热词统计
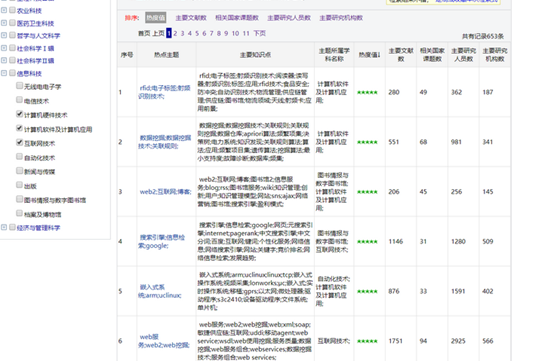
知网的数据,可以看到,只需要在左侧选择相关专业或者学科,右面就会对应查询出热门主题排行,这里获取整个表格的前一百行,需要的是除索引外前两列数据。主要是对第一列的数据进行相似度分析以及词频统计。获取到html数据后,使用beautifulsoup进行数据的提取,可以看到主题中是用分号进行短语分割的,首先会对这些使用split进行拆分后存到列表里,然后使用Counter统计词频,
from bs4 import BeautifulSoup
from collections import Counter
import jieba
import numpy as np
from operator import itemgetter
# 余弦相似度检验文本匹配情况
def cos_sim(str1, str2):
co_str1 = (Counter(str1))
co_str2 = (Counter(str2))
p_str1 = []
p_str2 = []
for temp in set(str1 + str2):
p_str1.append(co_str1[temp])
p_str2.append(co_str2[temp])
p_str1 = np.array(p_str1)
p_str2 = np.array(p_str2)
return p_str1.dot(p_str2) / (np.sqrt(p_str1.dot(p_str1)) * np.sqrt(p_str2.dot(p_str2)))
# 从本地提供的一个html中获取信息
path = 'soft.html'
htmlfile = open(path,'r',encoding='utf-8')
htmlhandle = htmlfile.read()
# 使用bs提取html中需要的数据
soup = BeautifulSoup(htmlhandle,'lxml')
list = soup.find_all('tr')
theme_list = []
knowledge_list = []
# 分离热点词汇和相关知识点词汇
for i in list:
tds = i.find_all('td')
for j in range(len(tds)):
if j==1:
for k in tds[j].text.split(";"):
if k.strip()!='':
theme_list.append(k.strip())
elif j==2:
knowledge_list.append(tds[j].text.strip())
# 词频统计
counter = Counter(theme_list)
dictionary = dict(counter)
fenci_list = []
print(dictionary)
# print(counter.most_common(10))
# 对每一个热点词汇进行jieba分词,用于后面检验文本相似度
for i in dictionary:
fenci_list.append(jieba.lcut(i))
# 操作分词列表,匹配文本相似度,并将相似度大于0.49的热词从字典中进行合并,同时移除后出现的热点词
for i in range(len(fenci_list)):
for j in range((i+1),len(fenci_list)):
result = cos_sim(fenci_list[i],fenci_list[j])
if result!=0.0:
# print(''.join(fenci_list[i])+" 和 "+''.join(fenci_list[j])+" 相似度为:",result)
pass
if result>0.49:
try:
value = dictionary.pop(''.join(fenci_list[j]))
# print(value)
dictionary[''.join(fenci_list[i])]+=value
except Exception as e:
# print(e)
pass
print(dictionary)
# 将相似文本合并后的结果倒序打印
final_result = sorted(dictionary.items(),key=itemgetter(1),reverse=True)
for i in range(len(final_result)):
print(final_result[i])

