

Spark权威指南读书笔记(一)
Spark权威指南读书笔记(一)
一、什么是Spark?
1.Spark设计哲学
- 统一平台
- 计算引擎(不考虑数据存储)
- 配套的软件库
二、Spark应用程序
spark应用程序由一个驱动器进程和一组执行器进程组成。
驱动器进程
负责运行main函数,主要负责三件事:
- 维护Spark应用程序的相关信息
- 回应用户的程序或输入
- 分析任务并分发给若干执行器进行处理
驱动器是Spark应用程序的核心,其在整个生命周期中维护者所有相关信息。
执行器进程
负责执行驱动器分配的实际计算任务,主要负责两件事:
- 执行驱动器分配给他的代码
- 将执行器的计算状态报告给运行驱动器的结点
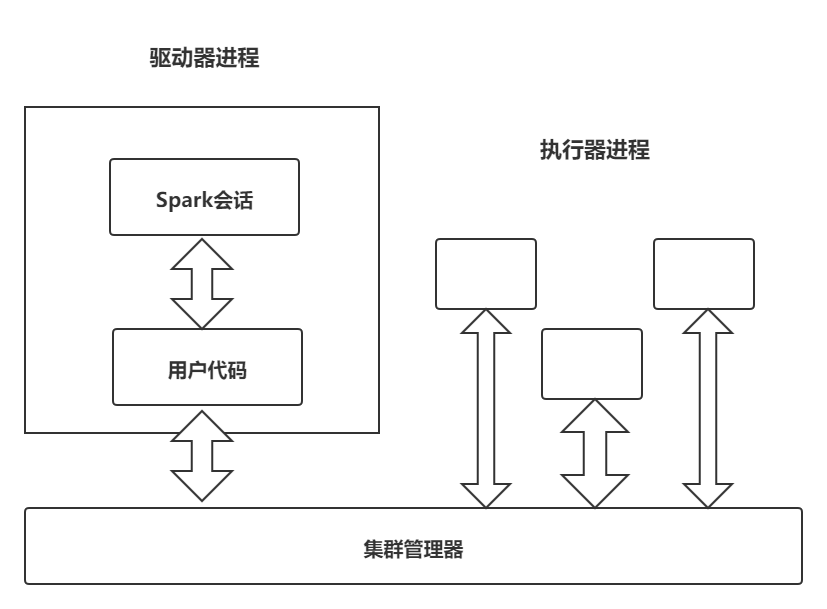
总结:
- Spark使用一个集群管理器跟踪可用的资源
- 驱动器进程负责执行驱动器命令完成给定的任务
三、转换操作
什么叫转换?
Spark的核心数据结构在计算过程中是保持不变的,意味着创建后无法更改!!!若你需要做出改变,需告知Spark如何修改满足需求,这个过程称为转换。
转换操作是使用Spark表达业务逻辑的核心,可分为两大类:指定窄依赖关系的转换操作和指定宽依赖关系的转换操作。
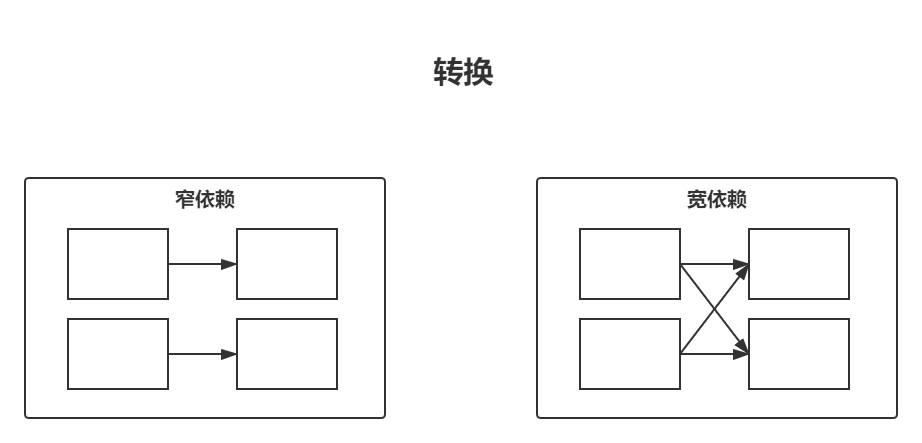
窄依赖转换与宽依赖转换
窄依赖转换是每个输入分区仅决定一个分区的转换。属于一对一映射关系。
宽依赖转换是每个输入分区决定了多个输出分区,这一操作常被称为shuffle,其将在集群中执行相互交换分区数据的 功能。属于一对多映射关系。
宽窄依赖潜度对比
对于窄依赖转换,Spark将自动执行流水线处理,这意味着在DataFrame指定多个过滤操作,将全部在内存中执行。
对于shuffle操作,即宽依赖转换,Spark会将结果写入磁盘。
惰性评估
惰性评估(lazy evaluation),即等到绝对需要才执行计算。具体而言,在Spark中,用户表达一些对数据的操作时,不是立即修改数据,而是建立一个作用到原始数据的转换计划。Spark首先会将计划编译为可在集群中高效执行的流水线式物理执行计划,然后等待,直到最后时刻才开始执行代码。因此,Spark可以优化了整个输入端到输出端的数据流。
动作操作
一个动作指示Spark在一系列转换操作后计算结果。
动作主要分为三类:
- 在控制台中查看数据的动作
- 在某个语言中将数据汇集为原生对象的动作
- 写入输出数据源的动作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号