


机器学习实战-SVM
支持向量机
线性SVM分类
SVM可用于回归、分类,甚至是异常检测,它很强大,广受欢迎。作为线性分类器时,它的核心思想是,不但要正确划分类别,而且要使得离决策边界最近的实例到决策边界的距离最大,这样就能使模型具有良好的泛化性能,因而也并称为大间隔分类。

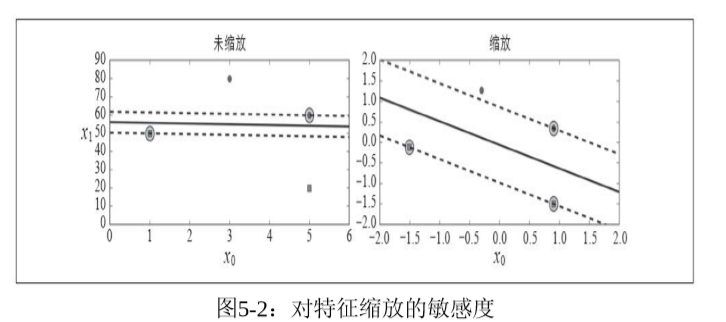
这些决策边界之间就像街道一样,而 在街道之外增加实例,并不会影响决策边界,因为它是由决策边界上的实例决定的,这些实例被称为支持向量,这正是支持向量机的由来。SVM对特征缩放特别敏感,因此实际项目中可以通过尝试不同的特征缩放以便于可视化。
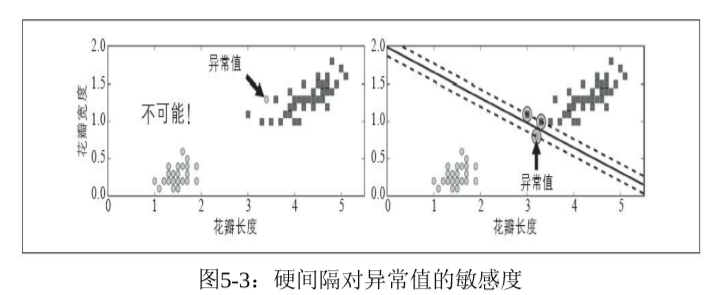
如果要求所有所有实例都不在街道上,并且位于正确的一侧,这就是硬间隔分类。它有两个问题:一是只有数据集线性可分时才有效;而是对异常值非常敏感,这可能导致泛化性能不好。
要避免这些问题,就要使用更灵活的模型。目标是在尽量在保持街道宽度和间隔违例之间找到良好的平衡,这就是软间隔分类。
非线性SVM分类
虽然在很多情况下线性SVM分类器是有效的,并且出人意料的好,但是很多数据集是远非线性可分的,这时线性SVM分类器就无能为力了。对此,一个常用的技巧是添加更多的特征,比如多项式特征,这样,在新的特征空间上,数据集可能是线性可分的。添加多项式特征很简单,而且很有效,不仅仅是对SVM而言,对所有机器学习算法都如此。但是,这种方法也并非没有问题,如果添加的多项式特征阶数太低,可能会拟合不足,如果阶数太高,又会导致模型运行很慢,可能会过度拟合。解决这个问题的终极大杀器就是:核方法。
在学习核方法之前还是先来理解SVM的原理吧!
SVM的决策函数是wTx + b ,如果为正,则预测类别为正类,反正亦然。注意SVM不会输出每个类别的概率。

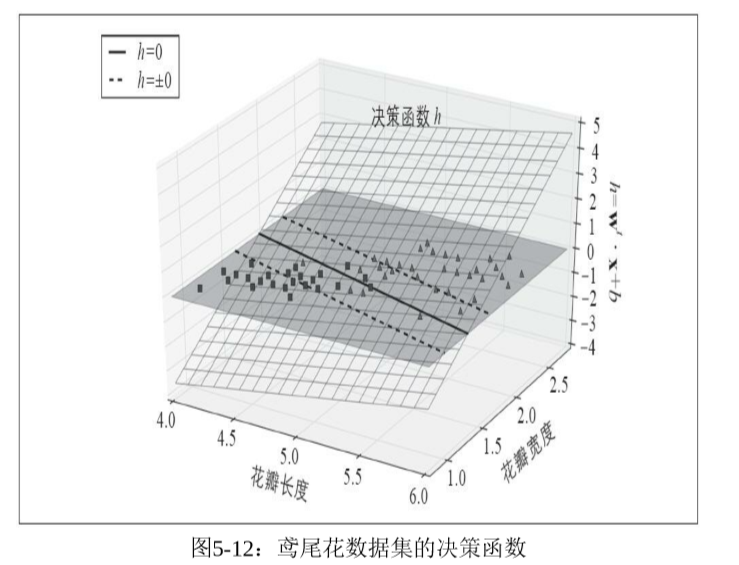
在鸢尾花数据集上有两个特征,虚线表示决策函数为+-1的,它们是平行的,而且与决策函数等距离。一般地,n个特征对应的决策函数为n维超平面,决策边界为n-1维超平面。训练SVM就是要找到合适的w和b,使得间隔大小与违例数达到给定的平衡度,平衡度是由超参数控制的。
有了决策函数,接下来就是训练目标了。
决策函数的斜率为||w||,样本空间中任意点到决策函数的距离为|wTx+b|/||w||,因为决策边界上的点(即支持向量)使得决策函数等于-+1,间隔宽度为2/||w||,如果把斜率除以2,则间隔也会变为2倍。所以我们要最小化||w||来最大化间隔,同时,如果不允许任何间隔违例,那么就要使所有正类训练集的决策函数大于2,负类训练集的决策函数小于-1(不包括支持向量)。定义实例为负类时t=-1,实例为正类时t=1。那么就可以将这个约束表示为:对所有实例t(wTx+b)>=1,这样就可以将硬间隔SVM分类器的目标表示为约束优化问题:
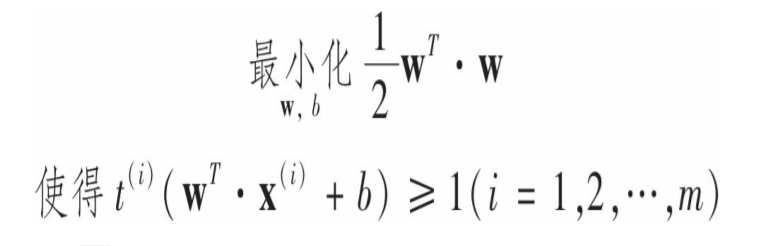
这里优化的是wTw/2 ,等价于优化||w||,但是||w||在w=0处是不可微的,而wTw/2的导数是w,处处可微。优化函数在可微函数上效果会好得多。硬间隔分类的导出的优化问题是基础,实际中使用的是软间隔分类,这是就要添加松弛变量sigma>=0,sigma(i)衡量的是第i个实例被允许间隔违例的程度。这样我们就有了两个矛盾的目标:最小化||w||以获得最大间隔,同时最小化sigma,尽量减少间隔违例,可表示如下:
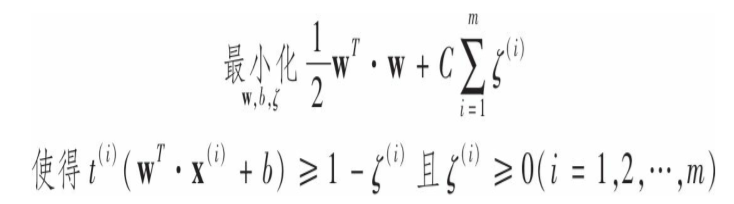
这类凸二次优化问题也称为二次规划问题,已经研究得很透彻,有很多现成的求解器可以用。这是SVM的理论基础,现在是时候继续讨论核方法了。
有这样一类问题,它的解与原始问题相近,在满足某系条件时,甚至于原始问题的解相等,它被称为原始问题的对偶问题(dual problem),对偶的利用在于有时它比原始问题更容易求解,尤其是训练实例的数目小于特征数的时候。考虑如下的二阶多项式转换:
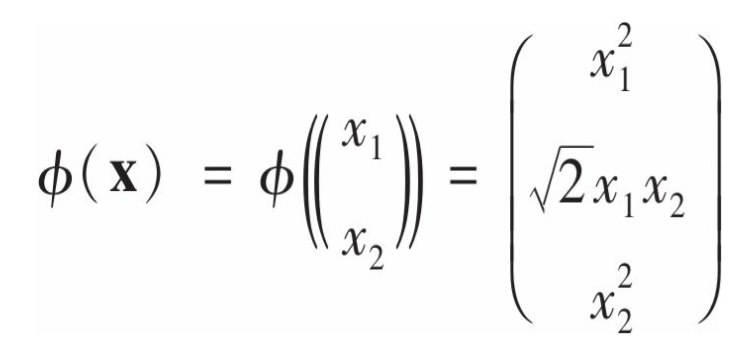
那么:
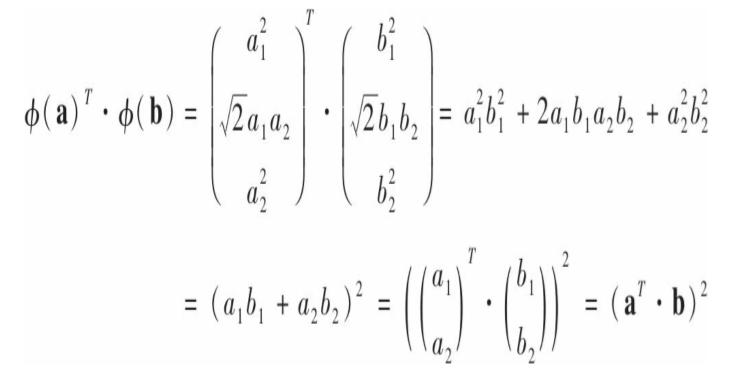
也就是说转换后的向量的点积等于原始向量点积的平方。这只是一种方法的理论基础,看看如何将它应用于SVM训练。线性SVM训练目标问题满足一些特定的条件,使得它的对偶问题的解与原始相等,这是一个好消息。其对偶问题为:
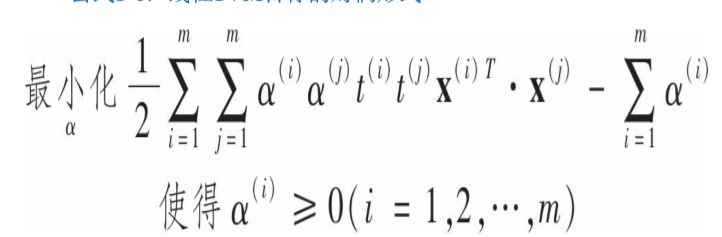
一旦求得alpha就可以通过下面的格式得到w和b:
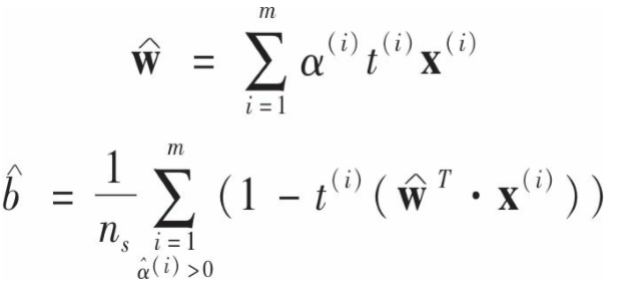
如果要将映射转换应用于所有训练实例,那么对偶问题中会包含![]() 点积的计算,如果这个函数是前面提到的二阶多项式,那么我们其实不用实际去计算这个转换的过程和结果,只需要在对偶问题中用x(i)T.x(j)代替
点积的计算,如果这个函数是前面提到的二阶多项式,那么我们其实不用实际去计算这个转换的过程和结果,只需要在对偶问题中用x(i)T.x(j)代替![]() ,因此计算难度大大降低,这正是核技巧的本质。好了,总结一下,为了解决线性不可分的分类问题,我们通过某种映射,将特征空间映射到更高维数的特征空间;为了求解新的特征空间上的约束优化问题,我们可以转而求解原始问题的对偶问题,这是因为对偶问题的求解难度更小。
,因此计算难度大大降低,这正是核技巧的本质。好了,总结一下,为了解决线性不可分的分类问题,我们通过某种映射,将特征空间映射到更高维数的特征空间;为了求解新的特征空间上的约束优化问题,我们可以转而求解原始问题的对偶问题,这是因为对偶问题的求解难度更小。
已经证明,当原始问题满足一定条件时,核函数一定存在,即使我们不知道这个核函数的具体形式。以下是常用的核函数,我们甚至不必关注它的具体转换过程,但是,如果选择的核函数不合适,意味着原始特征被映射到了一个不合适的新特征空间,这可能导致分类器性能不佳。

还有一个问题,如果应用RBF核函数,得到的 是无限维的,而对偶问题中的w和它的维数一致,那要如何求解呢?答案是不需要求解,只需要在新实例的决策函数中将w的表达式直接带入,这样就决策函数就只包含输入向量的点积,这时就可以再次使用核技巧:
是无限维的,而对偶问题中的w和它的维数一致,那要如何求解呢?答案是不需要求解,只需要在新实例的决策函数中将w的表达式直接带入,这样就决策函数就只包含输入向量的点积,这时就可以再次使用核技巧:
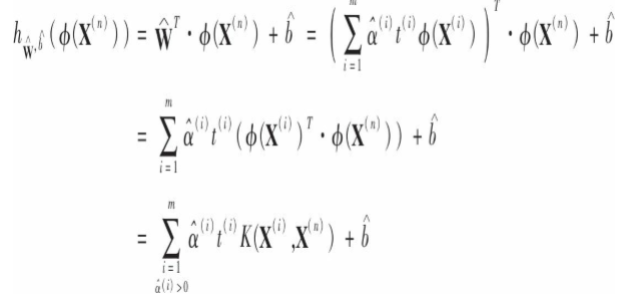
上式中仅对于支持向量才有alpha不等于0,所以预测时,计算新向量的点积仅使用支持向量而不是全部训练实例。同样,可以使用核方法求解b:
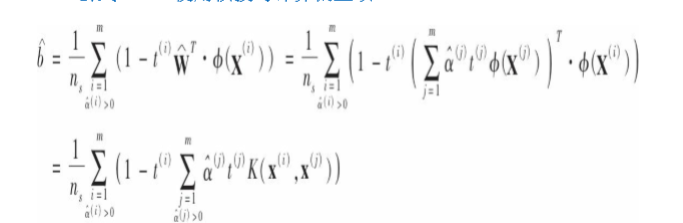
最后给出线性SVM分类器的成本函数:
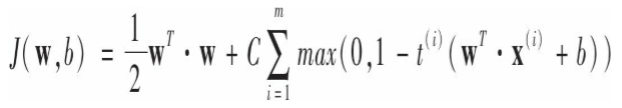
第一项推动模型得到一个较小的权重向量,以最大化间隔。第二项计算全部的间隔违例,如果没有一个实例位于街道上并且位于正确的一边,第二项为0.否则该实例违例的大小与其到街道正确的一边的距离的大小正正比。所以第二项使得间隔违例尽可能小也尽可能少。
