

最近面试题总结10.12
1.java基本数据类型: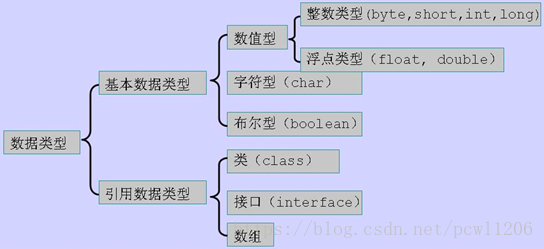
先说明两个词汇的基本概念:
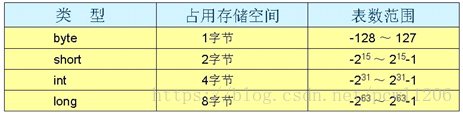
bit (位):位是计算机中存储数据的最小单位,指二进制数中的一个位数,其值为“0”或“1”。
byte (字节):字节是计算机存储容量的基本单位,一个字节由8位二进制数组成。在计算机内部,一个字节可以表示一个数据或者一个英文字母,但是一个汉字需要两个字节表示。
1B=8bit
1Byte=8bit
1KB=1024Byte(字节)=8*1024bit
1MB=1024KB
1GB=1024MB
1TB=1024GB
第二类、浮点数类型
float:单精度类型,32 位,后缀 F 或 f,1 位符号位,8 位指数,23 位有效尾数。
double:64 位,最常用,后缀 D 或 d,1 位符号位,11 位指数,52 位有效尾数。
java浮点型默认为double型,所以要声明一个变量为float型时,需要在数字后面加F或者f:
例如:double d = 88888.8; float f = 88888.8f; //不加f的话会报错
第三类、字符类型
char:16位,java字符使用Unicode编码,
第四类、布尔类型
boolean:true 真 和 false 假
简单数据类型之间的转换
在Java中整型、实型、字符型被视为简单数据类型,这些类型由低级到高级分别为
(byte,short,char)--int--long--float--double
更多可看:https://www.cnblogs.com/mxcl/p/7809959.html
2.工厂模式有什么好处?
工厂模式的作用,为什么要用工厂模式?
工厂模式是为了解耦:把对象的创建和使用的过程分开。就是Class A 想调用Class B,那么只是调用B的方法,而至于B的实例化,就交给工厂类。
工厂模式可以降低代码重复。如果创建B过程都很复杂,需要一定的代码量,而且很多地方都要用到,那么就会有很多的重复代码。可以把这些创建对象B的代码放到工厂里统一管理。既减少了重复代码,也方便以后对B的维护。
工厂模式可以减少错误,因为工厂管理了对象的创建逻辑,使用者不需要知道具体的创建过程,只管使用即可,减少了使用者因为创建逻辑导致的错误。
工厂模式的一些适用场景:
对象的创建过程/实例化准备工作很复杂,需要很多初始化参数,查询数据库等
类本身有好多子类,这些类的创建过程在业务中容易发生改变,或者对类的调用容易发生改变
可以参考,计算器例子。
3.二维数组的初始化
int [][] a=new int[][]{{1,2,3},{2,3}};
int [][] a=new int[4][4];
int [][]a=new int[3][];
4.一维数组初始化
int[] arr = new int[3];
int[] arr = null;
int[] arr = {1, 2, 3};
int[] arr = new int[]{1, 2, 3};
5.多态:
多态是同一个行为具有多个不同表现形式或形态的能力。
它包括两种类型:
静态多态性:包括变量的隐藏、方法的重载(指同一个类中,方法名相同[方便记忆],但是方法的参数类型、个数、次序不同,本质上是多个不同的方法);
动态多态性:是指子类在继承父类(或实现接口)时重写了父类(或接口)的方法,程序中用父类(或接口)引用去指向子类的具体实例,从代码形式上看是父类(或接口)引用去调用父类(接口)的方法,但是在实际运行时,JVM能够根据父类(或接口)引用所指的具体子类,去调用对应子类的方法,从而表现为不同子类对象有多种不同的形态。
多态的优点
- 1. 消除类型之间的耦合关系
- 2. 可替换性
- 3. 可扩充性
- 4. 接口性
- 5. 灵活性
- 6. 简化性
多态存在的三个必要条件
- 继承
- 重写
- 父类引用指向子类对象
6.封装:
封装的好处:
- 封装可以隐藏实现的细节
- 让使用者只能通过实现写好的访问方法来访问这些字段,这样一来我们只需要在这些方法中增加逻辑控制,限制对数据的不合理访问、
- 方便数据检查,有利于于保护对象信息的完整性
- 便于修改,提高代码的可维护性
实现封装的方式:使用访问控制符
java提供了三种访问权限,准确的说还有一种是默认的访问权限,加上它一共四种。
- private 在当前类中可访问
- default 在当前包内和访问
- protected 在当前类和它派生的类中可访问
- public 公众的访问权限,谁都能访问
7.把一个整数反转过来,这道你查一下,要注意正负数的情况


public class demo_exp_2 { public int reverse(int x) { int rev = 0; while (x != 0) { int pop = x % 10; x /= 10; if (rev > Integer.MAX_VALUE/10 || (rev == Integer.MAX_VALUE / 10 && pop > 7)) return 0; if (rev < Integer.MIN_VALUE/10 || (rev == Integer.MIN_VALUE / 10 && pop < -8)) return 0; rev = rev * 10 + pop; } return rev; } public static void main(String[] args){ demo_exp_2 a = new demo_exp_2(); System.out.println(a.reverse(-13232)); } }
简单代码如下:
public class Solution { public int reverse(int x) { int result = 0; while (x != 0) { result = result * 10 + x % 10; // 每一次都在原来结果的基础上变大10倍,再加上余数 x = x / 10; // 对x不停除10 } return result; }
8.一球从100米高度自由落下,每次落地后反跳回原高度的一半;再落下,求它在 第10次落地时,共经过多少米?第10次反弹多高?
public static void main(String[] args) { int total = 0; int height = 100; for (int i = 0; i < 10; i++) { System.out.print("第" + (i + 1) + "次落下时候高度:" + height + " "); total = total + height; height = height / 2; System.out.println("第" + (i + 1) + "次落下经过距离:" + total); } }
8.Mysql的数据类型
主要包括以下五大类:
整数类型:BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、 INT、 BIG INT
浮点数类型:FLOAT、DOUBLE、DECIMAL
字符串类型:CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB
日期类型:Date、DateTime、TimeStamp、Time、Year
其他数据类型:BINARY、VARBINARY、ENUM、SET、Geometry、Point、MultiPoint、LineString、MultiLineString、Polygon、GeometryCollection等
9.Mysql索引
为什么不实用二叉查找树或者红黑树作为数据库索引。
二叉树在处理海量数据时,树的高度太高,虽然索引效率很高,达到logN,但会进行大量磁盘io,得不偿失。而且删除或者插入数据可能导致数据结构改变变成链表,需要增进平衡算法。而红黑树,插入删除元素的时候会进行频繁的变色和旋转(左旋,右旋),很浪费时间。但是当数据量很小的时候,完全可以放入红黑树中,此时红黑树的时间复杂性比b树低。因此,综上考虑,数据库最后选择了b树作为索引。
B tree和B+ tree应用场景:
1.B树常用于文件系统,和少部分数据库索引,比如mongoDB。
2.B+树主要用于mysql数据库索引。
B+ tree对比B tree的优点
B树的每个节点除了存储指向 子节点的索引外,还要存储data域,因此单一节点指向子节点的索引并不是很多,树的高度较高,磁盘io次数较多。B+树的高度更低,且所有data都存储在叶子节点,叶子节点都处于同一层,因此查询性能稳定,便于范围查找。
12.关系型数据库三大范式
要想满足第二范式必须先满足第一范式,想满足第三范式必须先满足第二范式。
第一范式:是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。(列数据的不可分割)
第二范式:要求数据库表中的每个行必须可以被唯一地区分,为实现区别通常需要为表加上一个列,以存储各个实例的唯一标识(主键)
第三范式:需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
简单总结就是:第一范式的关键词是列的原子性
第二范式的关键词是不能包含部分依赖
第三范式的关键词是不能包含传递依赖
更多:https://www.cnblogs.com/wsg25/p/9615100.html
13.list<T>、 list<?>、list<Object>的区别?
List<T>、List<?>、List<Object>这三者都可以容纳所有的对象,
但使用的顺序应该是首选List<T>,次之List<?>,最后选择List<Object>
原因如下:
(1) List<T>是确定的某一个类型
List<T>表示的是List集合中的元素都为T类型,具体类型在运行期决定;List<?>表示任意类型,与List<T>类似,而List<Object>则表示List集合中的所有元素为Object类型,因为Object是所有类的父类,所以List<Object>也可以容纳所有的类类型,从这一字面意义上分析,List<T>更符合习惯:编码者知道它是某一个类型,只是在运行期才确定而已。
(2) List<T>可以进行读写操作
List<T>可以进行诸如add、remove等操作,因为它的类型是固定的T类型,在编码期 不需要进行任何的转型操作。
List<?>是只读类型的,不能进行增加、修改操作,因为编译器不知道List中容纳的是 什么类型的元素,也就无毕校验类型是否安全了,而且List<?>读取出的元素都是Object类 型的,需要主动转型,所以它经常用于泛型方法的返回值。注意,List<?>虽然无法增加、修 改元素,但是却可以删除元素,比如执行remove、clear等方法,那是因为它的删除动作与泛型类型无关。
List<Object>也可以读写操作,但是它执行写入操作时需要向上转型(Upcast),在读 取数据后需要向下转型(Downcast),而此时已经失去了泛型存在的意义了。
14.数据库优化
1、选取最适用的字段属性
2、使用连接(JOIN)来代替子查询(Sub-Queries)
3、使用联合(UNION)来代替手动创建的临时表
4、事务
5、锁定表
6、使用外键
7、使用索引
8、优化的查询语句
MySQL性能优化的一些经验 a.为查询优化你的查询 b.学会使用EXPLAIN c.当只要一行数据时使用LIMIT 1 当你查询表的有些时候只需要一条数据,请使用 limit 1。 d.正确的使用索引 索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索、拍下、条件,那么,请为其建立索引吧。 e.不要ORDER BY RAND() 效率很低的一种随机查询。 f.避免SELECT * 从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。必须应该养成一个需要什么就取什么的好的习惯。 g.使用 ENUM 而不是 VARCHAR ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。 如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。 h.使用 NOT NULL k.垂直分割 “垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。需要注意的是,这些被分出去的字段所形成的表,你不会经常性地去Join他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降。 l.拆分大的 DELETE 或 INSERT 语句 m.越小的列会越快 对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。 n.选择正确的存储引擎 在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。 MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。 InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
9.两个list查找相同元素!除了遍历外你还想到什么方法?
从两个list中找到重复元素,很容易就想到两个for循环嵌套来实现,但是如果两个list都非常大的话,时间复杂度将非常大。所以这里介绍一种以空间换时间的方法。
1.因为list中是可以存在相同元素的,但是想以2来得到重复的元素,所以需要进行去重
2.将list中的元素放入map中,并对元素个数进行一个统计
3.将hashmap中value为2的key存入list
代码如下:
public class TestList { public static void main(String[] args) { List<String> list1 = new ArrayList<String>(); List<String> list2 = new ArrayList<String>(); list1.add("a"); list1.add("b"); list1.add("b"); list1.add("c"); list2.add("b"); list2.add("c"); list2.add("d"); String duplicate = findDuplicate(list1, list2); System.out.println("duplicate element: " + duplicate); } private static String findDuplicate(List<String> list1, List<String> list2) { List<String> duplicate = new ArrayList<String>(); Map<String, Integer> map = new HashMap<String, Integer>(); //1.去重 List<String> list3 = new ArrayList<String>(new HashSet<String>(list1)); List<String> list4 = new ArrayList<String>(new HashSet<String>(list2)); //2.将list中的元素加入map中并进行统计 for (String s1 : list3) { map.put(s1, 1); } //3.将list中的元素加入map中并进行统计 for (String s2 : list4) { map.put(s2, (map.get(s2) == null ? 1 : 2)); } //4.将重复的元素放入list中 for (Map.Entry<String, Integer> m : map.entrySet()) { if (m.getValue() == 2) { duplicate.add(m.getKey()); } } return duplicate.toString(); } }
15.复习一下mybatis
16.数据库如果有某个字段忽然增大到几万的长度怎么办
可以另外建一个表来存储这段数据,再有就是把字段切割成几段,原先的表里存对应的id ,避免原先的表数据量过大
