JVM理论知识准备
JVM
1:JVM基础知识
- 什么是JVM
- JVM是一种规范
- 也是一种运行在操作系统之上的虚拟操作系统,也叫虚拟机;当然也存在一种基于硬件的JVM实现(具体的名字有点忘记了),这种作者自己理解的话认为也算是操作系统了
- 常见的JVM
- Oracle HotSpot(原SUN,不过也是收购来的),虽然是商用的,对应也有开源的版本
- Oracle JRockit(原BEA),现在已经被整合到HotSpot,算是废了吧(不过两套标准不太一样,其实整合的东西不多)
- IBM J9
- Azul ZING
2:ClassFileFormat
1、二进制Class文件的格式,这个比较复杂,建议自己看JVM规范文档吧,https://docs.oracle.com/javase/specs/jvms/se14/jvms14.pdf
2、大致是
ClassFile { u4 magic; // 魔数,姑且当做是用来直接判断是否class文件的一个特定数值 u2 minor_version; // 小版本号 u2 major_version; // 大版本号 u2 constant_pool_count; // 常量池大小,常量池实际数量要-1 cp_info constant_pool[constant_pool_count-1];// 常量池,姑且也认为是副本池吧,后面要用的数据在这里 u2 access_flags; // 访问标志,就是public、private这些 u2 this_class; // class的类型,好像是指向常量池 u2 super_class; // 父类类型 u2 interfaces_count; // 实现的接口数量 u2 interfaces[interfaces_count];// 实际的接口信息 u2 fields_count; // 成员变量(字段)数量 field_info fields[fields_count]; // 具体的字段信息 u2 methods_count; // 方法数量 method_info methods[methods_count]; // 具体的方法信息 u2 attributes_count; // 属性数量 attribute_info attributes[attributes_count]; // 具体的属性信息 }
intellij idea可以用这个插件来查看对应的class文件信息,会更直观:https://plugins.jetbrains.com/plugin/9248-jclasslib-bytecode-viewer/
3:类编译-加载-初始化
ClassLoader的三个过程
- Loading:相当于把二进制class文件加载到内存中(方法区),留一个访问入口
- Linking
- Valid:校验文件格式
- Prepare:实例化,对静态变量设置默认值
- Resolution:解析变量、方法等引用到常量池为直接引用,这一部有可能是延迟加载的
- initalzating:初始化,就是对静态变量设置初始值
4:JMM(Java Memory Model)
4.1、对象的内存布局:
-markword(8字节)
-class类型(没压缩的话是8字节,压缩后是4字节)
-数组的话,有个数组长度
-成员变量(这边是指针,没压缩的话,也是8字节,压缩后是4字节)
-补齐,如果最后字节数不是8的位数,则进行补齐
问题:new Object()大小,16字节,不管是否开启压缩,压缩的情况下,补齐后16字节,不压缩就直接是16字节。
markword包含信息:
-hashCode(如果hashCode方法被重写,则没有;偏向锁的状态下也没有,同样的位置用于存储一些和锁线程相关的信息)
-锁信息,两位:01无锁或偏向锁(偏向锁单独一个位判断),其他优点忘记了
-GC信息(年龄)
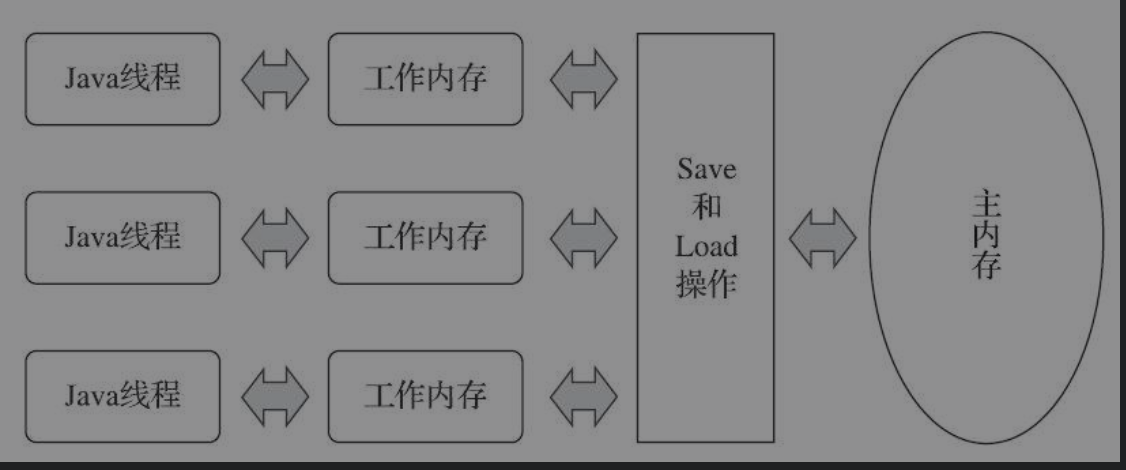
4.2、Java线程、工作内存和主内存之间的关系
5:对象
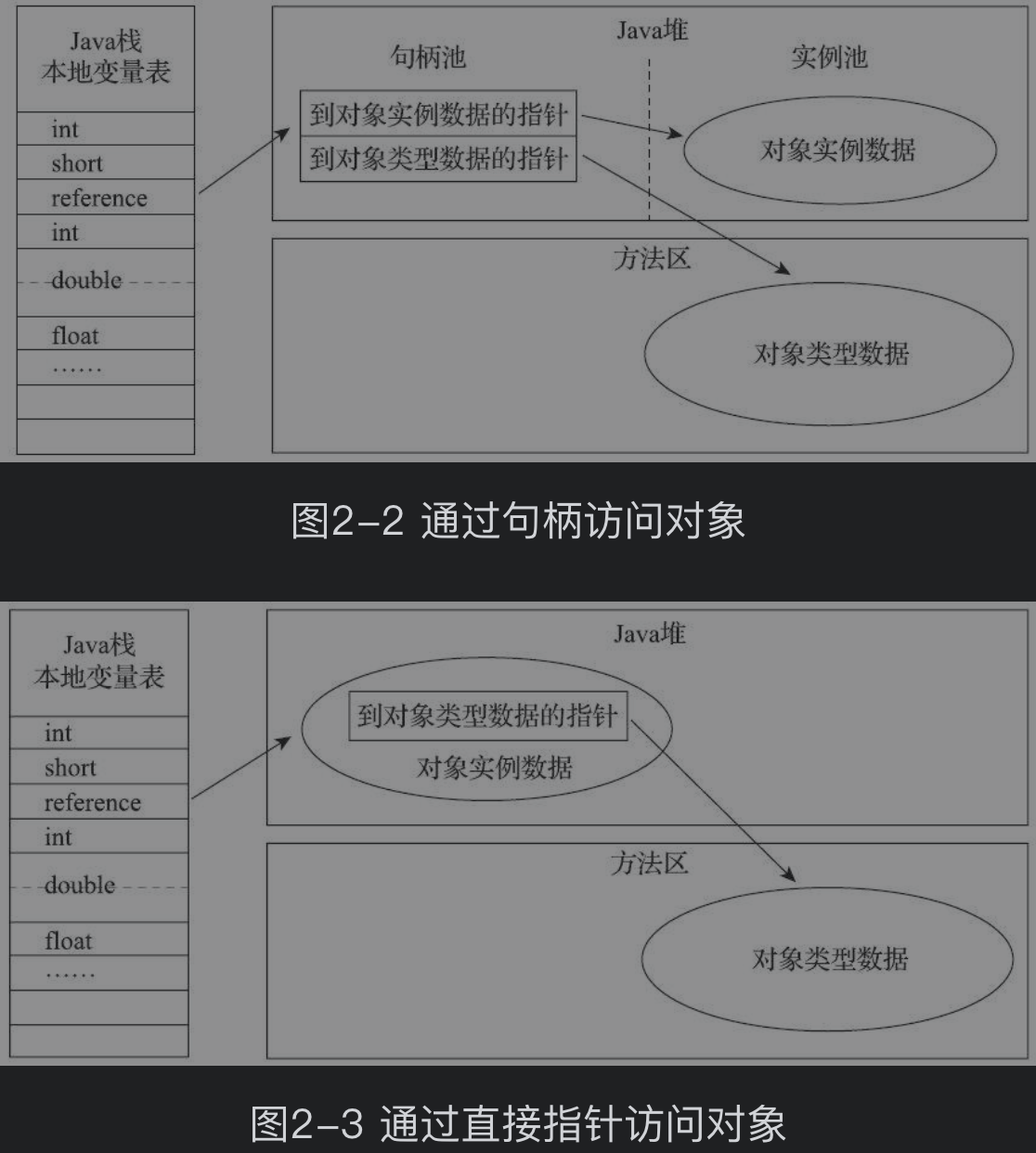
定位方式
1:句柄池 (指针池)间接指针,节省内存
2:直接指针,访问速度快
6:GC常用垃圾回收器
7.1、Serial 新生代 + Serial Old老年代
单线程回收,这边指的是垃圾回收线程单线程
7.2、Parallel Scavenge 新生代 + Parallel Scavenge Old 老年代
多线程并行回收(注意这里是并行回收,指的是垃圾回收线程不与工作线程同时进行,并发则是指垃圾回收线程和工作线程一起执行),目标是高吞吐量(工作时间 /(工作时间+垃圾回收时间))
7.3、ParNew 新生代+CMS(Concurrent Mark Sweep) 老年代
新生代是基于Paralle Scavenge产生的,原因是因为其不能搭配CMS使用,针对的是低延迟场景(响应速度快)
CMS是并发垃圾回收算法的里程碑,注意这边的并发是指垃圾回收可以和工作线程同时进行
7.4、G1(Garbage First):全代管理器,逻辑上还存在分代模型;是一个综合性比较强的垃圾回收器,可以保证比较低的延迟下,同时有较好的吞吐量
G1是基于CMS开发出来的,在物理上已经不再有分代的模型,只是逻辑上保留,且可以动态切换
G1是基于Region的,Region在不同时刻可以作为不同的年代,比如年轻代或老年代,一般有四个区域:年轻代Eden、年轻代survivor、老年代、大对象区

 浙公网安备 33010602011771号
浙公网安备 33010602011771号