2023数据采集与融合技术实践作业三
作业①
实验要求
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息:
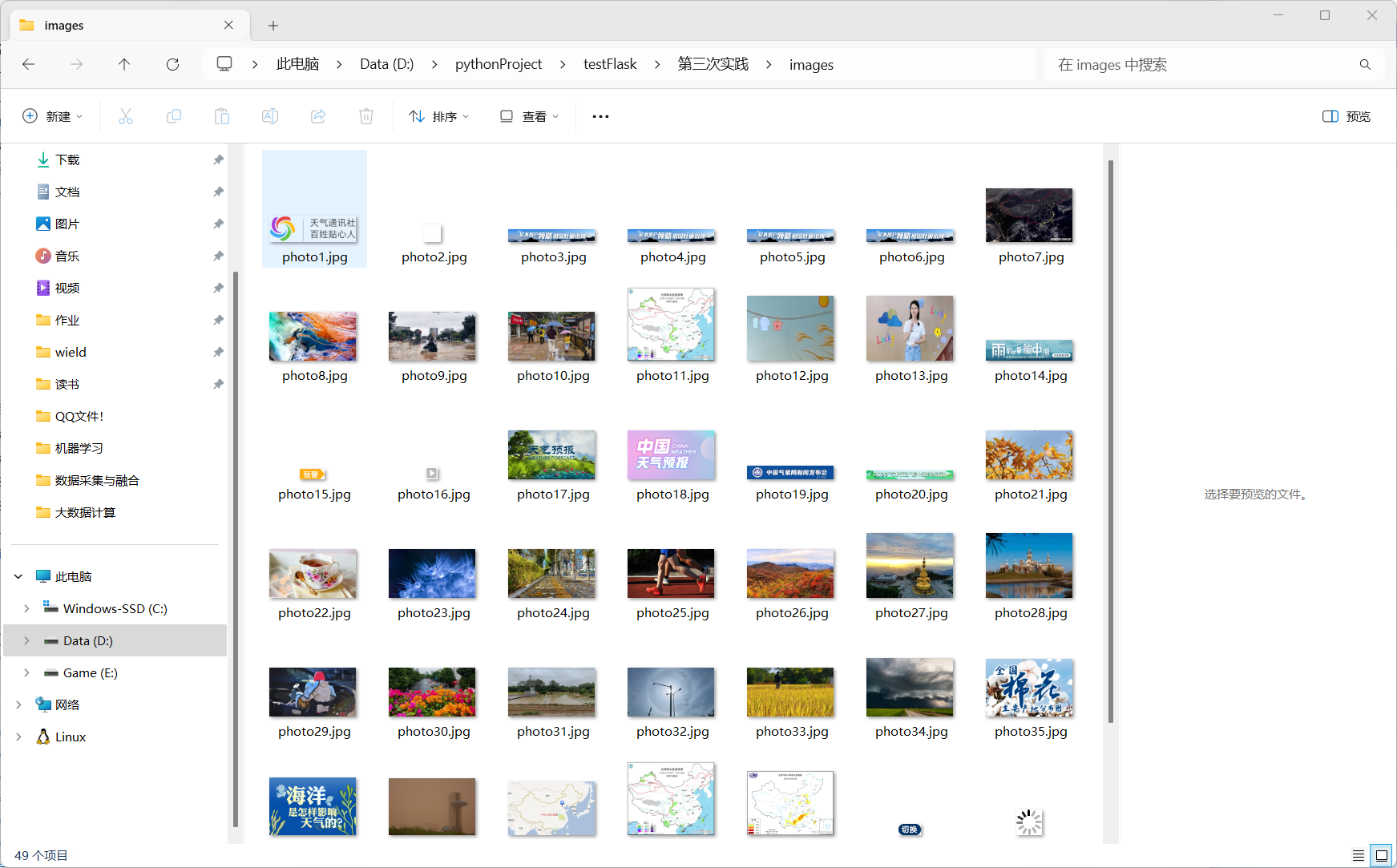
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
代码(单线程)
Gitee文件夹链接
这是MySpider.py文件,用于爬取到所需要的图片url地址,并将它们的信息在控制台输出。
import scrapy
from testFlask.第三次实践.shiyan3_1_1.shiyan3_1_1.items import ImgItem
class MySpider(scrapy.Spider):
name = 'mySpider'
def start_requests(self):
url = 'http://www.weather.com.cn/'
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
try:
data = response.body.decode()
selector = scrapy.Selector(text=data)
imgs = selector.xpath("//img//@src")
for img in imgs:
item = ImgItem()
# img = img.xpath("./@src")
item["img"] = img.extract()
print(item["img"])
yield item
except Exception as err:
print(err)
这是items.py文件,定义了一个img,用来接收img的url。
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ImgItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img = scrapy.Field()
pass
这是pipeline文件,作用是根据得到的图片url地址来下载图片。
import urllib
from itemadapter import ItemAdapter
class ImgPipeline:
count = 0
def process_item(self, item, spider):
ImgPipeline.count += 1
# print(item["img"])
urllib.request.urlretrieve(item["img"],f'D:/pythonProject/testFlask/第三次实践/images/photo{ImgPipeline.count}.jpg')
return item
不要忘记修改setting.py文件.
ITEM_PIPELINES = {
"shiyan3_1_1.pipelines.ImgPipeline": 300,
}
运行结果
控制台输出结果:
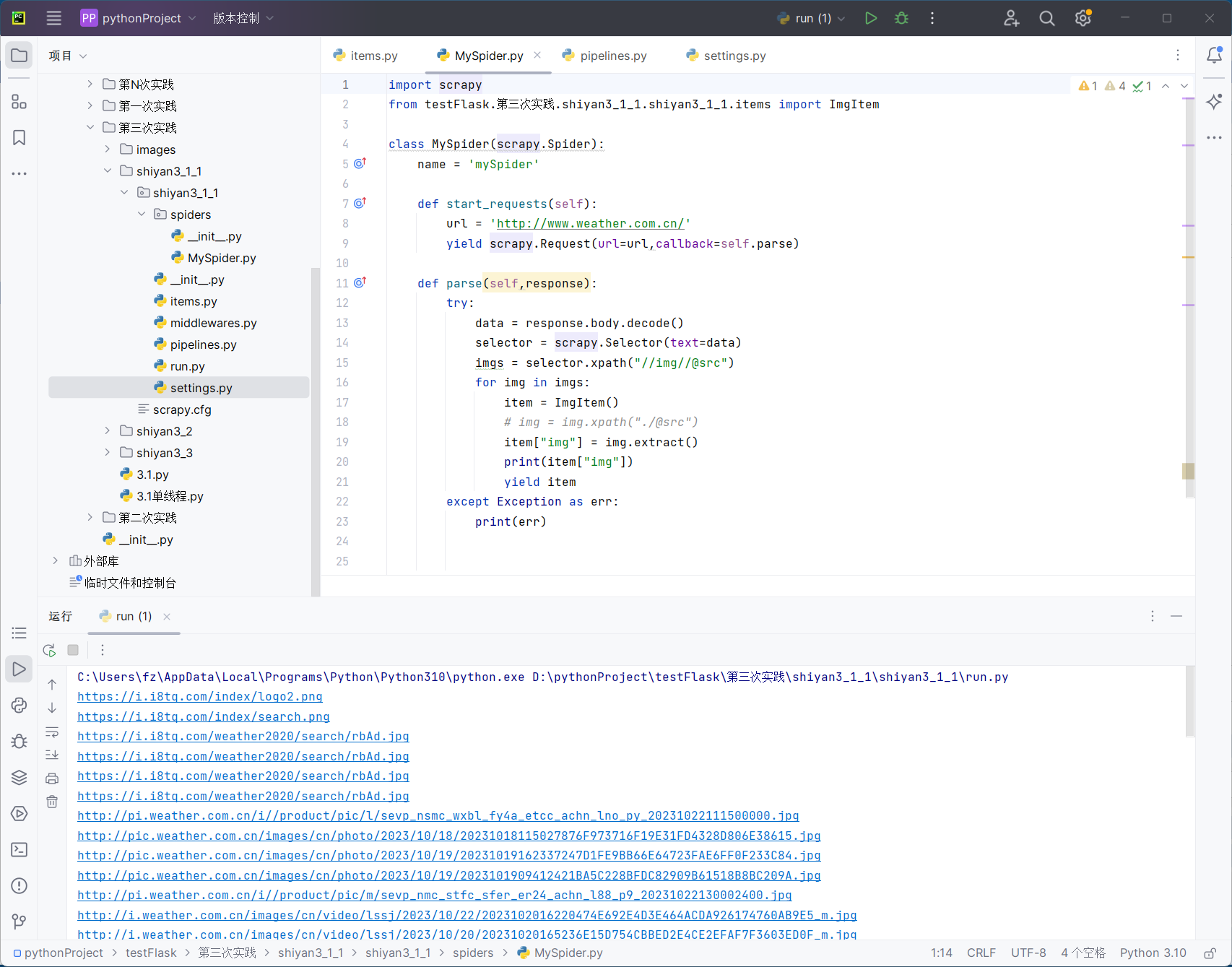
images文件夹结果:
关于多线程
上网查阅知道,在scrapy中设置多线程不需要通过thread,只需要修改setting.py中的CONCURRENT_REQUESTS的值即可,我修改为了32,其余与单线程一样。
心得体会
这个实验难度不是很高,甚至做出来后觉得比之前thread简单,但是上课的时候我不知道这点,所以花了蛮多的无用功。通过这个实验,我学会了使用scrapy来进行爬虫,熟悉了scrapy的大致步骤。
作业②
实验要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:
Gitee文件夹链接
代码
Gitee文件夹链接
这是MySpider.py,主要是获取网页信息
import scrapy
from testFlask.第三次实践.shiyan3_2.shiyan3_2.items import StockItem
import json
class MySpider(scrapy.Spider):
name = 'mySpider'
def start_requests(self):
# url = 'http://www.weather.com.cn/'
url = 'http://42.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124004594853117051989_1697955533168&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697955533169/'
yield scrapy.Request(url,callback=self.parse)
def parse(self,response):
try:
start = response.text.find('(') + 1
end = response.text.find(')')
data = response.text[start:end] # 去除掉前面不要的数据
data = json.loads(data)
datas = data['data']['diff'] # 选择需要的数据
# print(data)
stocks_list = []
fs = ['f12', 'f14', 'f2', 'f3', 'f4', 'f6', 'f7', 'f15', 'f16', 'f17', 'f18'] # 确认顺序
# 将数据存入二维数组中
i = 0
for data in datas:
i += 1
stockn = []
stockn.append(i)
for f in fs:
stockn.append(data[f])
stocks_list.append(stockn)
# print(list)
# print(stocks_list)
for stock in stocks_list:
# print(stock)
item = StockItem()
item["stockId"] = str(stock[0])
print(item["stockId"])
item["stockCode"] = str(stock[1])
item["stockName"] = str(stock[2])
item["latestPrice"] = str(stock[3])
item["changePercent"] = str(stock[4])
item["changeAmount"] = str(stock[5])
item["tradingVolume"] = str(stock[6])
item["amplitude"] = str(stock[7])
item["highest"] = str(stock[8])
item["lowest"] = str(stock[9])
item["todayOpen"] = str(stock[10])
item["yesterdayClose"] = str(stock[11])
yield item
except Exception as err:
print(err)
这是items.py,定义了本题所需要的一些信息。
import scrapy
class StockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
stockId = scrapy.Field()
stockCode = scrapy.Field()
stockName = scrapy.Field()
latestPrice = scrapy.Field()
changePercent = scrapy.Field()
changeAmount = scrapy.Field()
tradingVolume = scrapy.Field()
amplitude = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
todayOpen = scrapy.Field()
yesterdayClose = scrapy.Field()
pass
这是pipeline.py,主要用来连接MySQL,并向其中的表格进行insert操作。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class StockPipeline:
def process_item(self, item, spider):
connection = pymysql.connect(host='localhost',
user='root',
password='123456',
database='crawl')
cursor = connection.cursor()
try:
cursor.execute(
"insert into stocks(stockId, stockCode, stockName, latestPrice, changePercent, changeAmount, tradingVolume, amplitude, highest, lowest, todayOpen, yesterdayClose) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(item["stockId"], item["stockCode"], item["stockName"], item["latestPrice"], item["changePercent"], item["changeAmount"],
item["tradingVolume"], item["amplitude"], item["highest"], item["lowest"], item["todayOpen"], item["yesterdayClose"]))
connection.commit() # 提交更改
connection.close()
except BaseException as err:
print(err)
别忘记修改setting.py
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
"shiyan3_2.pipelines.StockPipeline": 300,
}
运行结果
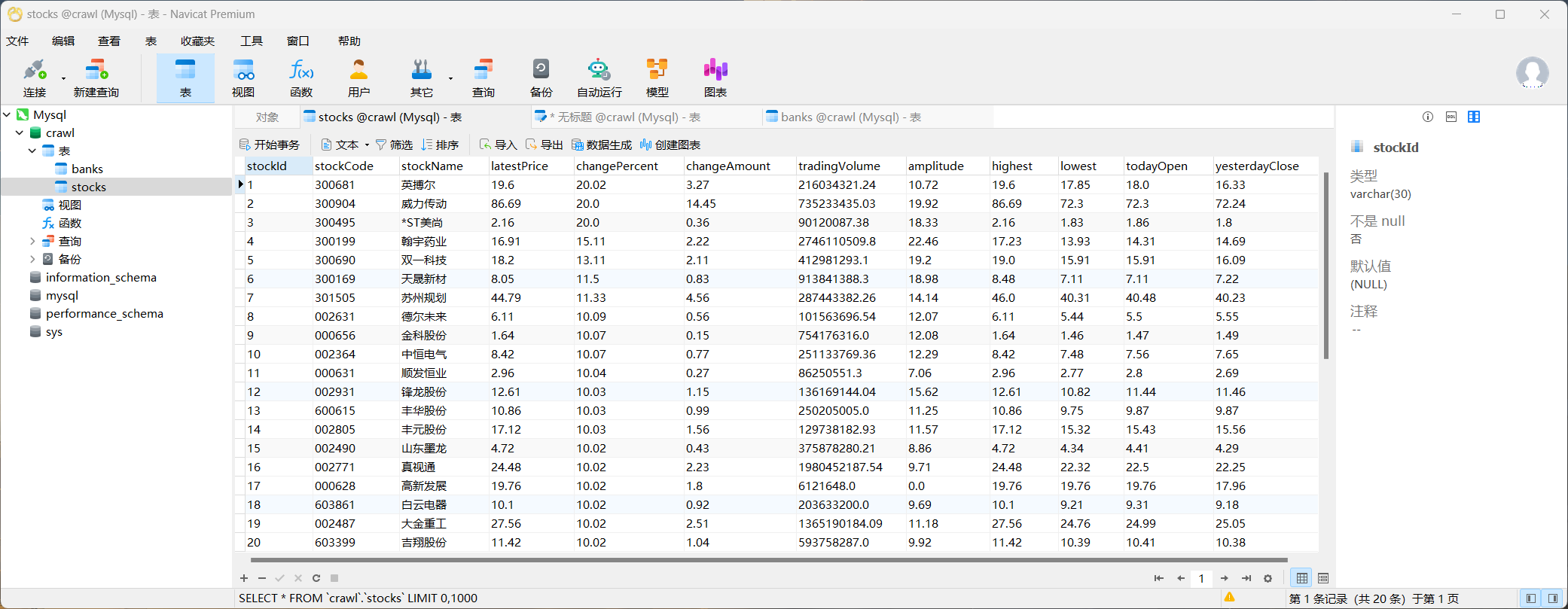
心得体会
通过本次实验,我学习到了一种全新的存储数据库方法。刚开始一直用xpath来提取数据,花了很长时间也没搞出来,最后发现这是动态网页,于是切换json来处理数据,很快就做出来了。
作业③
实验要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
代码
Gitee文件夹链接
这是MySpider.py,主要是获取网页信息
import scrapy
from testFlask.第三次实践.shiyan3_3.shiyan3_3.items import BankItem
import json
class MySpider(scrapy.Spider):
name = 'mySpider'
def start_requests(self):
url = 'https://www.boc.cn/sourcedb/whpj/'
yield scrapy.Request(url,callback=self.parse)
def parse(self,response):
try:
data = response.body.decode()
selector = scrapy.Selector(text=data)
# print(data)
datas = selector.xpath("//body//div//div//div//div//tr[position()>1]") #忽略第一个
for data in datas:
item = BankItem()
item["Currency"] = str(data.xpath("./td[1]//text()").get())
# print(item["Currency"])
item["TBP"] = str(data.xpath("./td[2]//text()").get())
# print(item["TBP"])
item["CBP"] = str(data.xpath("./td[3]//text()").get())
# print(item["CBP"])
item["TSP"] = str(data.xpath("./td[4]//text()").get())
# print(item["TSP"])
item["CSP"] = str(data.xpath("./td[5]//text()").get())
# print(item["CSP"])
item["Time"] = str(data.xpath("./td[8]//text()").get())
# print(item["Time"])
# print(data.extract())
yield item
# print(datas)
except Exception as err:
print(err)
这是items.py,定义了本题所需要的一些信息。
import scrapy
class BankItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
Time = scrapy.Field()
pass
这是pipeline.py,主要用来连接MySQL,并向其中的表格进行insert操作。
import pymysql
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class BankPipeline:
def process_item(self, item, spider):
connection = pymysql.connect(host='localhost',
user='root',
password='123456',
database='crawl')
cursor = connection.cursor()
try:
cursor.execute(
"insert into banks(Currency, TBP, CBP, TSP, CSP, Time) values(%s,%s,%s,%s,%s,%s)",
(item["Currency"], item["TBP"], item["CBP"], item["TSP"], item["CSP"], item["Time"],
))
connection.commit() # 提交更改
connection.close()
except BaseException as err:
print(err)
别忘记修改setting.py
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
"shiyan3_3.pipelines.BankPipeline": 300,
}
运行结果
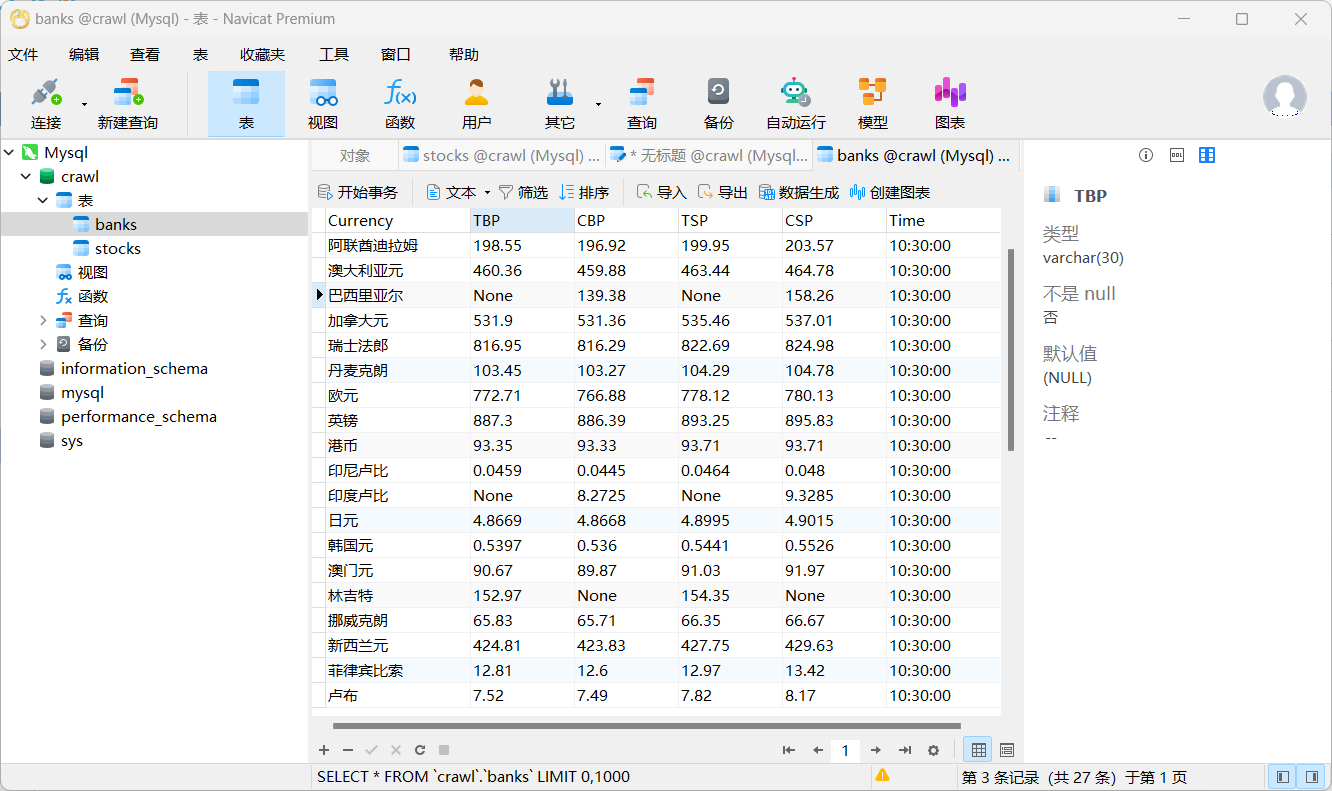
心得体会
这个问题和第二题基本一样,但是这道题可以使用xpath,很快就搞完了。但是中间在写主程序的时候,忘记yield item了,导致很长一段时间程序没有任何结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号