DolphinScheduler源码分析之任务日志
DolphinScheduler源码分析之任务日志
任务日志打印在调度系统中算是一个比较重要的功能,下面就简要分析一下其打印的逻辑和前端页面查询的流程。
AbstractTask
所有的任务都会继承AbstractTask,这个抽象类有一个比较重要的字段就是logger,其实也就是一个org.slf4j.Logger对象。
也就是说所有的任务都是通过slf4j打印日志的。那这个logger是如何创建的呢?
Logger taskLogger = LoggerFactory.getLogger(LoggerUtils.buildTaskId(LoggerUtils.TASK_LOGGER_INFO_PREFIX,
taskInstance.getProcessDefine().getId(),
taskInstance.getProcessInstance().getId(),
taskInstance.getId()));
public static String buildTaskId(String affix,
int processDefId,
int processInstId,
int taskId){
// - [taskAppId=TASK_79_4084_15210]
return String.format(" - [taskAppId=%s-%s-%s-%s]",affix,
processDefId,
processInstId,
taskId);
}
非常简单,就是通过LoggerFactory.getLogger获取的,名字是由流程定义ID、流程实例ID、任务ID拼接成的。前端查询日志时,taskAppId其实就是logger的名称。通过下图可以很直观的看到,当前任务的流程定义ID是1,流程实例ID是2,任务ID是2 
其实分析到这里,并没有证明最终的进程把日志通过logger写到文件,至少目前没有看到相关的代码。为了更加直观的证明,我们选择Shell类型的任务来分析打印日志的方式。因为它最终创建了一个shell子进程,如果要通过logger字段打印日志,一定会有相关的代码。
ShellCommandExecutor
Shell类型的任务是通过ShellCommandExecutor去执行具体的shell脚本的。
/**
* constructor
* @param logHandler log handler
* @param taskDir task dir
* @param taskAppId task app id
* @param taskInstId task instance id
* @param tenantCode tenant code
* @param envFile env file
* @param startTime start time
* @param timeout timeout
* @param logger logger
*/
public ShellCommandExecutor(Consumer<List<String>> logHandler,
String taskDir,
String taskAppId,
int taskInstId,
String tenantCode,
String envFile,
Date startTime,
int timeout,
Logger logger)
上面是ShellCommandExecutor的构造函数,通过注释以及参数命名大概可以猜到,logHandler是最终打印日志的地方。下面从其赋值以及如何使用分析日志究竟是不是logger打印的。
this.shellCommandExecutor = new ShellCommandExecutor(this::logHandle, taskProps.getTaskDir(),
taskProps.getTaskAppId(),
taskProps.getTaskInstId(),
taskProps.getTenantCode(),
taskProps.getEnvFile(),
taskProps.getTaskStartTime(),
taskProps.getTaskTimeout(),
logger);
ShellCommandExecutor创建的时候,logHandler是通过ShellTask的logHandle方法赋值的。
/**
* log handle
* @param logs log list
*/
public void logHandle(List<String> logs) {
// note that the "new line" is added here to facilitate log parsing
logger.info(" -> {}", String.join("\n\t", logs));
}
上面是logHandle的方法定义,很明显就是通过logger打印日志的。
那logHandler是什么时候使用的呢?
AbstractCommandExecutor
ShellCommandExecutor继承了AbstractCommandExecutor,在AbstractCommandExecutor.run中调用了一个非常重要的方法:parseProcessOutput
private void parseProcessOutput(Process process) {
String threadLoggerInfoName = String.format(LoggerUtils.TASK_LOGGER_THREAD_NAME + "-%s", taskAppId);
ExecutorService parseProcessOutputExecutorService = ThreadUtils.newDaemonSingleThreadExecutor(threadLoggerInfoName);
parseProcessOutputExecutorService.submit(new Runnable(){
@Override
public void run() {
BufferedReader inReader = null;
try {
inReader = new BufferedReader(new InputStreamReader(process.getInputStream()));
String line;
long lastFlushTime = System.currentTimeMillis();
while ((line = inReader.readLine()) != null) {
logBuffer.add(line);
lastFlushTime = flush(lastFlushTime);
}
} catch (Exception e) {
logger.error(e.getMessage(),e);
} finally {
clear();
close(inReader);
}
}
});
parseProcessOutputExecutorService.shutdown();
}
parseProcessOutput这个方法就是把Process的标准输入输出打印到了logBuffer中,然后根据条件flush。
private long flush(long lastFlushTime) {
long now = System.currentTimeMillis();
/**
* when log buffer siz or flush time reach condition , then flush
*/
if (logBuffer.size() >= Constants.defaultLogRowsNum || now - lastFlushTime > Constants.defaultLogFlushInterval) {
lastFlushTime = now;
/** log handle */
logHandler.accept(logBuffer);
logBuffer.clear();
}
return lastFlushTime;
}
flush就是根据条件(大小、时间)把logBuffer中的内容,通过logHandler打印,其实就是通过logger打印到文件。
分析到这个地方,我们才真正清楚,任务其实就是通过slf4j打印到文件。那么问题又来了,前端是如何查询日志文件的呢?日志文件的路径前端是如何找到的呢?
logback.xml
既然我们知道了是slf4j在打印日志,那么配置文件在哪里呢?
在dolphinscheduler-server模块的resources目录下,有两个logback.xml文件:worker_logback.xml、master_logback.xml。任务打印日志的配置应该是worker_logback.xml,在哪里指定的呢?
dolphinscheduler-daemon.sh文件中有一个关于日志的配置。
-Dlogging.config=classpath:master_logback.xml

上面是worker_logback.xml,可以看到有两个appender,其中TASKLOGFILE是我们关注的对象。它有一个比较关键的filter,根据logback中filter的概念来猜测,这应该就是用来区分workerlogfile这个appender的。也就是说两个appender,会通过filter分别筛选出各自的日志进行打印。
/**
* Accept or reject based on thread name
* @param event event
* @return FilterReply
*/
@Override
public FilterReply decide(ILoggingEvent event) {
if (event.getThreadName().startsWith(LoggerUtils.TASK_LOGGER_THREAD_NAME) || event.getLevel().isGreaterOrEqual(level)) {
return FilterReply.ACCEPT;
}
return FilterReply.DENY;
}
这个filter根据日志级别和线程名过滤,符合条件的才能打印到当前appender。其实也就是只打印任务线程的日志。
当然了,还配置了Discriminator,它限定了logger的名称符合前面的定义。
/**
* logger name should be like:
* Task Logger name should be like: Task-{processDefinitionId}-{processInstanceId}-{taskInstanceId}
*/
@Override
public String getDiscriminatingValue(ILoggingEvent event) {
String loggerName = event.getLoggerName()
.split(Constants.EQUAL_SIGN)[1];
String prefix = LoggerUtils.TASK_LOGGER_INFO_PREFIX + "-";
if (loggerName.startsWith(prefix)) {
return loggerName.substring(prefix.length(),
loggerName.length() - 1).replace("-","/");
} else {
return "unknown_task";
}
}
LoggerController
前面的分析我们知道,任务的日志其实就是打印到本地日志文件中,那么前端查询的时候估计就是直接读取日志文件然后返回。
但有一个很现实的问题,任务是随机分布在各个worker的,如何读取日志文件呢?
LoggerController.queryLog就是用来查询日志的,它调用了LoggerService.queryLog
public Result queryLog(int taskInstId, int skipLineNum, int limit) {
TaskInstance taskInstance = processDao.findTaskInstanceById(taskInstId);
if (taskInstance == null){
return new Result(Status.TASK_INSTANCE_NOT_FOUND.getCode(), Status.TASK_INSTANCE_NOT_FOUND.getMsg());
}
String host = taskInstance.getHost();
if(StringUtils.isEmpty(host)){
return new Result(Status.TASK_INSTANCE_NOT_FOUND.getCode(), Status.TASK_INSTANCE_NOT_FOUND.getMsg());
}
Result result = new Result(Status.SUCCESS.getCode(), Status.SUCCESS.getMsg());
logger.info("log host : {} , logPath : {} , logServer port : {}",host,taskInstance.getLogPath(),Constants.RPC_PORT);
LogClient logClient = new LogClient(host, Constants.RPC_PORT);
String log = logClient.rollViewLog(taskInstance.getLogPath(),skipLineNum,limit);
result.setData(log);
logger.info(log);
return result;
}
LoggerService.queryLog的逻辑其实就是通过任务实例ID,查询到了任务所在节点以及日志路径,通过LogClient读取日志。当然了,读取的时候,有限定跳过的行数以及需要读取的行数。
LogClient.rollViewLog其实就是一次rpc调用,它连接到对应host的50051端口,读取日志。
LoggerServer
LoggerServer其实就是一个socket服务,它监听Constants.RPC_PORT(50051)端口的连接,交给LogViewServiceGrpcImpl处理对应的rpc请求。
/**
* server start
* @throws IOException io exception
*/
public void start() throws IOException {
/* The port on which the server should run */
int port = Constants.RPC_PORT;
server = ServerBuilder.forPort(port)
.addService(new LogViewServiceGrpcImpl())
.build()
.start();
logger.info("server started, listening on port : {}" , port);
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
// Use stderr here since the logger may have been reset by its JVM shutdown hook.
logger.info("shutting down gRPC server since JVM is shutting down");
LoggerServer.this.stop();
logger.info("server shut down");
}
});
}
rollViewLog的实现如下,其实也比较简单,就是调用readFile读取日志文件,然后返回。
public void rollViewLog(LogParameter request, StreamObserver<RetStrInfo> responseObserver) {
logger.info("log parameter path : {} ,skip line : {}, limit : {}",
request.getPath(),
request.getSkipLineNum(),
request.getLimit());
List<String> list = readFile(request.getPath(), request.getSkipLineNum(), request.getLimit());
StringBuilder sb = new StringBuilder();
boolean errorLineFlag = false;
for (String line : list){
sb.append(line + "\r\n");
}
RetStrInfo retInfoBuild = RetStrInfo.newBuilder().setMsg(sb.toString()).build();
responseObserver.onNext(retInfoBuild);
responseObserver.onCompleted();
}
总结
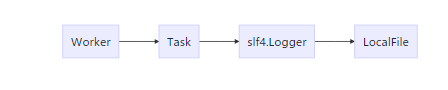
上面是一个简单的流程图,是worker写入日志的流程。

这是一个前端读取日志的路程,读取日志的请求按照箭头方向传递,最终由LoggerServer读取本地日志返回给远程的ApiServer,ApiServer返回给前端。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号