Phoenix数据覆盖的一种解决方案
最近在做实时数仓,需要兼顾离线和实时两种查询方式,大致的方案是数据通过binlog抽取,经Phoenix插入,hive映射hbase表;Phoenix创建索引,实时查询Phoenix;离线查询hive。(这个方案后面再写博客单独介绍)
但这都不是重点,重点是为了避免或者技术上100%解决binlog抽取不丢数,只能采取增量补数的方案了。也就是每小时增量抽取MySQL数据,通过hive映射Phoenix的方式,把这部分数据补充到Phoenix。
如何避免增量数据插入和Phoenix插入的相互覆盖问题呢?这就涉及到事务的问题,也就是说利用行锁,通过增量数据的更新时间判断是否插入。当批量数据更新时间比Phoenix现有数据新,此时插入现有数据;
否则不更新数据。
这是一种常见的解决方式,通过事务避免覆盖的问题。但有没有更优雅的方案呢?毕竟Phoenix的事务目前还是beta版本,而且涉及到事务,性能也跟不上。那怎么搞呢?
这个要从HBase的机制说起。HBase里面一个很重要的概念就是数据的版本/时间戳,也就是说每行的每个列都会有一个时间戳,来标志版本号。而Phoenix默认情况下只能查询最后一个版本,也就是最新的数据。
这跟数据覆盖有啥关系呢?我的方案巧就巧在这里!
如果我们把数据的更新时间(比如update_at)字段映射到Hbase的时间戳,即使旧版本数据被插入到HBase,Phoenix也只能查询更新时间最大的数据!这样就巧妙的避免了事务!惊不惊喜,意不意外!
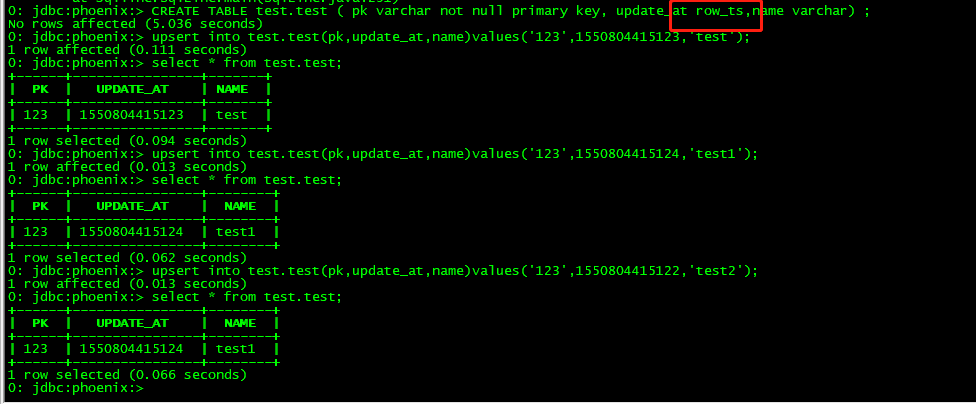
然而,Phoenix不支持将普通字段映射到HBase的时间戳。怎么办呢?哈哈,目前只能凉拌,不过我个人修改了Phoenix的源码,添加了ROW_TS类型。这样就可以啦。有图为证
欢迎大家加微信聊技术:HelloGrape
写点博客不容易,请大家转载注意添加原创连接,参考也请注明出处

 浙公网安备 33010602011771号
浙公网安备 33010602011771号