

网络爬虫第五次作业——Selenium
作业①:
1)爬取京东商城实验
- 要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架爬取京东商城某类商品信息及图片。 - 候选网站:http://www.jd.com/
- 关键词:自由选择
程序思路要点:
- 定位搜索框,输入预设关键词,利用键盘回车事件进行搜索
- 定位翻页按钮,模拟鼠标点击进行翻页
- 确定使每一页页面内容完整加载的方法
- 设计每一页的数据解析方法提取所需数据
- 使用多线程下载图片
- 数据库存储操作包括数据库以及表的创建、插入、关闭。
代码:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.common.exceptions import NoSuchElementException
import time
import pymysql
from urllib.parse import urljoin
from urllib.request import urlretrieve
import os
import random
import threading
import warnings
warnings.filterwarnings('ignore')
class SpiderGoods(object):
def __init__(self):
option = webdriver.FirefoxOptions()
option.add_argument('--headless') # 静默模式
self.browser = webdriver.Firefox(options=option) # 创建浏览器对象
# self.browser = webdriver.Firefox() # 创建浏览器对象
self.start_url = "http://www.jd.com/" # 起始网址
self.pagenum = 3 # 设置爬取页数
self.wait_time = 5 # 设置利用selenium执行操作后的等待时间
def search_keywords(self,keywords):
'''搜索指定关键词keywords'''
while True: # 直到定位到输入框
try:
input_box = self.browser.find_element_by_id("key") # 定位输入框
break
except:
print("The input box cannot be located, please try to wait")
input_box.send_keys(keywords) # 支持中文
input_box.send_keys(Keys.ENTER) # 模拟回车键
def get_complete_onepage(self,page):
'''获取单页完整字符内容'''
# 定位右上角的页码元素
locator = (By.XPATH,'//span[@class="fp-text"]/b[text()="{}"]'.format(str(page)))
# 显示等待,等待页面内容出现
# driver:浏览器驱动,timeout:最长超时时间,poll_frequency:检测的间隔步长,默认为0.5s
# 调用until方法,直到返回True
WebDriverWait(driver=self.browser, timeout=10, poll_frequency=0.5) \
.until(EC.presence_of_all_elements_located(locator)) # 直到返回值为True
# 将页面滚动条拖到底部
self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(self.wait_time) # 强制等待5s
# 模拟键盘空格键使页面下滑,进而加载下半部分页面内容
# 调用ActionChains的方法时,不会立即执行,而是所有的操作按顺序存放在一个队列里
# 当调用perform()方法时,队列中的事件会依次执行
ActionChains(self.browser).send_keys(Keys.SPACE).perform()
while True:
try:
# 定位未加载页面下半部分信息时才会出现的标签对
locator = (By.XPATH,'//div[@class="notice-loading-more"]')
WebDriverWait(driver=self.browser, timeout=10, poll_frequency=0.5) \
.until_not(EC.presence_of_all_elements_located(locator)) # 直到返回值为False
break
except Exception as err:
print(err)
print('div[@class="notice-loading-more"] still exists')
# 利用键盘事件随机上下移动滚动条使页面最终得以全部加载
random_choice = random.randint(0,1)
if random_choice:
ActionChains(self.browser).send_keys(Keys.DOWN).send_keys(Keys.DOWN).perform()
else:
ActionChains(self.browser).send_keys(Keys.UP).send_keys(Keys.UP).perform()
def turn_page(self):
'''翻页方法'''
try:
# 定位翻页按钮元素
button = self.browser.find_element_by_class_name("pn-next")
# 模拟点击
button.click()
except NoSuchElementException: # 如果定位不到翻页按钮元素
print("The last page has been reached, no more pages can be turned")
except Exception as err:
print(err)
def db_init(self):
'''初始化数据库参数'''
self.host = '127.0.0.1' # MYSQL服务器地址
self.port = 3306 # MYSQL服务器端口号
self.user = 'root' # 用户名
self.passwd = "passwd" # 密码
self.db = 'spider_db' # 数据库名称
self.charset = 'utf8' # 连接编码
self.table = 'goods' # 设置表名
def create_db(self):
'''建立数据库'''
try:
conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
charset=self.charset)
cursor = conn.cursor()
sql_crdb = "create database if not exists {}".format(self.db)
cursor.execute(sql_crdb)
print("数据库{}已创建".format(self.db))
except Exception as err:
print(err)
def build_table(self):
'''构建表结构'''
try:
self.con = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset=self.charset)
self.cursor = self.con.cursor() # 使用连接对象获得cursor对象
# 如果表存在则删除
sql_drop = 'drop table if exists {}'.format(self.table)
self.cursor.execute(sql_drop)
# 如果表不存在则创建,由于之前进行删表操作,所以这里会创建新表
sql_create = 'create table if not exists {}('.format(self.table) + \
"mNo varchar(32) primary key," + \
"mMark varchar(256)," + \
"mPrice varchar(32)," + \
"mNote varchar(1024)," + \
"mFile varchar(256))" # 注意避免Duplicate entry导致主键值相同的不同商品信息丢失
self.cursor.execute(sql_create)
# 清空表中记录
# sql_delete = "delete from {}".format(self.table)
# self.cursor.execute(sql_delete)
except Exception as err:
print(err)
def insert_table(self,mNo,mMark,mPrice,mNote,mFile):
'''按特定格式向表中插入数据'''
try:
sql_insert = "insert into {} (mNo,mMark,mPrice,mNote,mFile) values (%s,%s,%s,%s,%s)"\
.format(self.table)
self.cursor.execute(sql_insert, (mNo, mMark, mPrice, mNote, mFile))
except Exception as err:
print(err)
def close(self):
'''关闭数据库及当前窗口'''
try:
self.con.commit() # 用于将事务所做的修改保存到数据库
self.con.close() # 断开数据库连接
self.browser.close() # 关闭当前窗口
except Exception as err:
print(err)
def process_pages_data(self):
'''数据处理'''
# 初始化mNo
self.number = 0
# 爬取指定页数
for page in range(1, self.pagenum + 1):
# 获取指定页码的页面完整信息
self.get_complete_onepage(page)
# 获取存储每一个商品信息的li标签对象
li_list = self.browser.find_elements_by_xpath('//li[@class="gl-item"]')
for li in li_list:
# 编号
self.number += 1
number = "{:0>6}".format(self.number) # 填充前补0至指定位数
# 图片
try:
# data-lazy-img:图片懒加载
# The image is either in data-lazy-img attribute or in src
relative_url = li.find_element_by_xpath('.//div[@class="p-img"]//img').get_attribute("data-lazy-img")
if relative_url == "done":
relative_url = li.find_element_by_xpath('.//div[@class="p-img"]//img').get_attribute("src")
print("src:{}".format(relative_url))
img_url = urljoin(self.start_url, relative_url) # 拼接成绝对路径
except NoSuchElementException:
img_url = ''
print("Please check the parsing rules")
finally:
pos = img_url.rfind('.') # 返回字符串最后一次出现的位置(从右向左查询),如果没有匹配项则返回-1
img_name = number + img_url[pos:] # 图片文件名
# 价格
try:
price = li.find_element_by_xpath('.//div[@class="p-price"]//i').text
except NoSuchElementException:
price = '0'
# 品牌和简介
try:
em_text = li.find_element_by_xpath('.//div[@class="p-name p-name-type-2"]//em').text
try:
span_text = li.find_element_by_xpath\
('.//div[@class="p-name p-name-type-2"]//em/span').text
except NoSuchElementException:
span_text = ''
# 品牌
mark = em_text.split(" ")[0].replace(span_text,'').strip()
# 简介
note = em_text.replace(span_text,'').strip()
except NoSuchElementException:
mark,note = '',''
# 生成器
yield number,mark,price,note,img_name,img_url
# 爬取到指定的最后一页无需再进行翻页
if page < self.pagenum:
self.turn_page()
def threads_download(self,img_url,img_name):
'''为图片下载引入多线程'''
try:
T = threading.Thread(target=self.download, args=(img_url,img_name)) # 创建线程对象
T.setDaemon(False) # True则为守护线程,若设置守护线程,一旦主线程执行完毕,子线程都得结束
T.start() # 启动线程
self.threads.append(T)
except Exception as err:
print(err)
def download(self,img_url,img_name):
'''下载指定img_url的图片到预设文件夹,并命名为指定img_name'''
dirname = "images" # 存储图片的文件夹
if not os.path.exists(dirname):
os.makedirs(dirname)
print("{}文件夹创建在{}".format(dirname, os.getcwd()))
save_path = dirname + "\\" + img_name
try:
urlretrieve(img_url,save_path)
print("download "+img_name)
except Exception as err:
print(err)
print("download failed")
def execute_spider(self):
'''执行爬虫'''
print("Start the crawler")
# 初始化数据库
print("Initializing")
self.db_init()
self.create_db()
self.build_table()
# 初始化线程对象列表
self.threads = []
# 打开预设网址
self.browser.get(self.start_url)
print("Open preset url")
# 搜索指定关键词
keywords = "笔记本"
print("Searching for keywords:{}".format(keywords))
self.search_keywords(keywords)
# 处理指定多页商品数据
print("Processing data")
datas_generator = self.process_pages_data() # 返回generator对象
for goods_info in datas_generator:
number, mark, price, note, img_name, img_url = goods_info
# 多线程下载图片
self.threads_download(img_url, img_name)
# 插入数据到数据库
self.insert_table(number, mark, price, note, img_name)
# 关闭数据库连接以及当前窗口
print("Closing")
self.close()
# 主线程中等待所有子线程退出
for t in self.threads:
t.join()
print("Finished")
if __name__ == "__main__":
start = time.clock()
spider = SpiderGoods()
spider.execute_spider()
end = time.clock()
print('Running time: {} Seconds'.format(end - start))
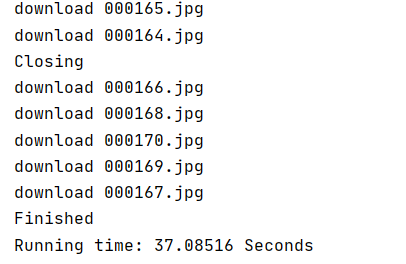
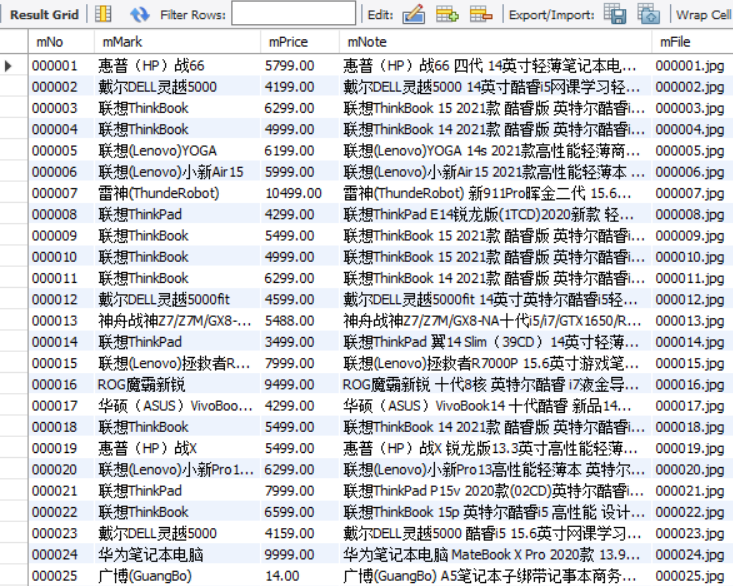
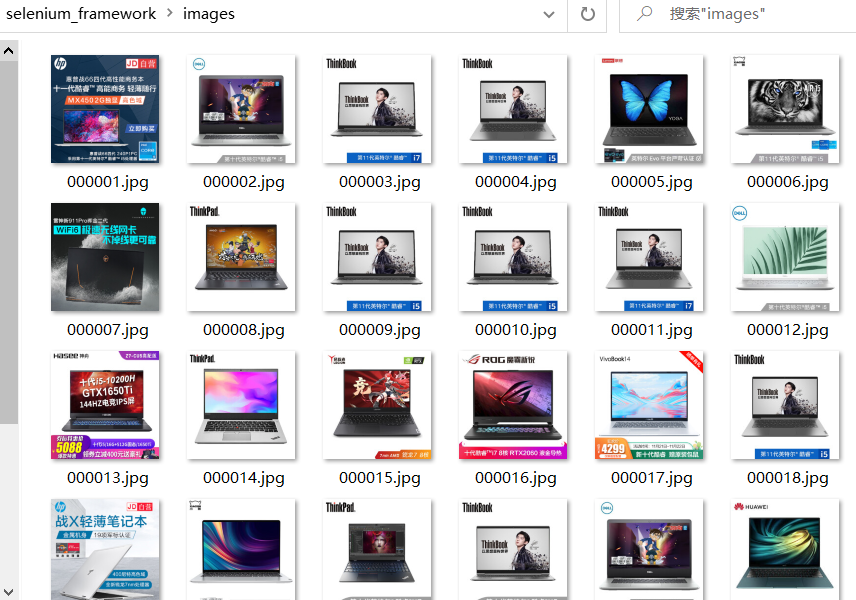
运行结果部分截图:
控制台输出

数据库存储

本地图片存储
2)心得体会:
困难:
1、京东的商品页面是懒加载(Lazy Load)的,也就是检测滚动状态,制造缓冲加载的效果。因此如果不采用selenium相关的操作模拟页面下滑则无法爬取到一页当中全部的商品内容(大概只能爬取一半),而简单采用将滚动条一次到底的方法无法解决这个问题。
self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")
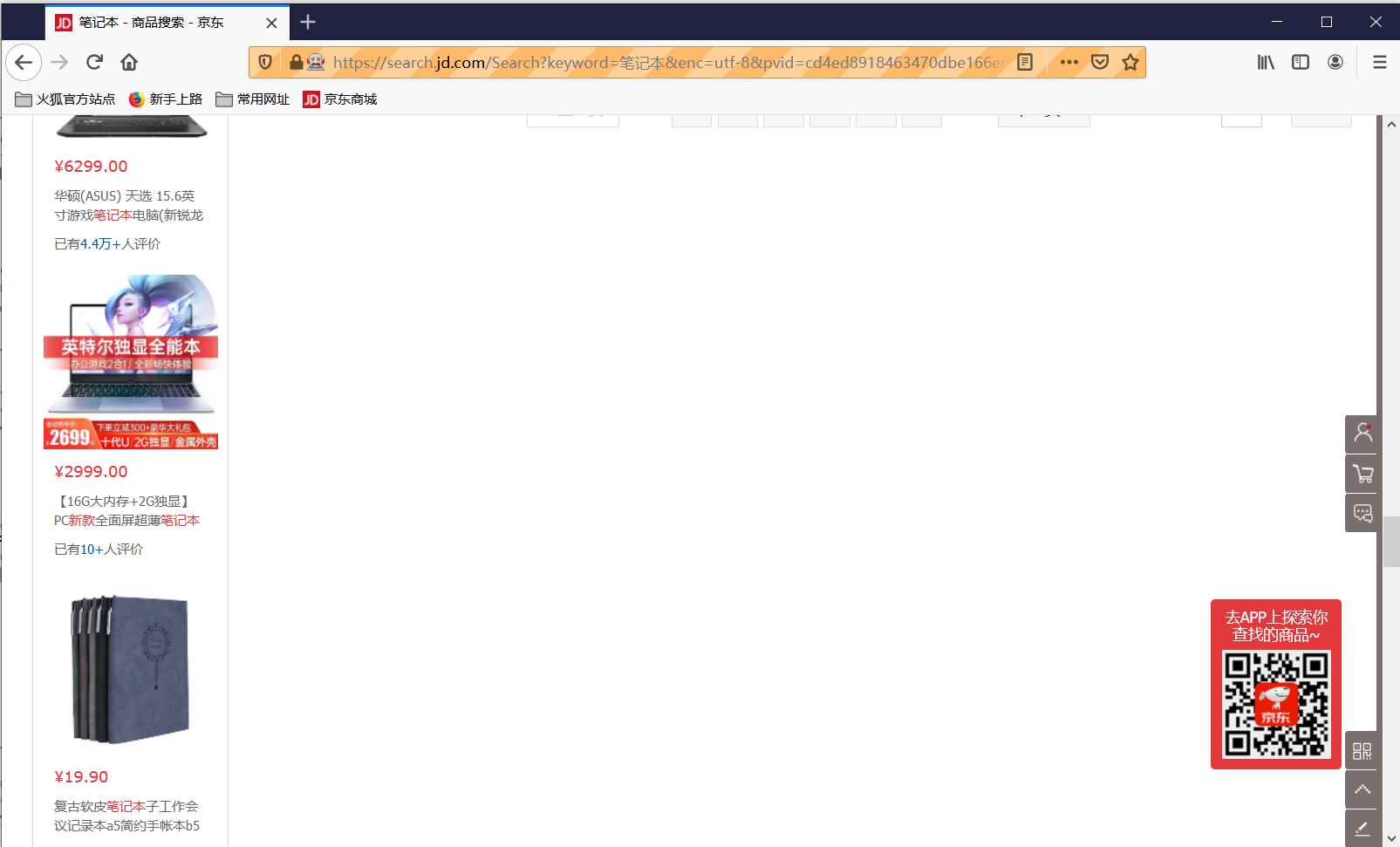
可以看到的是滚动条一次到底之后由于缓冲加载被弹回了中部而页面也定格住,没有完整加载。打印page_sourse可以发现以下标签:
<div id="J_scroll_loading" class="notice-loading-more"><span>正在加载中,请稍后~~</span></div>
最终采用利用定位器locator定位该标签,显示等待其出现,利用键盘事件空格使滚动条继续下滑的方法解决
# 模拟键盘空格键使页面下滑,进而加载下半部分页面内容
# 调用ActionChains的方法时,不会立即执行,而是所有的操作按顺序存放在一个队列里
# 当调用perform()方法时,队列中的事件会依次执行
ActionChains(self.browser).send_keys(Keys.SPACE).perform()
while True:
try:
# 定位未加载页面下半部分信息时才会出现的标签对
locator = (By.XPATH,'//div[@class="notice-loading-more"]')
WebDriverWait(driver=self.browser, timeout=10, poll_frequency=0.5) \
.until_not(EC.presence_of_all_elements_located(locator)) # 直到返回值为False
break
except Exception as err:
print(err)
print('div[@class="notice-loading-more"] still exists')
# 利用键盘事件随机上下移动滚动条使页面最终得以全部加载
random_choice = random.randint(0,1)
if random_choice:
ActionChains(self.browser).send_keys(Keys.DOWN).send_keys(Keys.DOWN).perform()
else:
ActionChains(self.browser).send_keys(Keys.UP).send_keys(Keys.UP).perform()
2、图片url所存储的标签位置不唯一,初看程序打印出的page_sourse以为图片url都存储在data-lazy-img属性中,但执行下载的时候发生了错误,仔细检查之后发现有少部分的图片url存储在src属性中,而此时对应的data-lazy-img属性值为“done”。这里图片采用了懒加载的方式。
3、品牌和简介中存在干扰项“京品电脑”以及换行符。由于干扰内容存储在span标签中,所以这里采用提取对应span标签中的文本再利用replace方法去除、利用strip方法去除首尾换行符的方式解决。
收获:
这次实验加深了我对selenium框架的理解,明白了如何利用selenium实现搜索、翻页以及加载页面完整内容等等。同时我也在这次实验中回顾了多线程处理IO密集型问题以及数据库存储操作。在等待页面元素的过程中体会到显示等待的魅力,但是同时也体会到了其局限性,其中的定位器locator需要定位到页面变动时不一样的元素标签才能发挥效果,所以本次实验还是结合使用了强制等待。
tips:本实验采用的搜索关键词应为某个商品的大类,如果是具体的某个商品例如书籍“苏菲的世界”,由于div标签下的属性与商品大类例如“笔记本”不同,所以品牌mark和简介note的解析规则应有所区别:
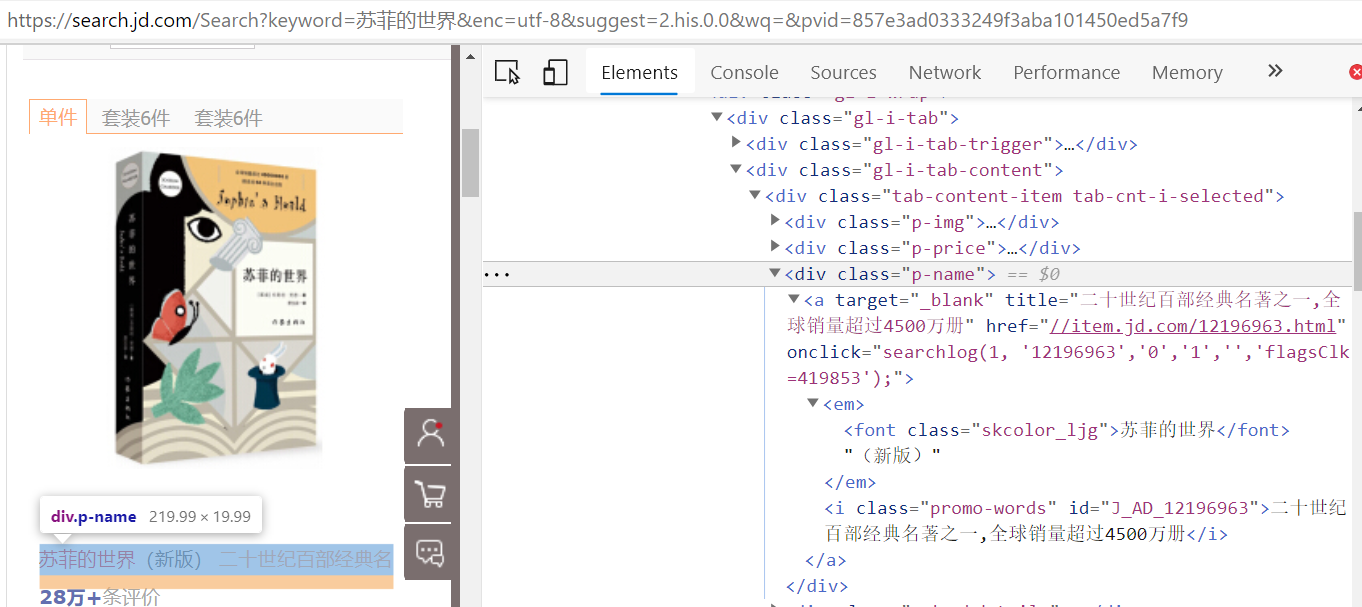
作业②:
1)爬取股票数据信息实验
-
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。 -
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
程序思路要点:
- 定位翻页按钮,模拟点击进行翻页
- 确定等待方式使页面内容完整加载
- 定位各个所需爬取的板块,模拟点击进行切换
- 设计数据解析方法提取所需数据
- 确定数据库存储操作
- 设计数据库数据在控制台的展示形式
代码:
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import time
import pymysql
import warnings
warnings.filterwarnings('ignore')
class SpiderStock(object):
def __init__(self):
# option = webdriver.FirefoxOptions()
# option.add_argument('--headless') # 静默模式
# self.browser = webdriver.Firefox(options=option) # 创建浏览器对象
self.browser = webdriver.Firefox() # 创建浏览器对象
self.start_url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board" # 起始网址
self.sections = ["沪深A股","上证A股","深证A股"]
self.pagenum = 3 # 设置爬取页数
self.wait_time = 3 # 设置利用selenium执行操作后的等待时间
def turn_section(self,section):
'''执行切换板块操作'''
try:
tab = self.browser.find_element_by_xpath('//div[@id="tab"]//li/a[text()="{}"]'.format(section)) # 定位
tab.click() # 点击
time.sleep(self.wait_time) # 等待
except NoSuchElementException: # 如果定位不到板块元素
print("The section does not exist")
except Exception as err:
print(err)
def turn_page(self):
'''执行翻页操作'''
try:
button = self.browser.find_element_by_xpath("//a[@class='next paginate_button']") # 定位
button.click() # 点击
time.sleep(self.wait_time) # 等待
except NoSuchElementException: # 如果定位不到翻页按钮元素
print("The last page has been reached, no more pages can be turned")
except Exception as err:
print(err)
def db_init(self):
'''初始化数据库参数'''
self.host = '127.0.0.1' # MYSQL服务器地址
self.port = 3306 # MYSQL服务器端口号
self.user = 'root' # 用户名
self.passwd = "passwd" # 密码
self.db = 'spider_db' # 数据库名称
self.charset = 'utf8' # 连接编码
self.table = 'stock' # 设置表名
def create_db(self):
'''建立数据库'''
try:
conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
charset=self.charset)
cursor = conn.cursor()
sql_crdb = "create database if not exists {}".format(self.db)
cursor.execute(sql_crdb)
print("数据库{}已创建".format(self.db))
except Exception as err:
print(err)
def build_table(self):
'''构建表结构'''
try:
self.con = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset=self.charset)
self.cursor = self.con.cursor() # 使用连接对象获得cursor对象
# 如果表存在则删除
sql_drop = 'drop table if exists {}'.format(self.table)
self.cursor.execute(sql_drop)
# 如果表不存在则创建,由于之前进行删表操作,所以这里会创建新表
sql_create = 'create table if not exists {}('.format(self.table) + \
"id int," + \
"stock_code varchar(32)," + \
"stock_name varchar(32)," + \
"latest_price varchar(32)," + \
"updown_range varchar(32)," + \
"updown_value varchar(32)," + \
"deal_volume varchar(32)," + \
"deal_value varchar(32)," + \
"stock_amplitude varchar(32)," + \
"stock_highest varchar(32)," + \
"stock_lowest varchar(32)," + \
"opening_price varchar(32)," + \
"closing_price varchar(32))"
self.cursor.execute(sql_create)
# 清空表中记录
# sql_delete = "delete from {}".format(self.table)
# self.cursor.execute(sql_delete)
except Exception as err:
print(err)
def insert_table(self,item):
'''按特定格式向表中插入数据'''
try:
sql_insert = "insert into {} (id,stock_code,stock_name,latest_price,updown_range,updown_value," \
"deal_volume,deal_value,stock_amplitude,stock_highest,stock_lowest,opening_price,closing_price) " \
"values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)".format(self.table)
self.cursor.execute(sql_insert,(int(item["id"]), item['stock_code'], item['stock_name'], item['latest_price'],
item['updown_range'], item['updown_value'], item['deal_volume'], item["deal_value"],
item["stock_amplitude"], item["stock_highest"], item["stock_lowest"],
item["opening_price"], item["closing_price"]))
except Exception as err:
print(err)
def show_table(self):
try:
titles = ["序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额",
"成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"]
tplt = "{0:^2}\t{1:^7}\t{2:^7}\t{3:^7}\t{4:^7}\t{5:^7}\t{6:^7}\t{7:^7}\t{8:^7}\t{9:^7}\t{10:^7}\t{11:^7}\t{12:^7}"
print(tplt.format(titles[0], titles[1], titles[2], titles[3], titles[4], titles[5], \
titles[6], titles[7], titles[8], titles[9], titles[10], titles[11], titles[12]))
sql_select = "select * from {}".format(self.table)
self.cursor.execute(sql_select)
rows = self.cursor.fetchall()
tplt = "{0:^3}\t{1:^8}\t{2:^8}\t{3:^8}\t{4:^8}\t{5:^8}\t{6:^8}\t{7:^8}\t{8:^8}\t{9:^8}\t{10:^8}\t{11:^8}\t{12:^8}"
for row in rows:
print(tplt.format(row[0], row[1], row[2], row[3], row[4], row[5], \
row[6], row[7], row[8], row[9], row[10], row[11], row[12]))
except Exception as err:
print(err)
def close(self):
'''关闭数据库及当前窗口'''
try:
self.con.commit() # 用于将事务所做的修改保存到数据库
self.con.close() # 断开数据库连接
self.browser.close() # 关闭当前窗口
except Exception as err:
print(err)
def process_datas(self):
'''处理多板块多页数据'''
try:
# 初始化数据项目字典
item = {}
for section in self.sections:
self.turn_section(section)
for page in range(1, self.pagenum+1):
# 获取存储每一个股票信息的tr标签对象
tr_list = self.browser.find_elements_by_xpath("//tbody/tr")
for tr in tr_list:
item["id"] = tr.find_element_by_xpath("./td[position()=1]").text
item["stock_code"] = tr.find_element_by_xpath("./td[position()=2]").text
item["stock_name"] = tr.find_element_by_xpath("./td[position()=3]").text
item["latest_price"] = tr.find_element_by_xpath("./td[position()=5]").text
item["updown_range"] = tr.find_element_by_xpath("./td[position()=6]").text
item["updown_value"] = tr.find_element_by_xpath("./td[position()=7]").text
item["deal_volume"] = tr.find_element_by_xpath("./td[position()=8]").text
item["deal_value"] = tr.find_element_by_xpath("./td[position()=9]").text
item["stock_amplitude"] = tr.find_element_by_xpath("./td[position()=10]").text
item["stock_highest"] = tr.find_element_by_xpath("./td[position()=11]").text
item["stock_lowest"] = tr.find_element_by_xpath("./td[position()=12]").text
item["opening_price"] = tr.find_element_by_xpath("./td[position()=13]").text
item["closing_price"] = tr.find_element_by_xpath("./td[position()=14]").text
yield item
if page < self.pagenum: # 最后一页无需点击按钮进行翻页
self.turn_page()
except Exception as err:
print(err)
def execute_spider(self):
'''执行爬虫'''
print("Start the crawler")
# 初始化数据库
print("Initializing")
self.db_init()
self.create_db()
self.build_table()
# 打开预设网址
self.browser.get(self.start_url)
print("Open preset url")
# 处理指定多板块多页数据
print("Processing data")
datas_generator = self.process_datas() # 返回generator对象
for item in datas_generator:
# 插入数据到数据库
self.insert_table(item)
# 展示数据库中表数据
print("Showing table data")
self.show_table()
# 关闭数据库连接以及当前窗口
print("Closing")
self.close()
print("Finished")
if __name__ == "__main__":
start = time.clock()
spider = SpiderStock()
spider.execute_spider()
end = time.clock()
print('Running time: {} Seconds'.format(end - start))
运行结果部分截图:
控制台输出
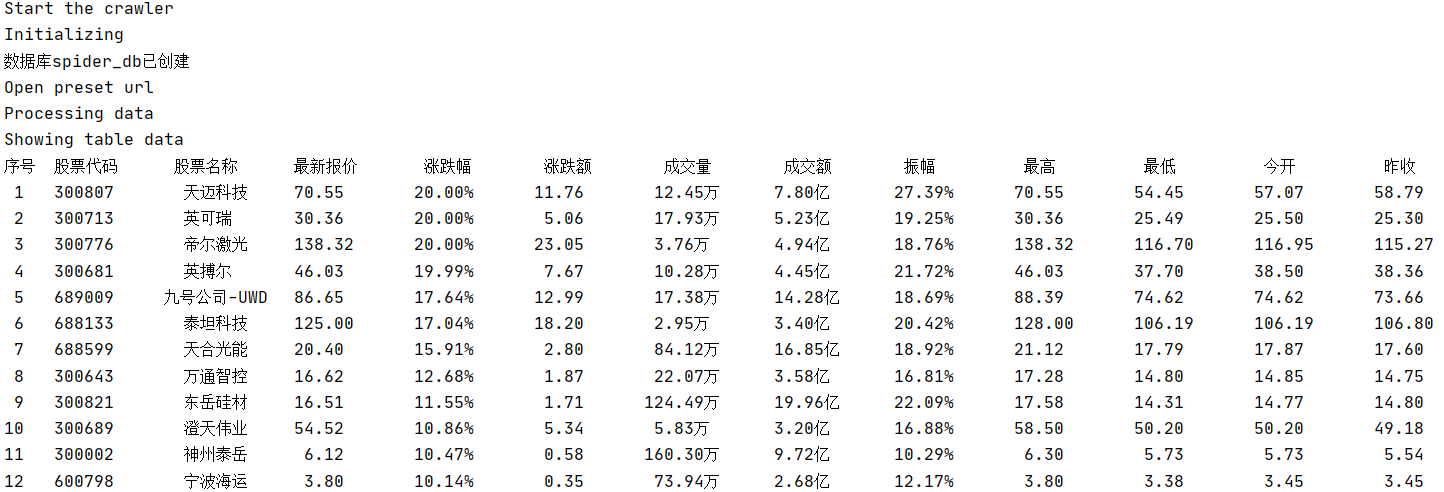

数据库存储
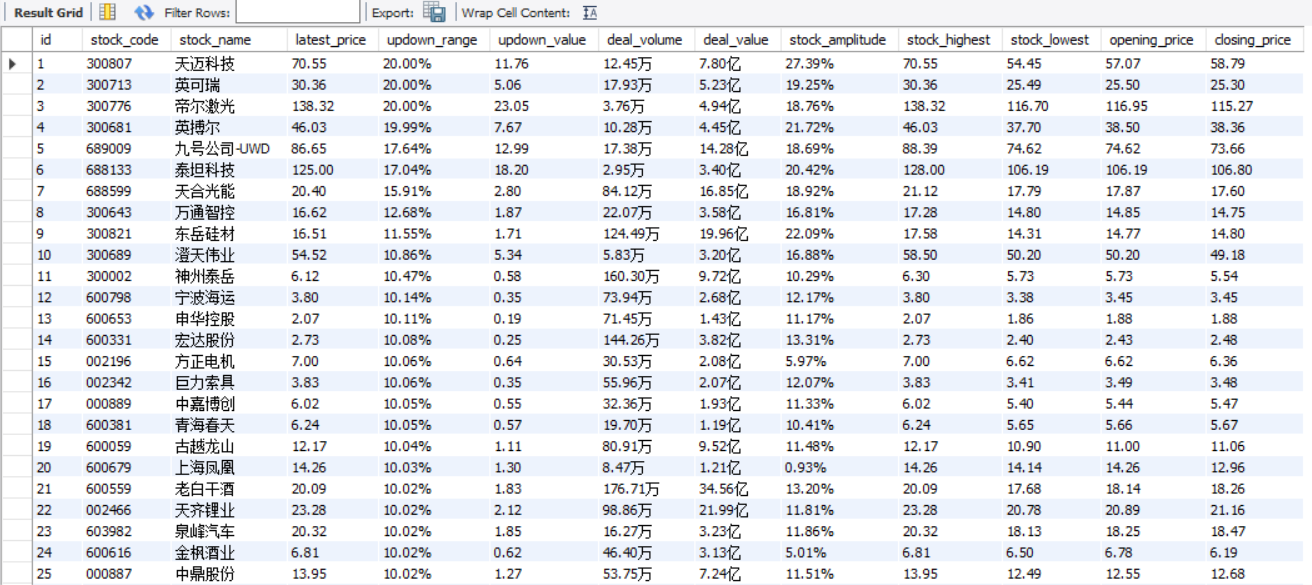
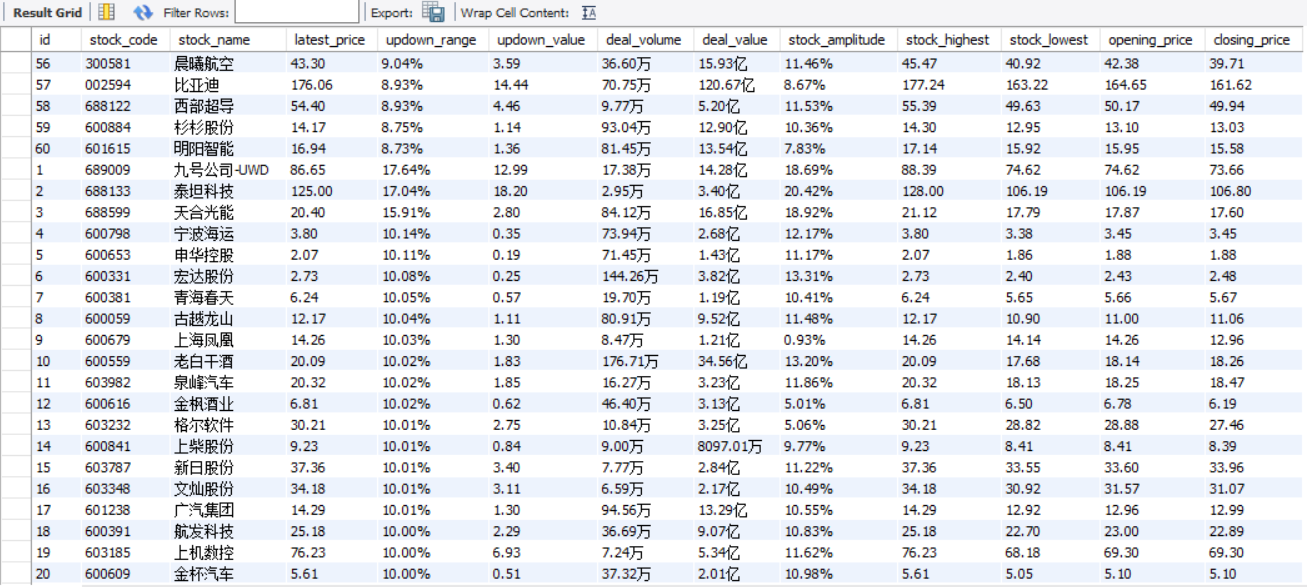
2)心得体会:
本次实验再一次练习了Selenium+MySQL,与之前的实验相比新增的操作就是板块的切换操作,这里通过定位板块位置模拟点击进行切换,其中定位板块位置我利用的是标签对的文本信息。在这次实验中我还练习了如何利用select语句以及fetchall()方法再结合格式化输出语句进行数据库数据的控制台展现。
作业③
1)爬取中国mooc网课程资源信息实验
-
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介) -
候选网站:中国mooc网:https://www.icourse163.org
程序思路要点:
- 定位页面按钮点击进入到登录窗口
- 切换iframe到登录窗口输入用户密码进行登录
- 定位搜索框,输入指定关键词进行搜索
- 定位所有课程条目,逐一进行模拟点击,进行浏览器窗口切换操作
- 定位翻页按钮进行翻页操作
- 设计等待方法使每一页面内容得以完整加载
- 设计数据解析方法解析所需提取的数据
- 数据库存储操作
代码:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
import time
import random
import pymysql
import re
import warnings
warnings.filterwarnings('ignore')
class SpiderMooc(object):
def __init__(self):
# option = webdriver.FirefoxOptions()
# option.add_argument('--headless') # 静默模式
# self.browser = webdriver.Firefox(options=option) # 创建浏览器对象
self.browser = webdriver.Firefox() # 创建浏览器对象
self.start_url = "https://www.icourse163.org" # 起始网址
self.pagenum = 2 # 设置爬取页数
self.wait_time = 5 # 设置利用selenium执行操作后的等待时间
def log_in(self):
'''模拟用户登录'''
while True: # 直到定位到登录按钮
try:
login_button = self.browser.find_element_by_xpath('//div[@class="unlogin"]/a')
break
except:
print("The login button cannot be located, please try to wait")
time.sleep(self.wait_time)
login_button.click()
locator = (By.XPATH, '//span[@class="ux-login-set-scan-code_ft_back"]')
WebDriverWait(driver=self.browser, timeout=10, poll_frequency=0.5) \
.until(EC.presence_of_all_elements_located(locator)) # 直到返回值为True
other_methods = self.browser.find_element_by_xpath('//span[@class="ux-login-set-scan-code_ft_back"]')
other_methods.click()
self.get_complete_onepage()
iframe = self.browser.find_element_by_tag_name("iframe")
self.browser.switch_to.frame(iframe)
email = self.browser.find_element_by_name("email")
email.send_keys(input('please input your email:\n'))
self.simulate_human()
password = self.browser.find_element_by_name("password")
password.send_keys(input('please input your password:\n'))
self.simulate_human()
# 模拟使用回车键进行登录
password.send_keys(Keys.ENTER)
# 释放iframe,重新回到主页面上操作
self.browser.switch_to.default_content()
self.get_complete_onepage()
def search_keywords(self,keywords):
'''搜索指定关键词keywords'''
while True: # 直到定位到输入框
try:
input_box = self.browser.find_element_by_name("search") # 定位输入框
break
except:
print("The input box cannot be located, please try to wait")
time.sleep(self.wait_time)
input_box.send_keys(keywords) # 支持中文
self.simulate_human()
input_box.send_keys(Keys.ENTER) # 模拟回车键
def get_complete_onepage(self):
'''获取完整页面'''
time.sleep(self.wait_time)
def simulate_human(self):
'''模拟人工操作'''
simulation_time = random.uniform(0.2, 1) # 模拟人工操作的时间
time.sleep(simulation_time)
def switch_new_window(self):
'''切换至新视窗'''
new_window = self.browser.window_handles[-1] # 返回最新句柄(所有句柄的最后一个)
# 切换到当前最新打开的窗口
self.browser.switch_to.window(new_window)
def switch_orgin_window(self):
'''切换至原视窗'''
self.browser.close() # 关闭当前视窗
orgin_window = self.browser.window_handles[0] # 返回原始句柄(所有句柄的第一个)
self.browser.switch_to.window(orgin_window) # 切换至原视窗
def turn_page(self):
'''执行翻页操作'''
try:
next_page = self.browser.find_element_by_xpath('//li[contains(@class,"next")]/a[@class="th-bk-main-gh"]') # 定位
next_page.click() # 点击
except NoSuchElementException: # 如果定位不到翻页按钮元素
print("The last page has been reached, no more pages can be turned")
except Exception as err:
print(err)
def db_init(self):
'''初始化数据库参数'''
self.host = '127.0.0.1' # MYSQL服务器地址
self.port = 3306 # MYSQL服务器端口号
self.user = 'root' # 用户名
self.passwd = "passwd" # 密码
self.db = 'spider_db' # 数据库名称
self.charset = 'utf8' # 连接编码
self.table = 'mooc' # 设置表名
def create_db(self):
'''建立数据库'''
try:
conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
charset=self.charset)
cursor = conn.cursor()
sql_crdb = "create database if not exists {}".format(self.db)
cursor.execute(sql_crdb)
print("数据库{}已创建".format(self.db))
except Exception as err:
print(err)
def build_table(self):
'''构建表结构'''
try:
self.con = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset=self.charset)
self.cursor = self.con.cursor() # 使用连接对象获得cursor对象
# 如果表存在则删除
sql_drop = 'drop table if exists {}'.format(self.table)
self.cursor.execute(sql_drop)
# 如果表不存在则创建,由于之前进行删表操作,所以这里会创建新表
sql_create = 'create table if not exists {}('.format(self.table) + \
"Id int," + \
"cCourse varchar(256)," + \
"cCollege varchar(32)," + \
"cTeacher varchar(32)," + \
"cTeam varchar(256)," + \
"cCount varchar(32)," + \
"cProcess varchar(256)," + \
"cBrief varchar(1024))"
self.cursor.execute(sql_create)
# 清空表中记录
# sql_delete = "delete from {}".format(self.table)
# self.cursor.execute(sql_delete)
except Exception as err:
print(err)
def insert_table(self,item):
'''按特定格式向表中插入数据'''
try:
sql_insert = "insert into {} (Id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) " \
"values(%s,%s,%s,%s,%s,%s,%s,%s)".format(self.table)
self.cursor.execute(sql_insert,(item["id"], item['course'], item['college'], item['teacher'],
item['team'], item['count'], item['process'], item["brief"]))
except Exception as err:
print(err)
def close(self):
'''关闭数据库及当前窗口'''
try:
self.con.commit() # 用于将事务所做的修改保存到数据库
self.con.close() # 断开数据库连接
self.browser.close() # 关闭当前窗口
except Exception as err:
print(err)
def process_datas(self):
'''处理多页数据'''
# 初始化
item = {} # 数据项目字典
item["id"] = 0 # Id
# 遍历指定多页
for page in range(1,self.pagenum+1):
self.get_complete_onepage() # 获取完整页面信息
div_list = self.browser.find_elements_by_xpath('//div[contains(@class,"u-clist")]')
for div in div_list:
div.click()
self.switch_new_window()
self.get_complete_onepage()
# Id
item["id"] += 1
# cCourse
item["course"] = self.browser.find_element_by_xpath('//span[starts-with(@class,"course-title")]').text
# cCollege
item["college"] = self.browser.find_element_by_xpath('//img[@class="u-img"]').get_attribute('alt')
# cTeacher and cTeam
teacher_title = self.browser.find_element_by_xpath('//div[@class="m-teachers_teacher-list"]/div').text
teacher_num = int(re.findall('\d+',teacher_title)[0]) # 正则表达式提取数字
h3_list = self.browser.find_elements_by_xpath('//div[@data-cate]//h3')
item["teacher"] = h3_list[0].text # cTeacher
item["team"] = ','.join([h3.text for h3 in h3_list]) if len(h3_list) == teacher_num \
else ','.join([h3.text for h3 in h3_list]) + '...' # cTeam
# cCount
count_text = self.browser.find_element_by_xpath('//span[contains(@class,"enroll-count")]').text
item["count"] = re.findall('\d+',count_text)[0] # 正则表达式提取数字
# cProcess
item["process"] = self.browser.find_element_by_xpath('//div[contains(@class,"term-time")]/span[last()]').text
# cBrief
item["brief"] = self.browser.find_element_by_id("j-rectxt2").text
# 切换回原窗口
self.switch_orgin_window()
yield item
print("第{}条课程信息爬取完成".format(item["id"]))
if page < self.pagenum: # 最后一页无需翻页
self.turn_page()
def execute_spider(self):
'''执行爬虫'''
print("Start the crawler")
# 打开预设网址
self.browser.get(self.start_url)
print("Open preset url")
use_login = True # 设置是否登录
if use_login:
print("Please pay attention to enter the account password in the console")
self.log_in()
# 初始化数据库
print("Initializing")
self.db_init()
self.create_db()
self.build_table()
# 搜索指定关键词
keywords = "python"
print("Searching for keywords:{}".format(keywords))
self.search_keywords(keywords)
# 处理指定课程多页数据
print("Processing data")
datas_generator = self.process_datas() # 返回generator对象
for item in datas_generator:
# 插入数据到数据库
self.insert_table(item)
# 关闭数据库连接以及当前窗口
print("Closing")
self.close()
print("Finished")
if __name__ == "__main__":
start = time.clock()
spider = SpiderMooc()
spider.execute_spider()
end = time.clock()
print('Running time: {} Seconds'.format(end - start))
运行结果部分截图:
控制台输出
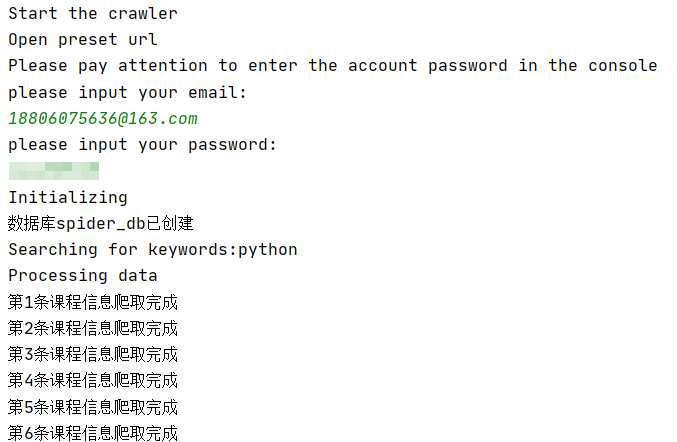

数据库存储
2)心得体会:
爬取MOOC课程资源信息实验算是这次大作业中最考验selenium技术含量的一个实验了,展现出了selenium的魅力所在——模拟真实用户操作。这里模拟了用户登录,重点利用了switch_to.frame方法,由于iframe标签对的特殊性,如果不进行切换frame操作是无法定位其中的元素的。
通过f12对源码进行分析,可以看出模拟登录操作所要定位的账号密码栏就存储在iframe标签对中:
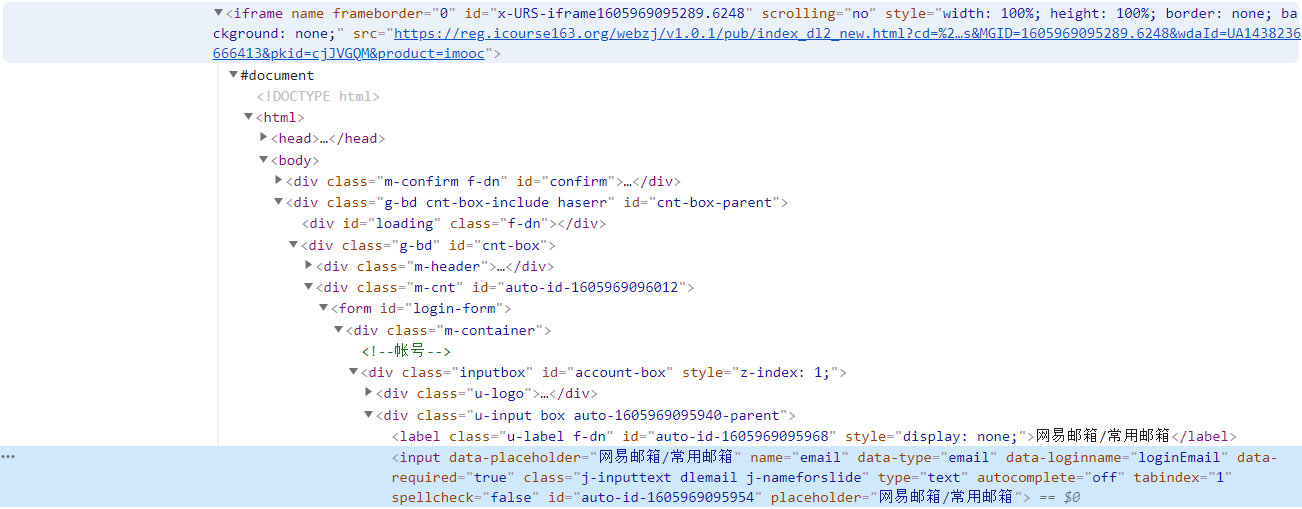
切换frame操作要注意的一点是释放iframe,重新回到主页面上操作
self.browser.switch_to.default_content()
还有这次切换窗口也是比较有意思的一个操作,模拟点击课程条目之后浏览器会弹出新的窗口,产生新的句柄,如果不切换窗口则浏览器当前网页句柄依旧不变,还是在原窗口进行操作,这里利用switch_to.window方法进行句柄切换操作,切换到新窗口以及切换回原窗口定义的方法如下:
def switch_new_window(self):
'''切换至新视窗'''
new_window = self.browser.window_handles[-1] # 返回最新句柄(所有句柄的最后一个)
# 切换到当前最新打开的窗口
self.browser.switch_to.window(new_window)
def switch_orgin_window(self):
'''切换至原视窗'''
self.browser.close() # 关闭当前视窗
orgin_window = self.browser.window_handles[0] # 返回原始句柄(所有句柄的第一个)
self.browser.switch_to.window(orgin_window) # 切换至原视窗
这里需要注意的是准备切换至原视窗时最好先关闭当前视窗,否则浏览器打开的窗口过多造成资源的浪费。
然后这次实验我还尝试了一下利用随机数使程序等待一段随机的时间模拟真实用户操作,关于反反爬方面还有很多值得探索的吧。
idea:“爬虫三境界”:
1、数据解析提取、元素定位、存储、展示
2、各种模拟用户操作、页面跳转
3、反反爬(确保爬取成功的关键所在,尤其使面对反爬机制强大的网站)
自己目前在获取到的页面源代码中进行数据解析提取以及元素定位还是比较有信心,模拟用户操作和反反爬方面还有待进一步的学习提高~
tips:本次实验中模拟的用户登录,所支持的是默认的邮箱登录方式。如果需要支持其他登录方式则需在代码中再加入定位、模拟键盘事件操作。由于技巧相似,时间原因没有在代码中体现。
小插曲:
1、强制等待使得爬虫程序不那么稳定,尤其是在设置的睡眠时间比较短的情况下,遇到过几次刚刚运行成果再运行却失败的情况,为了提高程序稳定性我决定加大睡眠时间,例如爬取mooc时统一设置为5s。
2、看网络上太多人使用chrome浏览器来进行爬虫工作,自己这次也配置了一个(虽然这次还是使用firefox驱动,因为在爬虫工作中没有明显差别吧),记录一下对此有帮助的博客:
selenium使用chrome浏览器测试
Selenium环境变量配置(火狐浏览器)及验证
