文件组与表分区
1,文件组与表分区:只有数据文件才有文件组的概念,日志文件是没有文件组的概念的
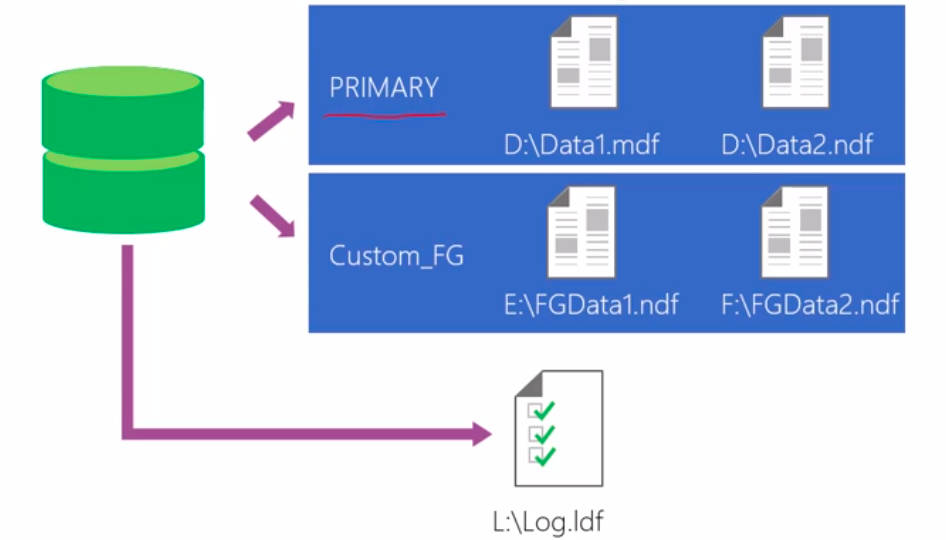
,数据只能指向文件组,而不能指向文件
2,文件组的作用: 在超大型数据库的时候,效果很是明显

3,文件组的注意事项

3-1 ,先创建文件组,而后创建文件,在确定之前需要仔细检查确认
3-2, ,数据的存储是在文件中,交替存放。缺少任何一个文件后,数据都是不完整的。
3-3, ,数据是存在文件里面,文件是放在文件组里面,所以在删除文件组之前,肯定是要先删除文件
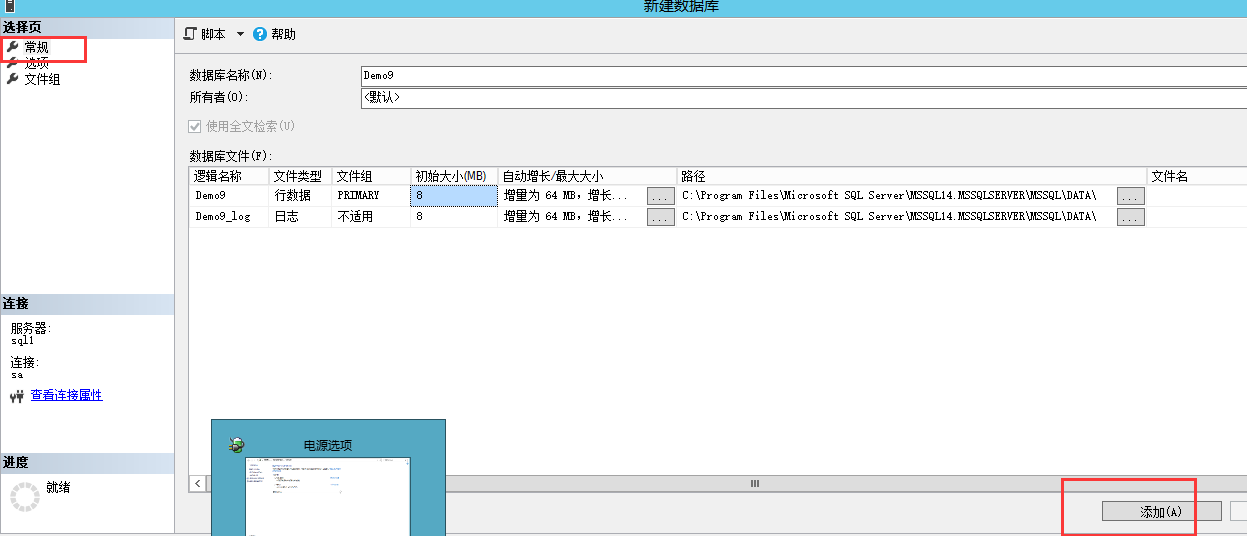
4. 文件组的创建过程
4-1,创建文件组
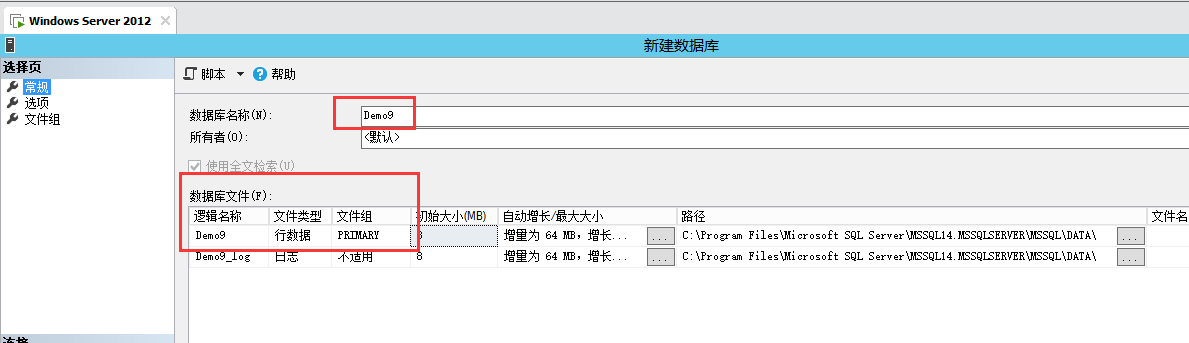
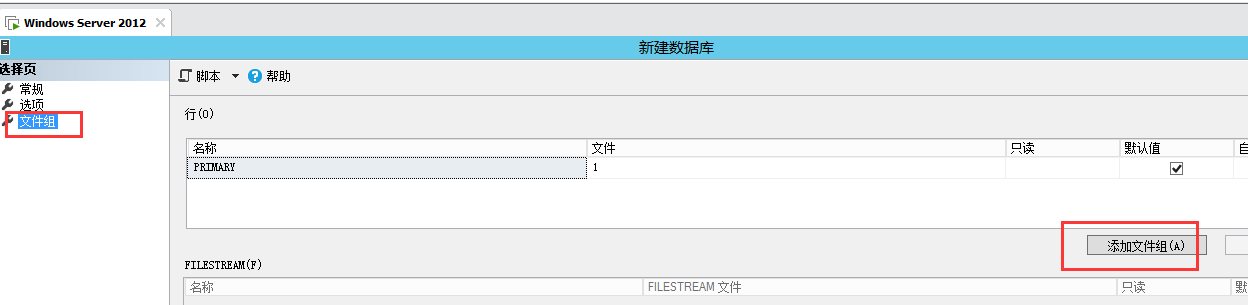
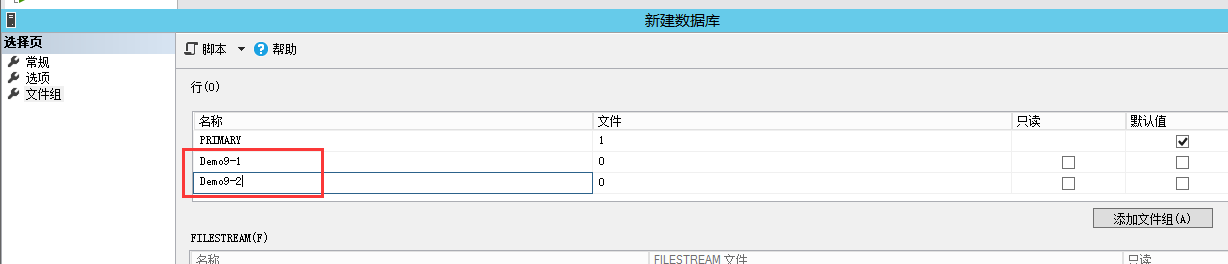
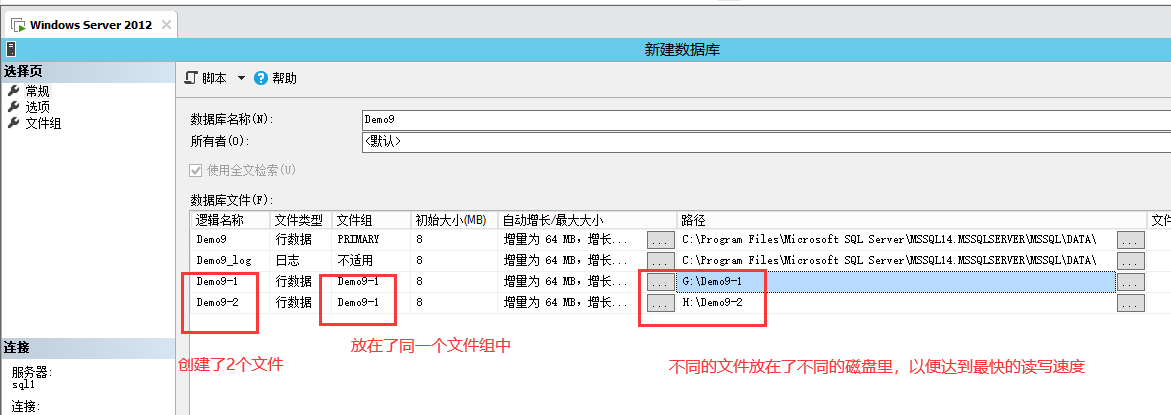
创建文件并放进文件组中:下图以后的过程
---------------------------------------------------------------------------------------------------------
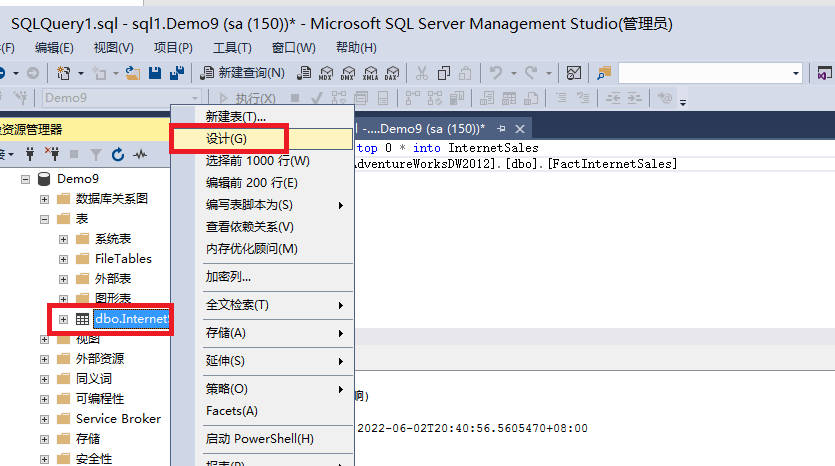
5,创建数据库里的表,并将表的存储设计修改为刚才创建的文件组
5-1;创建一张表
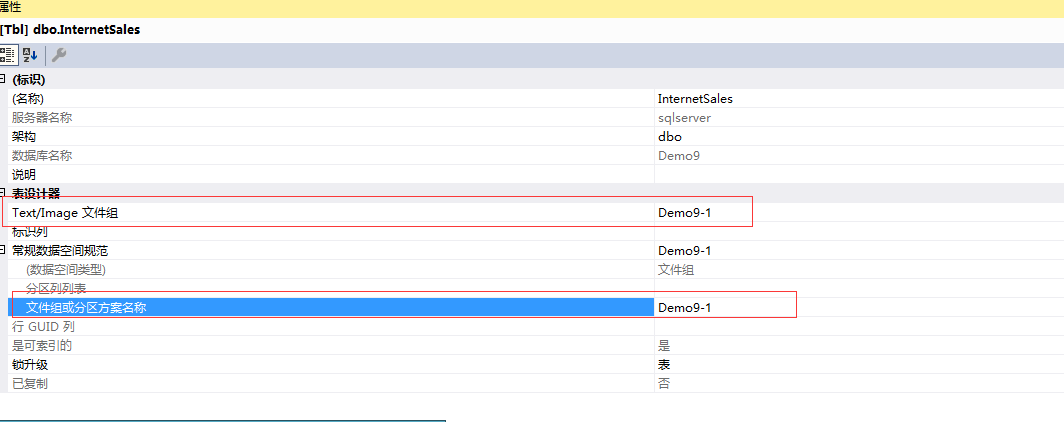
5-2;修改表的存储属性
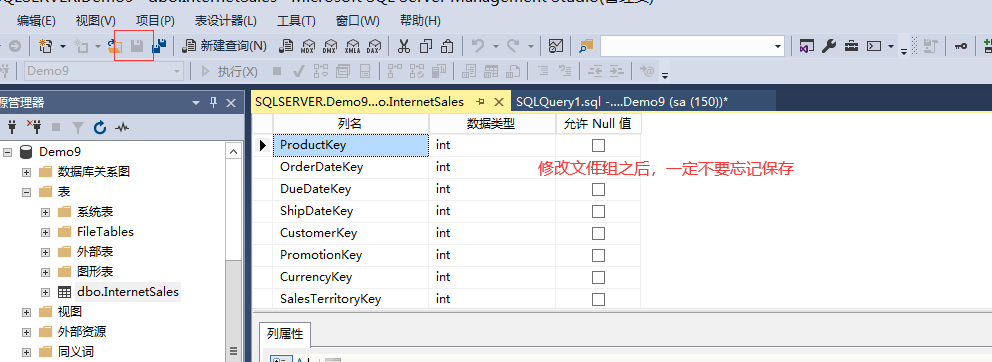
5-3,在表中填充数据,然后观察两个数据文件的体积交替变化
填充前:
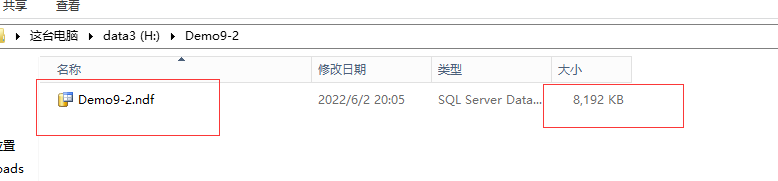
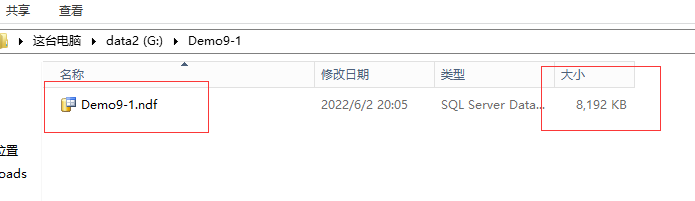
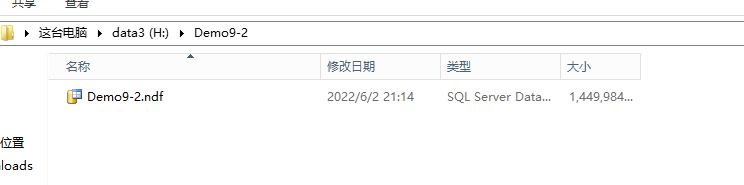
填充数据,然后查看文件的体积变化:在实际的数据插入过程中,两个数据文件都是在交替的增长64M。
=======================================================================================================
二,表分区----当在超大型的数据库中,单张表的数据量相当大的时候,例如500G或者1000G以上,那么表的查询和写入就会给性能带来相当大的
瓶颈,那么如果现在优化表,就会用到这个表分区。也就是说将单张表分成N个区,2012以上版本可以分15000个。再将不同的分区放到不同的 文件组中,文件组中又放着N个文件,而文件又放在不同的磁盘上,从而达到最佳的读写效果。
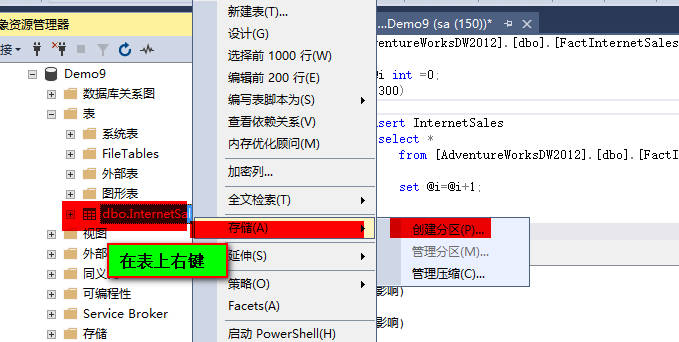
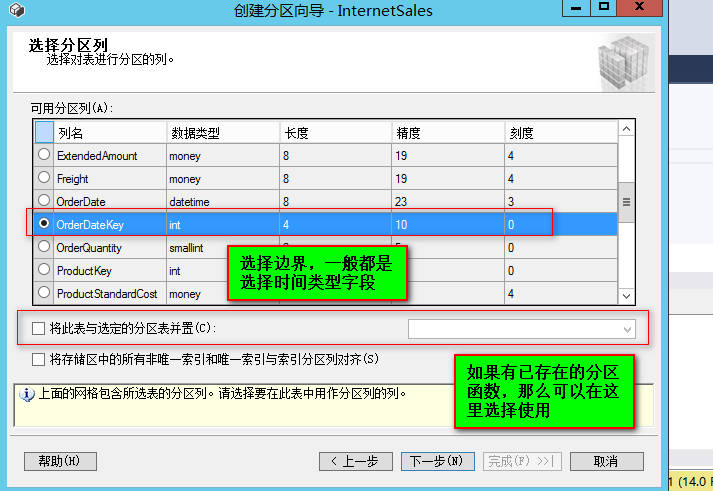
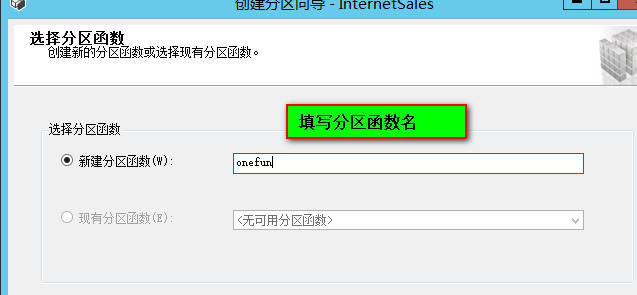
这里选择选择的文件组里面必须已经创建了数据文件,也就是数据库创建的时候,数据文件组创建后,需要
分配数据文件。数据表的分区就是将数据表分割后,分别存放在已经存在的不同的文件中。例如:
我们在创建此数据库的时候,我们有6块磁盘,其中有2块高速磁盘,我们分6个数据文件,每个文
件都放在一块磁盘上,分3个文件组,每1个文件组存放2个文件。我们将这个数据表里,读写数据频繁区段
切开后放在高速文件组中。比如 数据表中存放着19980101年---20220101的数据,然而2020年之前的数据
修改非常少,偶尔查询用。2020年之后的数据读写频繁。那我们将数据表分区后,2020年之前的数据分区后
存放在读写存储性能稍慢的上面。2020年之后的数据就放在读写性能高的存储上。以便实现提高数据库的性能的
目的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号