
Linux 文件系统
索引节点和目录项
文件系统,是对存储设备上的文件,进行组织管理的机制。组织方式不同,就会形成不同的文件系统。
Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。它们主要用来记录文件的元信息和目录结构。
- 索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
- 目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存
索引节点是每个文件的唯一标志,而目录项维护的正是文件系统的树状结构。
磁盘读写的最小单位是扇区,然而扇区只有 512B 大小,如果每次都读写这么小的单位,效率一定很低。所以,文件系统又把连续的扇区组成了逻辑块,然后每次都以逻辑块为最小单元,来管理数据。常见的逻辑块大小为 4KB,也就是由连续的 8 个扇区组成。
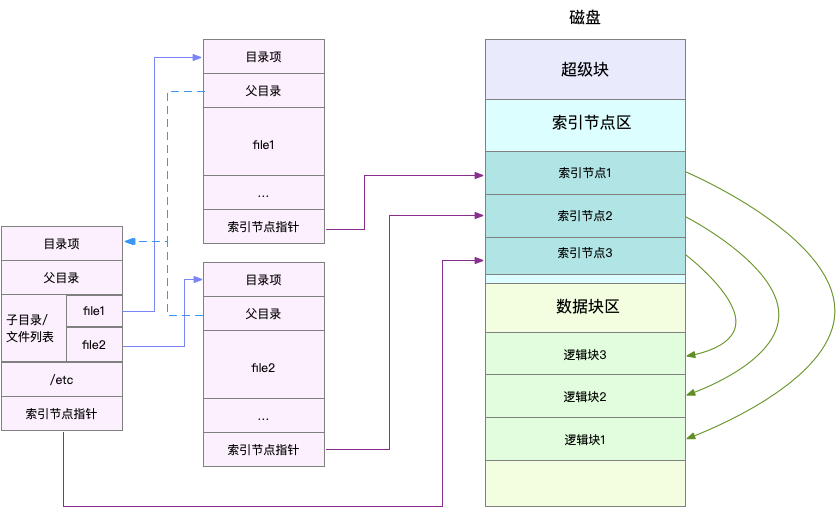
磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区。其中,
- 超级块,存储整个文件系统的状态。
- 索引节点区,用来存储索引节点。
- 数据块区,则用来存储文件数据。
虚拟文件系统
目录项、索引节点、逻辑块以及超级块,构成了 Linux 文件系统的四大基本要素。
为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。VFS 定义了一组所有文件系统都支持的数据结构和标准接口。
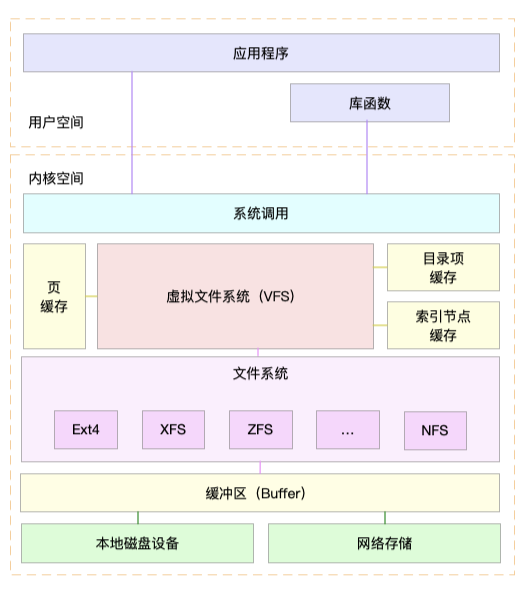
在 VFS 的下方,Linux 支持各种各样的文件系统,如 Ext4、XFS、NFS 等等。按照存储位置的不同,这些文件系统可以分为三类。
- 第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS 等,都是这类文件系统。
- 第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc 文件系统,其实就是一种最常见的虚拟文件系统。此外,/sys 文件系统也属于这一类,主要向用户空间导出层次化的内核对象。
- 第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、SMB、iSCSI 等。
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。拿第一类,也就是基于磁盘的文件系统为例,在安装系统时,要先挂载一个根目录(/),在根目录下再把其他文件系统(比如其他的磁盘分区、/proc 文件系统、/sys 文件系统、NFS 等)挂载进来。
cat 命令来说,它首先调用 open() ,打开一个文件;然后调用 read() ,读取文件的内容;最后再调用 write() ,把文件内容输出到控制台的标准输出中:
“Linux 一切皆文件”的深刻含义。无论是普通文件和块设备、还是网络套接字和管道等,它们都通过统一的 VFS 接口来访问。
性能观测
容量
[root@k8s ~]# df -h /dev/vda1
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 40G 14G 24G 37% /
有时候空间不足是因为索引节点空间不足。
索引节点的容量,(也就是 Inode 个数)是在格式化磁盘时设定好的,一般由格式化工具自动生成。当你发现索引节点空间不足,但磁盘空间充足时,很可能就是过多小文件导致的。
[root@k8s ~]# df -h /dev/vda1 -i
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/vda1 2.5M 255K 2.3M 10% /
总结
文件系统,是对存储设备上的文件,进行组织管理的一种机制。为了支持各类不同的文件系统,Linux 在各种文件系统实现上,抽象了一层虚拟文件系统(VFS)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,就只需要跟 VFS 提供的统一接口进行交互。
为了降低慢速磁盘对性能的影响,文件系统又通过页缓存、目录项缓存以及索引节点缓存,缓和磁盘延迟对应用程序的影响。
find / -name 这个命令是全盘扫描(既包括内存文件系统又包含本地的xfs【我的环境没有mount 网络文件系统】),所以 inode cache & dentry & proc inode cache 会升高。
另外,执行过了一次后再次执行find 就机会没有变化了,执行速度也快了很多,也就是下次的find大部分是依赖cache的结果。
学习笔记
整理自极客时间:《Linux性能优化实战》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号