python爬取斗图网中的 “最新套图”和“最新表情”
 1.分析斗图网
1.分析斗图网
斗图网地址:http://www.doutula.com
网站的顶部有这两个部分:

先分析“最新套图”

发现地址栏变成了这个链接,我们在点击第二页

可见,每一页的地址栏只有后面的page不同,代表页数;这样请求的地址就可以写了。
2.寻找表情包
然后就要找需要爬取的表情包链接了。我用的是chrome浏览器,F12进入开发者模式。
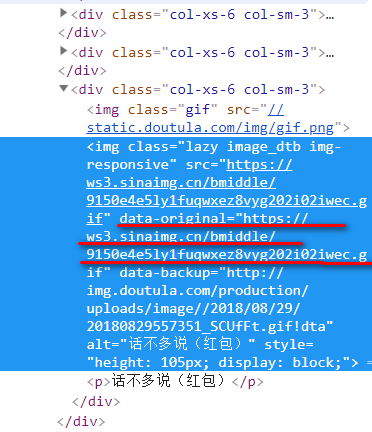
找到图片对应的img元素,发现每个Img元素的class都是相同的。data-original属性对应的地址,就是我们要下载的图片。alt属性就是图片的名字。
对于”最新表情“的页面,同样也是如此。
3.编写代码
元素都找到了,可以上代码了:
1 #coding=utf-8 2 import requests 3 from lxml import etree 4 from urllib import request 5 from time import sleep 6 import socket 7 import re 8 9 socket.setdefaulttimeout(20) 10 11 headers = {} 12 headers["User-Agent"] = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0" 13 headers["Host"] = "www.doutula.com" 14 headers["Accept"] = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8" 15 headers["Accept-Language"] = "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2" 16 headers["Accept-Encoding"] = "gzip, deflate" 17 headers["Connection"] = "close" 18 headers["Upgrade-Insecure-Requests"] = "1" 19 20 21 def get_url(page): 22 # 最新套图580页 23 url = "http://www.doutula.com/article/list/?page=" + str(page) 24 # 最新表情1855页 25 # url = "http://www.doutula.com/photo/list/?page=" + str(page) 26 response = requests.get(url, headers=headers) 27 html = response.text 28 selector = etree.HTML(html) 29 # print(html) 30 # 最新套图xpath 31 img_url = selector.xpath('//img[@class="lazy image_dtb img-responsive"]/@data-original') 32 img_name = selector.xpath('//img[@class="lazy image_dtb img-responsive"]/@alt') 33 # 最新表情xpath 34 # img_url = selector.xpath('//img[@style="width: 100%; height: 100%;"]/@data-original') 35 # img_name = selector.xpath('//img[@style="width: 100%; height: 100%;"]/@alt') 36 img_name = name_filter(img_name) 37 for img in img_url: 38 id = img_url.index(img) 39 get_img(id, img, img_name) 40 response.close() 41 42 43 def get_img(id, img, img_name): 44 """ 45 request.urlretrieve: 保存链接地址的文件 46 """ 47 global j 48 try: 49 if img[-3:] == 'dta': 50 if img[-7:-4] == 'gif': 51 request.urlretrieve(img, 'E:\\pictures\\%s.gif' % img_name[id]) 52 elif img[-7:-4] == 'png': 53 request.urlretrieve(img, 'E:\\pictures\\%s.png' % img_name[id]) 54 else: 55 request.urlretrieve(img, 'E:\\pictures\\%s.jpg' % img_name[id]) 56 elif img[-3:] == 'gif': 57 request.urlretrieve(img, 'E:\\pictures\\%s.gif' % img_name[id]) 58 elif img[-3:] == 'png': 59 request.urlretrieve(img, 'E:\\pictures\\%s.png' % img_name[id]) 60 else: 61 request.urlretrieve(img, 'E:\\pictures\\%s.jpg' % img_name[id]) 62 print("下载第%d张表情包" % j + img) 63 except Exception as ex: # urlopen error time out 64 print(str(ex)) 65 j += 1 66 67 68 def name_filter(img_name): 69 """ 70 过滤文件名中的特殊字符 71 """ 72 newlist = [] 73 for im in img_name: 74 im = re.sub(r'\?', '', str(im)) # / \ 75 newlist.append(im) 76 return newlist 77 78 79 if __name__ == '__main__': 80 81 j = 1 82 for page in range(1, 581): 83 print("第%s页" % page) 84 while True: 85 try: 86 get_url(page) 87 break 88 except Exception as e: 89 print(str(e)) 90 sleep(5) 91 sleep(10)
4.运行结果
爬了两天,可能代码中的sleep时间有点长,服务器那边也老是断开连接。

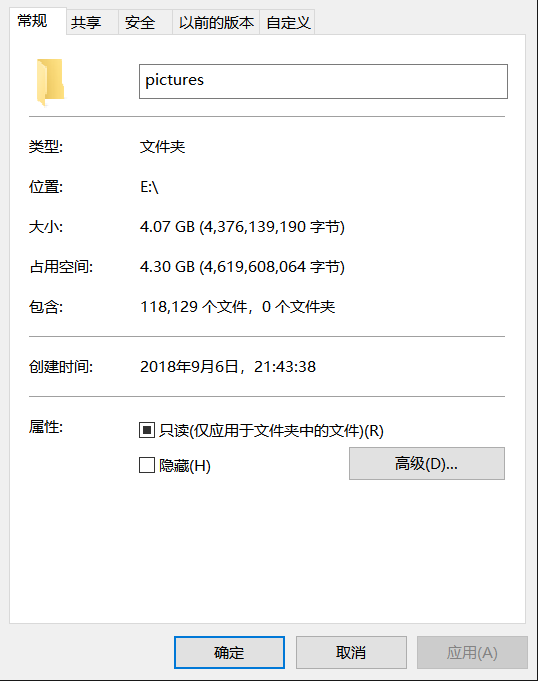
数据有些偏差,可能下载的过程网络的问题导致的。
5.总结
编码过程中,对于异常处理的思考,还需要多提高;有许多会出现问题的地方,都没有考虑到。

