

56门控循环单元GRU
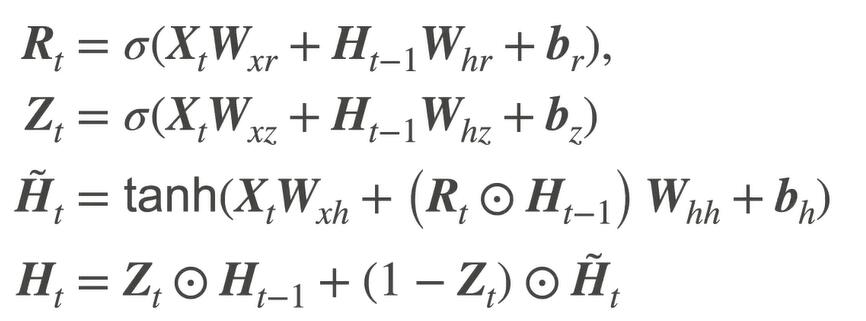
点击查看代码
import torch
from torch import nn
from d2l import torch as d2l
"""
额外的控制单元
"""
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 初始化模型参数
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
# 定义隐状态的初始化函数
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
# 定义门控循环单元模型
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
# (num_steps, batch_size, vocab_size)
for X in inputs:
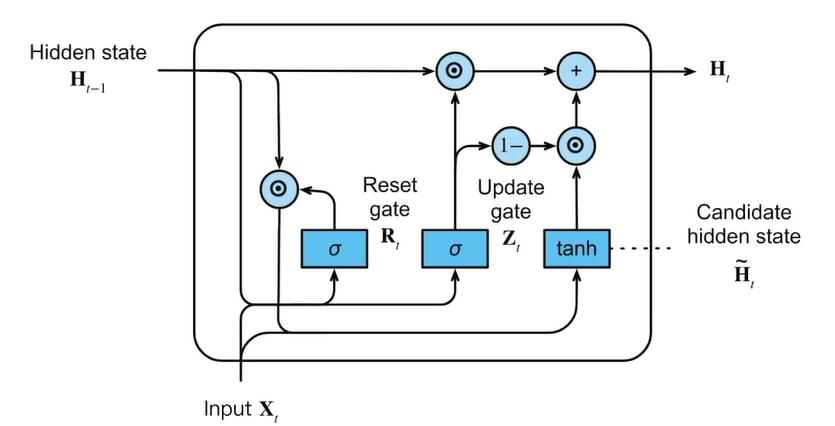
# 𝐙𝑡=𝜎(𝐗𝑡𝐖𝑥𝑧+𝐇𝑡−1𝐖ℎ𝑧+𝐛𝑧)
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
# 𝐑𝑡=𝜎(𝐗𝑡𝐖𝑥𝑟+𝐇𝑡−1𝐖ℎ𝑟+𝐛𝑟)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
# 𝐇̃𝑡=tanh(𝐗𝑡𝐖𝑥ℎ+(𝐑𝑡⊙𝐇𝑡−1)𝐖ℎℎ+𝐛ℎ)
# ⊙ 按元素乘法
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
# 𝐇𝑡=𝐙𝑡⊙𝐇𝑡−1+(1−𝐙𝑡)⊙𝐇̃𝑡
H = Z * H + (1 - Z) * H_tilda
# 输出
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
# 训练
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
# d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# 简洁实现
# 矩阵乘法
num_inputs = vocab_size
"""
input_size – The number of expected features in the input x
hidden_size – The number of features in the hidden state h
num_layers – Number of recurrent layers.
E.g., setting num_layers=2 would mean stacking two GRUs
together to form a stacked GRU, with the second GRU
taking in outputs of the first GRU and computing the final results.
Default: 1
bias – If False, then the layer does not use bias weights b_ih and b_hh.
Default: True
batch_first – If True, then the input and output tensors are provided
as (batch, seq, feature) instead of (seq, batch, feature).
Note that this does not apply to hidden or cell states.
See the Inputs/Outputs sections below for details.
Default: False
dropout – If non-zero, introduces a Dropout layer on the outputs of
each GRU layer except the last layer, with dropout probability
equal to dropout.
Default: 0
bidirectional – If True, becomes a bidirectional GRU.
Default: False
"""
gru_layer = nn.GRU(num_inputs, num_hiddens)
# model = d2l.RNNModel(gru_layer, len(vocab))
# model = model.to(device)
# d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# torch.save(model.state_dict(), 'gru.params')
clone = d2l.RNNModel(gru_layer, vocab_size=len(vocab))
clone = clone.to(device)
clone.load_state_dict(torch.load('gru.params'))
re = d2l.predict_ch8('time traveller', 15, clone, vocab, device)
print(re)
