

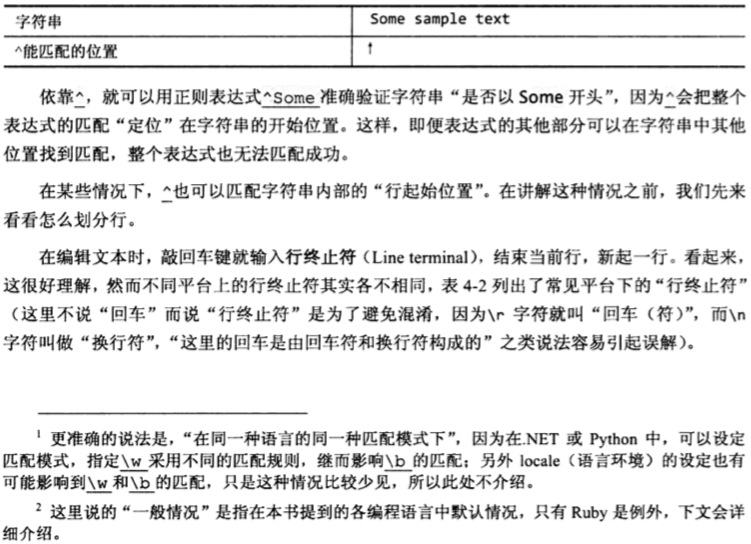
正则表达式——行起始/结束位置
单词边界匹配的是某个位置而不是文本,在正则表达式中,这类匹配位置的元素叫做锚点(anchor),它用来“定位”到某个位置。常用的锚点还有^和$,它们分别匹配字符串的开始位置和结束位置,所以可以用来判断“整个字符串能否由表达式匹配”。
| 平台 | 行终止符 |
| UNIX/Linux | \n |
| Windows | \r\n |
| Mac OS | \n |


// php
// ^ 和 $ 特点:进行正则表达式替换时并不会被替换。
// 也就是说,在起始/结束位置进行替换,只会在起始/结束位置添加一些字符,位置本身仍然存在。
$plainText = "line1\nline2\nline3";
$result = preg_replace('/$/m', '</p>', preg_replace('/^/m', '<p>', $plainText));
// ^ 和 $ 常用功能是删去多余的空白,包括行首尾的空白和空行。
$withSpaces = " begin\n between\t\n\nend ";
$spaceRegex = '/(^\s+|\s+$)/m';
$result = preg_replace($spaceRegex, '', $withSpaces);
// 不但第三行被删除,第二行和第四行也合并成一行,中间的\t\n\n全部删除了,第二行末尾没有了换行符;
// 而真正的目的其实只是将\t\n\n替换为\n。
// 仔细看看正则表达式(^\s+|\s+$)可以知道,在\s+$中,\s可以匹配\t和\n,
// 所以\s+$可以匹配开始的\t\n,同样^\s+可以匹配结尾的\n,所以\t\n\n经过两步被彻底删除
begin
betweenend
^和$的总结
|
模式 |
行为 | .NET | Java | Javascript | PHP | Python | Ruby |
|
默 认 模 式 |
^匹配字符串起始位置 | √ | √ | √ | √ | √ | √ |
| ^匹配字符串内部行起始位置 | √ | ||||||
| $匹配字符串结束位置 | √ | √ | √ | √ | √ | √ | |
| $匹配字符串末尾行终止符之前 | √ | √ | √ | √ | √ | ||
| $匹配字符串内部行结束位置 | √ | ||||||
| 支持多行模式 | √ | √ | √ | √ | √ | ||
|
多 行 模 式 |
^匹配字符串起始位置 | √ | √ | √ | √ | √ | 无此模式 |
| ^匹配字符串内部行起始位置 | √ | √ | √ | √ | √ | 无此模式 | |
| $匹配字符串结束位置 | √ | √ | √ | √ | √ | 无此模式 | |
| $匹配字符串内部行结束位置 | √ | √ | √ | √ | √ | 无此模式 | |
| \A 等于默认模式的^ | √ | √ | √ | 只能匹配字符串的起始位置 | × | ||
| \Z 等于默认模式的$ | √ | √ | √ | 只能匹配字符串的结束位置 | × | ||
| \z 匹配字符串的结束位置 | √ | √ | √ | 无 | × | ||

