Java正则表达式练习
一、导读
正则表达式,又称规则表达式。(英文名Regular Expression,所以代码中常以regex、regexp、RE表示)。正则表达式简单说就是用于操作文本数据的规则表达式,在Java中我们使用正则表达式来对字符串进行“有规则的操作”,没理解没关系,看下面的练习就懂了。
正则表达式对字符串的常见操作有:字符串的匹配、切割、替换、获取。下面我们就逐一进行练习:
二、正则表达式の规则
既然是表达式,就具有特定的规则,所以我们先看看jdk的工具类Pattern对正则表达式的规则的描述:(较多,简单浏览即可,当使用到对应的规则是来查阅即可。)

三、字符串の匹配:matches()
练习1:对输入的qq号进行匹配(qq匹配规则:长度为5-10位,纯数字组成,且不能以0开头。)
没有学习正则表示式之前,我们需要用各种if语句来进行判断,但现在我们可以使用则正表达式的规则来操作:
1 package RegularExpression; 2 3 public class regexTest { 4 public static void main(String[] args) { 5 //测试: 6 String qq1 = "1832137835"; 7 String qq2 = "789j9371"; 8 String qq3 = "22"; 9 String qq4 = "012189783"; 10 boolean b1 = isQQ(qq1); 11 boolean b2 = isQQ(qq2); 12 boolean b3 = isQQ(qq3); 13 boolean b4 = isQQ(qq4); 14 15 System.out.println(qq1+"是qq号码吗?"+b1); 16 System.out.println(qq2+"是qq号码吗?"+b2); 17 System.out.println(qq3+"是qq号码吗?"+b3); 18 System.out.println(qq4+"是qq号码吗?"+b4); 19 } 20 21 //练习1:匹配QQ号(长度为5-10位,纯数字组成,且不能以0开头) 22 public static boolean isQQ(String qq) { 23 //定义匹配规则: 24 String regex = "[1-9][0-9]{4,9}"; 25 26 //判断是否符合规则 27 boolean b = qq.matches(regex); 28 29 return b; 30 } 31 }
运行结果:
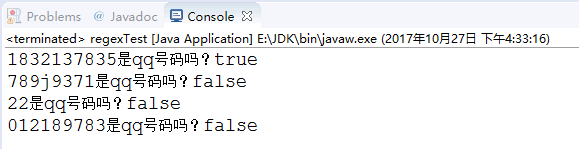
解析:注意匹配规则被“浓缩”到了字符串regex中,我们只需要用"[1-9][0-9]{4,9}"就描述了qq的匹配规则,怎么做到的呢?
首先我们在匹配需要“一位一位地匹配”,qq匹配规则是第一位不能是0的纯数字,所以我们用[1-9]来表示第一位的规则;接下来是第二位:随意的数字都行,所以我们用[0-9]来表示,按照这个逻辑,当然后面的都应该是纯数字即[0-9],但我们需要确定qq的长度只能是5~10,而规则里我们用{}来表示范围,即[0-9]{4,9}结合起来就表示:4~9个纯数字。
总的来说就是:[1-9]规定第一位只能是1~9即不为0的纯数字,而[0-9]{4,9}则规定可输入4~9个纯数字,加起来刚好是:首位不为0的长度为5~10的纯数字。
上面使用的规则如[]、{}等特殊符号在标题二中都能找到,对于这些常用的符号我们记住就好。
练习2:对输入的电话号码进行匹配(匹配要求:匹配成功的电话号码位数为11位的纯数字,且以1开头,第二位必须是:3、7、8中的一位,即只匹配13*********、17*********、18*********的电话号码)。
解析:同练习1一样,首先我们使用字符串regex对匹配规则进行描述,一位一位地匹配,所以,开头必须是数字1,那么我们可以写[1]来表示(不过对于只有一个字符的描述,可省略[]);接下来描述第二个字符:只能是3、7、8,所以我们使用[378]来表示。然后后9位号码只要是数字就可以了,所以我们可以用[0-9]{9}来表示。连起来就是:regex = "1[378][0-9]{9}"。
我们用代码来实现一下:
1 package RegularExpression; 2 3 public class regexTest { 4 public static void main(String[] args) { 5 //测试: 6 String t1 = "13745678901"; 7 String t2 = "12745678901"; 8 String t3 = "121213121212"; 9 String t4 = "23333333333"; 10 boolean b1 = isQQ(t1); 11 boolean b2 = isQQ(t2); 12 boolean b3 = isQQ(t3); 13 boolean b4 = isQQ(t4); 14 15 System.out.println(t1+"是电话号码吗?"+b1); 16 System.out.println(t2+"是电话号码吗?"+b2); 17 System.out.println(t3+"是电话号码吗?"+b3); 18 System.out.println(t4+"是电话号码吗?"+b4); 19 } 20 21 //练习2:匹配电话号吗(以1开头第二位必须是3/7/8的11位纯数字组成) 22 public static boolean isQQ(String qq) { 23 //定义匹配规则: 24 String regex = "1[378][0-9]{9}"; 25 26 //判断是否符合规则 27 boolean b = qq.matches(regex); 28 29 return b; 30 } 31 }
打印结果
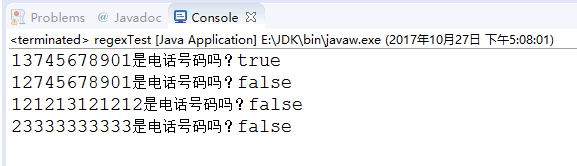
[一个小细节]:除了用[0-9]表示纯数字还可以用\d来表示(上面规则里有可以往上look),所以我们还可以令regex = "1[378]\\d{9}"。(在java中\需要用\来转义,所以写为\\d而不是\d)。
四、字符串の切割:split()
对字符串进行切割就是对一个字符串按照某个或某些字符进行切割,从而变成若干字符串。如“张三、李四、王五”,我们如果按照“、”来切割就变成三个字符串:“张三”,“李四”,“王五”。(切割的实质其实就是先进行字符串匹配,将匹配到的字符串“丢弃”,并将丢掉的前面部分和剩下的部分变成字符串)。
练习1:对字符串“张三@@@李四@@王五@茅台”进行切割,去掉@符号。
分析:首先我们要去掉字符串中的若干个@符号,如果只有一个@符号我们可以用直接用@来匹配,但这里的@是不确定的,所以我们要用到规则中的:

所以我们用@+来表示:@这个符号至少出现一次这种情况,现在我们可以来看看具体的代码:
1 package RegularExpression; 2 3 public class splitTest { 4 public static void main(String[] args) { 5 //练习1:切割字符串"张三@@@李四@@王五@茅台". 6 String s = "张三@@@李四@@王五@茅台"; 7 8 //描述切割规则:以若干@来切割 9 String regex = "@+"; 10 11 //切割后的字符串数组: 12 String[] ss = s.split(regex); 13 14 for(String string:ss){ 15 System.out.println(string); 16 } 17 18 } 19 }
打印结果:
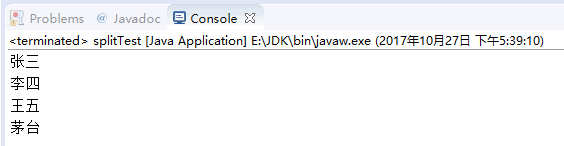
练习2:【以叠词切割】:如字符串"abccsasahhhz"按“叠词”来切割就变成了“ab”,“sasa”,“z”。因为“cc”、“hhh”都是叠词,需要切割掉。现在请将字符串“张三@@@李四¥¥王五ssssssss江流儿”按照叠词切割。
分析:关键点在于如何表示叠词呢?连续出现两个以上的相同字符即为叠词,首先我们要表示任意字符:
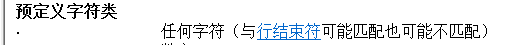
我们使用“.”来表示任意字符,接着我们需要表示两个这样的字符:这里我们需要使用到“组”的概念:

即使用括号:()来表示组,那么组是干嘛的?我们就可以 对组中的数据进行引用:那么regex = "(.)\\1"就表示:某一字符出现了两次(注意首先我们用(.)来表示任意字符,而\\1是对组(.)中的字符进行复用,合起来就是:两个相同的字符),现在我们不只是需要出现两次的字符,所以使用+号来表示出现多次,最终叠词就表示为:regex = "(.)\\1+"。
看具体实现代码:
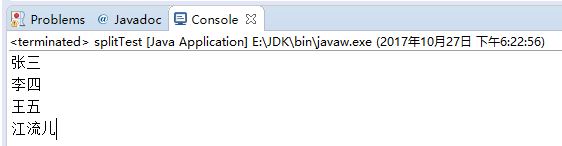
1 package RegularExpression; 2 3 public class splitTest { 4 public static void main(String[] args) { 5 //练习2:"张三@@@李四¥¥王五ssssssss江流儿"按叠词切割. 6 String s = "张三@@@李四¥¥王五ssssssss江流儿"; 7 8 //叠词切割 9 String regex = "(.)\\1+"; 10 11 //切割后的字符串数组: 12 String[] ss = s.split(regex); 13 14 for(String string:ss){ 15 System.out.println(string); 16 } 17 18 } 19 }
切割结果:
[一个小细节]:转义字符的使用
对于“haha.lisi.nihao”这样的字符串如果要用"."来切割,要怎么办呢?可能你会说定义regex="."不就哦了吗?但是如果你代码真这样写的话,你的输出结果就会像你的脑海一样“一片空白”。注意:“.”这个符号在正则表达式中是有特殊意义的:
这个小点可以代表任何字符,所以我们需要用转义字符\来将“.”转义为普通的点,所以只要把regex = "\\."即可。
五、字符串の替换:replaceAll()
利用正则表达式进行字符串替换其实是先匹配指定字符串中的字符,然后再用自定义字符替换掉匹配到的字符串。
练习一:将字符串“张三@@@李四YYY王五*****王尼玛”中的叠词替换为:“、”。
分析:第一步是匹配叠词:上面的练习中我们已经知道regex = "(.)\\1+"可以表示叠词,所以第二部就可以使用replaceAll()方法进行替换了:
1 package RegularExpression; 2 3 public class replaceAllTest { 4 public static void main(String[] args) { 5 //练习1:将字符串“张三@@@李四YYY王五*****王尼玛”中的叠词替换为:“、”。 6 String str = "张三@@@李四YYY王五*****王尼玛"; 7 8 //匹配规则 9 String regex = "(.)\\1+"; 10 11 //替换为: 12 String newStr = str.replaceAll(regex, "、"); 13 14 //替换后结果: 15 System.out.println(newStr); 16 } 17 18 }

练习二:将“张三@@@李四YYY王五*****王尼玛”中的叠词替换为单字符,即结果为:“张三@李四Y王五*王尼玛”。
分析:这个练习和练习1很像,首先我们都需要匹配到叠词,但是替换的内容却不是固定的“、”了,我们需要将叠词替换为它本身的字符,所以我们需要引用组的内容,我们可以使用$1来复用组中第1组的值(即叠词的字符):
1 package RegularExpression; 2 3 public class replaceAllTest { 4 public static void main(String[] args) { 5 //练习2:将“张三@@@李四YYY王五*****王尼玛”中的叠词替换为单字符,即结果为:“张三@李四Y王五*王尼玛”。 6 String str = "张三@@@李四YYY王五*****王尼玛"; 7 8 //匹配规则 9 String regex = "(.)\\1+"; 10 11 //替换为: 12 String newStr = str.replaceAll(regex, "$1"); 13 14 //替换后结果: 15 System.out.println(newStr); 16 } 17 18 }

六、字符串の获取:
正则表达式其实是封装成了Pattern类,所以字符串的匹配、切割、替换都是调用了Pattern类中的方法。所以如果我们需要获取指定字符串中的子串,首先同样的我们需要进行字符串匹配,然后判断指定字符串中是否有匹配的子串,有就获取,没有就获取不到。
获取子串的步骤:
1、描述要获取的子串:匹配子串
2、使用正则表达式的封装类Pattern来获取匹配器
3、使用匹配器中的方法group()获取字符串的匹配的子串
练习:获取字符串“Hi ! Don't be moved by yourself Fzz”中为两个字母的单词。即Hi、be、by。
分析:根据上面的步骤:
第一步,我们要对子串进行匹配,即两个字母的单词,字母可以用[a-zA-Z]来表示,范围是两个,所以regex = "[a-zA-Z]{2}"。
但这样不够准确,我们需要的是单词,而不是三个字母,所以要用到“边界匹配器”,即

单词边界:\b,所以regex = "\\b[a-zA-Z]{2}\\b"。
然后是第二步:获取匹配器
1 Pattern p = Pattern.compile(regex); 2 Matcher m = p.matcher(s);
最后一步:使用匹配器来获取匹配到的字符串
1 while(m.find()){ 2 System.out.println(m.group()); 3 }
我们来看看总体的实现代码:
1 package RegularExpression; 2 3 import java.util.regex.Matcher; 4 import java.util.regex.Pattern; 5 6 public class groupTest { 7 public static void main(String[] args) { 8 String s = "Hi ! Don't be moved by yourself Fzz"; 9 10 //1、匹配子串 11 String regex = "\\b[a-zA-Z]{2}\\b"; 12 13 //2、获取匹配器 14 Pattern p = Pattern.compile(regex); 15 Matcher m = p.matcher(s); 16 17 //3、使用匹配器的group()方法来获取:(find方法是判断是否具有匹配子串)、 18 System.out.println("”"+s+"“中的两个字母的单词有:"); 19 while(m.find()){ 20 System.out.println(m.group()); 21 } 22 } 23 }
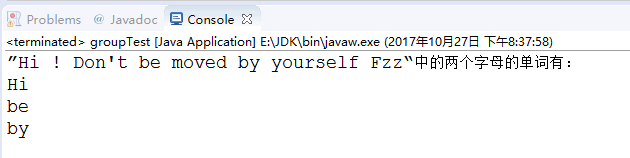
七、进阶:综合练习
练习一:口吃怎么办?需求:请将下面的字符串“我我我……我我……爱…爱爱……学…学……学编程”改为:“我爱学编程”。
分析:首先我们可以将字符串中的“……”去掉,然后就可以将叠词替换为单个汉字即可。
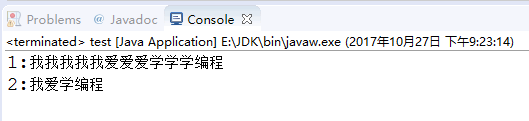
1 package RegularExpression; 2 3 public class test { 4 public static void main(String[] args) { 5 //口吃怎么办?将“我我我……我我……爱…爱爱……学…学……学编程”改为“我爱学编程”。 6 String str = "我我我......我我......爱...爱爱...学...学......学编程"; 7 //1、首先去掉...(将.替换为""即可) 8 String regex = "\\."; 9 String str1 = str.replaceAll(regex,""); 10 System.out.println("1:"+str1); 11 //2、替代叠词 12 regex = "(.)\\1+"; 13 String str2 = str1.replaceAll(regex, "$1"); 14 System.out.println("2:"+str2); 15 } 16 }
*练习二*:网络爬虫spider(专门获取指定规则数据的程序)。需求:在某一个网页中获取该网页中出现的特定信息,比如获取该网页中出现的邮箱地址。(其实这就是网页爬虫的简单运用:获取邮箱。)
分析:首先我们随便百度一个网页吧:
首先我们就以第一个网页为例:
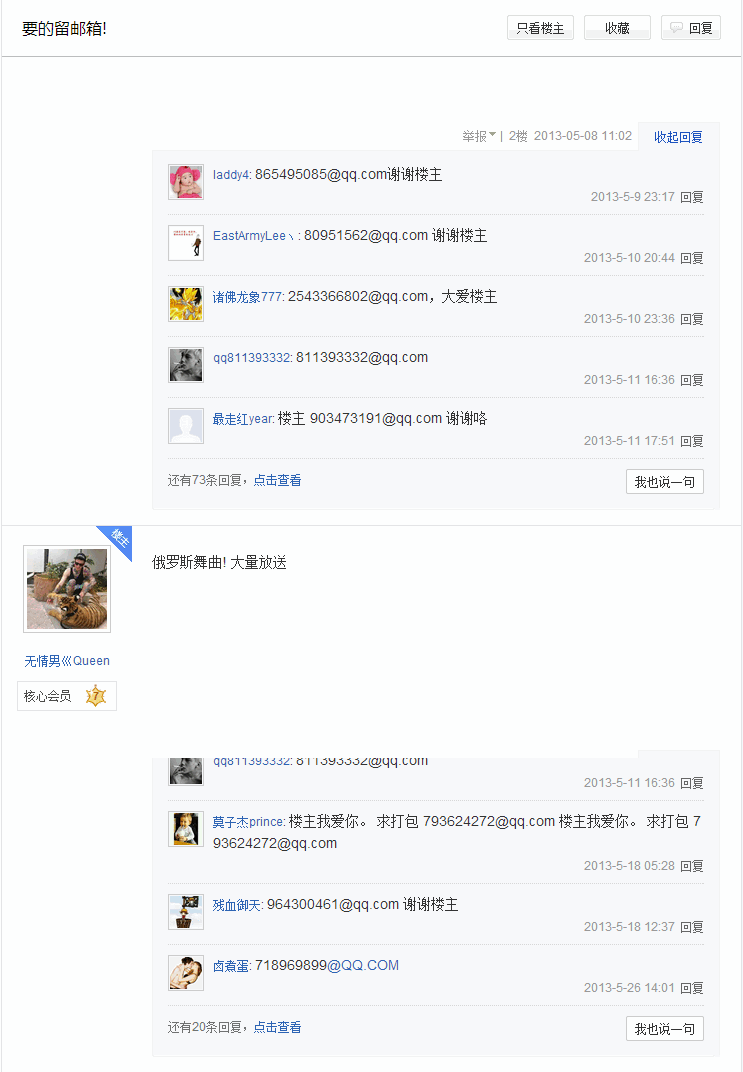
我们可以看到里面有超多的qq邮箱,现在我们就来获取这个网页里的qq邮箱。
1、首先我们要获取这个网页的html文档,方便获取其中的文字信息。现在我将这个文件保存在了本地方便操作。可以看一下用记事本打开的效果:
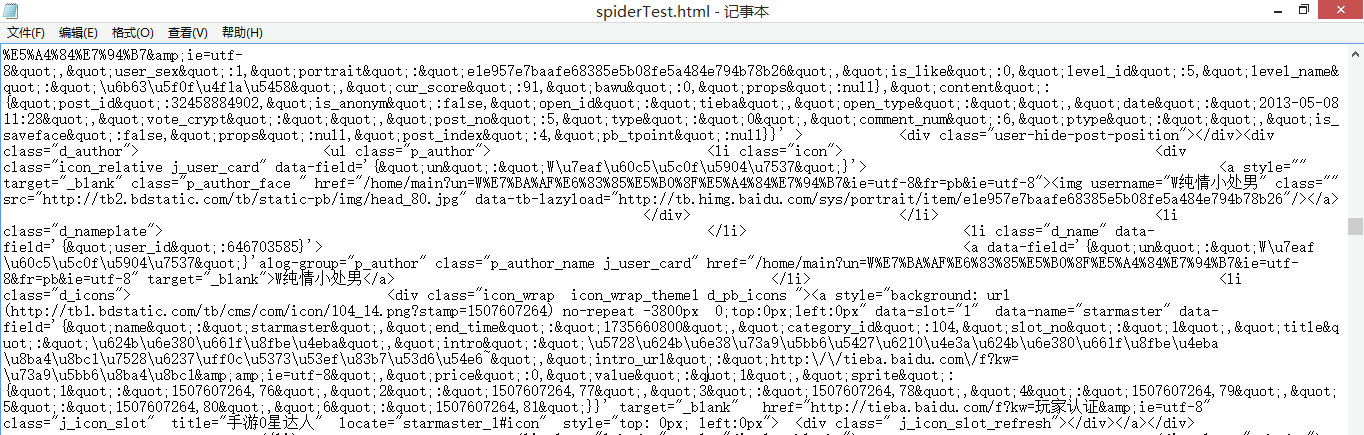
2、然后我们就需要使用IO流来读取这个html文档
3、对读取的文档利用正则表达式规则进行特定字符串(即qq邮箱)的获取


1 package RegularExpression; 2 3 import java.io.BufferedReader; 4 import java.io.File; 5 import java.io.FileReader; 6 import java.io.IOException; 7 import java.util.regex.Matcher; 8 import java.util.regex.Pattern; 9 10 /* 11 * 网页爬虫测试:获取某网页中的QQ邮箱 12 */ 13 public class spiderTest { 14 public static void main(String[] args) throws IOException { 15 //1、读取网页内容(即用IO流获取我保存的html文档) 16 File f = new File("tempFile\\spiderTest.html"); 17 BufferedReader br = new BufferedReader(new FileReader(f)); 18 19 //2、匹配规则:qq邮箱 20 String regex = "[0-9]{5,10}@qq.com";//匹配5-10位qq号和@qq.com 21 22 //3、开始获取: 23 Pattern p = Pattern.compile(regex); 24 String line = null; 25 26 while((line=br.readLine()) != null){//读取html中的数据 27 Matcher m = p.matcher(line); //匹配器 28 while(m.find()){ 29 System.out.println(m.group());//打印匹配到的qq邮箱 30 } 31 } 32 33 br.close();//关闭IO流 34 } 35 36 }
这就是我们获取到的邮箱:
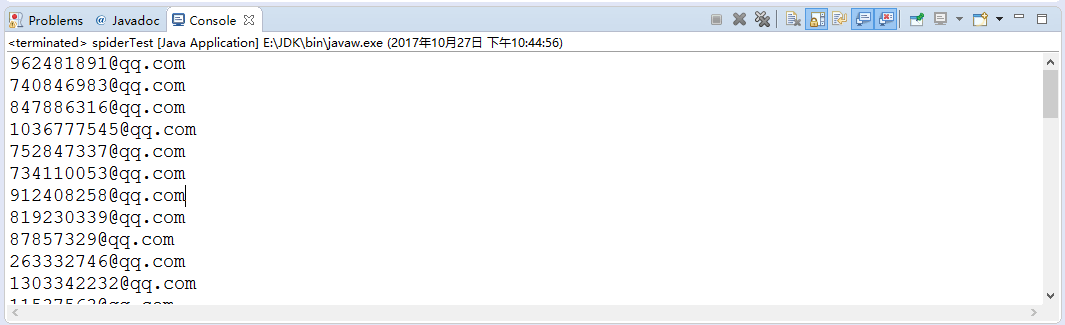
八、总结
正则表达式还有很多规则需要我们去深入学习,对于正则表达式,它的优点就是简化了字符串的操作,缺点是我们需要学习这些特点的规则,而且符号过多时不方便阅读。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号