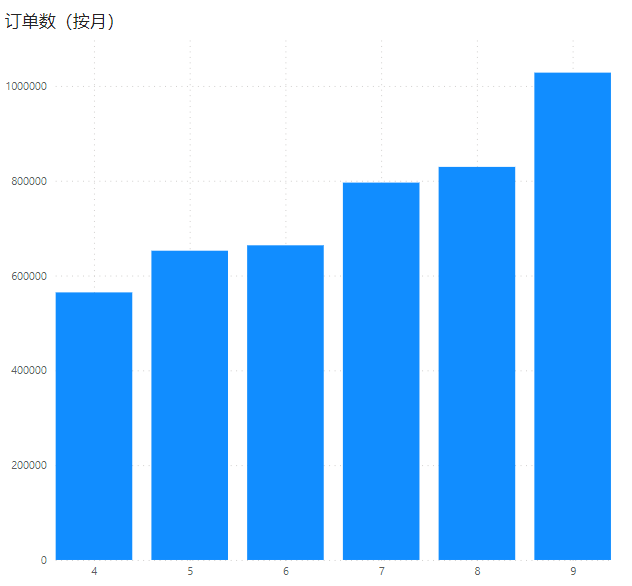
可以得到:月订单逐渐稳步增长。
区域偏好

容易得到:7点、17点的出行订单分布较为集中,主要集中在办公楼集中区域、商圈、住宅区,可根据办公集中区域、住宅集中区域的经纬度进行车辆的合理调度。
同时,根据之前给出的4-9月的订单分布:
可以得到日常出行订单主要集中于城市的中心区域,当旅游季到来时,订单会向海边等旅游地区扩张。
总结
- 提升订单满足率:
2014年、2015年Uber订单量持续增长,但在订单量提升的同时,需注意调度车辆,提升车辆利用率及订单满足率;针对上班早高峰等取消率较高的订单,需根据实际业务进一步分析,从交通情况、时间、取消原因等角度考虑,降低订单取消率。 - 用户出行偏好:
从其他外部数据对旅游、节假日订单进行预测,同时采取相应措施提升订单数;根据用户出行数据分布,合理利用行为数据,根据日常用户出行时间、出行区域及季节性出行特征构建模型并进行预测,制定更优化策略,提高订单量并提升订单满足率。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现