
Spark权威指南读书笔记(六) RDD 与分布式共享变量
Spark权威指南读书笔记(六) RDD 与分布式共享变量
一、弹性分布式数据集
低级API分类
低级API有两种,一种用于处理分布式数据集, 一种用于分发或处理分布式共享变量(广播变量和累加器)。
何时使用低级API
- 高级API找不到所需功能
- 需要维护一些使用RDD编写的遗留代码库
- 需要执行一些自定义共享变量时
如何使用低级API
SparkContext是低级API入口,可通过SparkSession来获取SparkContext。
关于RDD
简单而言,RDD是一个只读不可变的且已分块的记录集合,并可以并行处理。与DF比较而言,DF每条记录为结构化的数据行,字段已知且与schema已知,RDD中记录仅仅是程序员选择的对象。
对于用户而言,一般只会创建两种类型RDD,通用型RDD或提供附加函数的KV RDD。
每个RDD具有五个主要内部属性:
- 数据分片列表
- 作用在每个数据分片的计算函数
- 描述与其他RDD的依赖关系列表
- (可选)为KV RDD配置的Partitioner(分片方法)
- (可选)优先位置列表,根据数据本地特性,指定了每个Partition分片的处理位置偏好。
它支持两种算子操作,惰性执行的转换操作和立即执行的动作操作,均已分布式方法处理数据。
RDD创建
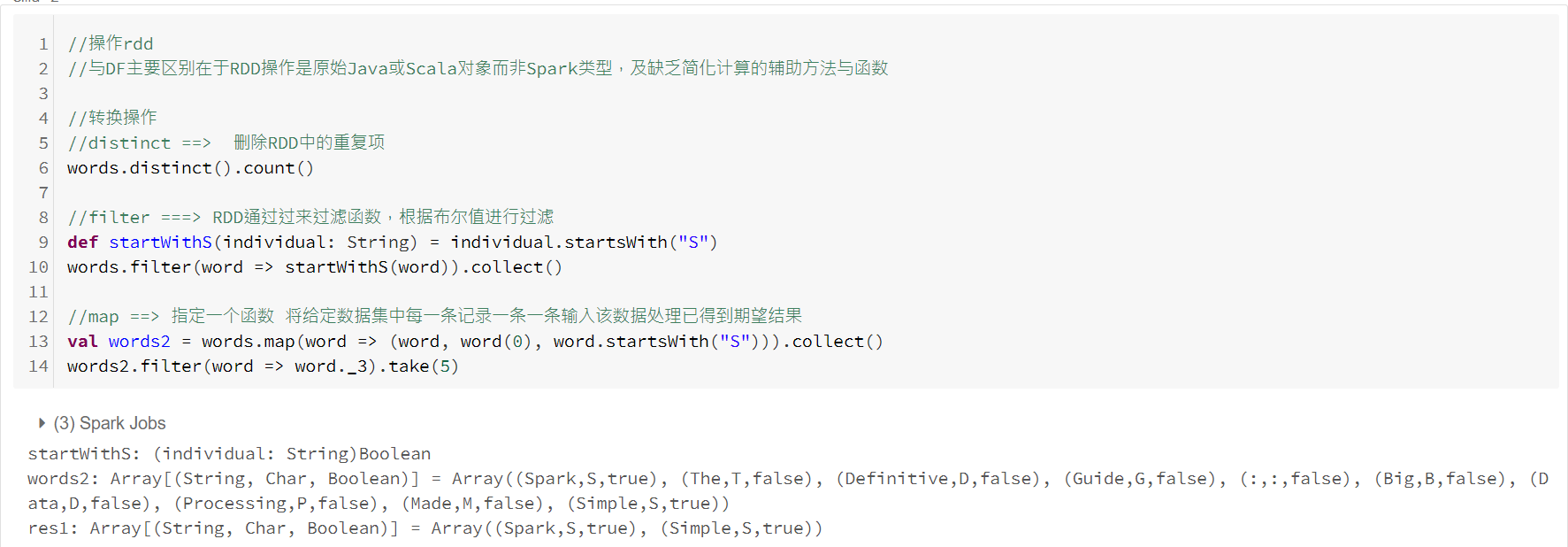
操作RDD
随机分割
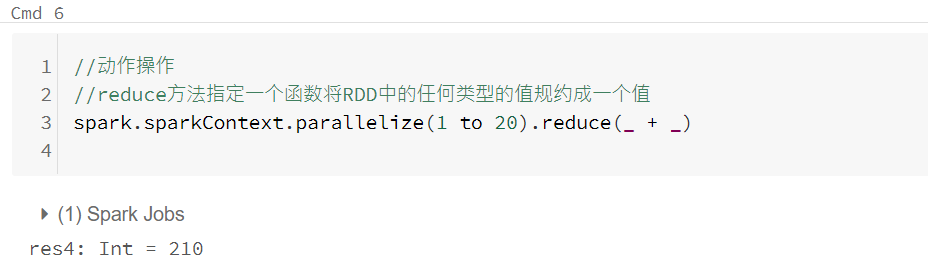
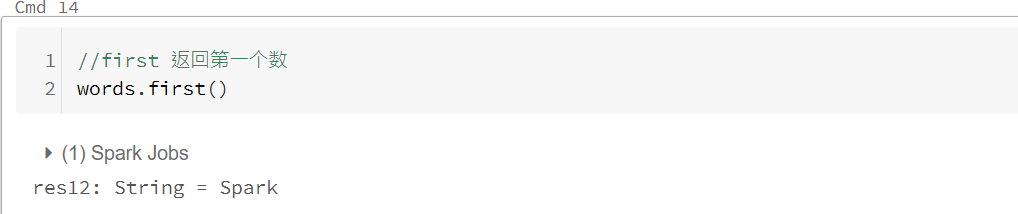
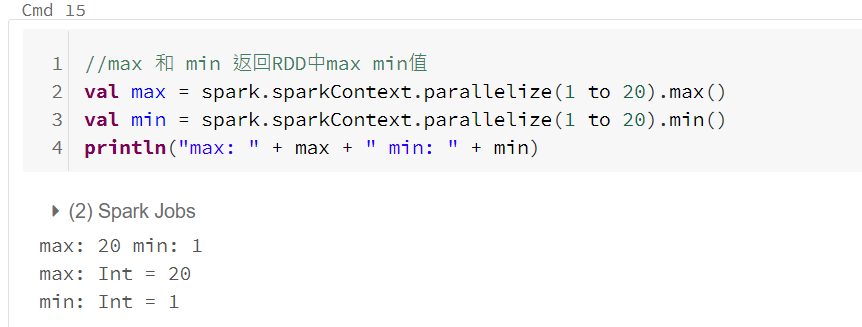
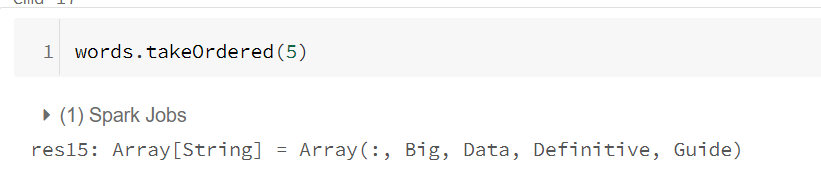
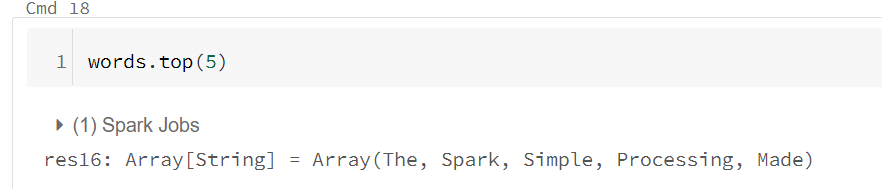
动作RDD
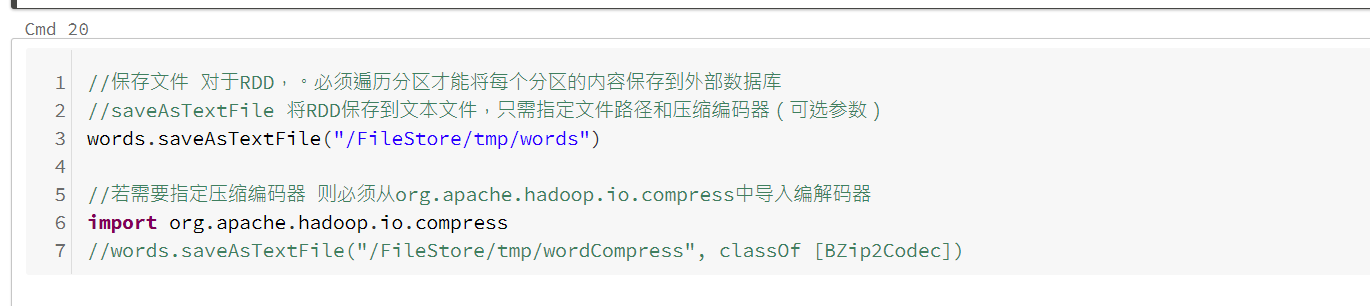
保存文件
缓存 与 检查点
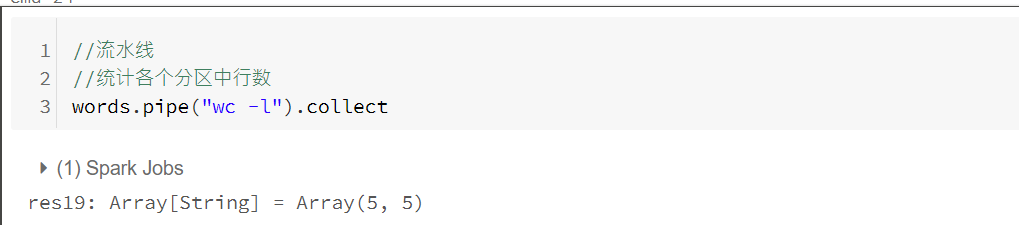
流水线方法
通过流水线技术调用外部进程来生成RDD,将每个数据分区交给指定外部进程来计算结果RDD。每个输入分区的所有元素被当作另一个外部进程的标准输入,输入元素由换行符分隔。最终结果由该外部进程的标准输出生成,标准输出的每一行产生输出分区的一个元素,空分区也会调用一个外部进程。

















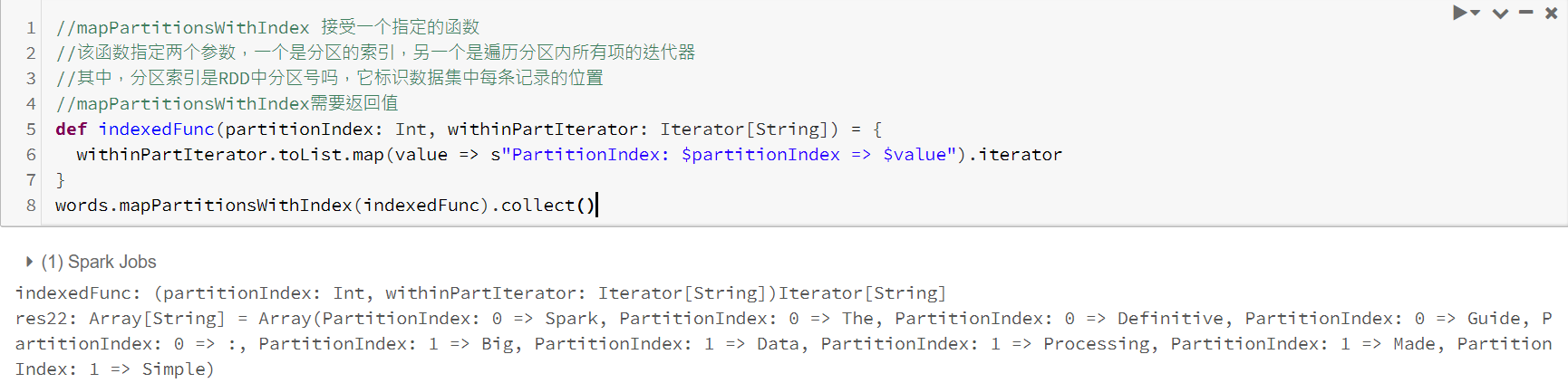

二、高级RDD
KV RDD 基础
聚合操作
连接操作
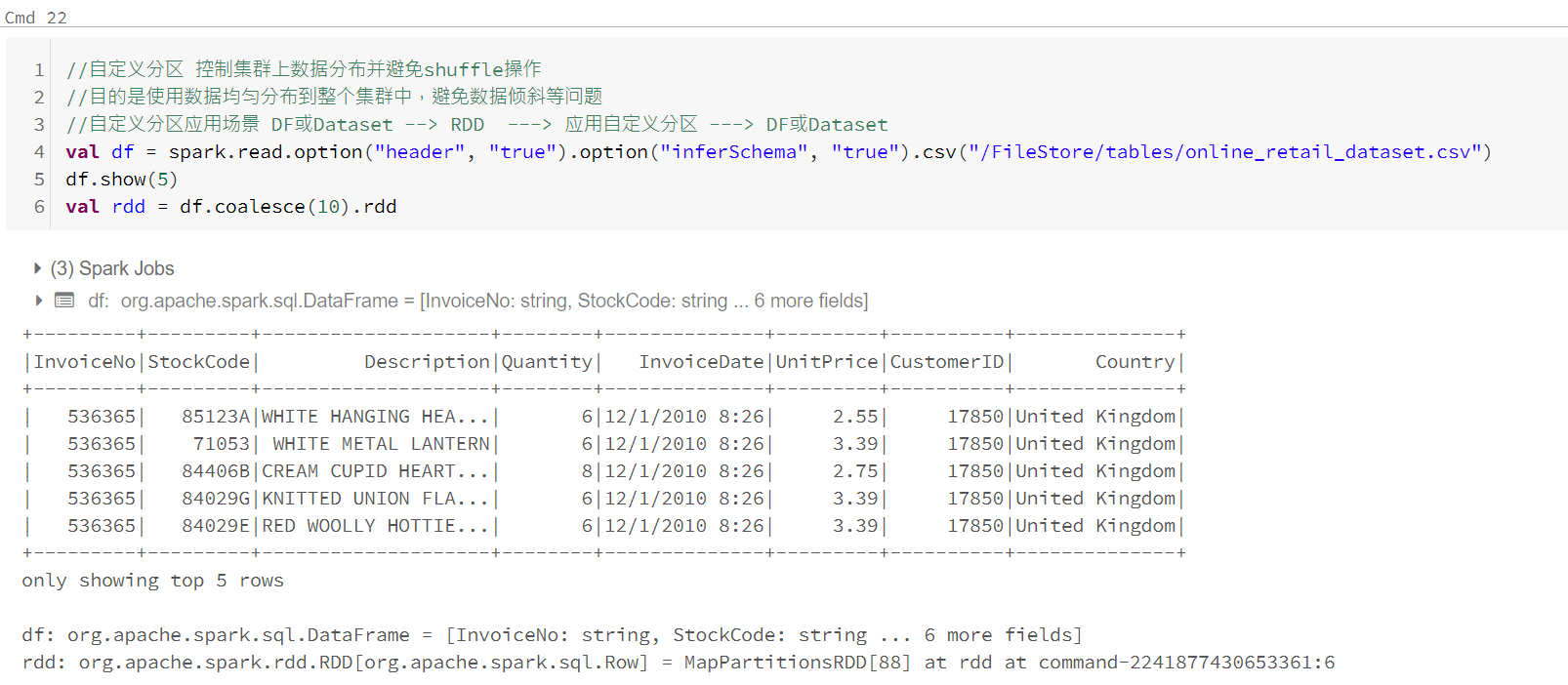
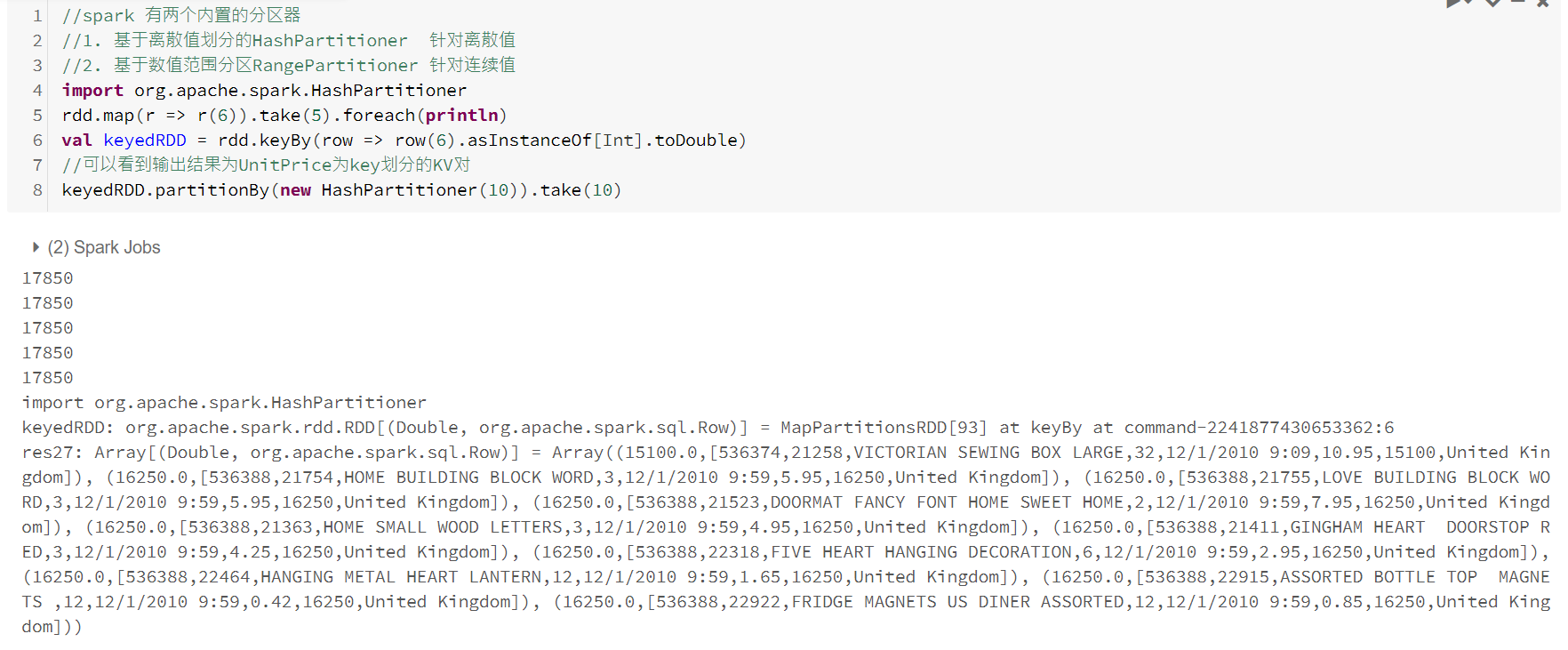
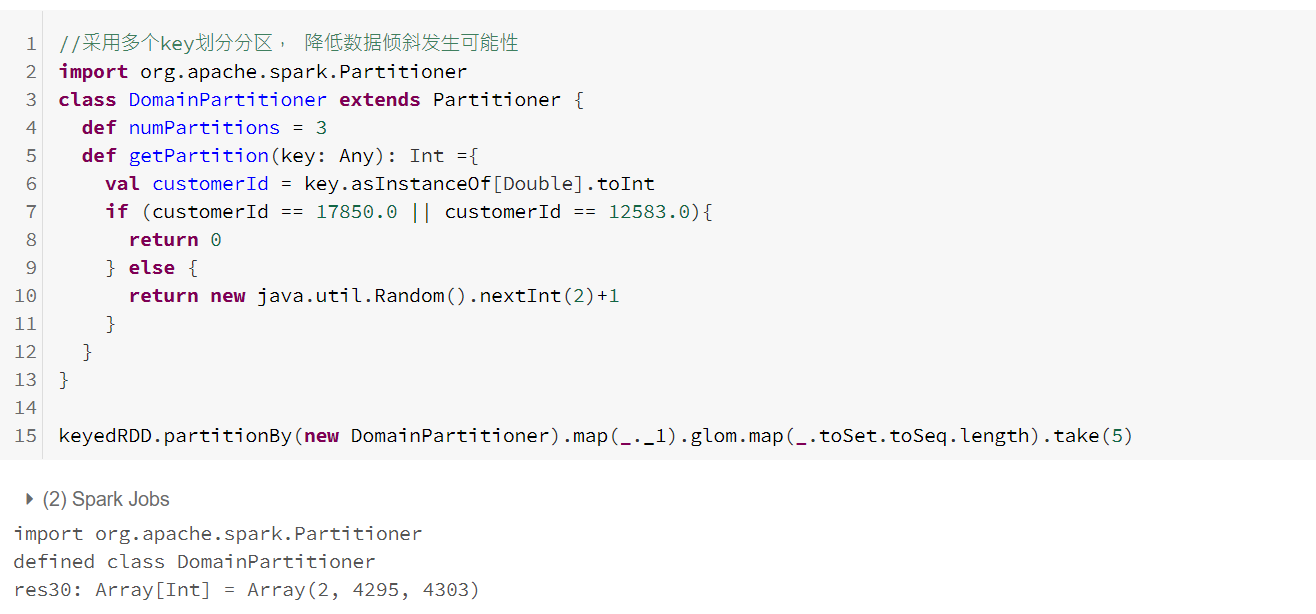
控制分区
分区器(详细理解参考:https://www.cnblogs.com/liuming1992/p/6377540.html)
自定义序列化











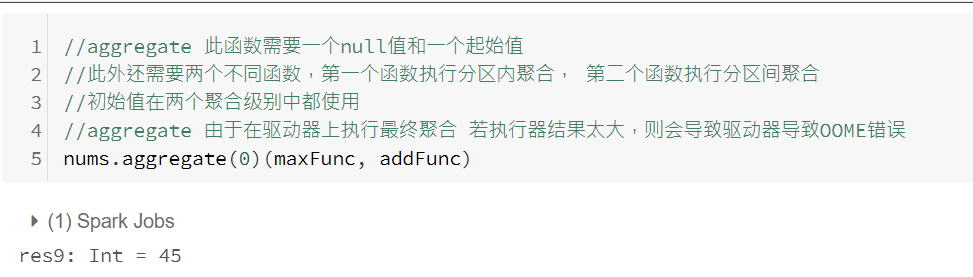


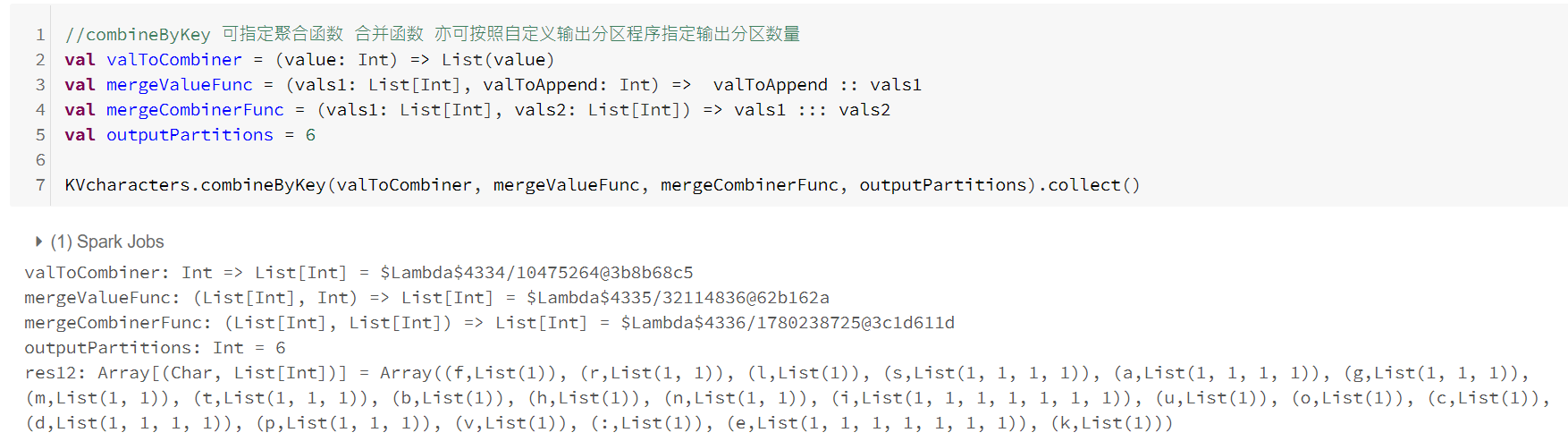







三、分布式共享变量
Spark中分布式共享变量主要包括两种类型: 广播变量和累加器。
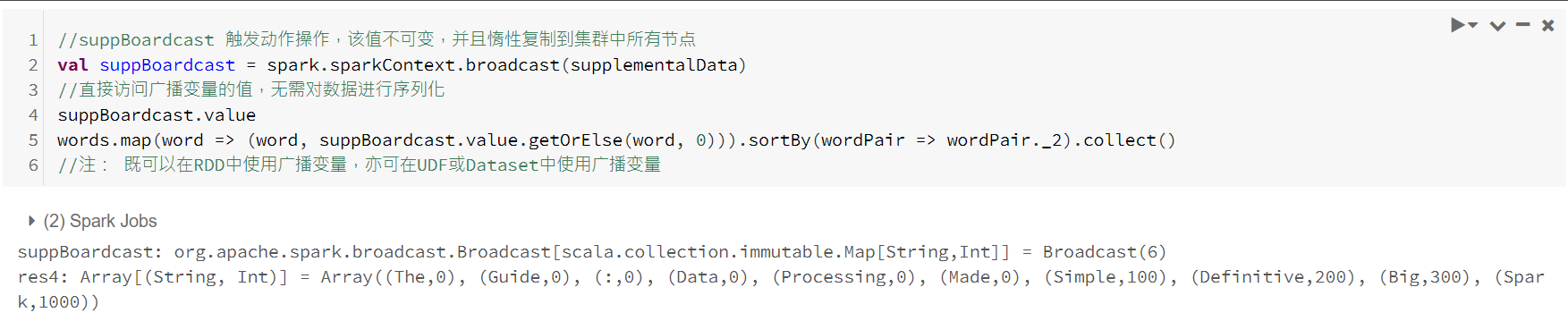
广播变量
通过使用广播变量可以在集群中有效地共享(只读的)不变量,而不需要将其封装到函数中。在驱动节点上使用变量的一般方法为简单的在函数闭包中引用,但是这种情况必须在工作节点上执行多次反序列化(每次任务依次)。如果在多个Spark操作和作业中使用了相同的变量,将重复发送到工作节点的每一个作业,而不是发送一次。
广播变量是共享的,不可修改的变量,它们缓存在集群中的每个节点上,而不是在每个任务中都反复序列化。


三、累加器
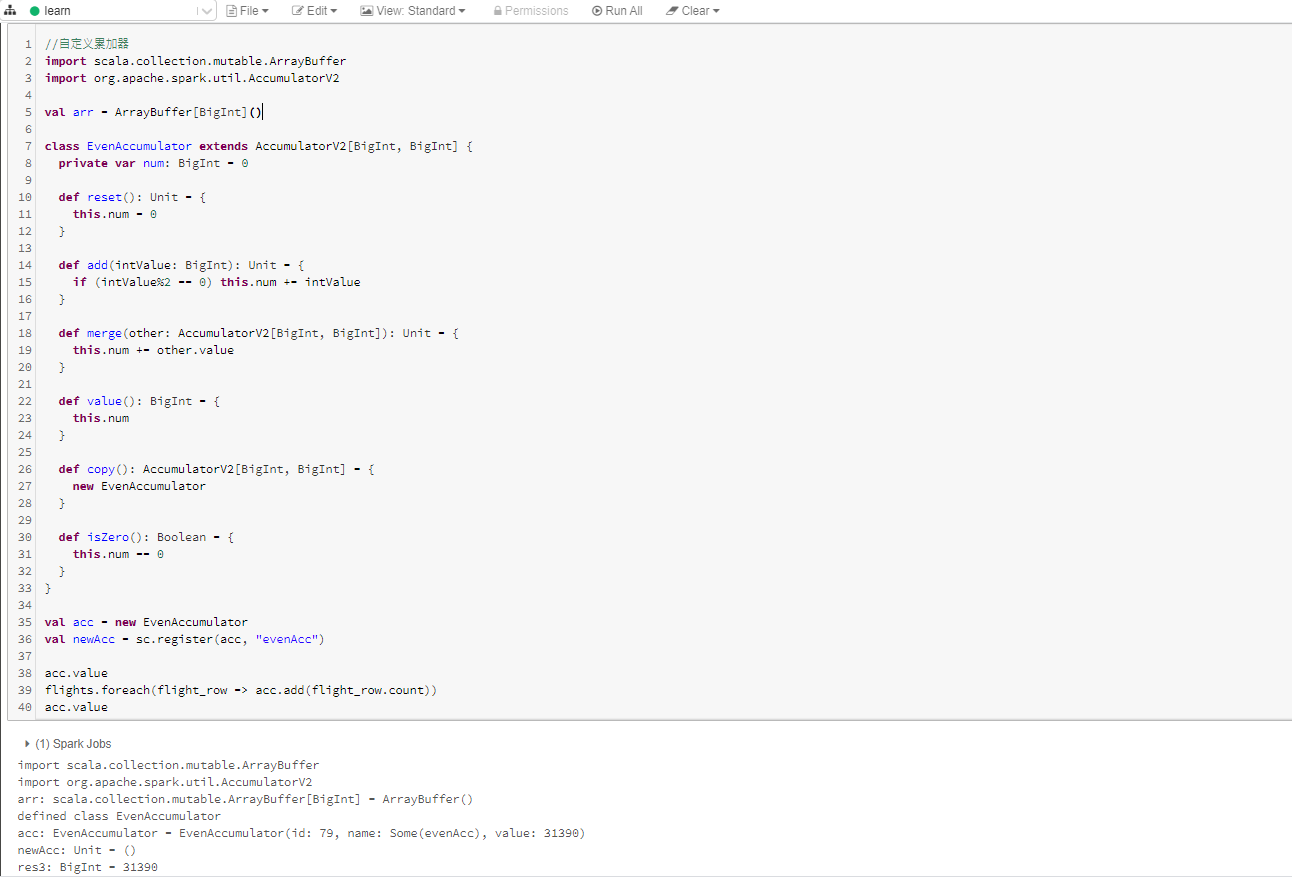
累加器提供一个累加用的变量,Spark集群可以按行方式对其进行安全更新。累加器仅支持由满足交换律和结合律的操作进行累加的变量,因此累加器可以高效并行,实现计数器或求和操作。Spark提供对数字类型累加器的原生支持,程序员可以自动添加对新类型的支持。
对于仅发生在动作操作内执行的累加器更新,Spark保证每个人物对累加器的更新将只发生一次,重新启动并不会再次更新该值。但是在转换操作中,如果任务或作业阶段重新执行,应注意累加器更新可能发生多次。
累加器遵循Spark的惰性评估机制,若RDD某个操作要更新累加器,则它的值只会在实际计算RDD时更新。
命名累加器可以在Spark用户界面上显示它们的运行结果,而未命名累加器则不会显示出来。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号