集群资源管理
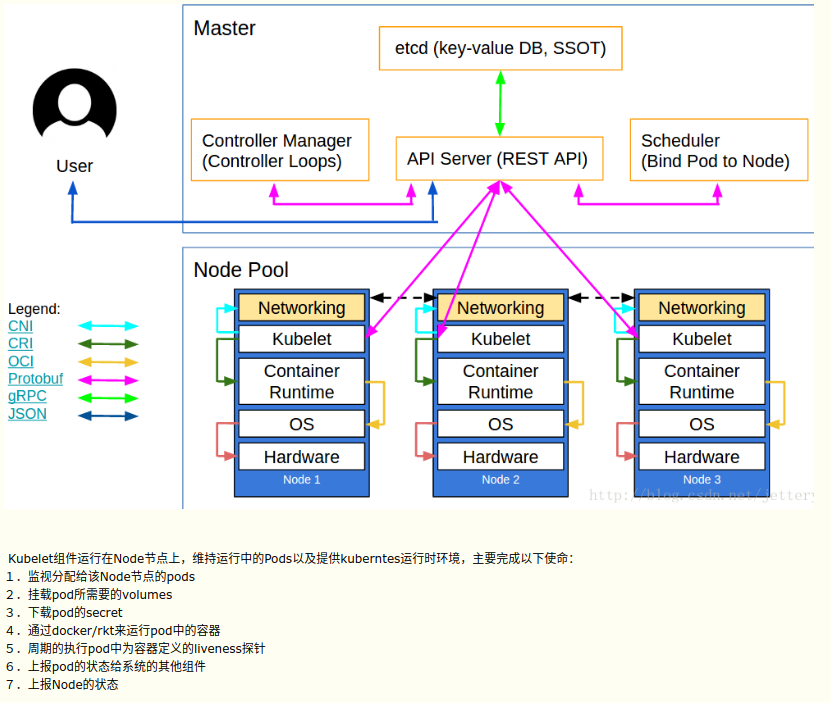

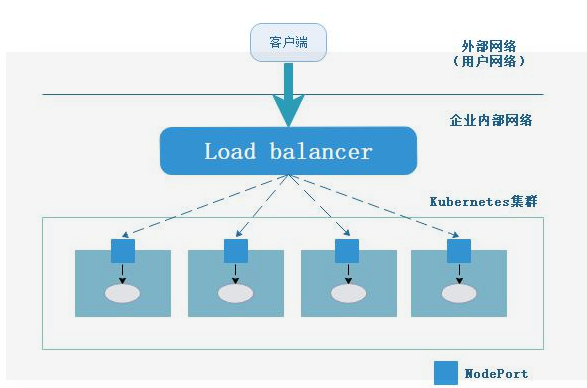
为了管理异构和不同配置的主机,为了便于Pod的运维管理,Kubernetes中提供了很多集群管理的配置和管理功能,通过namespace划分的空间,通过为node节点创建label和taint⽤于pod的调度等
Node
Node是kubernetes集群的⼯作节点,可以是物理机也可以是虚拟机。
Node的状态
Node包括如下状态信息
- Address
HostName:可以被kubelet中的 --hostname-override 参数替代。
ExternalIP:可以被集群外部路由到的IP地址。
InternalIP:集群内部使⽤的IP,集群外部⽆法访问。 - Condition
OutOfDisk:磁盘空间不⾜时为 True
Ready:Node controller 40秒内没有收到node的状态报告为 Unknown ,健康为 True ,否则为 False 。
MemoryPressure:当node没有内存压⼒时为 True ,否则为 False 。
DiskPressure:当node没有磁盘压⼒时为 True ,否则为 False 。 - Capacity
CPU
内存
可运⾏的最⼤Pod个数
Info:节点的⼀些版本信息,如OS、kubernetes、docker等
Node管理
禁⽌pod调度到该节点上
kubectl cordon
驱逐该节点上的所有pod
kubectl drain
该命令会删除该节点上的所有Pod(DaemonSet除外),在其他node上重新启动它们,通常该节点需要维护时使⽤该
命令。直接使⽤该命令会⾃动调⽤ kubectl cordon
Namespace
在⼀个Kubernetes集群中可以使⽤namespace创建多个“虚拟集群”,这些namespace之间可以完全隔离,也可以通过某种⽅式,让⼀个namespace中的service可以访问到其他的namespace中的服务,我们在CentOS中部署kubernetes1.6集群的时候就⽤到了好⼏个跨越namespace的服务,⽐如Traefik ingress和 kube-system namespace下的service就可以为整个集群提供服务,这些都需要通过RBAC定义集群级别的⻆⾊来实现
哪些情况下适合使⽤多个namespace
因为namespace可以提供独⽴的命名空间,因此可以实现部分的环境隔离。当你的项⽬和⼈员众多的时候可以考虑根据项⽬属性,例如⽣产、测试、开发划分不同的namespace
Namespace使⽤
获取集群中有哪些namespace
kubectl get ns
集群中默认会有 default 和 kube-system 这两个namespace。
在执⾏ kubectl 命令时可以使⽤ -n 指定操作的namespace。
⽤户的普通应⽤默认是在 default 下,与集群管理相关的为整个集群提供服务的应⽤⼀般部署在 kube-system 的
namespace下,例如我们在安装kubernetes集群时部署的 kubedns 、 heapseter 、 EFK 等都是在这个namespace下⾯。另外,并不是所有的资源对象都会对应namespace, node 和 persistentVolume 就不属于任何namespace
Label
Label是附着到object上(例如Pod)的键值对。可以在创建object的时候指定,也可以在object创建后随时指定。Labels的值对系统本身并没有什么含义,只是对⽤户才有意义
Label能够将组织架构映射到系统架构上(就像是康威定律),这样能够更便于微服务的管理,你可以给object打上如下类型的label
"release" : "stable" , "release" : "canary"
"environment" : "dev" , "environment" : "qa" , "environment" : "production"
"tier" : "frontend" , "tier" : "backend" , "tier" : "cache"
"partition" : "customerA" , "partition" : "customerB"
"track" : "daily" , "track" : "weekly"
"team" : "teamA" , "team:" : "teamB"
语法与字符集
Label key的组成:
- 不得超过63个字符
- 可以使⽤前缀,使⽤/分隔,前缀必须是DNS⼦域,不得超过253个字符,系统中的⾃动化组件创建的label必须指定
前缀, kubernetes.io/ 由kubernetes保留 - 起始必须是字⺟(⼤⼩写都可以)或数字,中间可以有连字符、下划线和点
Label value的组成:
- 不得超过63个字符
- 起始必须是字⺟(⼤⼩写都可以)或数字,中间可以有连字符、下划线和点
Label selector
Label不是唯⼀的,很多object可能有相同的label。
通过label selector,客户端/⽤户可以指定⼀个object集合,通过label selector对object的集合进⾏操作
Label selector有两种类型:
- equality-based :可以使⽤ = 、 == 、 != 操作符,可以使⽤逗号分隔多个表达式
- set-based :可以使⽤ in 、 notin 、 ! 操作符,另外还可以没有操作符,直接写出某个label的key,表示过滤有某
个key的object⽽不管该key的value是何值, ! 表示没有该label的object
$ kubectl get pods -l environment=production,tier=frontend
$ kubectl get pods -l 'environment in (production),tier in (frontend)'
$ kubectl get pods -l 'environment in (production, qa)'
$ kubectl get pods -l 'environment,environment notin (frontend)'
在API object中设置label selector
在 service 、 replicationcontroller 等object中有对pod的label selector,使⽤⽅法只能使⽤等于操作,例如:
selector:
component: redis
在 Job 、 Deployment 、 ReplicaSet 和 DaemonSet 这些object中,⽀持set-based的过滤,例如
selector:
matchLabels:
component: redis
matchExpressions:
- {key: tier, operator: In, values: [cache]}
- {key: environment, operator: NotIn, values: [dev]}
Annotation
注解。Annotation可以将Kubernetes资源对象关联到任意的⾮标识性元数据。使⽤客户端(如⼯具和库)可以检索到这些元数据
Label和Annotation都可以将元数据关联到Kubernetes资源对象。Label主要⽤于选择对象,可以挑选出满⾜特定条件的对象。相⽐之下,annotation 不能⽤于标识及选择对象。annotation中的元数据可多可少,可以是结构化的或⾮结构化的,也可以包含label中不允许出现的字符。
annotation和label⼀样都是key/value键值对映射结构:
"annotations": {
"key1" : "value1",
"key2" : "value2"
}
可以记录在 annotation 中的对象信息
- 声明配置层管理的字段。使⽤annotation关联这类字段可以⽤于区分以下⼏种配置来源:客户端或服务器设置的默认值,⾃动⽣成的字段或⾃动⽣成的 auto-scaling 和 auto-sizing 系统配置的字段。
- 创建信息、版本信息或镜像信息。例如时间戳、版本号、git分⽀、PR序号、镜像哈希值以及仓库地址。
- 记录⽇志、监控、分析或审计存储仓库的指针
- 可以⽤于debug的客户端(库或⼯具)信息,例如名称、版本和创建信息。
- ⽤户信息,以及⼯具或系统来源信息、例如来⾃⾮Kubernetes⽣态的相关对象的URL信息。
- 轻量级部署⼯具元数据,例如配置或检查点。
- 负责⼈的电话或联系⽅式,或能找到相关信息的⽬录条⽬信息,例如团队⽹站。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号