

pig安装配置及实例
一、前提
1、 hadoop集群环境配置好(本人hadoop版本:hadoop-2.7.3)
2、 windows基础环境准备:
jdk环境配置、esclipse环境配置
二、搭建pig环境
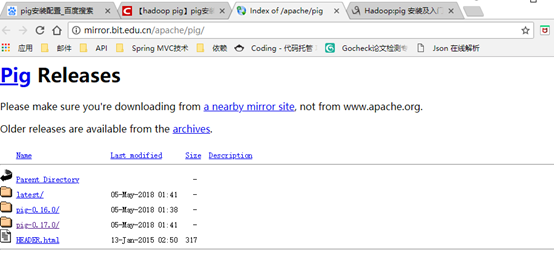
1、下载pig:
在Apache下载最新的Pig软件包,点击下载会推荐最快的镜像站点,以下为下载地址:http://mirror.bit.edu.cn/apache/pig/
2、上传pig(我的是上传到/opt/bigdata下面)
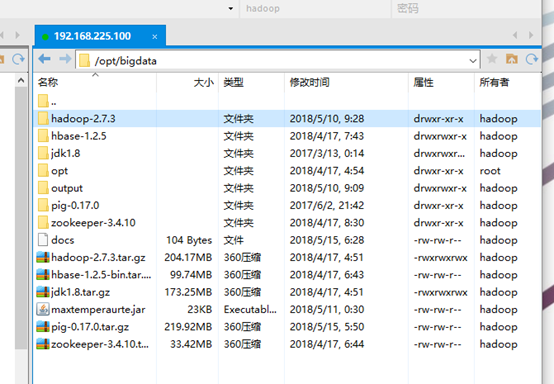
3、解压缩
[hadoop@wangmaster sbin]$ cd /opt/bigdata/ [hadoop@wangmaster bigdata]$ ls docs hadoop-2.7.3.tar.gz hbase-1.2.5-bin.tar.gz jdk1.8.tar.gz opt pig-0.17.0 zookeeper-3.4.10 hadoop-2.7.3 hbase-1.2.5 jdk1.8 maxtemperaurte.jar output pig-0.17.0.tar.gz zookeeper-3.4.10.tar.gz
[hadoop@wangmaster bigdata]$ tar -xzvf pig-0.17.0
4、设置环境变量
sudo vi /etc/profile ##设置pig的class路径和在path加入pig的路径,其中PIG_CLASSPATH参数是设置pig在MapReduce工作模式: export PIG_HOME=/opt/bigdata/pig-0.17.0 export PATH=$PATH: /opt/bigdata/hadoop-2.7.3/bin:$PIG_HOME/bin ##确认生效 source /etc/profile
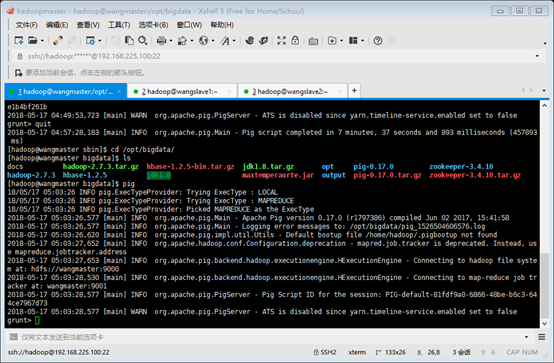
5、验证安装完成
重新登录终端,确保hadoop集群启动,键入pig命令,应该能看到pig连接到hadoop集群的信息并且进入了grunt shell命令行模式:
如果需要退出的话,在pig的grunt shell下键入quit即可。
三、实例
如果在启动hadoop集群时候start-all.sh里面没有包含mapreduce.jobhistory.address这一项?那么进行手动启动。
./mr-jobhistory-daemon.sh start historyserver (在hadoop路径下sbin下执行)
实例要求:这里我们给出一个学生表(学号,姓名,性别,年龄,所在系),其中含有如下几条记录并保存在/opt/bigdata/ziliao/student.txt文件:
201000101:Lihua:men:20:CST 201000102:Wangli:women:19:CST 201000103:Xiangming:women:18:CAT 201000104:Lixiao:men:19:CST 201000105:Wuda:women:19:CA 201000106:Huake:men:21:CST 201000107:Beihang:men:20:CA 201000108:Bob:women:17:CAT 201000109:Smith:men:19:CAT 201000110:Gxl:men:19:CST 201000111:Songwei:women:19:CA 201000112:Weihua:men:21:CAT 201000113:Weilei:women:18:CA 201000114:Luozheng:men:19:CA 201000115:Shangsi:women:20:CAT 201000116:Fandong:men:19:CST 201000117:Laosh:women:22:CAT 201000118:Haha:men:19:CA
它们所对应的数据类型如下所示:
Student(sno:chararray, sname:chararray, ssex:chararray, sage:int,
sdept:chararray)
我们将在不同的运行方式下取出各个学生的姓名和年龄两个字段,执行结果如下:
(Lihua,20) (Wangli,19) (Xiangming,18) (Lixiao,19) (Wuda,19) (Huake,21) (Beihang,20) (Bob,17) (Smith,19) (Gxl,19) (Songwei,19) (Weihua,21) (Weilei,18) (Luozheng,19) (Shangsi,20) (Fandong,19) (Laosh,22) (Haha,19)
1、local模式
进入grunt shell模式
[hadoop@wangmaster sbin]$ pig -x local
--加载数据(注意“=”左右两边要空格) grunt> A = load '/opt/bigdata/ziliao/student.txt' using PigStorage(':') as (sno:chararray, sname:chararray, ssex:chararray, sage:int, sdept:chararray); --从A中选出Student相应的字段(注意“=”左右两边要空格) grunt> B = foreach A generate sname, sage; --将B中的内容输出到屏幕上 grunt> dump B;
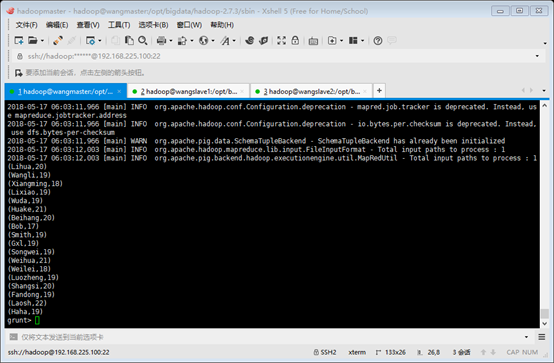
--将B的内容输出到本地文件中 grunt> store B into '/opt/bigdata/ziliao/result.txt'; --查看本地文件内容,没有'' grunt> cat /opt/bigdata/ziliao/result.txt;
(上面另一种执行方式—脚本文件)将下面语句存储到script.pig中(script.pig文件内容如下)
A = load '/opt/bigdata/ziliao/student.txt' using PigStorage(':') as (sno:chararray, sname:chararray, ssex:chararray, sage:int, sdept:chararray); B = foreach A generate sname, sage; dump B; store B into '/opt/bigdata/ziliao/result1.txt';
执行pig -x local script.pig命令
查看结果:grunt> cat /opt/bigdata/ziliao/result.txt;
2、 MapReduce模式
首先将/opt/bigdata/ziliao/student.txt放到hadoop的in目录下 hadoop dfs -put /opt/bigdata/ziliao/student.txt /in 输入pig,进入shell编辑模式下 grunt> ls /in hdfs://wangmaster:9000/docs<r 3> 104 hdfs://wangmaster:9000/hbase <dir> hdfs://wangmaster:9000/input <dir> hdfs://wangmaster:9000/output <dir> hdfs://wangmaster:9000/student.txt<r 3> 525 hdfs://wangmaster:9000/tmp <dir> hdfs://wangmaster:9000/wang <dir>
然后对其进行操作
输入目录变为hdfs://wangmaster:9000/in/student.txt
输出目录变为hdfs://wangmaster:9000/in/result.txt
(注意:脚本也是如此)。
A = load 'hdfs://wangmaster:9000/student.txt' using PigStorage(':') as (sno:chararray, sname:chararray, ssex:chararray, sage:int, sdept:chararray); B = foreach A generate sname, sage; dump B; store B into 'hdfs://wangmaster:9000/result0.txt' cat hdfs://wangmaster:9000/result0.txt;
第二例:求每个专业的最大的年龄人的相关信息:(数据还是上面的)
执行(在shell里面执行):
A = load '/opt/bigdata/ziliao/student.txt' using PigStorage(':') as (sno:chararray, sname:chararray, ssex:chararray, sage:int, sdept:chararray); B = group A by sdept; dump B; max_age = foreach B generate group,MAX(A.sage); dump = max_age; 输出结果: (CA,20) (CAT,22) (CST,21)
查找目标信息 CA = filter A by sdept == 'CA' and sage == 20; (CA专业的最大年龄人的信息) CAT0 = filter A by sdept == 'CAT' and sage == 22; (不可用标识词)(CAT专业的最大年龄人的信息) CST = filter A by sdept == 'CST' and sage == 21; (CST专业的最大年龄人的信息)

