11.二叉树
二叉树的概念
如果树中每个节点最多只能有两个字节点,这样的树就成为“二叉树”
前面,我们已经提过二叉树的重要性,不仅仅是因为简单,也因为几乎上所有的树都可以表示成二叉树的形式
二叉树的定义
二叉树可以为空,也就是没有节点
若不为空,则它是由根节点和称为其左子树TL和右子树TR的两个不相交的二叉树组成
二叉树的五种形态:

二叉树的特性
二叉树有几个比较重要的特性,在笔试题中比较常见:
一个二叉树第i层的最大节点数为:2^(i-1),i >= 1
深度为k的二叉树有最大节点总数为:2^k -1,k >= 1
对任何非空二叉树T,若n0表示叶节点的个数、n2是度为2的非叶节点个数,那么两者满足关系n0 = n2 + 1

完美二叉树
完美二叉树(Perfect Binary Tree),也成为满二叉树(Full Binary Tree)
在二叉树中,除了最下一层的叶节点外,每层节点都有2个字节点,就构成了满二叉树

完全二叉树
完全二叉树(Complete Binary Tree)
除二叉树最后一层外,其他各层的节点数都达到最大个数
且最后一层从左到右的叶节点连续存在,只缺右侧若干节点
完美二叉树是特殊的完全二叉树
下面不是完全二叉树,因为D节点还没有右节点,但是E节点就有了左右节点
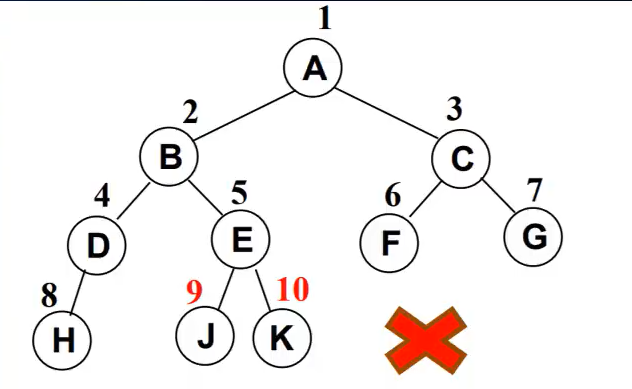
二叉树的存储
二叉树的存储常见的方式是数组和链表
使用数组
完全二叉树:按从上至下、从左到右顺序存储

非完全二叉树:
非完全二叉树要转成完全二叉树才可以按照上面的方案存储
但是会造成很大的空间浪费

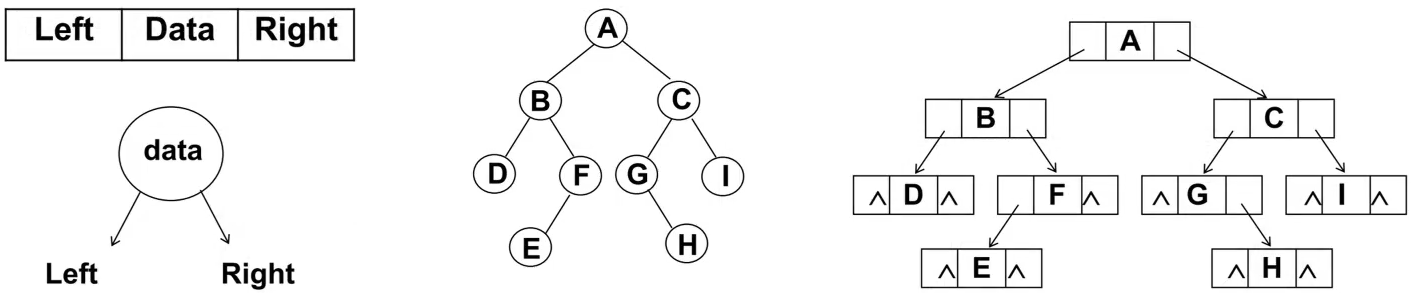
链表存储
二叉树最常见的方式还是使用链表存储
每个节点封装成一个Node,Node中包含存储的数据,左节点的引用,右节点的引用
什么是二叉搜索数?
二叉搜索树(BST,Binary Search Tree),也称二叉排序树或二叉查找树
二叉搜索树是一颗二叉树,可以为空;
如果不为空,满足以下性质:
非空左子树的所有键值小于其根节点的键值
非空右子树的所有键值大于其根节点的键值
左、右子树本身也都是二叉搜索树。
下面那些事二叉搜索树,那些不是?
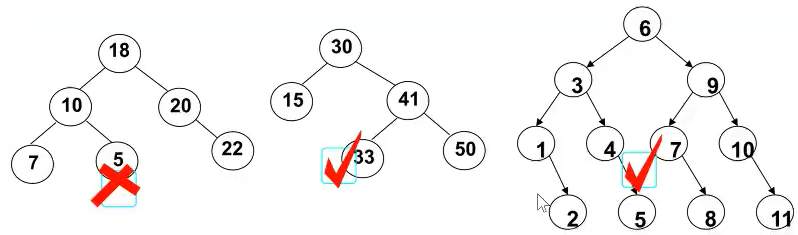
二叉搜索树的特点:
二叉搜索树的特点就是相对较小的值总是保存在左节点上,相对较大的值总是保存在右节点上。
那么利用这个特点,我们可以做什么事情呢?
查找效率非常高,这也是二叉搜索树中,搜索的来源
二叉搜索树
下面是一个二叉搜索树
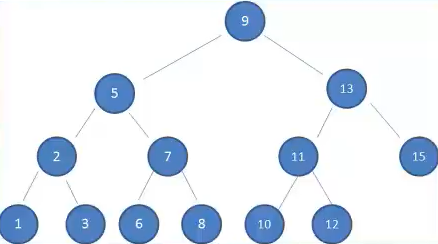
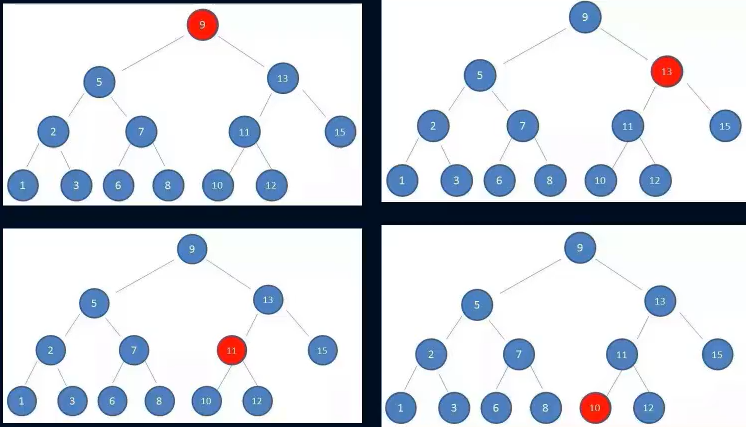
这样的数据结构有什么好处呢?
我们试着查找一下值为10的节点
这种方式就是二分查找的思想
查找所需的最大次数等于二叉搜索树的深度
插入节点时,也利用类似的方法,一层层比较大小,找到新节点合适的位置
二叉搜索树的封装
我们像封装其他数据结构一样,先来封装一个BinarySearchTree的累
<script>
// 封装二叉搜索树
function BinarySerachTree() {
function Node(key) {
this.key = key
this.left = null
this.right = null
}
// 属性
this.root = null
// 方法
}
</script>
代码解析:
封装BinarySearchTree的构造函数
还需要封装一个用于保存每一个节点的类Node
该类包含三个属性:节点对应的key,指向的左子树,指向的右子树
对于BinarySearchTree来说,只需要保存根节点即可,因为其他节点都可以通过根节点找到
二叉搜索树常见操作
二叉搜索树有那些常见的操作呢?
insert(key):向书中插入一个新的值
search(key):在树种查找一个键,如果节点存在,则返回true;如果不存在,则返回false
inOrderTraverse:通过中序遍历方式遍历所有节点
preOrderTraverse:通过先序遍历方式遍历所有节点
postOrderTraverse:通过后序遍历方式遍历所有节点
min:返回树中最小的值/键
max:返回树中最大的值/键
remove(key):从树中移除某个键
向树中插入数据
我们分两个部分来完成这个功能。
首先,外界调用的insert方法:
// 插入数据:对外给用户调用的方法
BinarySerachTree.prototype.insert = function(key) {
// 根据key创建节点
var newNode = new Node(key)
// 判断根节点是否有值
if (this.root == null) {
this.root = newNode
} else {
this.insertNode(this.root, newNode)
}
}
// 第一次:node -> 9 newNode -> 14
// 第二次:node -> 13 newNode -> 14
// 第三次:node -> 15 newNode -> 14
BinarySerachTree.prototype.insertNode = function(node, newNode) {
if (newNode.key < node.key) { // 向左查找
if (node.left == null) {
node.left = newNode
} else {
this.insertNode(node.left, newNode)
}
} else { //向右查找
if (node.right == null) {
node.right = newNode
} else {
this.insertNode(node.right, newNode)
}
}
}
代码解析:
首先,根据插入的key,创建对应的Node
其次,向树种插入数据需要分成两种情况:
第一次插入,直接修改根节点即可
其他次插入,需要进行相关的比较决定插入的位置
在代码中的insertNode方法,我们还没有实现,也是我们接下来要完成的任务。
遍历二叉搜索树
前面,我们向树中插入了很多的数据,为了能很多的看到测试结果,我们先来学习一下树的遍历
注意:这里我们学习的树的遍历,针对所有的二叉树都是适用的,不仅仅是二叉搜索树‘
树的遍历:
遍历一棵树是指访问数的每个节点(也可以对每个节点进行某些操作,我们这里就是简单的打印)
但是树和线性结构不大一样,线性结构我们通常按照从前到后的顺序遍历,但是树呢?
应该从树的顶端还是底端开始呢?从左开始还是从右开始呢?
二叉树的遍历常见的有三种方式:
先序遍历 中序遍历 后续遍历
(还有程序遍历,使用较少,可以使用队列来完成,此处不再给出实现)
先序遍历
// 先序遍历
BinarySerachTree.prototype.preOrderTraversal = function(handler) {
this.preOrderTraversalNode(this.root, handler)
}
// 第一次:node -> 11
// 第二次:node -> 7
// 第三次:node -> 5
// 第四次:node -> 3
BinarySerachTree.prototype.preOrderTraversalNode = function(node, handler) {
if (node != null) {
// 处理经过的节点
alert(node.key)
// 处理经过的节点的左子节点
this.preOrderTraversalNode(node.left, handler)
// 处理经过的节点的右子节点
this.preOrderTraversalNode(node.right, handler)
}
}
// 测试遍历
var resultString = ""
bst.preOrderTraversal(function(key) {
resultString += key + " "
})
console.log(resultString)
遍历过程为:
访问根节点
先序遍历其左子树
先序遍历其右子树
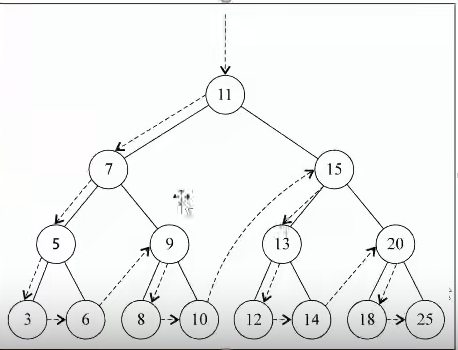

中序遍历
// 中序遍历
BinarySerachTree.prototype.minOrderTraversal = function(handler) {
this.minOrderTraversalNode(this.root, handler)
}
BinarySerachTree.prototype.minOrderTraversalNode = function(node, handler) {
if (node != null) {
// 处理经过的节点的左子节点
this.minOrderTraversalNode(node.left, handler)
// 处理经过的节点
handler(node.key)
// 处理经过的节点的右子节点
this.minOrderTraversalNode(node.right, handler)
}
}
// 测试中序遍历
var resultString = ""
bst.minOrderTraversal(function(key) {
resultString += key + " "
})
alert(resultString)
遍历过程为:
中序遍历其左子树
访问根节点
中序遍历其右子树

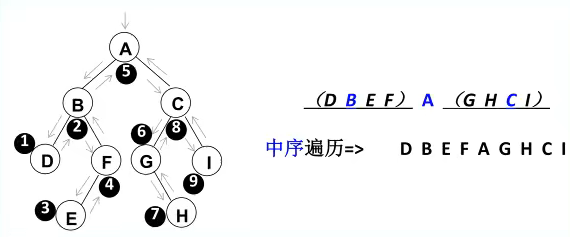
后序遍历
//后序遍历
BinarySerachTree.prototype.postOrderTravesal = function(handler) {
this.postOrderTravesalNode(this.root, handler)
}
BinarySerachTree.prototype.postOrderTravesalNode = function(node, handler) {
if (node != null) {
// 处理经过的节点的左子节点
this.postOrderTravesalNode(node.left, handler)
// 处理经过的节点的右子节点
this.postOrderTravesalNode(node.right, handler)
// 处理经过的节点
handler(node.key)
}
}
// 测试后序遍历
var resultString = ""
bst.postOrderTravesal(function(key) {
resultString += key + " "
})
alert(resultString)
遍历过程为:
后序遍历其左子树
后序遍历其右子树
访问根节点
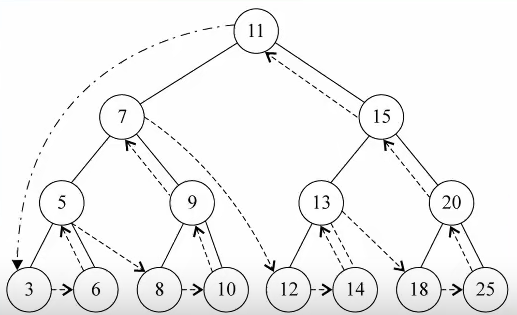

最大值&最小值
// 寻找最值
// 寻找最大值
BinarySerachTree.prototype.max = function() {
// 获取根节点
var node = this.root
// 依次向右不断的查找,直到节点为null
var key = null
while (node != null) {
key = node.key
node = node.right
}
return key
}
// 寻找最小值
BinarySerachTree.prototype.min = function() {
// 获取根节点
var node = this.root
// 依次向左不断的查找,直到节点为null
var key = null
while (node != null) {
key = node.key
node = node.left
}
return key
}
// 测试最值
console.log(bst.max())
console.log(bst.min())
在二叉搜索树中搜索最值是一件非常简单的事情,其实用眼睛看就可以看出来了

搜索特定的值
// 搜索某一个key
BinarySerachTree.prototype.search = function(key) {
// 获取根节点
var node = this.root
// 循环搜索key
while (node != null) {
if (key < node.key) {
node = node.left
} else if (key > node.key) {
node = node.right
} else {
return true
}
}
return false
}
// 测试搜索方法
console.log(bst.search(25))
console.log(bst.search(24))
console.log(bst.search(2))
二叉搜索树不仅仅获取最值效率非常高,搜索特定的值效率也非常高
代码解析:
这里我们还是使用了递归的方式,待会儿我们来写一个非递归的实现。
递归必须有退出条件,我们这里是两种情况下退出
node === null,也就是后面不再有节点的时候
找到对应的key,也就是node.key === key的时候
在其他情况下,根据node.的key和传入的key进行比较来决定向左还是向右查找
如果node.key > key,那么说明传入的值更小,需要向左查找
如果node.key < key,那么说明传入的值更大,需要向右查找
二叉搜索树的删除
二叉搜索树的删除有些复杂,我们一点点完成
删除节点要从查找要删的节点开始,找到节点后,需要考虑三种情况:
该节点是叶节点(没有子节点,比较简单)
该节点有一个子节点(也相对简单)
该节点有两个子节点(情况比较复杂,我们后面慢慢道来)
我们先从查找要删除的节点入手
先找到要删除的节点,如果没有找到,不需要山东出
找到要删除的几点
删除叶子节点
删除只有一个子节点的节点
删除有两个子节点的节点
情况一:没有子节点
// 删除的节点是叶子节点(没有子节点)
if (current.left == null && current.right == null) {
if (current == this.root) {
this.root = null
} else if (isLeftChild) {
parent.left = null
} else {
parent.right = null
}
}
情况一:没有子节点
这种情况相对比较简单,我们需要检测current的left以及right是否都为null
都为null之后还要检测一个东西,就是是否current就是根,都为null,并且为跟根,那么相当于要清空二叉树
(当然,只是清空了根,因为只有它)
否则就把父节点的left或者right字段设置为null即可
如果只有一个单独的根,直接删除即可
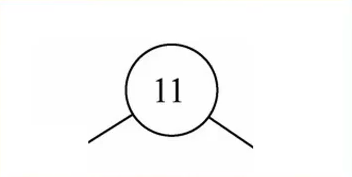
如果是叶节点,那么处理方式如下:

情况二:一个子节点
// 删除的节点有一个子节点
else if (current.right == null) {
if (current == this.root) {
this.root = current.left
} else if (isLeftChild) {
parent.left = current.left
} else {
parent.right = current.left
}
} else if (current.left = null) {
if (current == this.root) {
this.root = current.right
} else if (isLeftChild) {
parent.left = current.right
} else {
parent.right = current.right
}
}
情况二:有一个子节点
这种情况也不是很难
要删除的current节点,直有2个连接(如果有两个子节点,就是三个连接了),
一个连接父节点,一个连接唯一的子节点
需要从这三者之间:爷爷-自己-儿子,将自己(current)剪短,让爷爷直接连接儿子即可
这个过程要求改变父节点的left或者right,指向要删除节点的子节点
当然,在这个过程中还要考虑是否current就是根
图解过程:
如果是根的情况,大家可以自家画一下,比较简单,这里不再给出
如果不是根,并且只有一个子节点的情况

情况三:两个子节点
// 删除的节点有两个子节点
else {
// 获取后续节点
var successor = this.getSussessor(current)
// 判断是否根节点
if (current == this.root) {
this.root = successor
} else if (isLeftChild) {
parent.left = successor
} else {
parent.right = successor
}
// 将删除节点的左子树 = current.left
successor.left = current.left
}
情况三:有两个子节点
事情变得非常复杂,也非常有趣了
我们先来思考一下我提出得一些问题

删除操作总结
看到这里,你就会发现删除节点相当棘手
实际上,因为它非常复杂,一些程序员都尝试着避开删除操作
他们的做法是在Node类中添加一个boolean的字段,比如名称为isDeleted
要删除一个节点时,即将此字段设置为true
其他操作,比如find()在查找之前先判断这个节点是不是标记为删除
这样相对比较简单,每次删除节点不会改变原有的树结构
但是在二叉树的储存中,还保留着那些本该已经被删除掉的节点
上面的做法看起来很聪明,其实是一种逃避
这样会造成很大空间的浪费,特别时针对数据量较大的情况
而且,作为程序员要学会通过这些复杂的操作,锻炼自己的逻辑
二叉搜索树完整代码:
<script>
// 封装二叉搜索树
function BinarySerachTree() {
function Node(key) {
this.key = key
this.left = null
this.right = null
}
// 属性
this.root = null
// 方法
// 插入数据:对外给用户调用的方法
BinarySerachTree.prototype.insert = function(key) {
// 根据key创建节点
var newNode = new Node(key)
// 判断根节点是否有值
if (this.root == null) {
this.root = newNode
} else {
this.insertNode(this.root, newNode)
}
}
// 第一次:node -> 9 newNode -> 14
// 第二次:node -> 13 newNode -> 14
// 第三次:node -> 15 newNode -> 14
BinarySerachTree.prototype.insertNode = function(node, newNode) {
if (newNode.key < node.key) { // 向左查找
if (node.left == null) {
node.left = newNode
} else {
this.insertNode(node.left, newNode)
}
} else { //向右查找
if (node.right == null) {
node.right = newNode
} else {
this.insertNode(node.right, newNode)
}
}
}
// 树的遍历
// 先序遍历
BinarySerachTree.prototype.preOrderTraversal = function(handler) {
this.preOrderTraversalNode(this.root, handler)
}
// 第一次:node -> 11
// 第二次:node -> 7
// 第三次:node -> 5
// 第四次:node -> 3
BinarySerachTree.prototype.preOrderTraversalNode = function(node, handler) {
if (node != null) {
// 处理经过的节点
alert(node.key)
// 处理经过的节点的左子节点
this.preOrderTraversalNode(node.left, handler)
// 处理经过的节点的右子节点
this.preOrderTraversalNode(node.right, handler)
}
}
// 中序遍历
BinarySerachTree.prototype.minOrderTraversal = function(handler) {
this.minOrderTraversalNode(this.root, handler)
}
BinarySerachTree.prototype.minOrderTraversalNode = function(node, handler) {
if (node != null) {
// 处理经过的节点的左子节点
this.minOrderTraversalNode(node.left, handler)
// 处理经过的节点
handler(node.key)
// 处理经过的节点的右子节点
this.minOrderTraversalNode(node.right, handler)
}
}
//后序遍历
BinarySerachTree.prototype.postOrderTravesal = function(handler) {
this.postOrderTravesalNode(this.root, handler)
}
BinarySerachTree.prototype.postOrderTravesalNode = function(node, handler) {
if (node != null) {
// 处理经过的节点的左子节点
this.postOrderTravesalNode(node.left, handler)
// 处理经过的节点的右子节点
this.postOrderTravesalNode(node.right, handler)
// 处理经过的节点
handler(node.key)
}
}
// 寻找最值
// 寻找最大值
BinarySerachTree.prototype.max = function() {
// 获取根节点
var node = this.root
// 依次向右不断的查找,直到节点为null
var key = null
while (node != null) {
key = node.key
node = node.right
}
return key
}
// 寻找最小值
BinarySerachTree.prototype.min = function() {
// 获取根节点
var node = this.root
// 依次向左不断的查找,直到节点为null
var key = null
while (node != null) {
key = node.key
node = node.left
}
return key
}
// 搜索某一个key
BinarySerachTree.prototype.search = function(key) {
// 获取根节点
var node = this.root
// 循环搜索key
while (node != null) {
if (key < node.key) {
node = node.left
} else if (key > node.key) {
node = node.right
} else {
return true
}
}
return false
}
// 删除节点
BinarySerachTree.prototype.remove = function(key) {
// 寻找要删除的节点
// 定义变量,保存一些信息
var current = this.root
var parent = null
var isLeftChild = true
// 开始寻找删除的节点
while (current.key != key) {
parent = current
if (key < current.key) {
isLeftChild = true
current = current.left
} else {
isLeftChild = false
current = current.right
}
// 某种情况:已经找到了最后的节点,依然没有找到==key
if (current == null) return false
}
// 根据对应的情况删除节点
// 找到了current.key == key
// 删除的节点是叶子节点(没有子节点)
if (current.left == null && current.right == null) {
if (current == this.root) {
this.root = null
} else if (isLeftChild) {
parent.left = null
} else {
parent.right = null
}
}
// 删除的节点有一个子节点
else if (current.right == null) {
if (current == this.root) {
this.root = current.left
} else if (isLeftChild) {
parent.left = current.left
} else {
parent.right = current.left
}
} else if (current.left = null) {
if (current == this.root) {
this.root = current.right
} else if (isLeftChild) {
parent.left = current.right
} else {
parent.right = current.right
}
}
// 删除的节点有两个子节点
else {
// 获取后续节点
var successor = this.getSussessor(current)
// 判断是否根节点
if (current == this.root) {
this.root = successor
} else if (isLeftChild) {
parent.left = successor
} else {
parent.right = successor
}
// 将删除节点的左子树 = current.left
successor.left = current.left
}
}
// 找后续的方法
BinarySerachTree.prototype.getSussessor = function(delNode) {
// 定义变量,保存找到的后续
var successor = delNode
var current = delNode.right
var successorParent = delNode
// 循环查找
while (current != null) {
successorParent = successor
successor = current
current = current.left
}
// 判断寻找的后续节点是否直接就是delNode的right节点
if (successor != delNode.right) {
successorParent.left = successor.right
successor.right = delNode.right
}
return successor
}
}
// 测试代码
// 创建BinarySearchTree
var bst = new BinarySerachTree()
// 插入数据
bst.insert(11)
bst.insert(7)
bst.insert(15)
bst.insert(5)
bst.insert(3)
bst.insert(9)
bst.insert(8)
bst.insert(10)
bst.insert(13)
bst.insert(12)
bst.insert(14)
bst.insert(20)
bst.insert(18)
bst.insert(25)
bst.insert(6)
// console.log(bst)
// 测试遍历
// 测试先序遍历
var resultString = ""
bst.preOrderTraversal(function(key) {
resultString += key + " "
})
// alert(resultString)
// 测试中序遍历
resultString = ""
bst.minOrderTraversal(function(key) {
resultString += key + " "
})
// alert(resultString)
// 测试后序遍历
resultString = ""
bst.postOrderTravesal(function(key) {
resultString += key + " "
})
// alert(resultString)
// // 测试最值
// console.log(bst.max())
// console.log(bst.min())
// // 测试搜索方法
// console.log(bst.search(25))
// console.log(bst.search(24))
// console.log(bst.search(2))
// 测试删除代码
bst.remove(9)
bst.remove(7)
bst.remove(15)
resultString = ""
bst.postOrderTravesal(function(key) {
resultString += key + " "
})
alert(resultString)
</script>
二叉搜索树的缺陷
二叉搜索树作为数据存储的结构由重要的优势:
可以快速的找到给定关键字的数据项 并且可以快速地插入和删除数据项
但是,二叉搜索树有一个很麻烦的问题:
如果插入的数据时有序的数据,比如下面的情况
有一棵初始化为 9 8 12 的二叉树
插入下面的数据:7 6 5 4 3
非平衡树
比较好的二叉搜索树数据应该是左右分布均匀的
但是插入连续数据后,分布的不均匀,我称这种树为非平衡树
对于一棵平衡二叉树来说,插入/查找等操作的效率时O(logN)
对于以可非平衡二叉树,相当于编写了一个链表,查找效率变成了O(N)
树的平衡性
为了能以较快的时间O(logN)来操作一棵树,我们需要保证树总是平衡的:
至少大部分是平衡的,那么时间复杂度也是接近O(logN)的
也就是说树中每个节点左边的子孙节点的个数,应该尽可能的等于右边的子孙节点的个数
常见的平衡树有哪些呢?
AVL树:
AVL树是最早的一种平衡树,它有些办法保持树的平衡(每个节点多存储了一个额外的数据)
因为AVL树是平衡的,所以时间复杂度也是O(logN)
但是,每次插入/删除操作相对于红黑树效率不高,所以整体效率不如红黑树
红黑树:
红黑树也通过一些特性来保持树的平衡
因为是平衡树,所以时间复杂度也是在O(logN)
另外插入/删除等操作,红黑树的性能要优于AVL树,所以现在平衡树的应用基本都是红黑树

 浙公网安备 33010602011771号
浙公网安备 33010602011771号