

Spark权威指南读书笔记(三) 处理不同的数据类型
Spark权威指南读书笔记(三) 处理不同的数据类型
一、转换成Spark类型
使用lit函数将原始类型转换为Spark类型

二、处理布尔类型
布尔语句由四个要素组成: and、or、true和false。
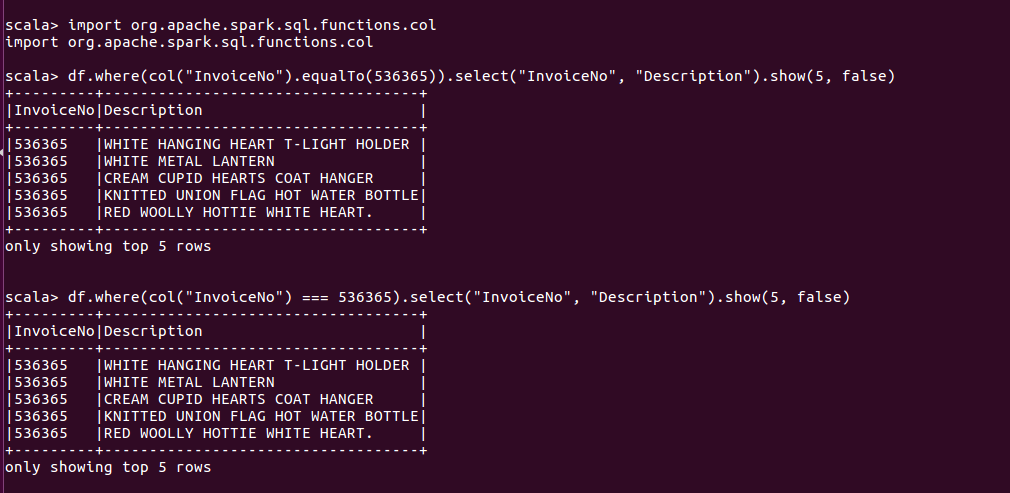
scala中有一些关于 == 和 ===用法的特殊语义。在Spark中,如果想通过相等条件来进行过滤,应该使用 ===(等于) 或 =!=(不等于)符号,还可以使用not函数和equalTo方法实现。
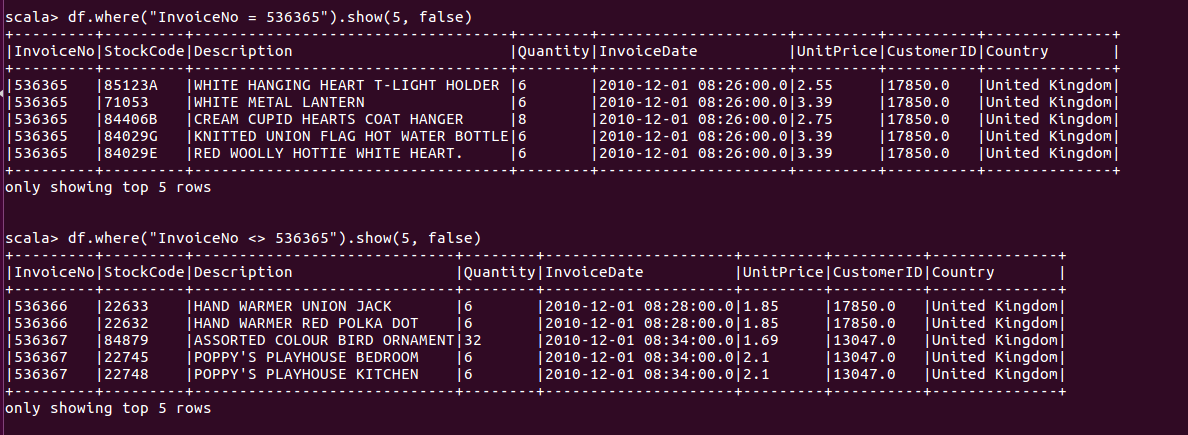
另一种方法是使用字符串形式的谓词表达式
对于链式连接的方式, Spark会将所有过滤条件合并为一条语句,并同时执行这些过滤器,创建and语句。
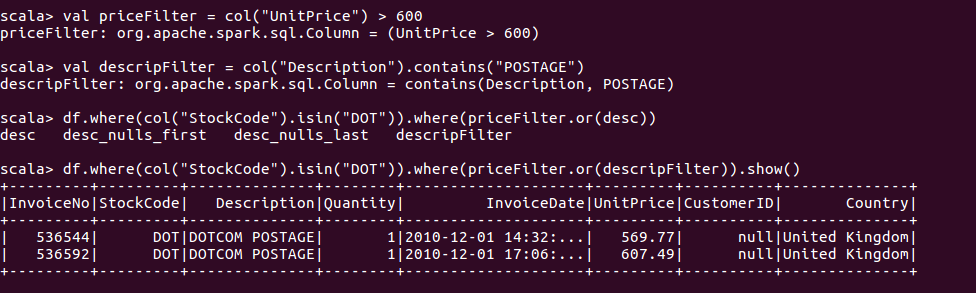
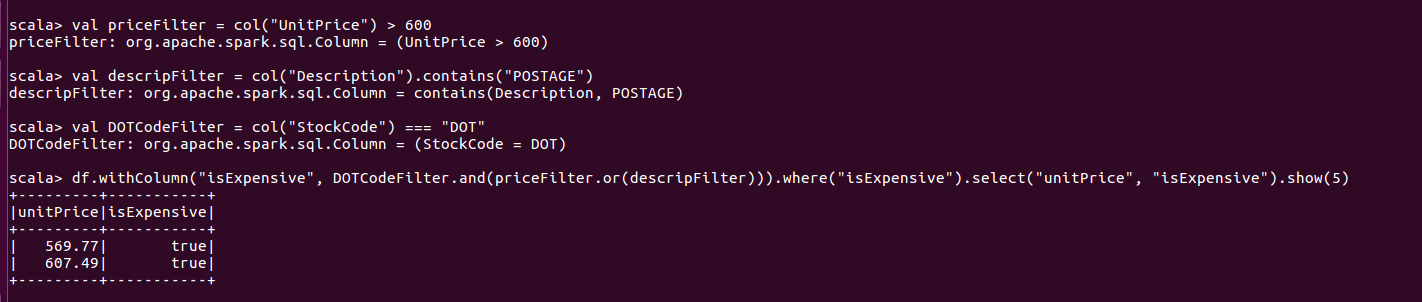
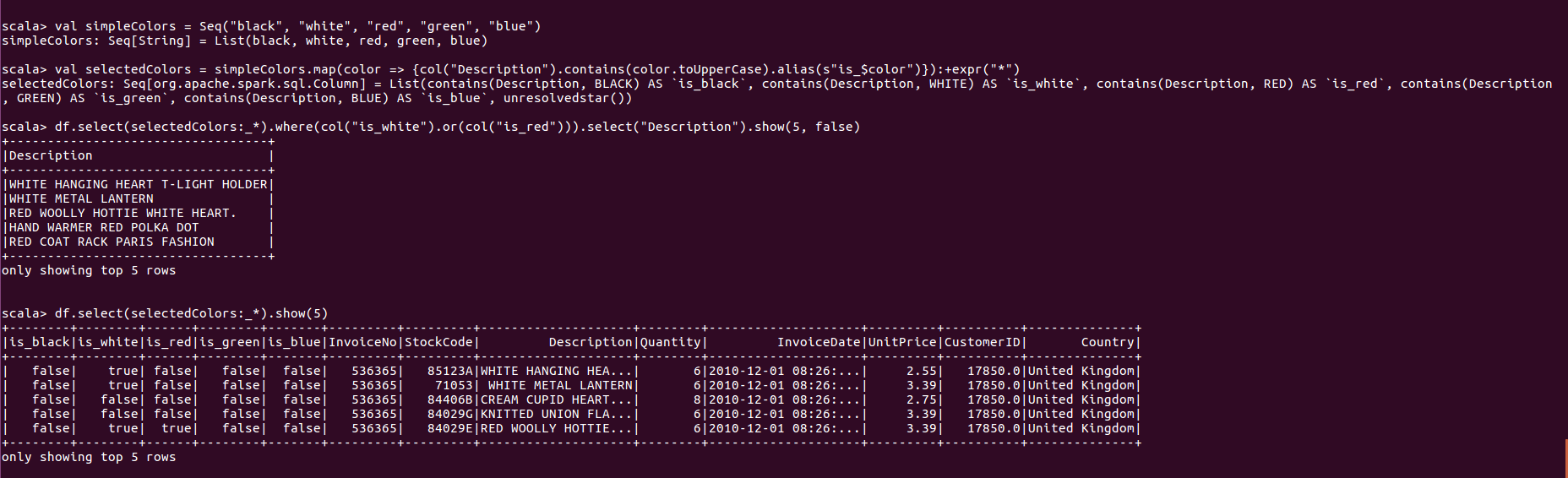
构建过滤列
注:创建布尔表达式时,需注意空值处理否则易出现问题。可使用以下语句保证执行空值执行的等价测试。

三、处理数值类型
1.基础运算
2.四舍五入
使用round或bround函数进行四舍五入,round/bround支持某个精度级别的转换, 若恰好处于两数之间,则round函数会向上取整, bround函数向下取整。
3.计算两列相关性(以Pearson系数为例)
$$
\rho = \frac{cov(X, Y)}{\sigma x \sigma y} = \frac{E[(X-\mu x)(Y - \mu y)]}{\sigma x \sigma y} \\
r = \frac{\sum_{i = 1}^{n} (X_i - \bar X)(Y_i - \bar(Y) }{\sqrt[]{\sum_{i = 1}^n (X_i - \bar X)^2} \sqrt[]{\sum_{i = 1}^n (Y_i - \bar Y)^2}} \\
r = \frac{1}{n-1} \sum_ {i = 1} ^ n
$$
- 当 r > 0时, 表示两个变量正相关,即一个变量值越大则另一个变量也会越大
- 当 r < 0时, 表示两个变量负相关, 即一个变量值越大则另一个变量值反而越小
- 当 r = 0时, 表示两个变量不是线性相关
- 当 r = 1 或 r = -1时, 意味着两个变量X和Y适合用直线方程描述
4.计算一列或一组列的汇总统计信息
使用describe方法,可以计算所有数值类型列的计数、平均值、标准差、最小值和最大值(更精确统计函数使用StatFunctions包)
5.行ID
使用monotonically_increasing_id函数为每行添加一个唯一的ID,它会从0开始,为每行生成一个唯一值。

四、处理字符串类型
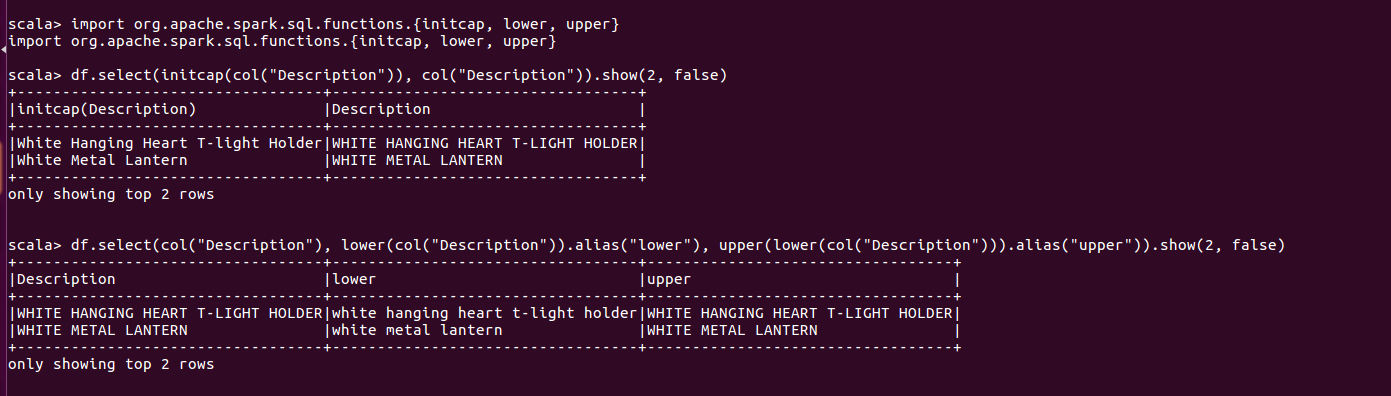
1.大小写
使用initcap函数将会给定字符串中空格分隔的每个单词首字母大写,使用upper或lower将字符串转为大写或小写
2.处理字符串周围的空格
注:如果lpad或rpad输入数值参数小于字符串长度,它将从字符串右侧删除字符。

五、正则表达式
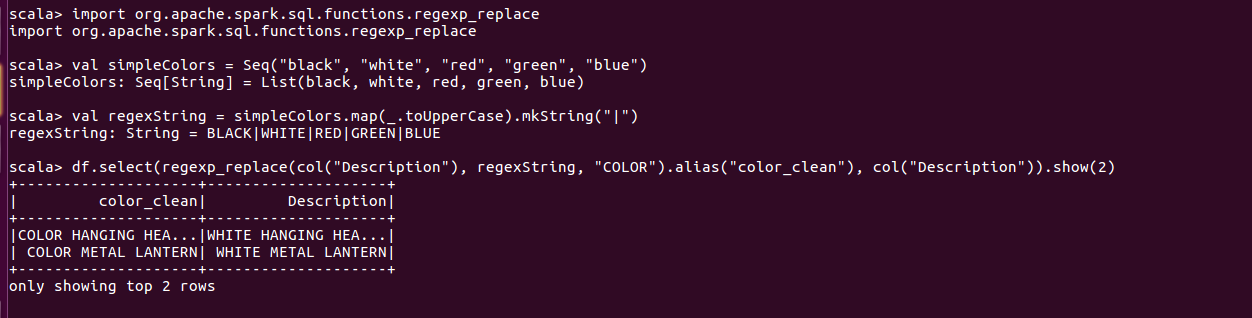
1.regexp_replace替换值
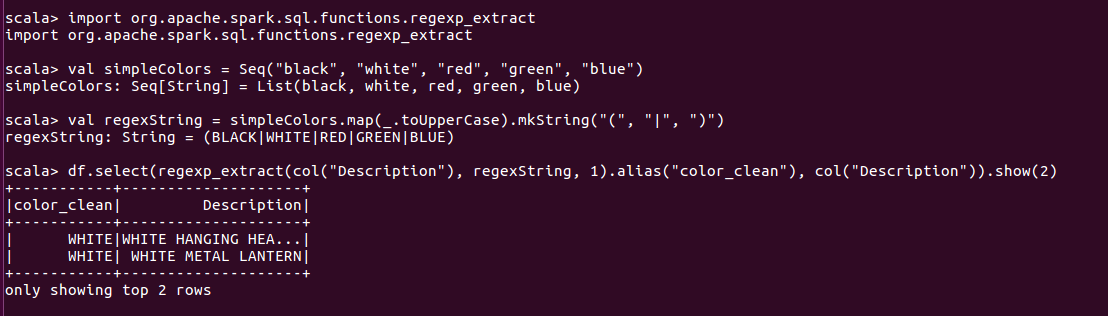
2.regexp_extract提取值
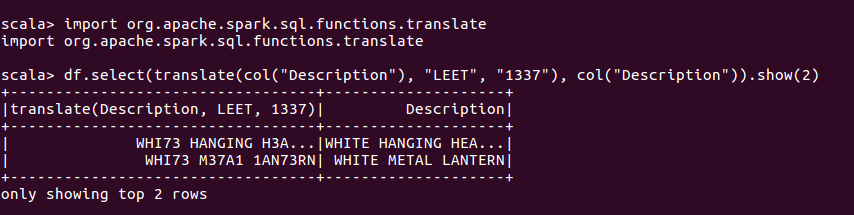
3.使用translate函数实现字符替换工作
这是在字符级上完成的操作,并将用给定字符串替换掉所有出现的某字符串。
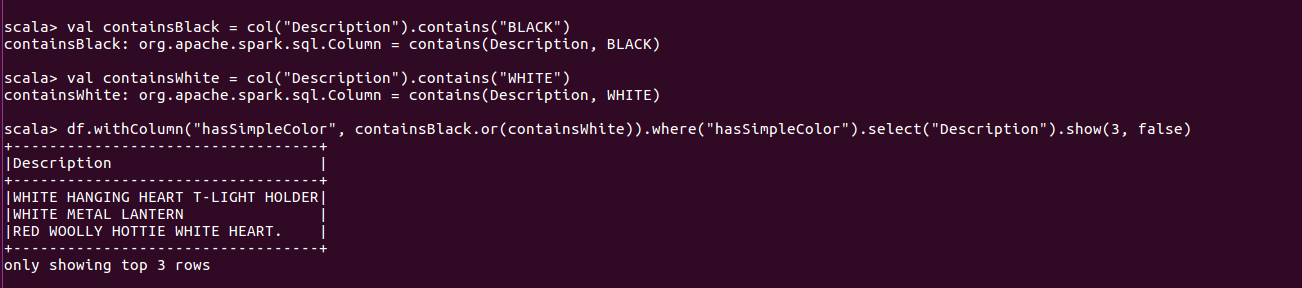
4.使用contains检查是否存在, 返回布尔值
使用不定量参数解决问题
六、处理日期和时间戳类型
Spark内部有日历日期的data, 及包括日期和时间信息的timestamp。Spark会尽最大努力正确识别列数据类型。当设置inferSchema为true时,Spark会自动推理出日期与时间戳数据类型。
注:在2.1版本及之前,如果时区没有被显示指定,Spark会根据计算机时区进行解析。如果有必要的情况下,可以通过设置spark.conf.sessionLocalTimeZone设置会话本地时区,根据java的TimeZone格式设置。
Spark的TimestampType类只支持二级精度,这意味着如果处理毫秒或微秒,可能需要将数据作为Long型操作才能解决问题。再强制转换为TimeStampType时, 任何更高精度都被删除。
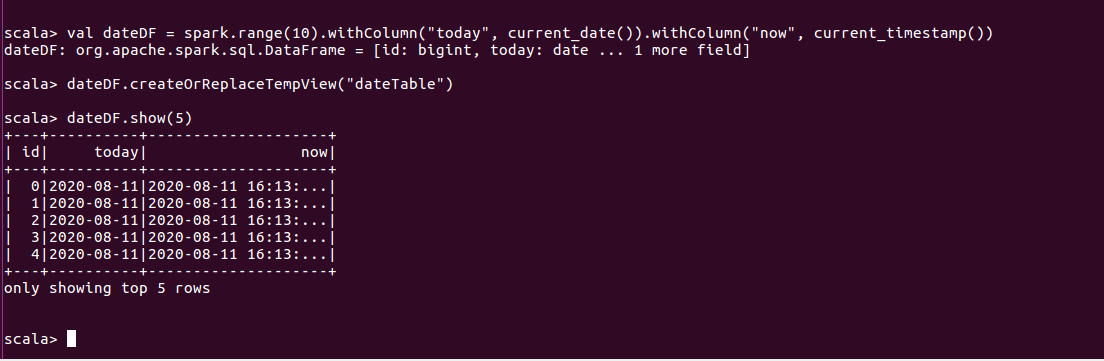
1.使用current_date current_timestamp获取当前日期和当前时间
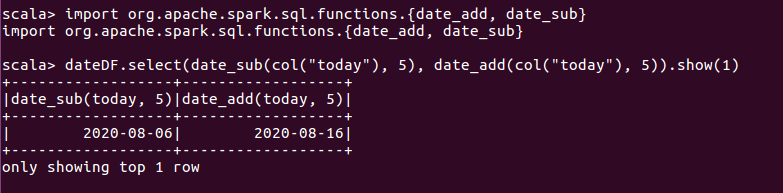
2.date_add date_sub增减天数
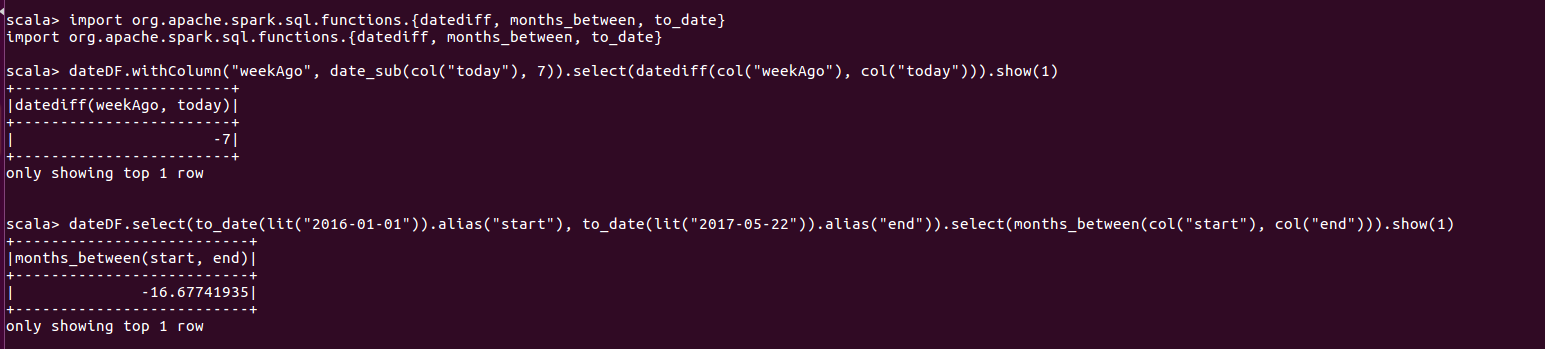
3.使用datediff返回两个日期之间的天数, months_between返回两个日期之间的月数
4.to_date 使用指定格式将字符串转换为日期数据
须使用java_simpleDateFrame指定想要的格式。如果Spark无法解析日期,其不会抛出错误,而只是返回null。
解决此类问题,需要根据Java SimpleDataFormat标准指定日期格式。
to_date选择指定一种日期格式, to_timestamp强制要求使用一种日期格式
注:面对可能需要处理null值或不同时区及格式的日期时,建议使用显示类型转换,切勿使用隐式类型转换。


七、空值处理
在实际应用中,建议始终使用null来表示DF缺少或空的数据。使用null值有利于Spark进行优化。基于DataFrame, 处理null值主要使用.na子包。
注:对于Spark而言,显式处理空值比隐式处理较好。当声明列没有空值时,这并不是实际意义上的强制无空值,当定义一个数据模式时,其中所有的列被声明为不具有null值类型时,Spark不会强制拒绝空值插入。空值设置本身只是为了帮助Spark SQL处理该列时进行优化。
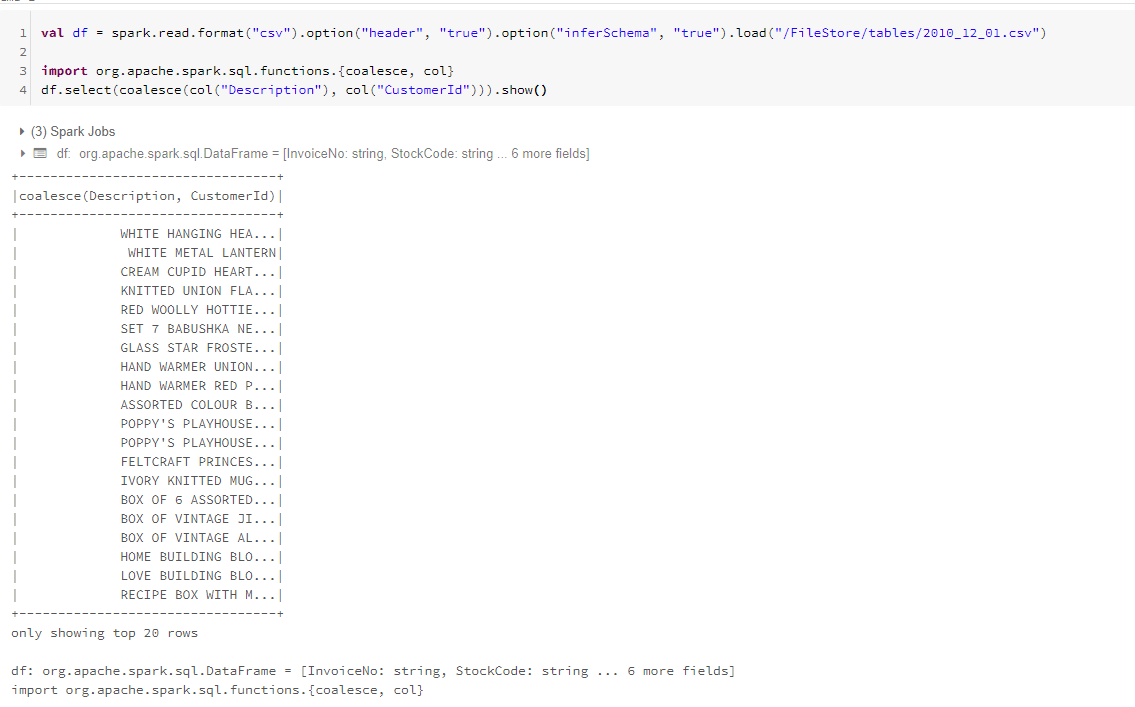
1.合并
使用coalesce函数,实现从一组列中选择第一个非空值,即第一个空值
2.ifnull、nullif、nvl、nvl2等SQL函数
ifnull =》如果第一个值为空,则选择第二个值,并将其默认为第一个。
nullif =》 如果两个值相等,则返回null, 否则返回第二个值
nvl =》 若第一个值为null, 则返回第二个值,否则返回第一个值
nvl2 =》 若第一个值不为null, 返回第二个值, 否则他将返回第一个值
3.drop
使用drop删除包含null的行,默认删除包含null值的行。若指定“any”作为参数,当存在一个值为null时,即删除该行;若指定“all”为参数, 只有当所有的值为null或者NaN才能删除该行。也可以通过指定某几列,来对列进行删除空值操作。
df.na.drop() df.na.drop("any") df.na.drop("all") df.na.drop("all", Seq("StockCode", "InvoiceNo"))4.fill
fill函数可以使用一组值填充一列或多列,它可以通过指定一个映射(即一个特定值和一组列)来完成。
df.na.fill("All Null values become this string") //需要注意列的类型 df.na.fill(5, Seq("StockCode", "InvoiceNo")) //使用映射实现 val fillColValues = Map("StockCode" -> 5, "Description" -> "No Value") df.na.fill(fillColValue)5.replace
根据当前值替换掉 某列中所有值,唯一要求时替换值与原始值的类型相同。
df.na.replace("Description", Map("" -> "UNKNOWN"))
八、复杂类型
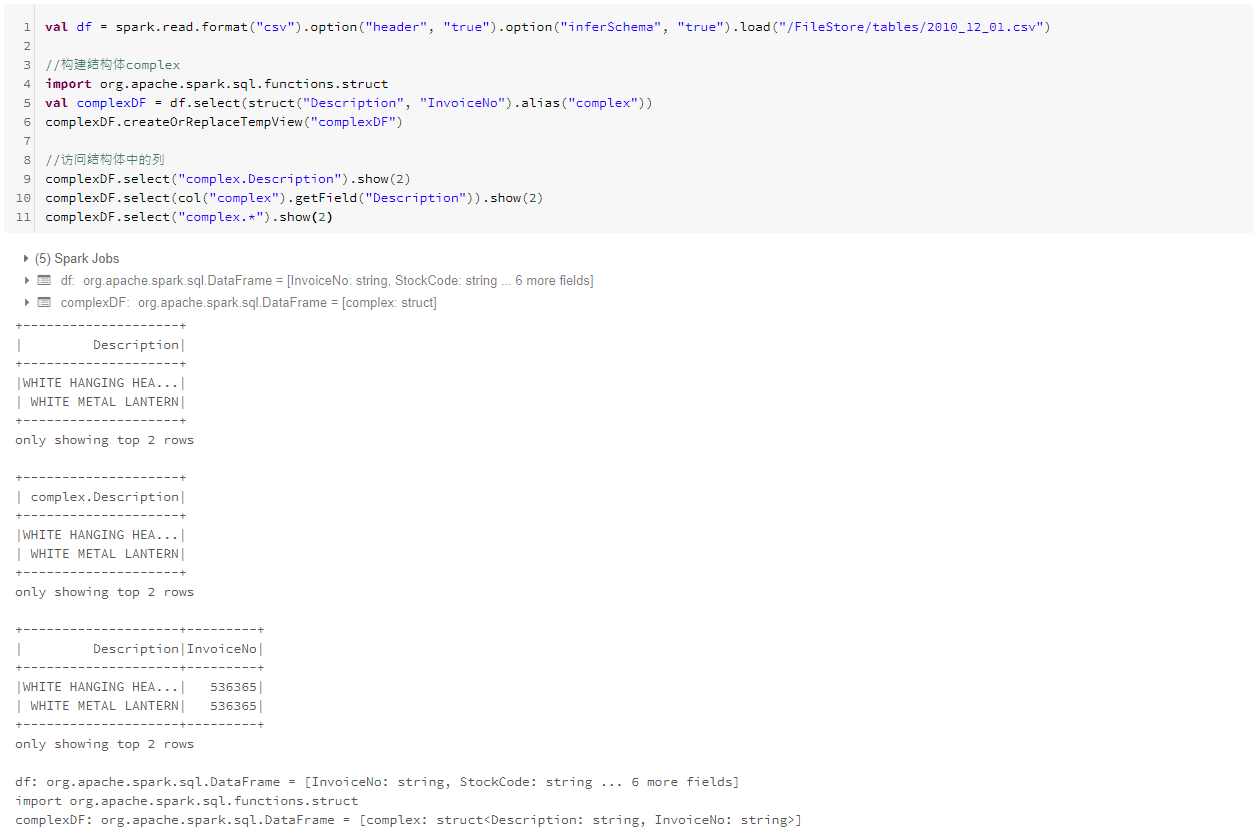
1.结构体
结构体可以使用“.”访问列或使用getField方法,还可以使用*查询结构体中的所有值。
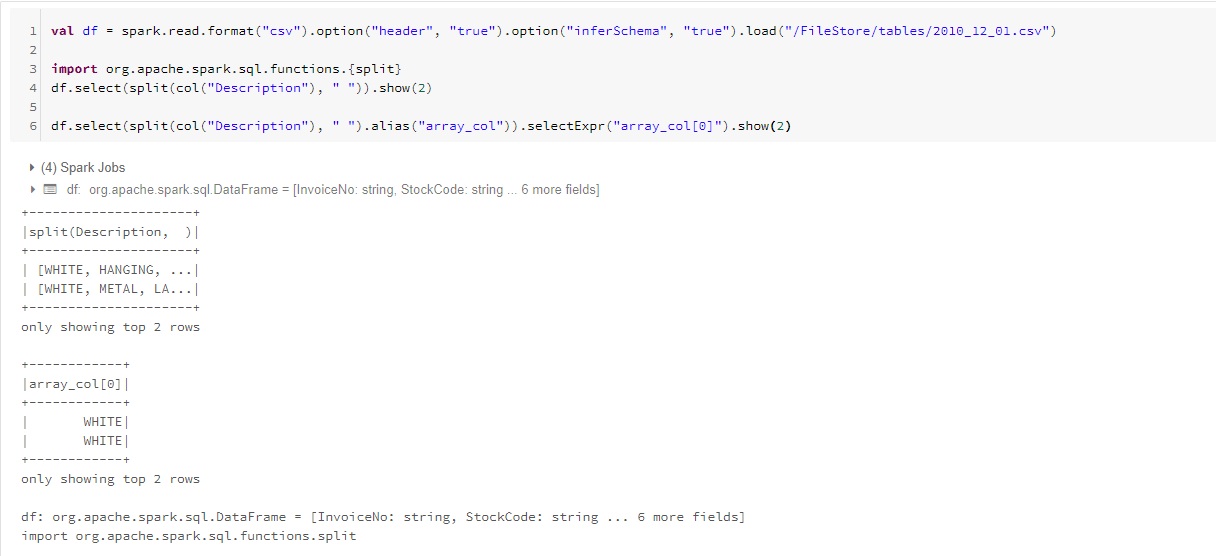
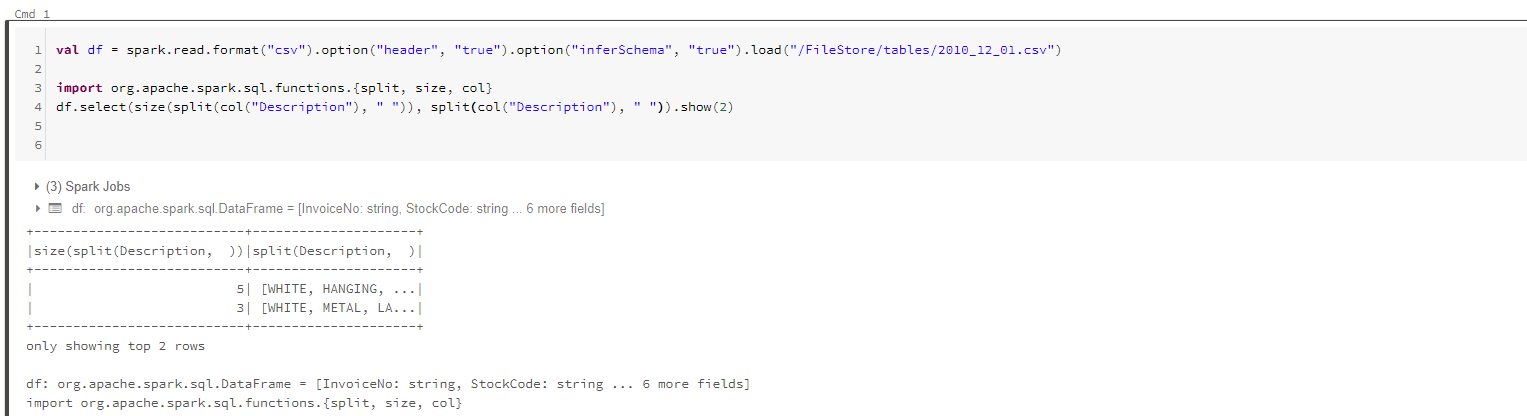
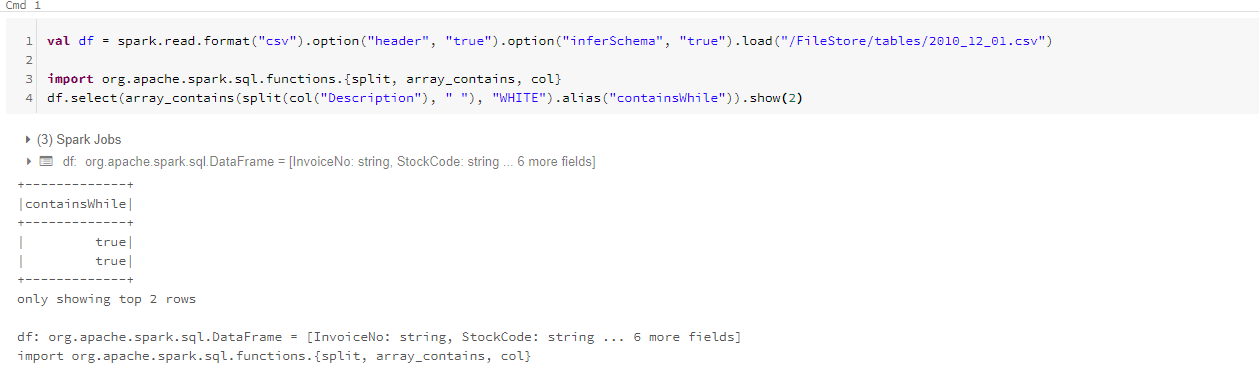
2.数组
split函数并指定分隔符执行操作
求数组长度
array_contains 查询数组是否包含某个值
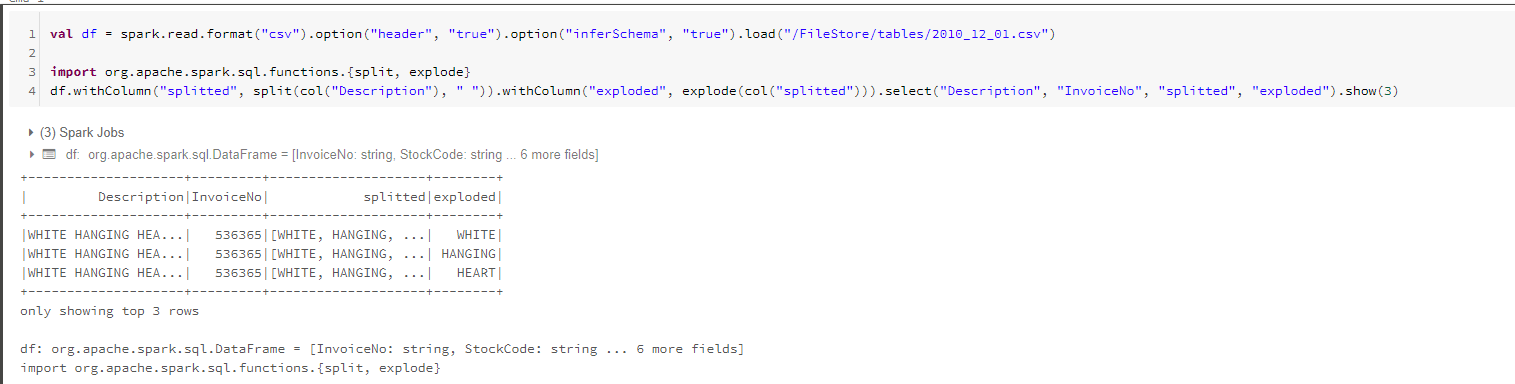
explode
explode函数输入参数为一个包含数组的列,并为该数组的每个值创建一行
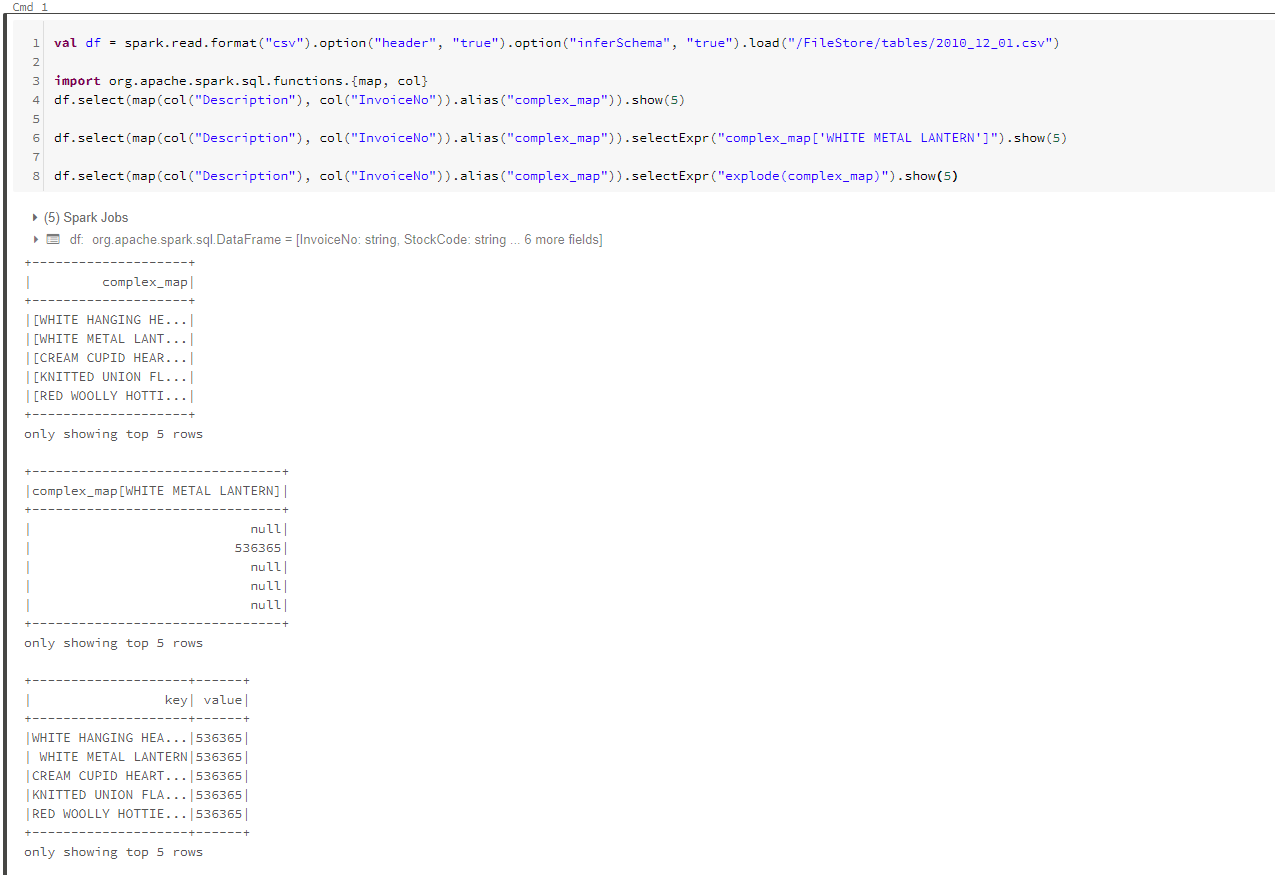
map
map映射是通过map函数构建两列内容键值对映射形式。
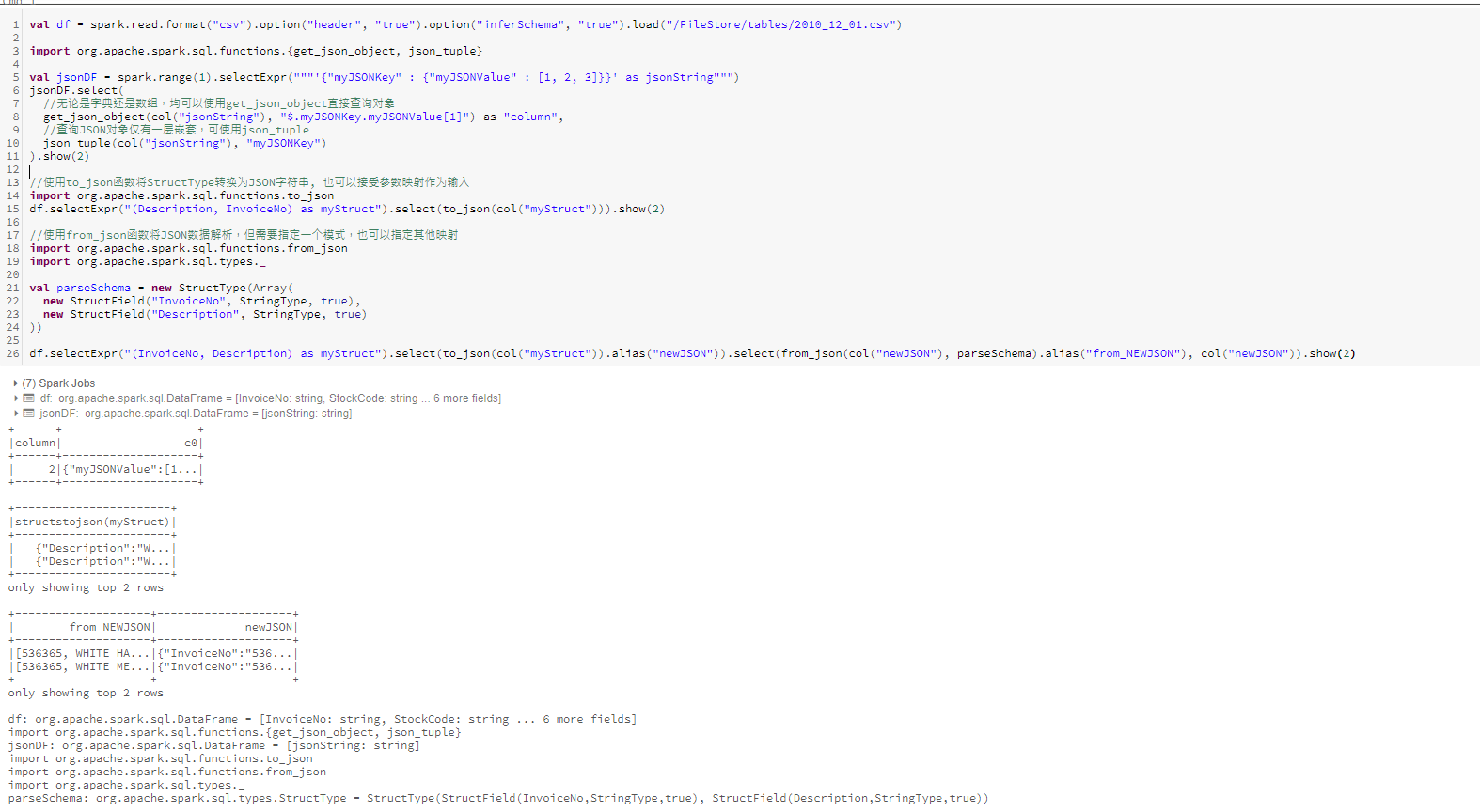
九、JSON类型
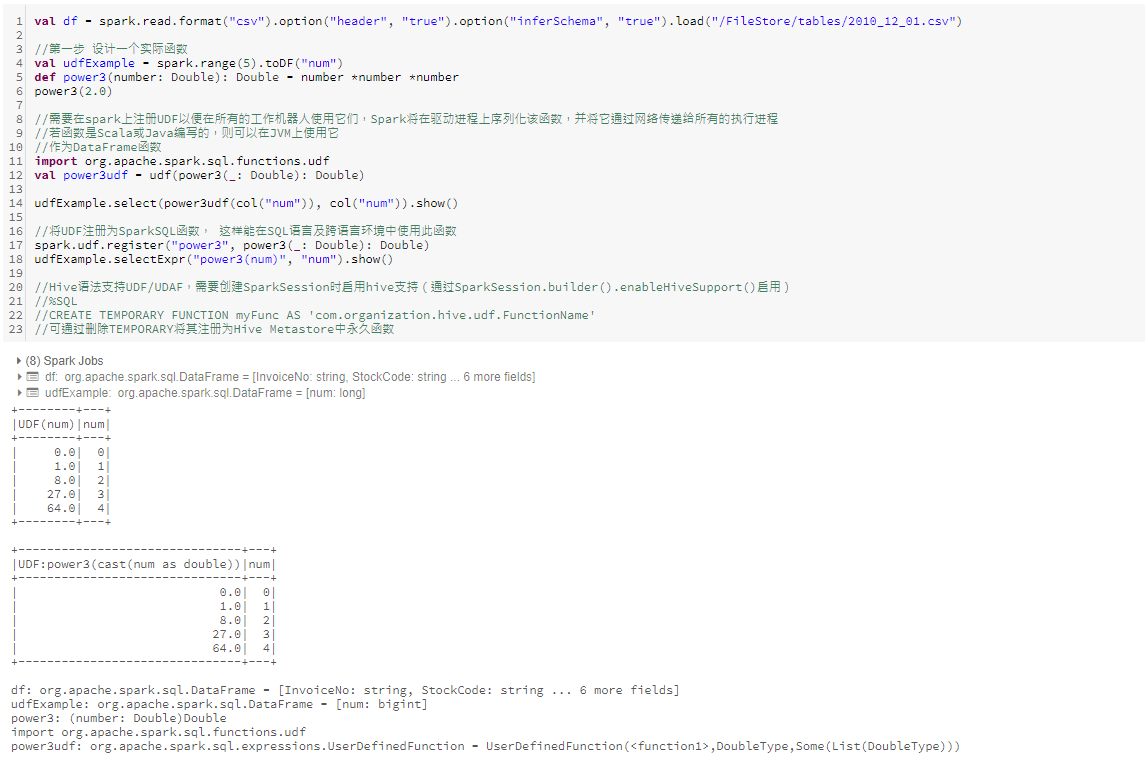
十、用户自定义函数
UDF,即用户自定义函数可以使用户使用python或scala编写自己的自定义转换操作,甚至使用外部库。UDF可以将一个或多个列作为输入,同时也可以返回一个或多个列。默认情况下,这些函数被注册为SparkSession或者Context的临时函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号