

网络爬虫第四次作业——Scrapy+Xpath+MySQL
作业①:
1)爬取当当网站图书数据实验
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
- 候选网站:http://www.dangdang.com/
程序思路要点:
- 确定搜索关键词,拼接成完整url作为入口函数参数
- 确定要爬取的数据项在items模块体现
- 确定各个数据项的解析方法在爬虫程序的parse函数中体现
- 确定翻页方法以及爬取页数在爬虫程序的parse函数中体现
- 确定数据库存储方式在pipelines模块中体现
- 配置项目对应的settings.py文件
代码:
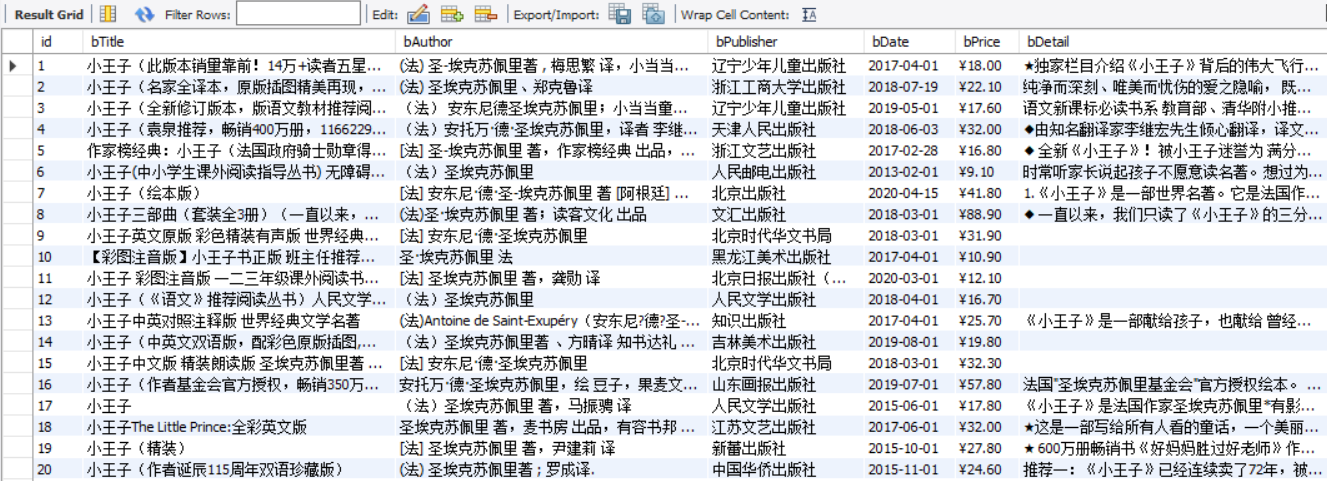
- items.py(数据项目类)
import scrapy
class BookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
pass
- mySpider.py(spiders文件夹下的爬虫程序)
import scrapy
from dangdang.items import BookItem # 项目名为dangdang,导入dangdang项目中的items模块,items模块在上级目录中
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider" # 爬虫程序名称
key = "小王子" # 搜索关键词
sourse_url = "http://search.dangdang.com/" # 当当网初始url
pagenum = 10 # 设置爬取页数
count = 1
def start_requests(self):
'''程序入口函数'''
url = MySpider.sourse_url + "?key=" + MySpider.key # 拼接url,搜索关键词key
yield scrapy.Request(url=url,callback=self.parse) # 回调函数parse
def parse(self,response):
'''解析函数/回调函数'''
try:
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data) # 装载html文档,形成一个selector对象
# 选取所有拥有sku属性且class属性值开始位置包含'line'关键字的页面元素
li_list = selector.xpath("//li['@sku'][starts-with(@class,'line')]") # 返回值是selector对象列表
for li in li_list: # li是selector对象
# 选取属于li标签下的第一个a标签的title属性值,以string形式返回
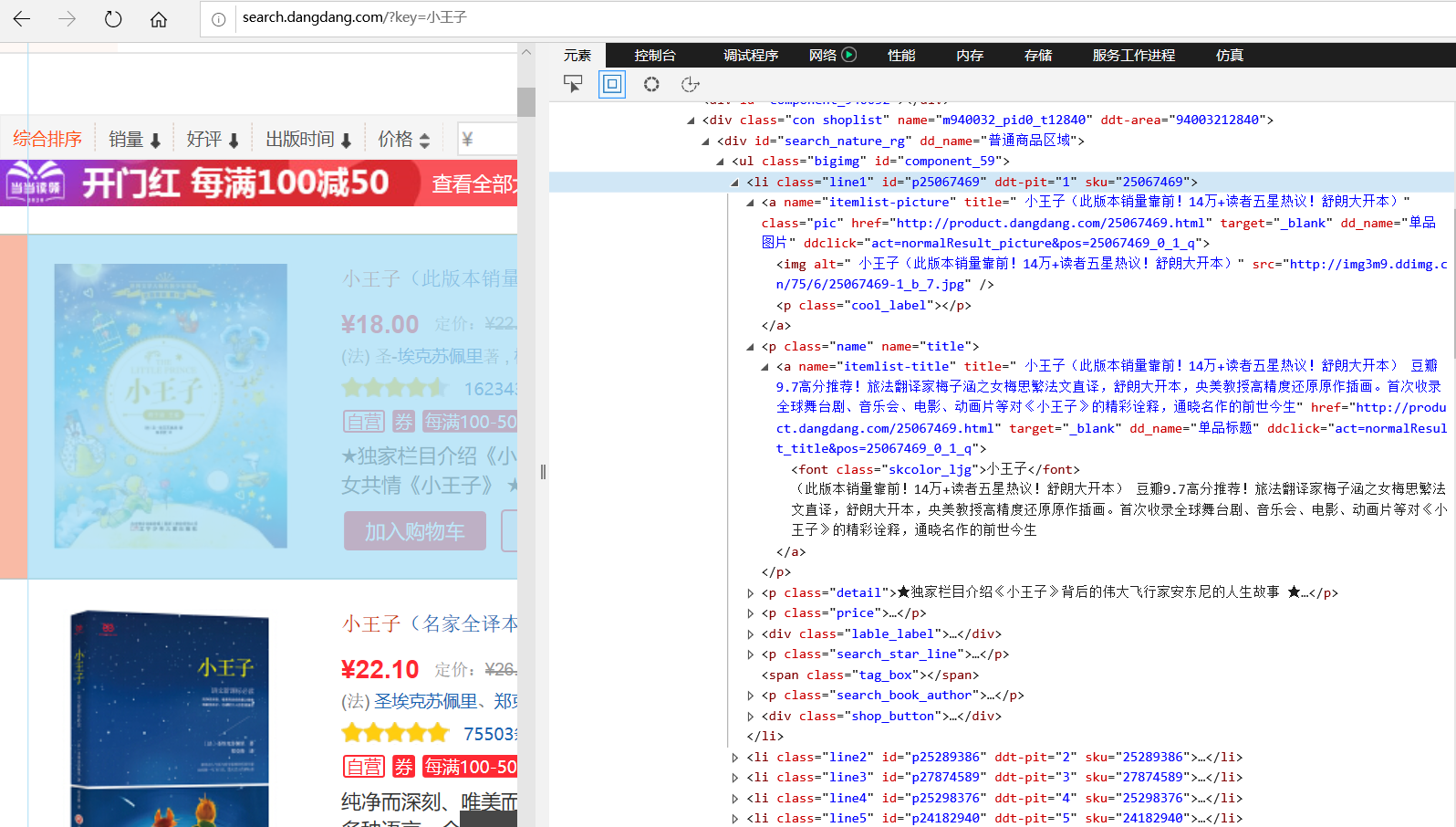
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first() # detail有时没有,结果为NONE
item = BookItem()
item["title"] = title.strip() if title else "" # 如果title值非空时去除空格存储,否则赋值为空字符
item["price"] = price.strip() if price else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else "" # date样式如"/2017-04-01",跳过第一个字符进行存储
item["publisher"] = publisher.strip() if publisher else ""
item["detail"] = detail.strip() if detail else ""
yield item # 生成器,向pipeline发送数据
# 解析出下一页的相对路径,最后一页时由于没有下一页,link为NONE
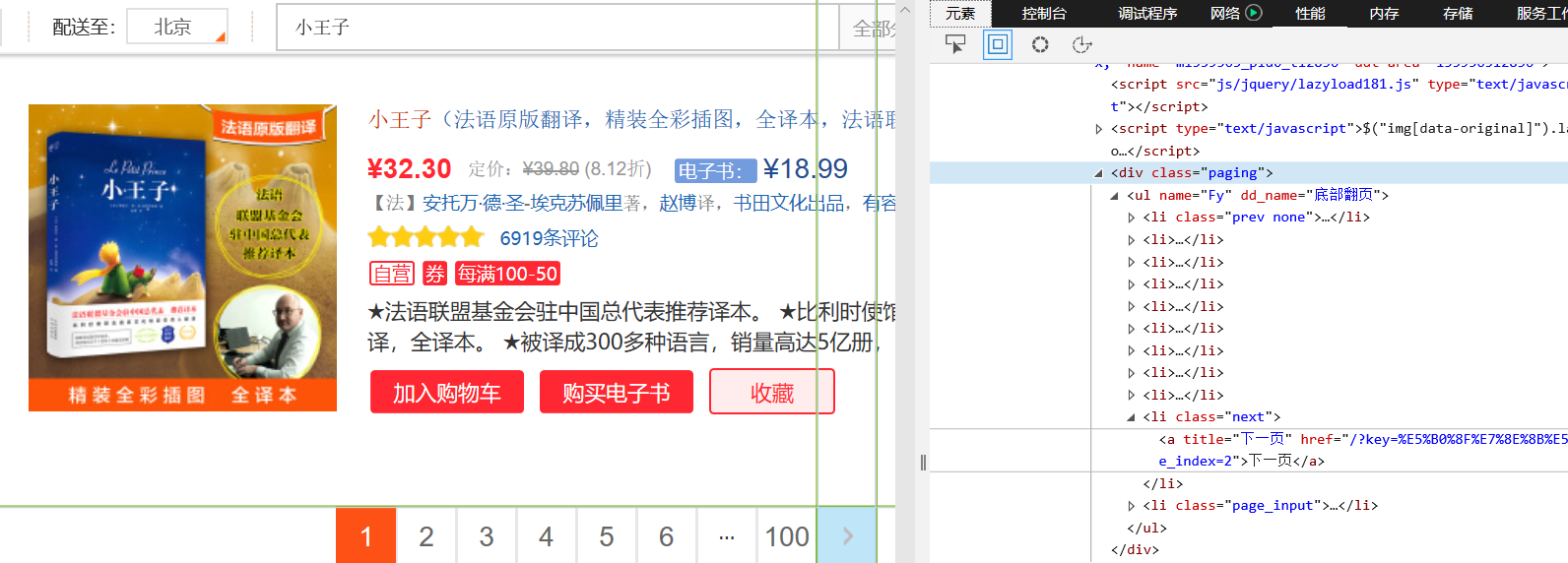
link = selector.xpath("//div[@class='paging']/ul[@dd_name='底部翻页']/li[@class='next']/a/@href").extract_first()
if link and self.count < self.pagenum: # 如果link不为NONE,且还未达到目标爬取页数
self.count += 1
# response对象的urljoin方法,拼接url成绝对路径(还可以使用urlparse的urljoin方法)
url = response.urljoin(link)
yield scrapy.Request(url=url,callback=self.parse) # 生成器不断发出新的url请求,并调用回调函数self.parse处理response
except Exception as err:
print(err)
- pipelines.py(数据管道处理类)
from itemadapter import ItemAdapter
import pymysql # 引入pymysql操作mysql数据库
class BookPipeline:
def db_init(self):
self.host = '127.0.0.1' # MYSQL服务器地址
self.port = 3306 # MYSQL服务器端口号
self.user = 'root' # 用户名
self.passwd = "passwd" # 密码
self.db = 'spider_db' # 数据库名称
self.charset = 'utf8' # 连接编码
self.table = 'books'
def create_db(self):
try:
conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
charset=self.charset)
cursor = conn.cursor()
sql_crdb = "create database if not exists {}".format(self.db)
cursor.execute(sql_crdb)
print("数据库{}已创建".format(self.db))
except Exception as err:
print(err)
# 当爬虫开始工作的时候执行一次,即爬虫执行开始的时候回调open_spider
def open_spider(self,spider):
print("opened")
try:
self.db_init() # 初始化数据库相关信息
self.create_db() # 如果数据库不存在则创建
self.con = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset=self.charset)
self.cursor = self.con.cursor() # 使用连接对象获得cursor对象,接下来使用cursor提供的方法工作(pymysql.cursors.DictCursor)
# 如果表存在则删除
sql_drop = 'drop table if exists {}'.format(self.table)
self.cursor.execute(sql_drop)
# 如果表不存在则创建,由于之前进行删表操作,所以这里会创建新表
sql_create = 'create table if not exists {}('.format(self.table) + \
"id int primary key auto_increment," + \
"bTitle varchar(512)," + \
"bAuthor varchar(256)," + \
"bPublisher varchar(256)," + \
"bDate varchar(32)," + \
"bPrice varchar(16)," + \
"bDetail text)" # 注意避免Duplicate entry导致主键值相同的不同商品信息丢失
self.cursor.execute(sql_create)
sql_delete = "delete from {}".format(self.table) # 清空表中记录
self.cursor.execute(sql_delete)
print("清空数据库数据")
self.opened = True
self.count = 0 # 记录爬取数据条目数
except Exception as err:
print(err)
self.opened = False
# 处理每条数据
def process_item(self, item, spider):
try:
self.count += 1
print(self.count,item['title'])
if self.opened: # 数据库连接处于打开状态
sql_insert = "insert into {} (id,bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values(%s,%s,%s,%s,%s,%s,%s)"\
.format(self.table)
self.cursor.execute(sql_insert,(self.count,item['title'],item['author'],item['publisher'],
item['date'],item['price'],item['detail']))
except Exception as err:
print(err)
return item
# 爬虫程序结束的时候执行一次,即当爬虫程序执行结束的时候回调close_spider
def close_spider(self,spider):
if self.opened:
self.con.commit() # 用于将事务所做的修改保存到数据库
# self.cursor.execute("select * from {}".format(self.table))
# print(self.cursor.fetchall()) # 输出表中信息
self.con.close() # 断开数据库连接
self.opened = False
print("closed")
print("总共爬取{}本书籍".format(self.count))
- settings.py(配置文件)
BOT_NAME = 'dangdang'
SPIDER_MODULES = ['dangdang.spiders']
NEWSPIDER_MODULE = 'dangdang.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'dangdang.pipelines.BookPipeline': 300,
}
- run.py(执行爬虫程序)
from scrapy import cmdline
command = "scrapy crawl mySpider -s LOG_ENABLED=False"
cmdline.execute(command.split())
运行结果部分截图:
控制台输出


数据库存储
2)心得体会:
确定各个数据项的解析方法:
确定翻页方法:
我从这次实验中加深了对scrapy框架的理解:例如其中items模块是确定所要提取的数据项目,爬虫程序parse方法的任务就是设计解析规则解析出items模块确定的数据项目,pipelines模块负责进一步处理items数据项目进行展现、存储。数据库存储方面,学会了如何利用pymysql模块去与MYSQL数据库建立连接并进行增删改查等操作,并经过设计使得对数据库操作的这部分代码可复用性比较高,后续实验的对数据库操作的代码部分基本上就是这边的移植(修改了部分参数)。xpath应用方面,书本、PPT、CSDN都给了我很大的帮助,xpath真是一个很灵活的解析手段。
作业②:
1)爬取股票相关信息实验
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
- 候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
程序思路要点:
- 确定要爬取的数据项在items模块体现
- 确定各个数据项的解析方法在parse函数中用xpath实现
- 确定翻页方法,这里应用selenium模拟点击实现翻页
- 确定数据在控制台的展现方式在pipelines模块中实现
- 确定数据库存储方式在pipelines模块中实现
- 配置项目对应的settings.py文件
代码:
- items.py(数据项目类)
class EastmoneyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序号
id = scrapy.Field()
# 股票代码
stock_code = scrapy.Field()
# 股票名称
stock_name = scrapy.Field()
# 最新报价
latest_price = scrapy.Field()
# 涨跌幅
updown_range = scrapy.Field()
# 涨跌额
updown_value = scrapy.Field()
# 成交量
deal_volume = scrapy.Field()
# 成交额
deal_value = scrapy.Field()
# 振幅
stock_amplitude = scrapy.Field()
# 最高
stock_highest = scrapy.Field()
# 最低
stock_lowest = scrapy.Field()
# 今开
opening_price = scrapy.Field()
# 昨收
closing_price = scrapy.Field()
pass
- SpiderStock.py(spiders文件夹下的爬虫程序)
import scrapy
from EastMoney.items import EastmoneyItem
from selenium import webdriver
import time
class SpiderStock(scrapy.Spider):
name = "SpiderEastmoney"
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
browser = webdriver.Firefox() # 声明浏览器
pagenum = 3 # 设置爬取页数
# sections = ['#sh_a_board','#sz_a_board'] # 设置更多爬取板块
# option = webdriver.FirefoxOptions()
# option.add_argument('--headless') # 静默模式
# browser = webdriver.Firefox(options=option) # 若不设置options采用默认配置,可以看到selenium驱动浏览器操作过程
def turn_page(self):
'''执行翻页操作'''
try:
button = self.browser.find_element_by_xpath("//div[@id='main-table_paginate']/a[@class='next paginate_button']")
button.click() # 点击操作
time.sleep(5) # 等待,确保下一页网页内容加载成功
except Exception as err:
print(err) # Unable to locate element
print("The number of crawled pages may exceed the upper limit") # 爬取页数超过上限
def start_requests(self):
'''程序入口函数'''
yield scrapy.Request(url=self.url,callback=self.parse)
def parse(self, response):
'''回调函数/解析函数'''
try:
self.browser.get(response.url) # 打开浏览器预设网址
for page in range(self.pagenum):
selector = scrapy.Selector(text=self.browser.page_source)
# 每个股票信息存储在tr标签对中
tr_list = selector.xpath("//div[@class='listview full']/table/tbody/tr")
for tr in tr_list:
item = EastmoneyItem()
item["id"] = tr.xpath("./td[position()=1]/text()").extract_first()
item["stock_code"] = tr.xpath("./td[position()=2]/a/text()").extract_first()
item["stock_name"] = tr.xpath("./td[position()=3]/a/text()").extract_first()
item["latest_price"] = tr.xpath("./td[position()=5]/span/text()").extract_first()
item["updown_range"] = tr.xpath("./td[position()=6]/span/text()").extract_first()
item["updown_value"] = tr.xpath("./td[position()=7]/span/text()").extract_first()
item["deal_volume"] = tr.xpath("./td[position()=8]/text()").extract_first()
item["deal_value"] = tr.xpath("./td[position()=9]/text()").extract_first()
item["stock_amplitude"] = tr.xpath("./td[position()=10]/text()").extract_first()
item["stock_highest"] = tr.xpath("./td[position()=11]/span/text()").extract_first()
item["stock_lowest"] = tr.xpath("./td[position()=12]/span/text()").extract_first()
item["opening_price"] = tr.xpath("./td[position()=13]/span/text()").extract_first()
item["closing_price"] = tr.xpath("./td[position()=14]/text()").extract_first()
yield item
if page < self.pagenum-1: # 最后一页无需点击按钮进行翻页
self.turn_page()
except Exception as err:
print(err)
- pipelines.py(数据管道处理类)
from itemadapter import ItemAdapter
import pymysql
class EastmoneyPipeline:
titles = ["序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额",
"成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"]
def db_init(self):
self.host = '127.0.0.1' # MYSQL服务器地址
self.port = 3306 # MYSQL服务器端口号
self.user = 'root' # 用户名
self.passwd = "passwd" # 密码
self.db = 'spider_db' # 数据库名称
self.charset = 'utf8' # 连接编码
self.table = 'stock'
def create_db(self):
try:
conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
charset=self.charset)
cursor = conn.cursor()
sql_crdb = "create database if not exists {}".format(self.db)
cursor.execute(sql_crdb)
print("数据库{}已创建".format(self.db))
except Exception as err:
print(err)
# 当爬虫开始工作的时候执行一次,即爬虫执行开始的时候回调open_spider
def open_spider(self, spider):
print("opened")
try:
self.db_init() # 初始化数据库相关信息
self.create_db() # 如果数据库不存在则创建
self.con = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset=self.charset)
self.cursor = self.con.cursor() # 使用连接对象获得cursor对象,接下来使用cursor提供的方法工作(pymysql.cursors.DictCursor)
# 如果表存在则删除
sql_drop = 'drop table if exists {}'.format(self.table)
self.cursor.execute(sql_drop)
# 如果表不存在则创建,由于之前进行删表操作,所以这里会创建新表
sql_create = 'create table if not exists {}('.format(self.table) + \
"id int primary key auto_increment," + \
"stock_code varchar(32)," + \
"stock_name varchar(32)," + \
"latest_price varchar(32)," + \
"updown_range varchar(32)," + \
"updown_value varchar(32)," + \
"deal_volume varchar(32)," + \
"deal_value varchar(32)," + \
"stock_amplitude varchar(32)," + \
"stock_highest varchar(32)," + \
"stock_lowest varchar(32)," + \
"opening_price varchar(32)," + \
"closing_price varchar(32))"
self.cursor.execute(sql_create)
sql_delete = "delete from {}".format(self.table) # 清空表中记录
self.cursor.execute(sql_delete)
print("清空数据库数据")
self.opened = True
except Exception as err:
print(err)
self.opened = False
# 处理每条数据
def process_item(self, item, spider):
try:
if self.opened: # 数据库连接处于打开状态
sql_insert = "insert into {} (id,stock_code,stock_name,latest_price,updown_range,updown_value," \
"deal_volume,deal_value,stock_amplitude,stock_highest,stock_lowest,opening_price,closing_price) " \
"values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)" .format(self.table)
self.cursor.execute(sql_insert, (int(item["id"]), item['stock_code'], item['stock_name'], item['latest_price'],
item['updown_range'], item['updown_value'], item['deal_volume'],item["deal_value"],
item["stock_amplitude"],item["stock_highest"],item["stock_lowest"],
item["opening_price"],item["closing_price"]))
self.show_data(item)
self.count = item["id"]
except Exception as err:
print(err)
return item
# 爬虫程序结束的时候执行一次,即当爬虫程序执行结束的时候回调close_spider
def close_spider(self, spider):
if self.opened:
self.con.commit() # 用于将事务所做的修改保存到数据库
# self.cursor.execute("select * from {}".format(self.table))
# print(self.cursor.fetchall()) # 输出表中信息
self.con.close() # 断开数据库连接
self.opened = False
print("closed")
print("总共爬取{}条股票信息".format(self.count))
def show_data(self,item):
if item["id"] == '1': # 第一次打印标题
pat = "{0:^2}\t{1:^7}\t{2:^7}\t{3:^7}\t{4:^7}\t{5:^7}\t{6:^7}\t{7:^7}\t{8:^7}\t{9:^7}\t{10:^7}\t{11:^7}\t{12:^7}"
titles = self.titles
print(pat.format(titles[0],titles[1],titles[2],titles[3],titles[4],titles[5],\
titles[6],titles[7],titles[8],titles[9],titles[10],titles[11],titles[12]))
pat = "{0:^3}\t{1:^8}\t{2:^8}\t{3:^8}\t{4:^8}\t{5:^8}\t{6:^8}\t{7:^8}\t{8:^8}\t{9:^8}\t{10:^8}\t{11:^8}\t{12:^8}"
print(pat.format((item["id"]), item['stock_code'], item['stock_name'], item['latest_price'],
item['updown_range'], item['updown_value'], item['deal_volume'],item["deal_value"],
item["stock_amplitude"],item["stock_highest"],item["stock_lowest"],
item["opening_price"],item["closing_price"]))
- settings.py(配置文件)
BOT_NAME = 'EastMoney'
SPIDER_MODULES = ['EastMoney.spiders']
NEWSPIDER_MODULE = 'EastMoney.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'EastMoney.pipelines.EastmoneyPipeline': 300,
}
- run.py(执行爬虫程序)
from scrapy import cmdline
command = "scrapy crawl SpiderEastmoney -s LOG_ENABLED=False"
cmdline.execute(command.split())
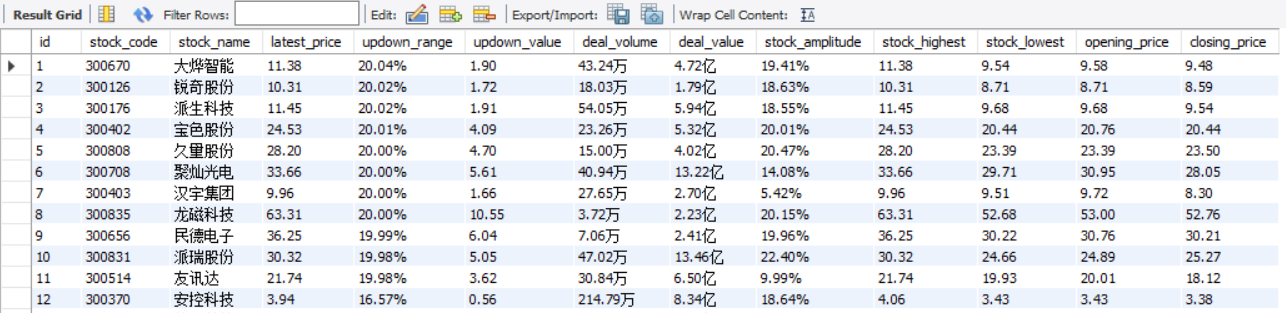
运行结果部分截图:
控制台输出
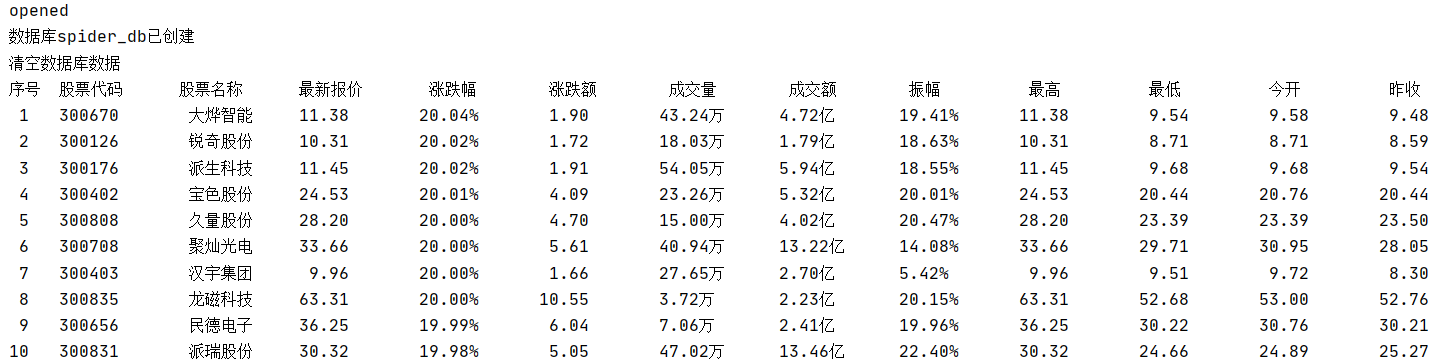

数据库存储
2)心得体会:
本次实验再一次练习了scrapy+xpath+MYSQL。所特殊的是selenium的应用,selenium是一个用于Web应用程序测试的工具。直接运行在浏览器中,就像真正的用户在操作一样。这边利用了selenium中的方法定位翻页按钮并点击进行翻页操作。归纳一下目前为止常用的四种翻页操作:1、人工比对不同页码的url字段变化找出规律。2、查看翻页按钮对应的源代码是否有新url链接可供拼接。3、开发者工具f12进行翻页过程中的抓包。4、selenium定位翻页按钮并进行点击操作。
- 补充:
1、scrapy+selenium的配合还可以在中间件middlewares中实现。可参考:
scrapy爬虫框架和selenium的配合使用
2、记录一篇对我这次配置selenium环境很有帮助的博客:
Selenium环境变量配置(火狐浏览器)及验证
作业③
1)爬取外汇网站数据实验
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
- 候选网站:招商银行网:http://fx.cmbchina.com/hq/
程序思路要点:
- 确定要爬取的数据项在items模块体现
- 确定各个数据项的解析方法在parse函数中用xpath实现
- 确定数据在控制台的展现方式,这里使用了prettytable
- 确定数据库存储方式在pipelines模块中实现
- 配置项目对应的settings.py文件
代码:
- items.py(数据项目类)
import scrapy
class CmbchinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
currency = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
time = scrapy.Field()
pass
- spider_cmbchina.py(spiders文件夹下的爬虫程序)
import scrapy
from cmbchina.items import CmbchinaItem
class MySpider(scrapy.Spider):
name = "SpiderCmbChina"
url = "http://fx.cmbchina.com/hq/"
def start_requests(self):
yield scrapy.Request(url=self.url,callback=self.parse)
def parse(self,response):
try:
html = response.body.decode()
selector = scrapy.Selector(text=html) # 装载html文档,形成一个selector对象
# 每一条外汇信息存储在一对tr标签中(其中未获取到tbody标签)
tr_list = selector.xpath("//div[@id='realRateInfo']/table/tr")
# 第一个tr标签对存储的是表头信息
for tr in tr_list[1:]:
currency = tr.xpath("./td[position()=1]/text()").extract_first()
tsp = tr.xpath("./td[position()=4]/text()").extract_first()
csp = tr.xpath("./td[position()=5]/text()").extract_first()
tbp = tr.xpath("./td[position()=6]/text()").extract_first()
cbp = tr.xpath("./td[position()=7]/text()").extract_first()
time = tr.xpath("./td[position()=8]/text()").extract_first()
item = CmbchinaItem()
item["currency"] = currency.strip() if currency else ""
item["tsp"] = tsp.strip() if tsp else ""
item["csp"] = csp.strip() if csp else ""
item["tbp"] = tbp.strip()if tbp else ""
item["cbp"] = cbp.strip() if cbp else ""
item["time"] = time.strip() if time else ""
yield item # 生成器,向pipeline发送数据
except Exception as err:
print(err)
- pipelines.py(数据管道处理类)
from itemadapter import ItemAdapter
import pymysql
from prettytable import PrettyTable
class CmbchinaPipeline:
pt = PrettyTable()
pt.field_names = ["Id","Currency","TSP","CSP","TBP","CBP","Time"]
def db_init(self):
self.host = '127.0.0.1' # MYSQL服务器地址
self.port = 3306 # MYSQL服务器端口号
self.user = 'root' # 用户名
self.passwd = "passwd" # 密码
self.db = 'spider_db' # 数据库名称
self.charset = 'utf8' # 连接编码
self.table = 'cmbchina'
def create_db(self):
try:
conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
charset=self.charset)
cursor = conn.cursor()
sql_crdb = "create database if not exists {}".format(self.db)
cursor.execute(sql_crdb)
print("数据库{}已创建".format(self.db))
except Exception as err:
print(err)
# 当爬虫开始工作的时候执行一次,即爬虫执行开始的时候回调open_spider
def open_spider(self, spider):
print("opened")
try:
self.db_init() # 初始化数据库相关信息
self.create_db() # 如果数据库不存在则创建
self.con = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset=self.charset)
self.cursor = self.con.cursor() # 使用连接对象获得cursor对象,接下来使用cursor提供的方法工作(pymysql.cursors.DictCursor)
# 如果表存在则删除
sql_drop = 'drop table if exists {}'.format(self.table)
self.cursor.execute(sql_drop)
# 如果表不存在则创建,由于之前进行删表操作,所以这里会创建新表
sql_create = 'create table if not exists {}('.format(self.table) + \
"Id int primary key auto_increment," + \
"Currency varchar(32)," + \
"TSP varchar(32)," + \
"CSP varchar(32)," + \
"TBP varchar(32)," + \
"CBP varchar(32)," + \
"Time varchar(32))" # 注意避免Duplicate entry导致主键值相同的不同商品信息丢失
self.cursor.execute(sql_create)
sql_delete = "delete from {}".format(self.table) # 清空表中记录
self.cursor.execute(sql_delete)
print("清空数据库数据")
self.opened = True
self.count = 0 # 记录爬取数据条目数
except Exception as err:
print(err)
self.opened = False
# 处理每条数据
def process_item(self, item, spider):
try:
self.count += 1
if self.opened: # 数据库连接处于打开状态
sql_insert = "insert into {} (Id,Currency,TSP,CSP,TBP,CBP,Time) values(%s,%s,%s,%s,%s,%s,%s)" \
.format(self.table)
self.cursor.execute(sql_insert, (self.count, item['currency'], item['tsp'], item['csp'],
item['tbp'], item['cbp'], item['time']))
self.pt.add_row(
[self.count, item['currency'], item['tsp'], item['csp'],
item['tbp'], item['cbp'], item['time']]
)
except Exception as err:
print(err)
return item
# 爬虫程序结束的时候执行一次,即当爬虫程序执行结束的时候回调close_spider
def close_spider(self, spider):
if self.opened:
self.con.commit() # 用于将事务所做的修改保存到数据库
# self.cursor.execute("select * from {}".format(self.table))
# print(self.cursor.fetchall()) # 输出表中信息
print(self.pt)
self.con.close() # 断开数据库连接
self.opened = False
print("closed")
print("总共爬取{}条外汇记录".format(self.count))
- settings.py(配置文件)
BOT_NAME = 'cmbchina'
SPIDER_MODULES = ['cmbchina.spiders']
NEWSPIDER_MODULE = 'cmbchina.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'cmbchina.pipelines.CmbchinaPipeline': 300,
}
- run.py(执行爬虫程序)
from scrapy import cmdline
command = "scrapy crawl SpiderCmbChina -s LOG_ENABLED=False"
cmdline.execute(command.split())
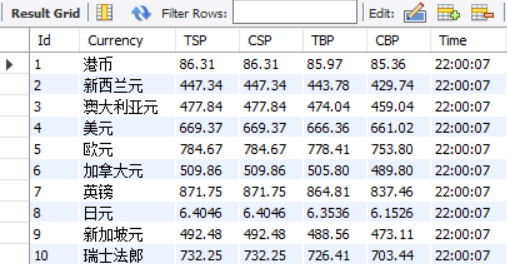
运行结果部分截图:
控制台输出
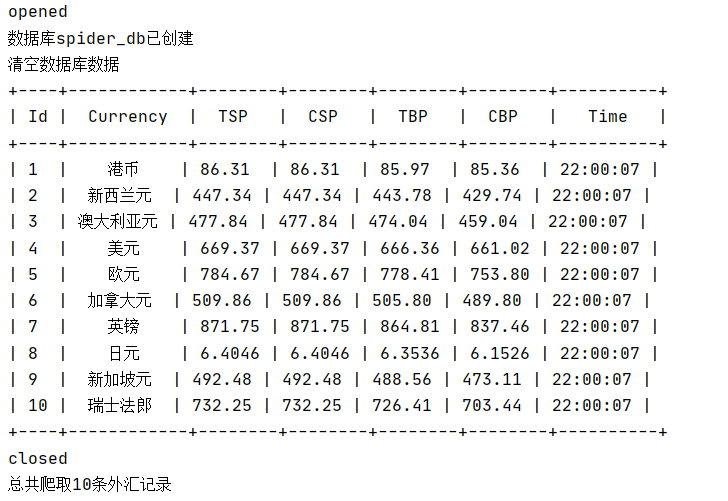
数据库存储
2)心得体会:
进一步强化了scrapy+xpath+MYSQL的使用。在数据展示环节练习了一下prettytable模块,由于存在中文字符,给prettytable的对齐带来了难度。

