

Spark权威指南读书笔记(二) 结构化API
Spark权威指南读书笔记(二) 结构化API
一、结构化API综述与简介
结构化API是处理各种数据类型的工具,可处理非结构化的日志文件,半结构化的CSV文件,以及高度结构化的Parquet文件。
通常而言,结构化API主要指以下三种核心分布式集合类型API:
- Dataset类型
- DataFrame类型
- SQL表和视图
1.DataFrame类型 与 Dataset类型
DateFrame
具有行和列的类似于分布式数据表的集合类型,所有列的行数相同 ,可用null指定缺省值,每一列的所有行必须保持一致的数据类型。DataFrame代表不可变数据集合,可通过它指定特定位置数据操作,该操作以惰性评估方式执行。
Dataset
具有行和列的类似于分布式数据表的集合类型,所有列的行数相同 ,可用null指定缺省值,每一列的所有行必须保持一致的数据类型。Dataset代表不可变数据集合,可通过它指定特定位置数据操作,该操作以惰性评估方式执行。
DataFrame 与 Dateset对比
实质上,结构化API包含两类API,即非类型化的DataFrame和类型化的Dataset。准确来说,DataFrame具有类型,只是Spark完全负责维护它的类型,仅在运行时检查这些类型是否与schema指定类型一致。Dataset在编译时会检查类型是否符合规范。Dataset仅适用于基于Java虚拟机的语言,并通过case class或Java beans指定类型。
2.Schema (模式)
Schema定义了DataFrame的列名与类型,可以手动定义或者从数据源读取。
3.Catalyst
Spark实际上具有自己的编程语言,其内部使用Catalyst引擎,在计划制定和执行作业过程中使用Catalyst维护自己的类型信息。
外部输入 --(API查找表)--> Catalyst优化编译----> 内部表示执行
4.行
一行对应一个数据记录,DataFrame中每条记录都必须是Row类型。可以通过SQL手动创建,或者从弹性分布式数据集(RDD)提取,或从数据源手动创建。某种角度上看来,在Scala版本Spark中,DataFrame是一些Row类型的Dataset集合。Row类型是Spark用于支持内存计算而优化的数据格式。这种格式有利于高效计算,因为其避免使用会带来昂贵垃圾回收开销和对象实例化开销的JVM类型,而是基于自己内部格式运行。
5.列
列表示一个类型。
二、Spark类型(Scala类型参考表)
数据类型 Scala值类型 获取或创建数据类型的API ByteType Byte ByteType ShortType Short ShortType IntegerType Int IntergeType LongType Long LongType FloatType Float FloatType DoubleType Double DoubleType DecimalType java.math.BigDecimal DecimalType StringType String StringType BinaryType Array[Type] BinaryType BooleanType Boolean BooleanType TimestampType java.sql.TimeStamp TimeStampType DataType java.sql.Date DataType ArrayType scala.collection.seq ArrayType(elementType)[contains null] MapType scala.collection.Map MapType(keyType, valueType)[value Contains null] StructType org.apache.spark.sql.Row StrcutType(fields) 【注:fields是一个包含多个StructField的Array,并且任意两个StructField不能同名】 StructField 该字段对应Scala的数据类型 StructField(name, dataType, [nullable]).【注:nullable默认为true】
三、结构化API执行
1.用户代码到执行代码的概述过程
- 编写DataFrame、Dataset或SQL代码
- 若代码可以有效执行,Spark可将其转换为一个逻辑执行计划
- Spark将此逻辑转换计划转化为一个物理执行计划,检查可行优化策略,并在此过程中检查优化。
- Spark在集群上执行物理执行计划(RDD操作)
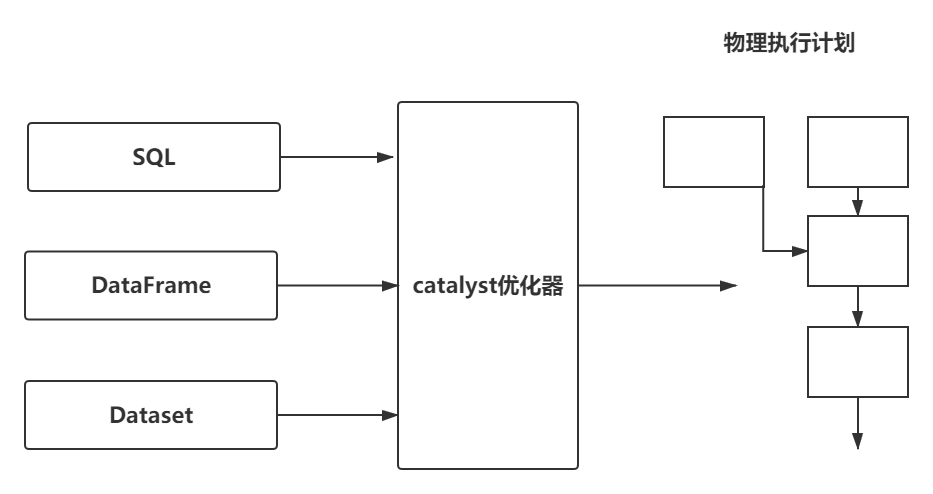
2.逻辑计划
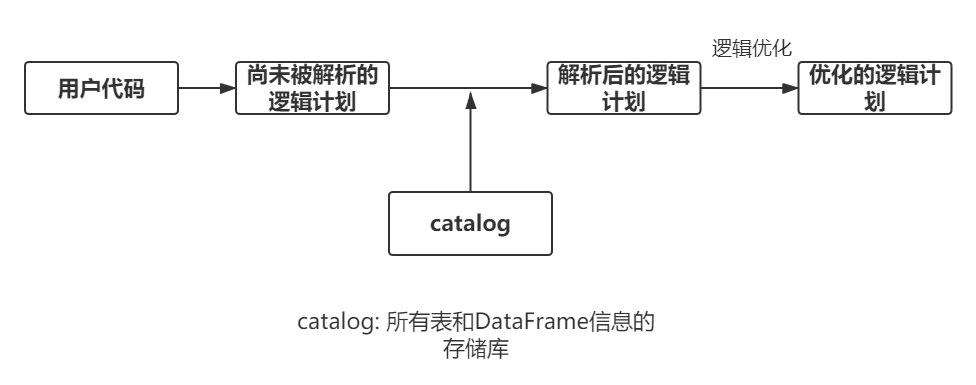
3.物理计划

四、基本结构化操作
1.Schema 模式
模式定义DataFrame的列名及列的数据类型,可以由数据源定义模式(读时 模式),亦可显式定义。
注:使用读时模式在某些状态下会造成数据精度损失问题。

一个模式是由多个字段构成的StructType。这些字段即为StructField,具有名称、类型、布尔标志(指定该列是否可以包含缺省值或空值),并且用户可指定与该列关联的元数据。元数据存储有关此列的信息。
2.列和表达式
列是逻辑结构,它只是表示根据表达式为每个记录( Row)计算出的值。这意味着要为列创建一个真值,需要有一行,而一行需要有DataFrame。
列的构造方法
常用的两种方法是通过col函数或者column函数,需要传入列名!


注1:DataFrame可能不包含某列,所以该列要将列名与catalog中维护的列名相比较后才会确定该列是否会被解析。
注2:列的其他引用方法 符号$将字符串指定为表达式,而符号(')指定一个symbol,是Scala引用标识符的特殊结构。

表达式
表达式是对一个DataFrame中的某条记录的一个或多个值的一组转换操作。它将一个或多个列名作为输入,解析他们,然后针对数据集中的每条记录应用表达式得到一个单值。
需要关注两点:
- 列只是表达式
- 列与对这些列的转换操作被编译后生成的逻辑计划,与解析后的表达式的逻辑计划是一样的。
可以使用columns查询DataFrame的所有列:

3.记录与行
在Spark中,DataFrame的每一行都是一个记录,而记录是Row类型的对象。Spark使用列表达式操纵Row类型对象,Row对象内部其实是字节数组。
显示第一行

创建行
只有DataFrame具有模式, 行对象本身没有模式, 这意味着,如果你手动创建Row对象,则必须按照该行所附属DataFrame的列顺序初始化Row对象。

注:直接通过位置获取的元素的类型为Any类型
4.DataFrame
DataFrame核心操作分类:
- 添加行或列
- 删除行或列
- 将一行转换操作为一列(或者将一列数据转换为一行)
- 根据列中的值更改行的顺序
创建DataFrame
- 由数据源构造
- 手动创建行构造

注:在Scala中可以使用Seq类型上运行toDF函数来利用控制台中Spark隐式方法,但由于对于null类型的支持并不稳定,故不推荐在实际生产中使用。

Select函数与SelectExpr函数

相当于
SELECT DEST_COUNTRY_NAME FROM dfTable LIMIT 2重命名操作
使用expr引用方式结合as, 或者expr配合alias使用
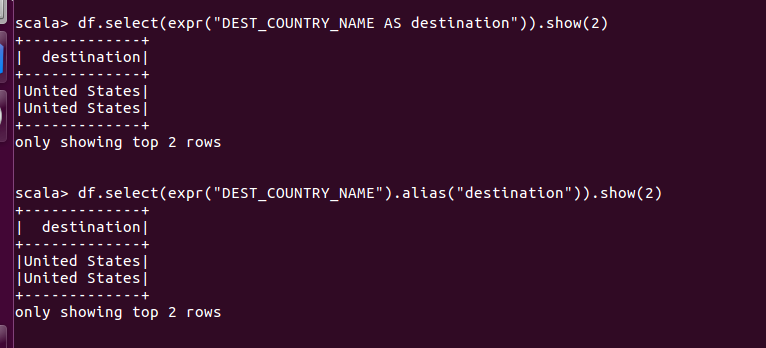
相当于
SELECT DEST_COUNTRY_NAME as destination FROM dfTable LIMIT 2SelectExpr
可以添加任何不包含聚合操作的有效SQL语句,并且只要列可以解析,即有效。
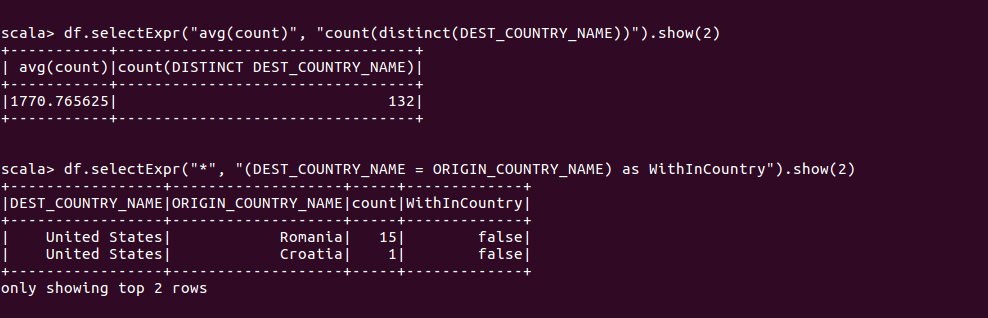
相当于
SELECT *, (DEST_COUNTRY_NAME = ORIGIN_COUNTRY_NAME) as WithInCountry FROM dfTable LIMIT 2 SELECT avg(count), count(distinct(DEST_COUNTRY_NAME)) FROM dfTable LIMIT 2字面量(将给定的编程语言的字面上的值转换操作为Spark可以理解的值)

相当于
SELECT *, 1 as One FROM dfTable LIMIT 2添加列
使用WithColumn可以为DataFrame添加新列,这种方式更为规范。withColumn函数有两个参数,列名和为给定行赋值的表达式。因此也可以使用WithColumn对列重命名
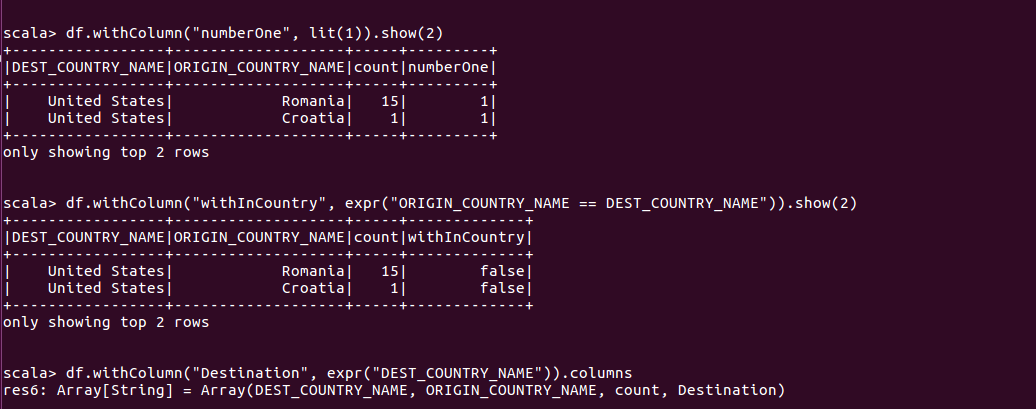
重命名列
上例中可见withColumn可以实现重命名列,此外还可以通过withColumnRenamed实现。withColumnRenamed中,第一个参数是被修改的列的名,第二个参数是新的列名。

保留字与关键字
区分大小写
spark默认是不区分大小写的,可通过配置Spark区分大小写:
set spark.sql.caseSensitive true删除列
使用drop方法删除列
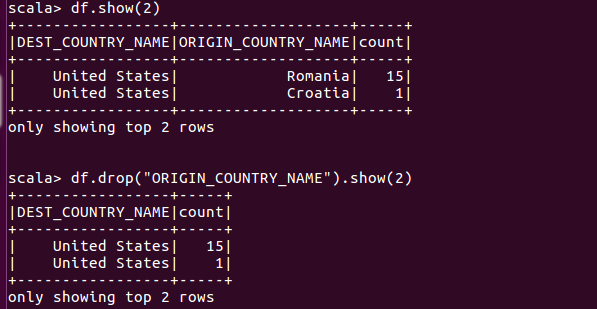
更改列的类型(强制类型转换)

过滤行
使用where或filter可以过滤使表达式为false的行,这二者执行相同操作,接受相同类型参数。
对于多个过滤条件,Spark会同时执行所有过滤条件操作,不管过滤条件的先后顺序,因此当指定多个AND过滤操作时,只需要按照先后顺序以链式方式将过滤条件串联起来即可。

注:在scala中,=!=运算符不仅能比较字符串,还能比较表达式。
去除

随机抽样
通过使用DataFrame的sample方法,它将按一定比例从DataFrame中随机抽取一部分行,也可以通过withReplacement参数是定是否放回抽样,true为有放回抽样,false为无放回抽样。

随机分割
可通过设置分割比例将DataFrame分割为两个不同的DataFrame,由于随机分割是一种随即方法,需指定一个随机种子。

联合操作
联合操作基于位置而非基于数据模式Schema执行,它不会自动根据列名匹配对齐后再进行联合,所以两个DataFrame需要具有完全相同的模式和列数,否则会失败。
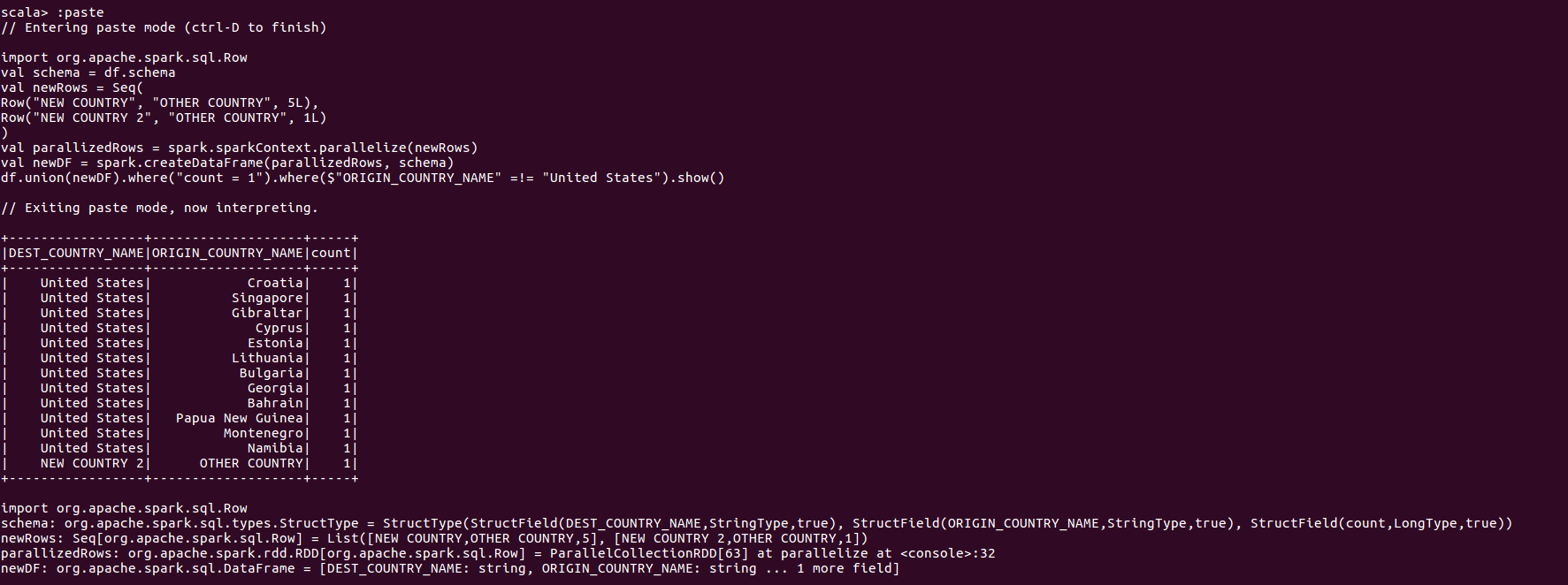
行排序
使用sort和orderby方法进行排序,二者执行方式一致。均接受列表达式和字符串,以及多个列。默认设置按升序排序。若要更明确地指定升序或降序,则需要使用asc函数和desc函数。
通过高级技巧,可以指定空值在排序列表中的位置,使用asc_nulls_first指示空值安排在升序排列前面,使用desc_nulls_first指示空值安排在降序排列前面,使用asc_nulls_last指示空值安排在升序排列后面,使用desc_nulls_last指示空值安排在降序排列后面。

出于性能优化目的,最好能够在进行别的转换操作前,先对每个分区进行内部排序,可以使用sortWithinPartitions.

Limit方法
重划分和合并
根据一些经常过滤的列对数据进行分区,控制跨集群数据物理布局,包括分区方案和分区数是一种重要优化。另一方面,合并操作不会导致数据全面洗牌,但会尝试合并分区。

驱动器获取行
为了遍历整个数据集,还有一种让驱动器获取行的方法,即toLocalIterator函数。toLocalIterator是一个迭代器,将每个分区数据返回给驱动器,这个函数允许你以串行方式一个个分区迭代整个数据集。
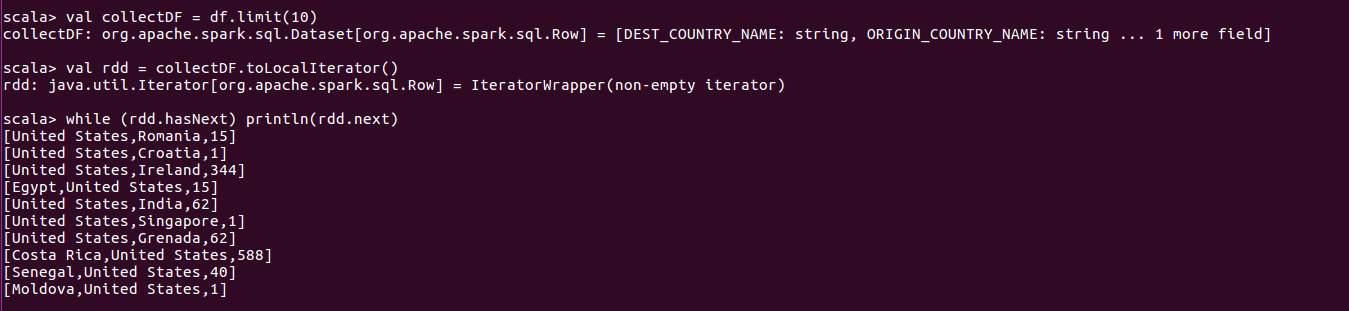
注:将数据集合传递给驱动器代码很高。当数据集很大时调用collect函数,可能会导致驱动器崩溃,使用toLocalItertor,并且分区很大的情况下,则容易导致结点崩溃并丢失应用程序状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号