prometheus 标签修改promSQL
relabel_configs
根据prometheus 监控k8s配置文件中学习
未修改前默认配置文件:
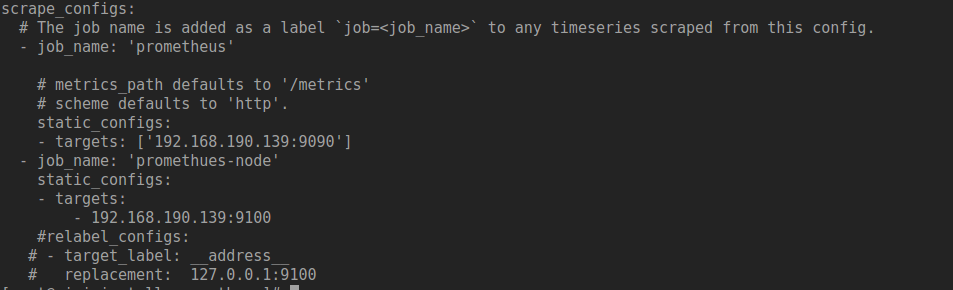
网页显示:
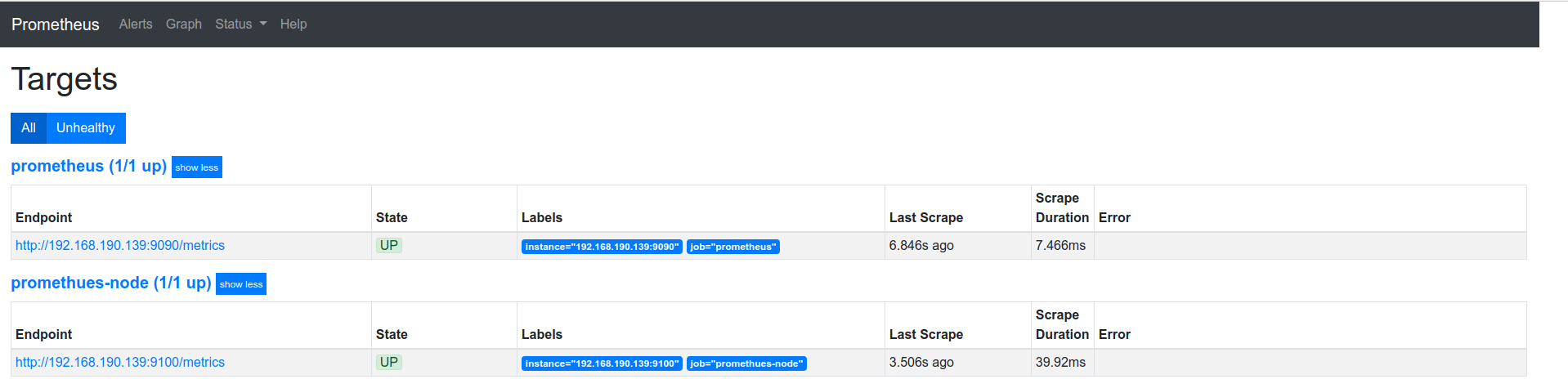
修改配置文件后:

网页显示:

服务发现网页:
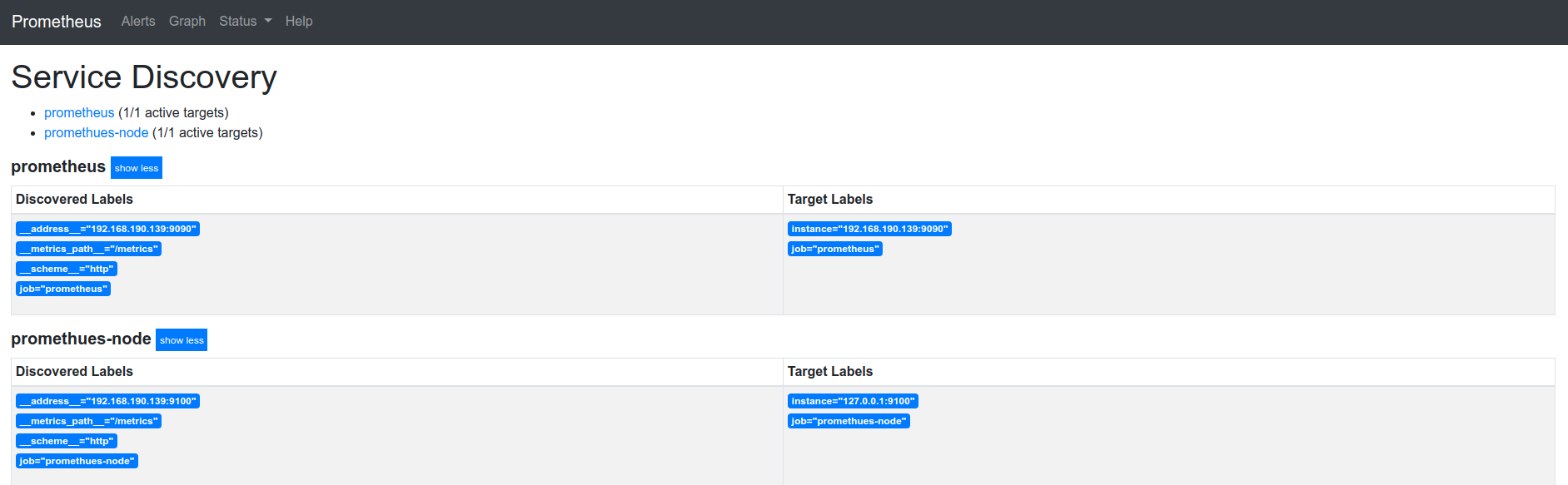
总结:
在数据采集之前对任何目标的标签进行修改,重打标签的意义就是如果标签有重复的可以帮你重命名
relabel_config语法
relabel_configs:
[ source_labels: '[' <labelname> [, ...] ']' ] ##源标签,指定对哪个现有标签进行操作
[ separator: <string> | default = ; ] ##多个源标签时连接的分隔符
[ target_label: <labelname> ] ##要将源标签换成什么名字
[ regex: <regex> | default = (.*) ] ##怎么来匹配源标签,默认匹配所有
[ modulus: <uint64> ] ##不怎么会用到
[ replacement: <string> | default = $1 ] ##替换正则表达式匹配到的分组,分组引用$1,$2,$3
[ action: <relabel_action> | default = replace ] ##基于正则表达式匹配执行的操作,默认替换
action重新打标签动作
值 描述
replace 默认,通过正则匹配 source_label 的值,使用 replacement 来引用表达式匹配的分组
keep 删除 regex 于链接不匹配的目标 source_labels
drop 删除 regex 与连接匹配的目标 source_labels
labeldrop 匹配 Regex 所有标签名称
labelkeep 匹配 regex 所有标签名称
hashmod 设置 target_label 为 modulus 连接的哈希值 source_lanels
labelmap 匹配 regex 所有标签名称,复制匹配标签的值分组,replacement 分组引用 (${1},${2}) 替代
节点贴标签
未修改前:
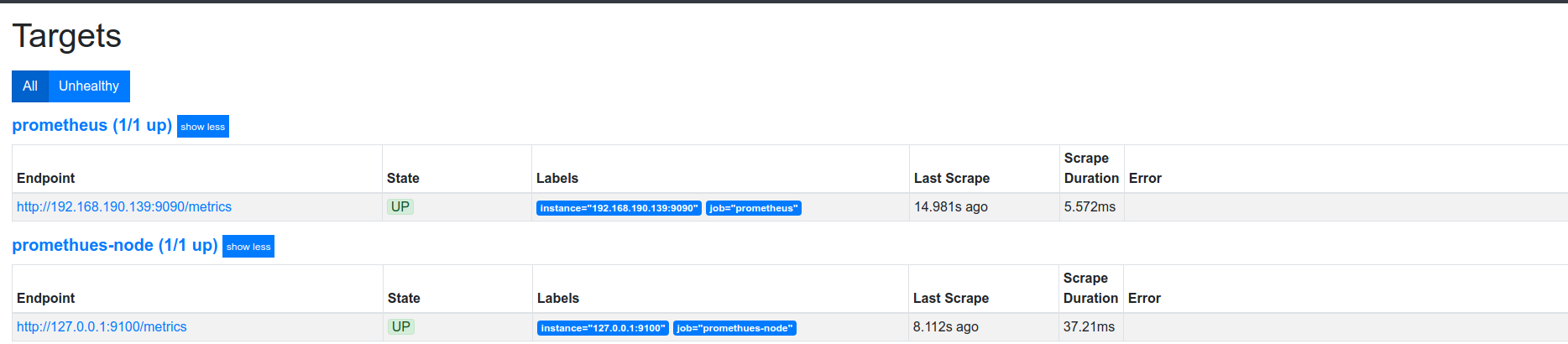
修改后:
配置:
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['192.168.190.139:9090']
- job_name: 'promethues-node'
static_configs:
- targets:
- 192.168.190.139:9100
labels: ##添加的标签
server: local ##添加的标签
relabel_configs:
- target_label: __address__
replacement: 127.0.0.1:9100
效果:

标签重命名
修改前:

修改后配置:
- job_name: 'promethues-node'
static_configs:
- targets:
- 192.168.190.139:9100
labels:
server: local
relabel_configs:
- action: replace ##动作:替换
source_labels: ['job'] ##对源标签操作,标签名为‘job’
regex: (.*) ##正则,会匹配到job值
replacement: $1 ##引用正则匹配到的内容
target_label: ttt ##赋予新的标签,名为ttt
修改后展示:

因为原来的标签名未删除,所以还会展示,现在删除原来的标签
配置文件:
- job_name: 'promethues-node'
static_configs:
- targets:
- 192.168.190.139:9100
labels:
server: local
relabel_configs:
- action: replace
source_labels: ['job']
regex: (.*)
replacement: $1
target_label: ttt
- action: labeldrop
regex: job

受影响的只是标签,对采集的主机并没有产生影响
不想采集目标标签数据
scrape_configs:
- job_name: 'server21'
static_configs:
- targets: ['localhost:9090']
relabel_configs:
- action: replace
source_labels: ['job']
regex: (.*)
replacement: $1
target_label: local
- action: drop ##删除标签为 job 的节点,采集不到数据了
source_labels: ["job"]
基于文件的服务发现
原始配置:
[root@redhat /usr/local/prometheus]# cat prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
scrape_configs:
- job_name: 'prometheus'
修改配置文件,通过文件服务发现监控主机
[root@redhat /usr/local/prometheus]# cat prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
scrape_configs:
- job_name: 'prometheus'
file_sd_configs:
- files: ['/usr/local/prometheus/files_sd_configs/*.yaml'] ##指定服务发现文件位置
refresh_interval: 5s ##刷新间隔改为5秒
在指定目录编写需要监控的文件
[root@redhat /usr/local/prometheus/files_sd_configs]# cat configs.yml
- targets: ['localhost:9090']
labels:
name: ttt123
PromSQL

查询标签,以node 开头的element 都是node_expores 采集的。
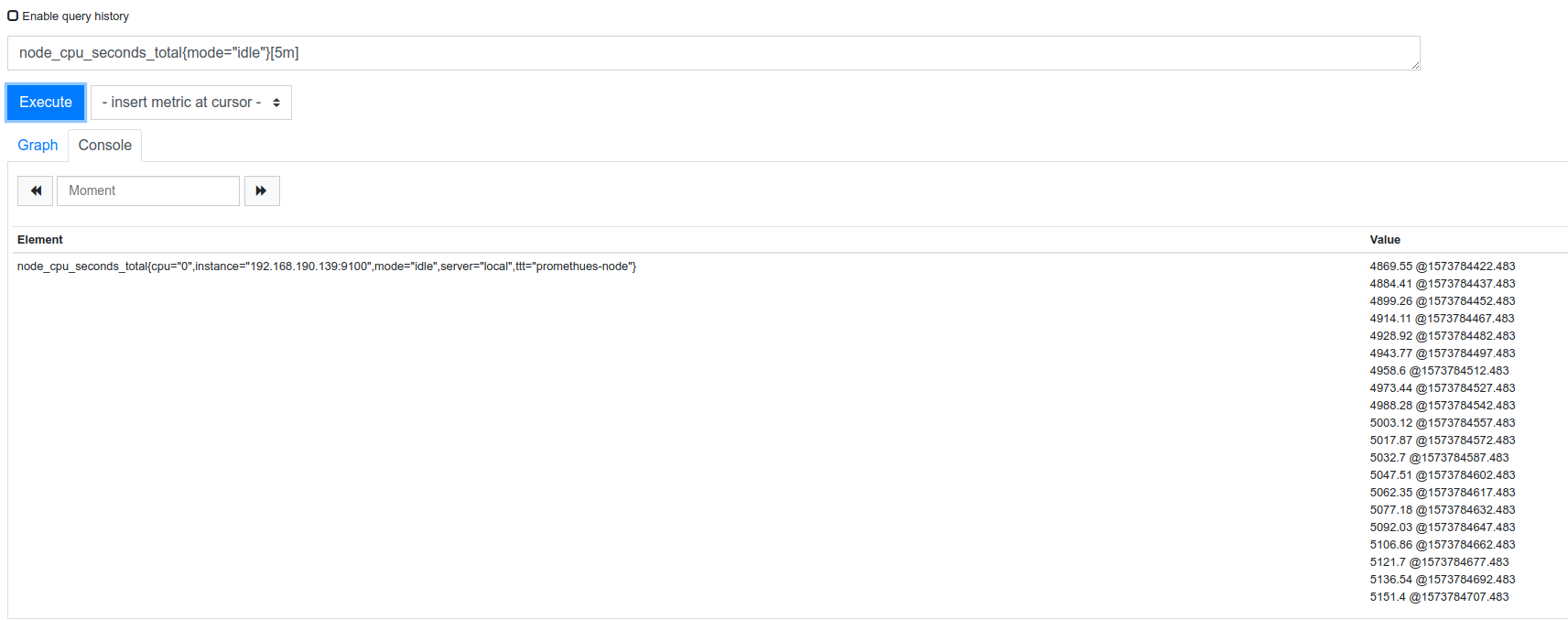
node节点5M中cpu的平均使用率
1,
node_cpu_seconds_total{mode="idle"}[5m]
节点5分钟内空闲的cpu 采集来的数据
2,统计平均值irate 函数
irate(node_cpu_seconds_total{mode="idle"}[5m])*100
5分钟内所有节点cpu的平均空闲率

3,100 - irate(node_cpu_seconds_total{mode="idle"}[5m])*100
内存使用率
100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes *100
硬盘使用率
查看收集到的信息
node_filesystem_files

100- (node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{mountpoint="/",fstype=~"ext4|xfs"} *100)
node_filesystem_size_bytes 查的是 / 总大小,node_filesystem_free_bytes 查的是剩余大小,只匹配 ext4&xfs 类型的
查询标签
node_filesystem_size_bytes{mountpoint='/'}

查询系统服务运行状态
监控以 systemctl 启动的服务
在节点配置启动参数,支持该功能
cat /etc/systemd/system/node-exporter.service
[Unit]
Description=Prometheus Node Exporter
After=network.target
[Service]
ExecStart=/usr/local/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(prometheus|sshd).service
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl restart node_exporter.service
查询
node_systemd_unit_state
node_systemd_unit_state{name=~"(prometheus|sshd).service"}
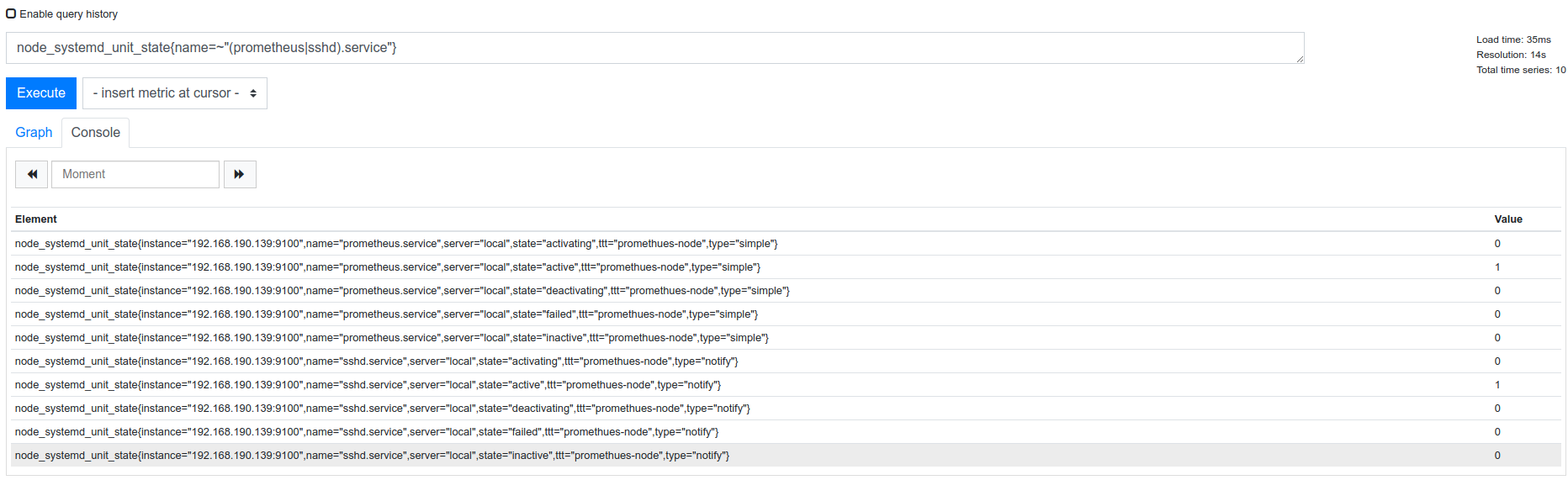
state=active 的值为 0,说明正常运行 ,写告警规则去判断这个值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号