
简单验证码识别及登陆并下载页面
1-背景
公司需要做一个抓取功能,抓取网站需要登录才可以抓取,登录有验证码,所以就有了该需求
2-实现
百度了好久,找到了OCR图文识别库,不过该库是C++编写,不过有一个.NET封装版本 ,那我们就开始折腾吧
2.1 分析网站获取验证码图片
a-通过查看网页源码可以看见,与登陆有关的js 是new_login.min.js,我们把它下载下来,然后格式化查看就得到了,验证码获取方法和验证码校验方法以及登录方法
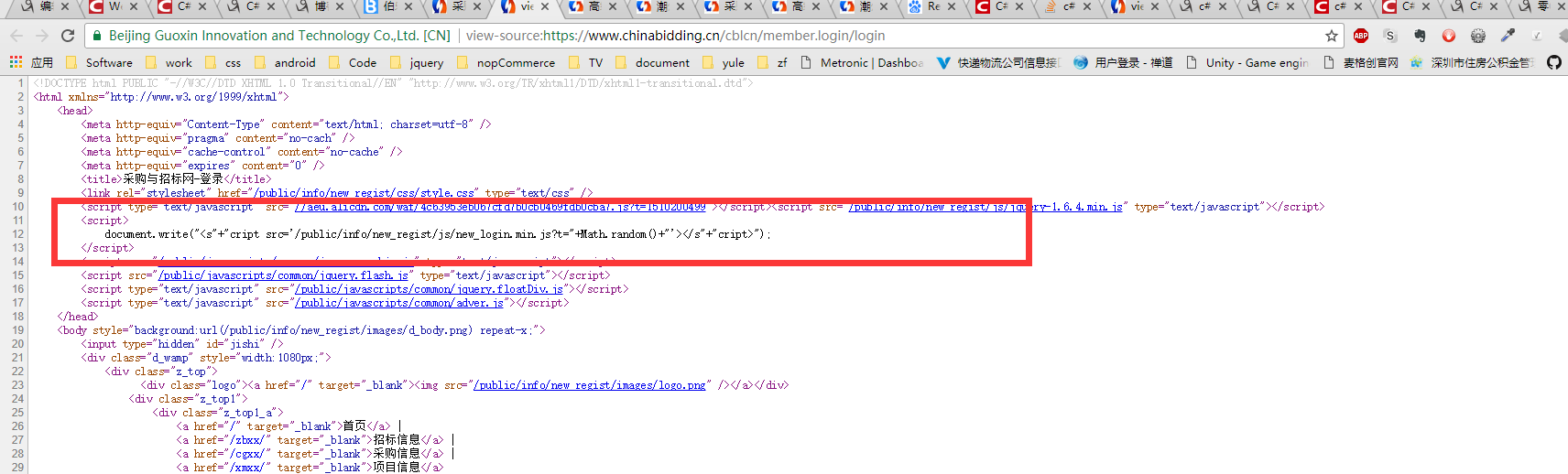
验证码获取方法

验证码校验方法
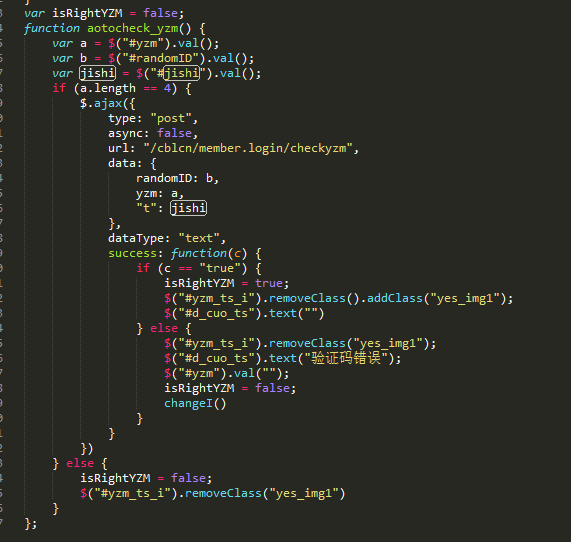
登录方法

其实通过找个代码可以看出我们其实可以绕过验证码,直接登录的。
2.2 接下来我们开始分析验证码,并且校验
安装OCR .net封装版本

2.3 识别验证码,单生成的验证码图片中的字符挨得比较近的时候,识别率很低



var imgurl = string.Format("https://www.XXXX.cn/cblcn/member.login/captcha?t={0}&randomID={1}", timeTicks, randomNum); var uir = new Uri(imgurl); var imgByte = webClient.DownloadData(uir); var imgStream = new MemoryStream(imgByte); var image = new Bitmap(imgStream); //省略了识别 if (string.IsNullOrEmpty(result.VCode)) new Bitmap(imgStream).Save(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, string.Format("{0}.png", Guid.NewGuid().ToString().ToLower().Replace("-", "")))); else new Bitmap(imgStream).Save(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, string.Format("{0}.png", result.VCode))); return result;
/// <summary> /// 识别图片,返回验证码 /// </summary> /// <param name="image"></param> /// <returns></returns> public static string StartOCR(Bitmap image) { string defaultList = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; //string defaultList = "2345689ABCDEFGHJKLMNPRSTWXY"; const string language = "eng"; //Nuget安装的Tessract版本为3.20,tessdata的版本必须与其匹配,另外路径最后必须以"\"或者"/"结尾 const string TessractData = @"D:\work\ZhaoBiaoSolution\YanZhengMaDemo\tessdata\"; TesseractEngine test = new TesseractEngine(TessractData, language); test.SetVariable("tessedit_char_whitelist", defaultList); var tmpPage = test.Process(image, pageSegMode: test.DefaultPageSegMode); return tmpPage.GetText(); }
/// <summary> /// 获取验证码 /// </summary> /// <param name="randomNum"></param> /// <param name="timeTicks"></param> /// <returns></returns> public static VerificationCodeRequest GetVerificationCode(WebClient webClient, string randomNum, long timeTicks) { var result = new VerificationCodeRequest(); var imgurl = string.Format("https://www.chinabidding.cn/cblcn/member.login/captcha?t={0}&randomID={1}", timeTicks, randomNum); //string defaultList = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var uir = new Uri(imgurl); var imgByte = webClient.DownloadData(uir); var imgStream = new MemoryStream(imgByte); var image = new Bitmap(imgStream); result.VCode = StartOCR(image).Trim(); result.TimeTicks = timeTicks; result.RandomNum = randomNum; //while (string.IsNullOrEmpty(result.VCode) && result.VCode.Length < 4) //{ // result = GetVerificationCode(webClient, randomNum, GetJsTimeTicks()); //} if (string.IsNullOrEmpty(result.VCode)) new Bitmap(imgStream).Save(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, string.Format("{0}.png", Guid.NewGuid().ToString().ToLower().Replace("-", "")))); else new Bitmap(imgStream).Save(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, string.Format("{0}.png", result.VCode))); return result; }
2.4 获取到了验证码后,我们就开始校验验证码,该方法使用了RestSharp
private const string _domainUrl = "https://www.xxxxx.cn"; /// <summary> /// 校验验证码 /// </summary> /// <returns></returns> public static string CheckVerificationCode(VerificationCodeRequest data) { //验证 var action = "/cblcn/member.login/checkyzm"; var client = new RestClient(_domainUrl); var request = new RestRequest(action, Method.POST); request.AddParameter("randomID", data.RandomNum); request.AddParameter("yzm", data.VCode); request.AddParameter("t", data.TimeTicks); // request.AddHeader("Accept", "text/html"); var result = client.Execute(request); return result.Content; }
2.5 接下来就是登录了,返回的是IRestResponse对象,因为我需要里面的登录返回结果以及服务器cookies
/// <summary> /// 登录 /// </summary> /// <returns></returns> public static IRestResponse Login() { //验证 var action = "/cblcn/member.login/logincheck"; var client = new RestClient(_domainUrl); var request = new RestRequest(action, Method.POST); request.AddParameter("name", "name"); request.AddParameter("password", "密码"); request.AddParameter("url", ""); // request.AddHeader("Accept", "text/html"); var result = client.Execute(request); return result; }
2.6 最后带着cookies 访问需要的页面并且下载页面数据
public static string GetPageHtml(string url, IList<RestResponseCookie> cookies) { //var action = "/zbgs/eofTK.html"; var client = new RestClient(_domainUrl); var request = new RestRequest(url, Method.POST); if (cookies != null) { client.CookieContainer = new CookieContainer(); foreach (var cookie in cookies) { client.CookieContainer.Add(new Cookie(cookie.Name, cookie.Value, cookie.Path, cookie.Domain)); } } //client.DownloadData(request); var response= client.Execute(request); return response.Content; }
打完收工
2.7 正则获取数据
//登录 //zbgg/eoyHX.html#pos_60117326 var html = VerificationCodeUtils.GetPageHtml("/zbgs/eofTK.html", Method.GET, lresult.Cookies); // Console.WriteLine(html); var matchCollection = new Regex("<div class=\"cen_xq c_xq_b(?<content>.*?)<div class=\"anniu1\">", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.ExplicitCapture).Matches(html);//new Regex("<div class=\"cen_xq c_xq_b\" id=\"(?<id>.*?)\">(?<content>.*?)<div class=\"anniu1\">", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.ExplicitCapture).Matches(html); foreach (Match match in matchCollection) { //Console.WriteLine(match.Value); } Console.WriteLine("--------------------------------------------------------"); Console.WriteLine(); var html2 = VerificationCodeUtils.GetPageHtml("/search/searchgj/zbcg", Method.GET, lresult.Cookies); var matchCollection2 = new Regex("bordercolordark=\"WHITE\">-->(?<content>.*?)</table>", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.ExplicitCapture).Matches(html2); foreach (Match match in matchCollection2) { Console.WriteLine(match.Value); }
参考文章:
https://www.cnblogs.com/warioland/archive/2012/03/06/2381355.html
https://www.cnblogs.com/lcawen/articles/7040005.html
http://www.cnblogs.com/ivanyb/archive/2011/11/25/2262964.html
http://www.cnblogs.com/263613093/p/5076146.html
漫漫人生,唯有激流勇进,不畏艰险,奋力拼搏,方能中流击水,抵达光明的彼岸



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App