

表操作
列属性
| Column Name | Datatype | PK | NN | AI | Default |
|---|---|---|---|---|---|
| Customer_id | INT | √ | √ | √ | |
| first_name | VARCHAR(50) | √ | |||
| birth_date | DATE | NULL | |||
| phone | VARCHAR(50) | NULL | |||
| state | CHAR(2) | √ |
char与varchar:
char类型的长度是固定的。每次修改的数据长度相同,效率更高。存储的时候是初始预计字符串再加上一个记录字符串长度的字节,占用空间较大。
varchar类型的长度是可变的。每次修改的数据长度不同,效率更低。存储的时候是实际字符串再加上一个记录字符串长度的字节,占用空间较小。
PK是主键的缩写(Primary Key):主键是用来唯一地标识一行数据。主键列必须包含唯一的值,且不能包含空值。
FK是外键的缩写(Foreign Key):外键用来建立主表与从表的关联关系,为两个表的数据建立连接,约束两个表中数据的一致性和完整性。一个表可以有一个或多个外键,外键可以为空值,若不为空值,则每一个外键的值必须等于主表中主键的某个值。
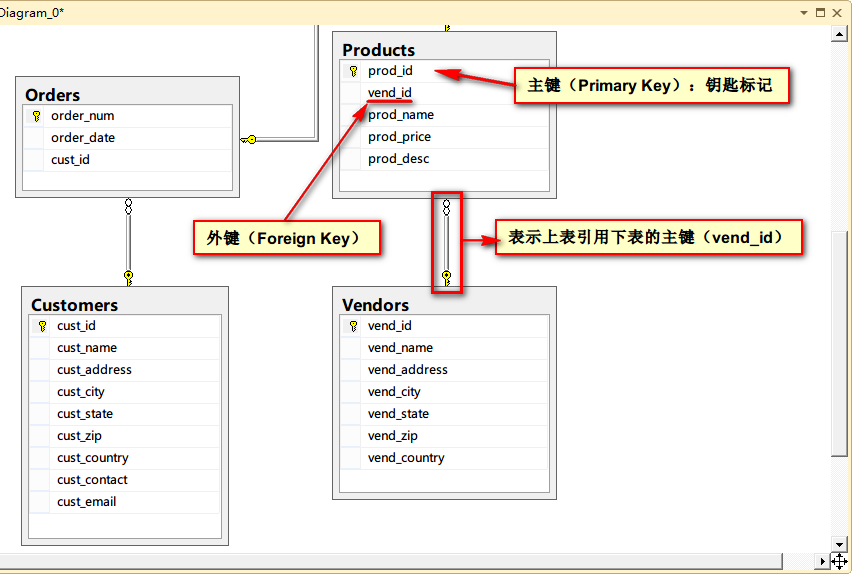
NN是非空值。
AI是自动递增。自动递增列INSERT时可以忽略。
default是默认值。
插入记录的方法:
{
-- 写字段名
INSERT INTO
exam_record(uid, exam_id, start_time, submit_time, score)
VALUES
(1001,9001,'2021-09-01 22:11:12','2021-09-01 22:11:12'+ INTERVAL 50 minute,90),
(1002,9002,'2021-09-04 07:01:02',NULL,NULL)
---
-- 不写字段名、自增ID
INSERT INTO
exam_record
VALUES
(DEFAULT,1001,9001,'2021-09-01 22:11:12',DATE_ADD('2021-09-01 22:11:12',INTERVAL 50 minute) ,90),
(DEFAULT,1002,9002,'2021-09-04 07:01:02',DEFAULT,DEFAULT)
-- 建表的时候写了id为自增id,而写0或者NULL或者DEFAULT或者没有在自增id中出现的(不重复)数(例如-1,-2),系统都会自动填充id。如果建表的时候没有写明是自增id,那么主键一定是不能为空的,这个时候写null就会报错。
}
另外一个例子:
{
-- 写字段名
INSERT INTO
exam_record_before_2021(uid,exam_id,start_time,submit_time,score)
SELECT uid,exam_id,start_time,submit_time,score
FROM exam_record
WHERE year(submit_time) < 2021
AND score IS NOT NULL
---
-- 不写字段名、自增ID
INSERT INTO
exam_record_before_2021
SELECT 0,uid,exam_id,start_time,submit_time,score
FROM exam_record
WHERE year(submit_time) < 2021
AND score IS NOT NULL
}
插入单行
{
INSERT INTO customers ()
VALUES (
DEFAULT,
'John',
'Smith',
'1990-01-01',
NULL,
'address',
'city',
'CA',
DEFAULT) -- 默认插入则每一列都要有与之对应的内容
INSERT INTO customers (
first_name,
last_name,
birth_date,
address,
city,
state)
VALUES (
'John',
'Smith',
'1990-01-01',
'address',
'city',
'CA') -- 指定列插入
}
插入多行
{
INSERT INTO products(name,quantity_in_stock,unit_price)
VALUES
('Product1','10','1.95'),
('Product2','11','1.95'),
('Product3','12','1.95')
#34 插入分层行
INSERT INTO orders (customer_id, order_date,status)
VALUES (1,'2019-01-02',1);
INSERT INTO order_items
VALUE
(LAST_INSERT_ID(), 1, 1, 2.95),
(LAST_INSERT_ID(), 2, 1, 3.95) -- LAST_INSERT_ID()返回插入新行时MYSQL生成的那个id
}
创建表复制
{
CREATE TABLE orders_archived AS
SELECT *
FROM orders-- 这样创建的表 orders_archived是没有主键的
INSERT INTO orders_archived
SELECT *
FROM orders
WHERE order_date < '2019-01-01'-- 在INSERT下使用的一段子查询
---
CREATE TABLE invoices_archived AS
SELECT
i.invoice_id,
i.number,
c.name AS client,
i.invoice_total,
i.payment_total,
i.invoice_date,
i.due_date,
i.payment_date
FROM invoices i
JOIN clients c
ON i.client_id=c.client_id
WHERE payment_date IS NOT NULL
}
更新单行
{
UPDATE invoices-- invoices是表名
SET payment_total = DEFAULT ,payment_date=NULL
WHERE invoice_id=1
---
UPDATE invoices
SET payment_total = invoice_total * 0.5 ,payment_date=due_date
WHERE invoice_id=3
}
更新多行
{
UPDATE invoices-- invoices是表名
SET
payment_total = invoice_total * 0.5 ,
payment_date=due_date
WHERE client_id =3-- WHERE client_id IN (3, 4)
}
UPDATE中使用子查询
{
UPDATE invoices
SET
payment_total = invoice_total * 0.5 ,
payment_date=due_date
WHERE client_id IN
(SELECT client_id
FROM clients
WHERE state IN ('CA','NY')) -- 在执行之前,可以先运行先子查询看看会更新什么记录
---
UPDATE orders
SET comments = 'Golden customer'
WHERE customer_id IN
(SELECT customer_id
FROM customers
WHERE points > 3000)
}
删除行
{
DELETE FROM invoices
WHERE client_id = (
SELECT *
FROM clients
WHERE name = 'Myworks'
)
---
DELETE FROM exam_record
WHERE submit_time IS NULL OR TIMESTAMPDIFF(MINUTE,start_time,submit_time) <5
order by start_time
limit 3 -- 请删除exam_record表中未完成作答或作答时间小于5分钟整的记录中,开始作答时间最早的3条记录
}
删除表
truncated table是删除表中所有行。
delete与truncate的区别:
delete:数据打上删除的标记,不释放空间,可回滚 空间优化optimize table_name(delete table之后立即完成)
truncate:删除整个表,创建一个新的空表,释放空间,不可回滚(删完立即买机票跑路)
drop:删除整张表(包括表结构),释放空间,不可回滚(买完机票再删)
速度:drop > truncate > delete
格式:
{
TRUNCATE TABLE table_name
DROP TABLE IF EXISTS table_name
}
replace into
跟 insert into功能类似,不同点在于:replace into 首先尝试插入数据到表中,如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据;否则,直接插入新数据。要注意的是:插入数据的表必须有主键或者是唯一索引!否则的话,replace into 会直接插入数据,这将导致表中出现重复的数据。
{
REPLACE INTO examination_info
VALUES(NULL,9003,'SQL','hard',90,'2021-01-01 00:00:00')
-- 等价于
DELETE FROM examination_info
WHERE exam_id=9003;
INSERT INTO examination_info
VALUES(NULL,9003, 'SQL','hard', 90, '2021-01-01 00:00:00')
}
创建表
如果有需要,添加 drop table [if exists] table_name,以此避免创建表名已经存在的表。
{
drop table [if exists] table_name
create table if not exists user_info_vip(
id int(11) primary key auto_increment comment "自增ID",
uid int(11) unique not null comment "用户ID",
nick_name varchar(64) comment "昵称",
achievement int(11) default 0 comment "成就值",
level int(11) comment "用户等级",
job varchar(32) comment "职业方向",
register_time datetime default current_timestamp comment "注册时间"
)DEFAULT CHARSET=UTF8;
-- 字符编码默认是utf8mb4,需要将默认编码改成UTF8才能通过。
}
ALTER TABLE
用于在已有的表中添加、修改或删除列,创建删除索引等。
{
ALTER TABLE table_name
ADD COLUMN column_name datatype-- 添加列
ALTER TABLE user_info
ADD COLUMN school varchar(15) AFTER `level`-- level的后面增加一列最多可保存15个汉字的字段school
ALTER TABLE table_name
DROP COLUMN column_name-- 删除列
ALTER TABLE table_name
CHANGE COLUMN column_name datatype -- 改变表中数据类型
ALTER TABLE user_info
CHANGE COLUMN job profession varchar(10) -- 将表中job列名改为profession
ALTER TABLE table_name
MODIFY COLUMN column_name datatype -- 修改数据类型
ALTER TABLE user_info
MODIFY COLUMN achievement int(10) DEFAULT 0 -- 把achievement的默认值设置为0
ALTER TABLE table_name
ADD INDEX 索引名(列名) -- 无:普通索引 UNIQUE:唯一性索引 FULLTEXT:全文索引
ALTER TABLE examination_info
ADD UNIQUE INDEX uniq_idx_exam_id(exam_id)-- 在exam_id列创建唯一性索引uniq_idx_exam_id
ALTER TABLE table_name
DROP INDEX 索引名 -- 删除索引
}

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步