大数据学习17_Spark集群搭建以及入门案例运行
Spark
Spark是什么
- Apache Spark 是一个快速的, 多用途的集群计算系统, 相对于 Hadoop MapReduce 将中间结果保存在磁盘中, Spark 使用了内存保存中间结果, 能在数据尚未写入硬盘时在内存中进行运算.
- Spark 只是一个计算框架, 不像 Hadoop 一样包含了分布式文件系统和完备的调度系统, 如果要使用 Spark, 需要搭载其它的文件系统和更成熟的调度系统
- Spark 产生之前, 已经有非常成熟的计算系统存在了, 例如 MapReduce, 这些计算系统提供了高层次的API, 把计算运行在集群中并提供容错能力, 从而实现分布式计算.虽然这些框架提供了大量的对访问利用计算资源的抽象, 但是它们缺少了对利用分布式内存的抽象, 这些框架多个计算之间的数据复用就是将中间数据写到一个稳定的文件系统中(例如HDFS), 所以会产生数据的复制备份, 磁盘的I/O以及数据的序列化, 所以这些框架在遇到需要在多个计算之间复用中间结果的操作时会非常的不高效.而这类操作是非常常见的, 例如迭代式计算, 交互式数据挖掘, 图计算等.
- 认识到这个问题后, 学术界的 AMPLab 提出了一个新的模型, 叫做
RDDs.RDDs是一个可以容错且并行的数据结构, 它可以让用户显式的将中间结果数据集保存在内中, 并且通过控制数据集的分区来达到数据存放处理最优化.同时RDDs也提供了丰富的 API 来操作数据集.
Spark的优点
- Spark 是为了解决 MapReduce 等过去的计算系统无法在内存中保存中间结果的问题
- Spark 的核心是 RDDs, RDDs 不仅是一种计算框架, 也是一种数据结构
- Spark 的在内存时的运行速度是 Hadoop MapReduce 的100倍
- 基于硬盘的运算速度大概是 Hadoop MapReduce 的10倍
- Spark 实现了一种叫做 RDDs 的 DAG 执行引擎, 其数据缓存在内存中可以进行迭代处理
- Spark 支持 Java, Scala, Python, R, SQL 等多种语言的API.
- Spark 支持超过80个高级运算符使得用户非常轻易的构建并行计算程序
- Spark 可以使用基于 Scala, Python, R, SQL的 Shell 交互式查询.
- Spark 提供一个完整的技术栈, 包括 SQL执行, Dataset命令式API, 机器学习库MLlib, 图计算框架GraphX, 流计算SparkStreaming
- 用户可以在同一个应用中同时使用这些工具, 这一点是划时代的
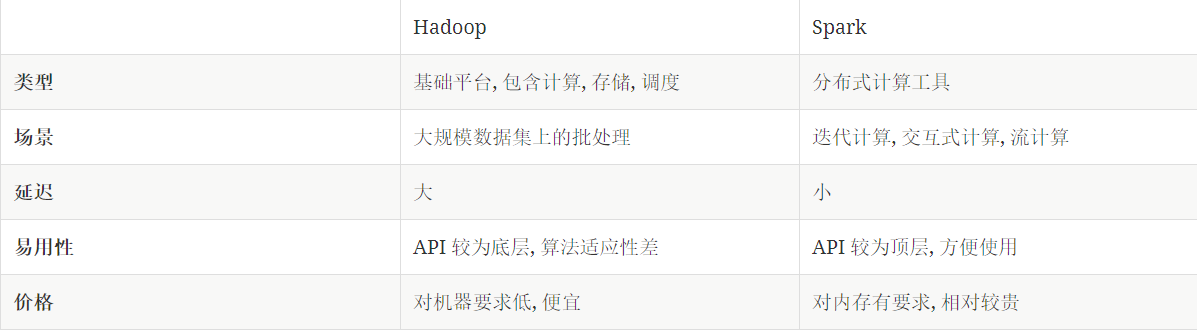
Spark和Hadoop的异同
Spark 集群搭建
这里是将Spark搭建在Hadoop的yarn集群中,采用spark的版本是2.2.0的,下载的时候要和Hadoop的版本对应。我的Hadoop版本是2.7.5的。
下载链接:https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
解压移动
解压 Spark 安装包
tar xzvf spark-2.2.0-bin-hadoop2.7.tgz
移动 Spark 安装包
mv spark-2.2.0-bin-hadoop2.7.tgz /export/servers/spark
修改配置文件
修改配置文件`spark-env.sh`, 以指定运行参数
cp spark-env.sh.template spark-env.sh vi spark-env.sh
将以下内容复制进配置文件末尾
# 指定 Java Home export JAVA_HOME=/export/servers/jdk1.8.0 (和jdk版本对应)
# 指定 Spark Master 地址 export SPARK_MASTER_HOST=node01 export SPARK_MASTER_PORT=7077
修改配置文件 slaves, 以指定从节点为止, 从在使用 sbin/start-all.sh 启动集群的时候, 可以一键启动整个集群所有的 Worker
cp slaves.template slaves vi slaves
文件末尾添加
node02 node03
分发和运行
将 Spark 安装包分发给集群中其它机器
cd /export/servers
scp -r spark root@node02:$PWD
scp -r spark root@node03:$PWD
启动 Spark Master 和 Slaves, 以及 HistoryServer
cd /export/servers/spark
sbin/start-all.sh
sbin/start-history-server.sh
高可用配置
对于 Spark Standalone 集群来说, 当 Worker 调度出现问题的时候, 会自动的弹性容错, 将出错的 Task 调度到其它 Worker 执行
但是对于 Master 来说, 是会出现单点失败的, 为了避免可能出现的单点失败问题, Spark 提供了两种方式满足高可用
-
使用 Zookeeper 实现 Masters 的主备切换
-
使用文件系统做主备切换
进入 spark-env.sh 所在目录, 打开 vi 编辑
编辑 spark-env.sh, 添加 Spark 启动参数, 并去掉 SPARK_MASTER_HOST 地址,内容如下:
1 # 指定 Java Home 2 export JAVA_HOME=/export/servers/jdk1.8.0_141 3 4 # 指定 Spark Master 地址 5 # export SPARK_MASTER_HOST=node01 6 export SPARK_MASTER_PORT=7077 7 8 # 指定 Spark History 运行参数 9 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log" 10 11 # 指定 Spark 运行时参数 12 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"
配置完之后在进行一次分发即可。
启动查看是否配置成功
在 node01 上启动整个集群
sbin/start-all.sh sbin/start-history-server.sh
在 node02 上单独再启动一个 Master
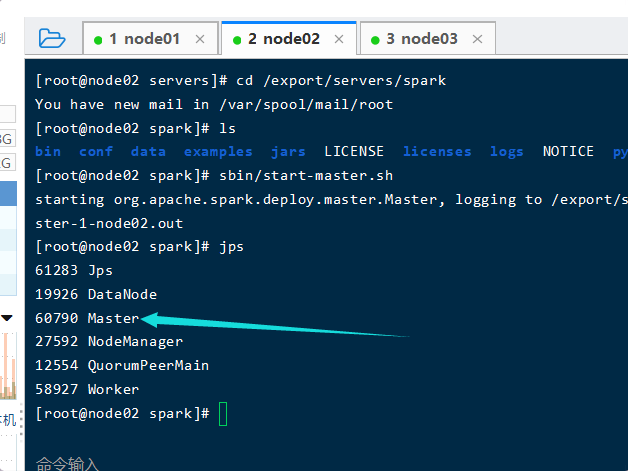
sbin/start-master.sh
在node01启动master
在node02再一次启动一个master

在Web UI界面查看状态
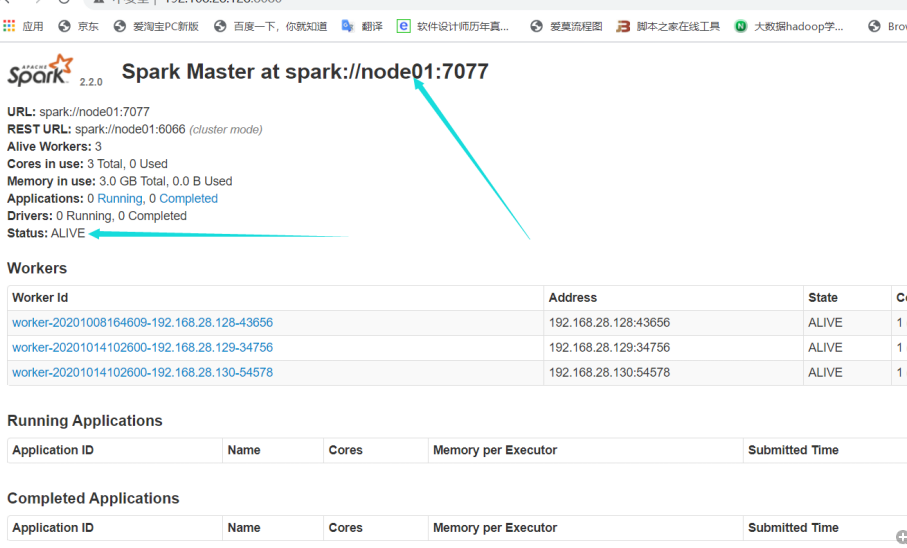
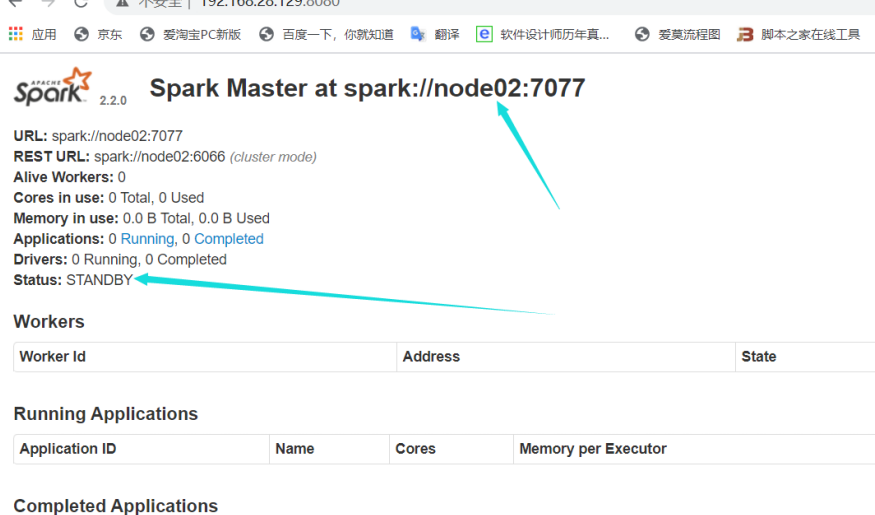
可以看到node01是激活状态,node02是备用状态
入门案例运行
Spark自带的蒙特卡洛算法求圆周率的值;
jar包路径如下
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://node01:7077,node02:7077,node03:7077 \ --executor-memory 1G \ --total-executor-cores 2 \ /export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \ 100
运行结果

这样就可以证明Spark完全搭建完成!!!
