【翻译】- EffectiveAkka-第一章
第一章 Actor应用程序类型
在会议上发言时,我遇到的最多问题之一是“基于Actor的应用程序的用例是什么?”这取决于您要完成的任务,但是如果您想构建具有可管理的并发性、跨节点向外扩展性、并具有容错能力的应用程序,actor就非常适合了。
领域驱动
在一个由域驱动的actor应用程序中,actor表示现实缓存世界中的存在和消亡的状态,其中这些actor的存在以及封装的状态显示了应用程序的数据。 它们经常用于把信息以最终的一致性方式提供给多个其他服务器的系统中。 这意味着,试图提供另一台服务器的actor可能无法在给定点上这样做,所以必须尝试直到它可以。
例如,想象一个大型金融机构试图保持对所有客户的实时视图:包含所有账户以及客户在特定时间通过账户拥有的所有投资。 这些信息可以通过actor-supervisor层次结构创建和维护。
这种实时域建模(实质上是创建一个包含行为的缓存),由Akka actors的轻量级特性完成。 由于Akka actor之间共享资源(如线程),因此每个实例在添加领域状态之前仅占用大约400个字节的堆空间。 用一个服务器包含Akka actor表示的大型企业的整个业务领域,这似乎是合理的。
使用actor进行这种领域建模的另一个好处是引入了容错能力:您可以使用Akka的监督策略来确保系统的高运行时间,而不是领域对象的简单缓存,当然异常必须在服务层处理。图1-1是一个例子
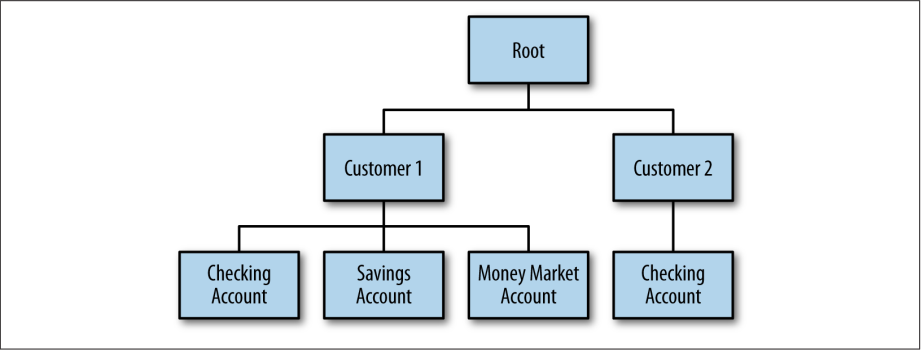
图1-1 领域驱动的actor
这真的可以融入Eric Evans的“领域驱动设计”范式。 actor可以表示在领域驱动方法中描述的概念,如实体,聚合门和聚合根。 您可以用actor设计整个上下文边界。 当我们来到用例来展示模式时,我会告诉你如何设计。
领域驱动消息:事实
当你建立一个以actor表示的领域对象的层次结构时,他们需要得到周围世界发生的事情的通知。 这通常用传递的消息表示发生的“事实”。虽然这本身不是一个规则,但记住这是最佳做法。 领域对象应该对外部事件做出反应,改变它正在建模的世界,并且它应该自我变形,以便在发生变化时满足这些变化。 如果发生了阻止领域actor表示这些更改的事情,则应该把他们设计成能够最终找到与它们的一致性:
// An example of a fact message case class AccountAddressUpdated(accountId: Long, address: AccountAddress)
工作分配
在这种情况下,actor是无状态的并接收包含状态的消息,对这些消息他们将执行一些预定义的操作并返回某种状态的新表示。 这是worker actor和领域actor之间最重要的区别:worker actor是为了把危险的任务并行化或者分离成actor,而actor就是专门为此目的而建立的,并且他们将始终为其提供数据。 上一节介绍的领域actor代表了一个现实缓存,actor的存在以及封装的状态是应用程序当前状态的视图。 对于如何实施有不同的策略,每种策略都有自己的好处和用例。
路由器和路由routee
在Akka中,routers用于产生同actor类型的多个实例,以便工作可以在其中分布。 actor的每个实例都包含自己的邮箱,因此不能将其视为“偷工减料”的实现。路由器有几种策略可用,包括以下部分。
随机
随机是一种策略,它以随机的方式将消息分发给actor,这不是我所喜欢的。 最近有一个关于使用Heroku Dynos(虚拟服务器实例)的初创公司进行的讨论,它把请求随机分配给每个dyno,这意味着即使大量用户导致扩大了dynos的数量以处理更多的请求,他们也不能保证新的终端会得到任何请求,也不能保证负载将被分散。 也就是说,随机routee是唯一不会导致路由瓶颈的路由,因为在转发消息之前不会检查任何东西。 如果你有大量的消息流经你的路由器,这可能是一个有用的折衷。
看图1-2。 如果我有五个routee并使用随机战略,则其中一个routee的邮箱可能没有任何消息(比如3号routee),而另一个routee可能有一堆(比如2号routee)。而接下来的消息仍然可能被路由到2号routee。
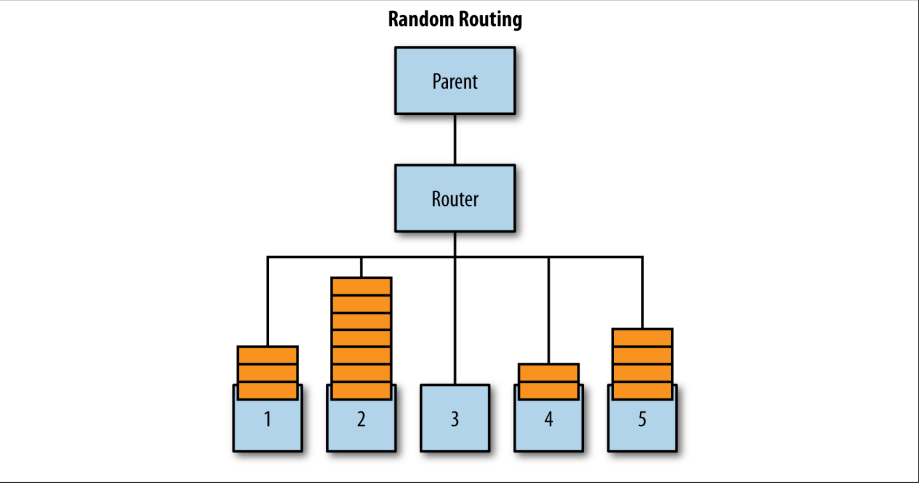
图1-2.随机路由
Round robin
Round robin这种策略把消息按顺序分发给每个actor实例,就好像它们处于一个环中,这对于均匀分布来说是有好处的。 它在routee之间顺序的分发工作,当所有routee执行的操作总是相同且CPU绑定时,这可能是一种很好的策略。 它假定routee和运行它们的机器之间的所有注意事项都是相同的:线程池有用于调度任务的线程,并且这些机器具有可用于执行工作的内核。
在图1-3中,工作分配均匀,下一条消息将会转到3号routee

图1-3 Round-robin路由
Smallest mailbox
Smallest mailbox这种策略把消息分发给具有最小邮箱(当前具有的消息最少)的actor实例。 这听起来像是万灵丹,但事实并非如此。 具有最小邮箱的actor的工作量可能最少,因为它被要求执行的任务比其他actor的工作时间要长。 把消息放到它的邮箱中,可能比那些已经拥有更多消息排队的actor耗费更长的时间。 与Round-robin路由器一样,这种策略对于始终处理完全相同工作的路由很有用,但工作本质上是阻塞的:例如,可能存在不同延迟的IO绑定操作。
注意:Smallest mailbox策略对远程actor不起作用,因为路由器不知道远程routee邮箱的大小
在图1-4中,工作将分配给4号routee,也就是邮箱中消息数最少的actor。发生这种情况忽略了一个可能性:1号routee可能会更快的接收和处理,即使它有更多的工作但仍然会耗费更少的时间。
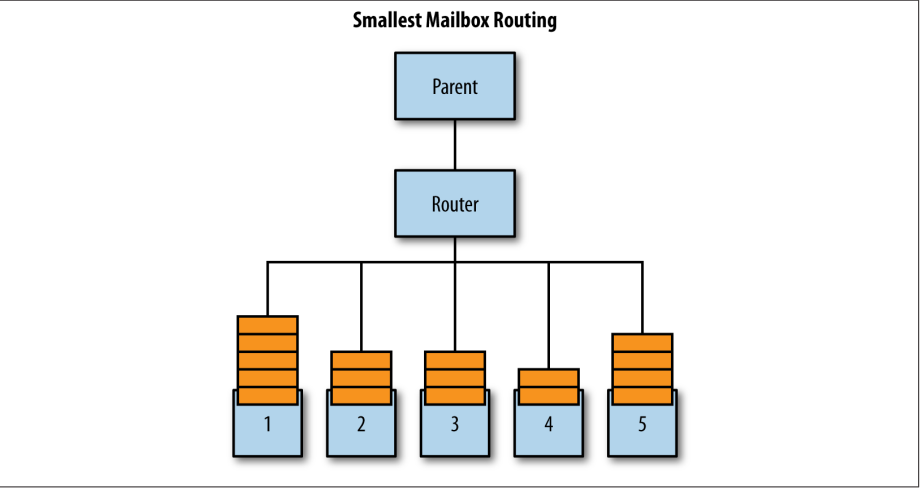
图1-4 Smallest mailbox路由
广播
Broadcast是一种将消息发送给路由器控制的actor的所有实例的策略。把工作分发给可能执行不同任务的节点,或通过把任务分给执行相同任务的节点进行容错,来防止发生任何故障都是有好处的。
由于路由器下的所有routee都会收到该消息,所以理论上它们的邮箱应该同时满或同时空。现实情况是,如何在消息处理中应用调度器以实现公平(通过调整“吞吐量”配置值)调度将决定这一点。 尽量不要认为路由器会给你的系统带来确定性,即使它们的工作都是均匀分配:它仅仅意味着工作是均匀分布的,但在不同的routee中仍然会在不同的时间被处理。 示例见图1-5。
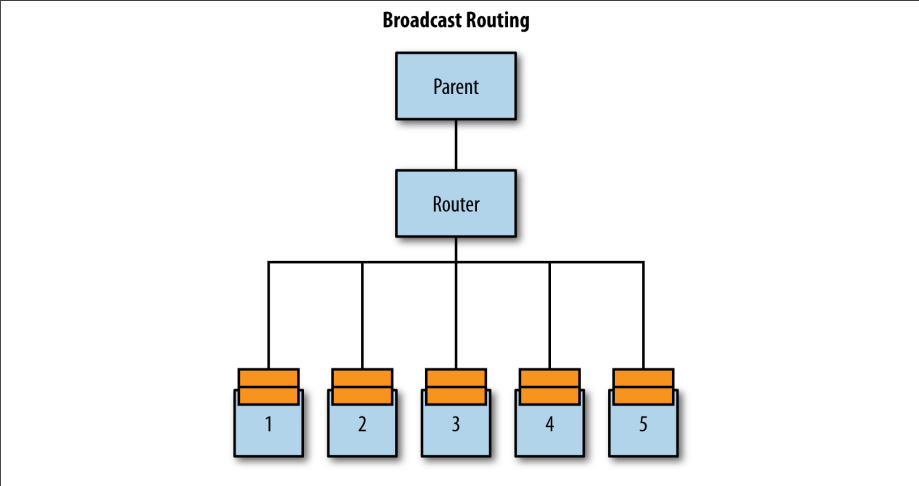
图1-5 Broadcast 路由
ScatterGatherFirstCompletedOf
ScatterGatherFirstCompletedOf这策略将消息发送给路由器控制的actor的所有实例,但只处理来自其中任何实例的第一个响应。 这对于需要快速响应并希望多个处理程序尝试为您执行此操作的情况非常有用。 通过这种方式,您不必担心哪个routee的工作量最少,或者即使排队的任务最少,因为这些任务不会比另一个已经拥有更多消息的routee需要更长时间处理。
如果routee分布在多个JVM或物理机器中,这将特别有用。 每个机器可能会以不同的速率运行,您希望尽可能快地执行工作,而无需手动确定哪个机器目前的工作最少。 更糟的是,即使你确实检查出了一个机器最空闲,并发送了该工作时,它可能已经变慢了,因为它需要处理其他工作。
在图1-6中,我正在将某项工作发送给五个routee,而我只关心哪一个最先完成工作并作出响应。这以潜在的网络延迟(如果这些机器的距离超过一个最近物理跳的距离)以及额外的CPU利用率(因为每个routee都必须完成这项工作)为代价才能获得最快的响应。
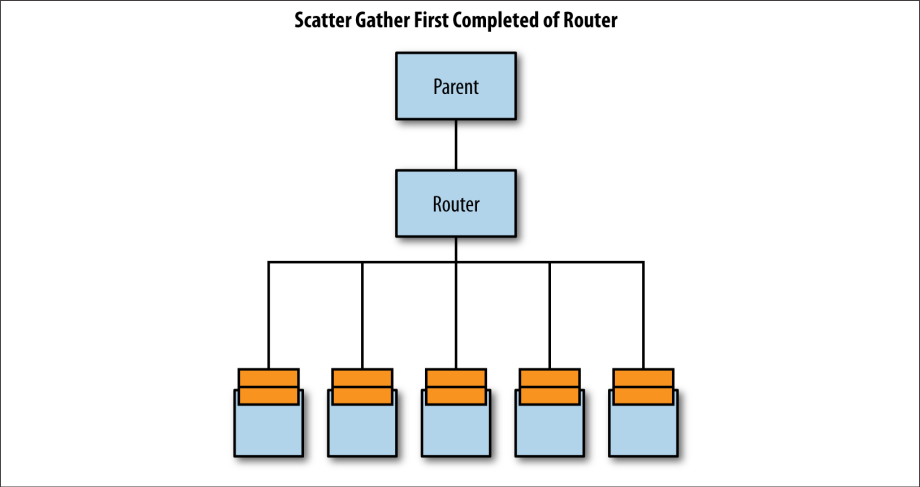
图1-6 ScatterGatherFirstCompletedOf路由
一致性HASH路由
这是一种新的路由策略,最近在Akka 2.1中添加。 在某些情况下,您需要知道哪个routee将处理特定类型的工作,可能是因为您在几个远程节点上有明确定义的Akka应用程序,并且您想确保将工作发送到最近的服务器避免延迟。 它与群集感知路由的方式类似。 这很有用,因为你知道,通过哈希,此次工作尽可能被路由到处理上一次相同工作的同一个routee。 根据定义,Consistent hash(一致性HASH)路由并不能保证工作的均匀分布。
BalancingDispatcher很快会被废弃
我之前提到过,路由器中的每个actor都不能共享邮箱,因此即使采用不同的策略,工作“窃取”(类似工作负载)也是不可能的。 Akka用BalancingDispatcher来解决这个问题,所有使用该调度器创建的actor都共享一个邮箱,在完成当前工作时可以立即获取下一条消息。 工作“窃取”是一个非常强大的概念,并且需要使用特定的调度器来实现,因此它将工人隔离在自己的线程池中,这对于避免actor饥饿非常重要。
然而,鉴于其特殊性和有些意想不到的行为,BalancingDispatcher被认为是古怪的、并不推荐用于一般场景。 在即将到来的Akka版本中,它很快将被弃用,以代替新的路由器类型来处理窃取工作的语义,但是这种方式尚未定义。 Akka团队不建议使用BalancingDispatcher,因此请远离它。
工作分配消息:命令
当你在actor中分配工作时,你通常会发送给actor可以响应的命令,从而完成任务。 该消息包含actor执行工作所需的数据,并且您应该避免将状态放入完成计算所需的actor中。 这个任务应该是幂等的 - 任何一个routee实例都可以处理这个消息,并且在给定相同输入的情况下,你应该总是得到相同的响应,而没有副作用
// An example of a command message case class CalculateSumOfBalances(balances: List[BigDecimal])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号