

网络爬虫第二次作业——天气、股票
作业①:
1)爬取天气预报信息实验
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
程序主要思路:
代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
'''
没有设置共同属性,定义四个方法
open_db:创建数据库
close_db:关闭数据库
insert:向数据库中插入数据
show:按指定格式展示数据库内容
'''
def open_db(self):
self.con = sqlite3.connect("weathers.db") # SQLite3创建数据库,返回连接对象
self.cursor = self.con.cursor() # 使用连接对象获得cursor对象,接下来使用cursor提供的方法工作
try:
# 声明表的名字和所有字段的名字及其类型(大小写不敏感)
sql = "create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64), \
wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))" #主键约束(wCity,wDate)
self.cursor.execute(sql) # 执行单条sql语句,接收的参数为sql语句本身和使用的参数列表
except Exception as err:
print(err)
sql = "delete from weathers"
self.cursor.execute(sql)
def close_db(self):
self.con.commit() # COMMIT命令用于把事务所做的修改保存到数据库
self.con.close()
def insert(self,city,date,weather,temp):
try:
sql = "insert into weathers (wCity,wDate,wWeather,wTemp) values(?,?,?,?)"
self.cursor.execute(sql,(city,date,weather,temp))
except Exception as err:
print(err)
def show(self):
sql = "select * from weathers"
self.cursor.execute(sql)
rows = self.cursor.fetchall() # 通过fetchall得到的就是多行记录,是一个二维元组
# 格式化输出
form = "{0:^20}{1:^20}{2:^20}{3:^20}{4:^20}"
cn_blank = 2*chr(12288) #两个中文空格作为填充
titles = ["序号","地区","日期","天气信息","温度"]
print(form.format(titles[0],titles[1],titles[2],titles[3],titles[4],cn_blank))
num = 1
for row in rows:
print(form.format(num,row[0],row[1],row[2],row[3],cn_blank))
num += 1
class WeatherForecast:
'''
共同属性是UA头以及城市及其编码组成的字典,定义了三个方法
forecast_city:解析网页内容,读取给定城市的一周天气信息并写入数据库
build_db:将给定城市集的一周天气预报信息存入数据库
show_db:主要是展示数据库内容,调用WeatherDB的show方法
'''
def __init__(self,cityCode):
self.headers={
"User-Agent":"Mozilla/5.0" # 简单模拟浏览器
}
self.cityCode = cityCode
def forecast_city(self,city):
if city not in self.cityCode.keys():
print(city+"code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml" # 城市查询接口
try:
req = urllib.request.Request(url,headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data,["utf-8","gbk"]) # 猜测文档编码
data = dammit.unicode_markup
soup = BeautifulSoup(data,"html.parser")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
try: # 晚上爬取网页的时候会出现list out of range,原因是温度下缺少span标签对
temp = li.select('p[class="tem"] \
span')[0].text +"/" +li.select('p[class="tem"] i')[0].text
except IndexError:
temp = li.select('p[class="tem"] i')[0].text
self.db.insert(city,date,weather,temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def build_db(self):
self.db = WeatherDB()
self.db.open_db()
for city in self.cityCode.keys():
self.forecast_city(city)
def show_db(self):
self.db.show()
self.db.close_db()
if __name__ == "__main__":
cityCode = {"北京":"101010100","上海":"101020100", \
"福州":"101230101","三明":"101230801"} # 所选取的城市集
wf = WeatherForecast(cityCode)
wf.build_db()
wf.show_db()
运行结果部分截图:

代码主要是在书上所给代码的基础上做了一些改动,多次运行之后发现,晚上运行的时候会提示list out of range异常,控制台只会输出每个城市的6天数据(今天的消失了),去网站查看发现,晚上的时候当天的温度信息只出现一个值,原来在span标签对中的温度值消失了,可在解析数据的代码块中加入异常处理或者条件判断语句解决这个问题。
2)心得体会:
这次实验作业用到的解析技巧和第一次实验作业原理一致,都是通过直接观察网站html代码结构以及url字段然后运用betifulsoup提取特定标签对中的数据信息。特别的是有关数据库的操作,从这次实验中我学习了如何创建数据库并进行增删改查操作,部分代码的含义在注释中体现。
作业②:
1)爬取股票相关信息实验
要求:定向爬取股票相关信息(这里选取东方财富网)
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
程序主要思路:
代码:
import requests
import re
import pandas as pd
import os
class SpiderStock(object):
'''创建一个实现爬取东方财富网站的类'''
def __init__(self,fs_name):
'''设置共同属性'''
self.header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
} # UA伪装浏览器
self.fs_type = {
"沪深A股": "m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23",
"上证A股": "m:1+t:2,m:1+t:23",
"深证A股": "m:0+t:6,m:0+t:13,m:0+t:80"
} # 东方财富网行情中心的板块变化体现在fs字段,通过f12抓包可得以上编码,其余板块依此类推
self.dic = {
"股票代码": 'f12', "股票名称": 'f14', "最新报价": 'f2', "涨跌幅": 'f3',
"涨跌额": 'f4', "成交量": 'f5', "成交额": 'f6', "振幅": 'f7',
"最高": 'f15', "最低": 'f16', "今开": 'f17', "昨收": 'f18'
} # json网页中的字典键值对应含义
self.titles = ["序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额",
"成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"]
self.fs_code = self.fs_type[fs_name]
def get_html_text(self,url):
'''获取网址字符内容'''
req = requests.get(url, headers=self.header, timeout=30)
req.raise_for_status() # 若状态码不是200抛出HttpError异常
# req.encoding = req.apparent_encoding # 分析编码比较耗时,可手动设置
req.encoding = 'utf-8' # 手动设置编码方式
return req.text
def get_onepage_url(self,page):
'''获取网站指定板块号单页网址'''
url_page = "http://5.push2.eastmoney.com/api/qt/clist/get?pn={0:d}&pz=20&po=1&np=1".format(page)
url_fs = "&fltt=2&invt=2&fid=f3&fs={}&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18".format(self.fs_code)
url = url_page + url_fs
return url
def extract_infos(self,req_text):
'''从所有网页字符内容中提取所需信息范围'''
pattern = "\[(.*?)\]"
infos = re.compile(pattern,re.S).findall(req_text)[0] # 所有信息一次被匹配,findall方法返回的列表中有且只有一个字符串元素
return list(eval(infos)) # eval返回该字符串所代表的python对象(元组),为便于后续操作再将元组转化为列表
def format_data(self,info):
'''将不符合题目格式的原始量格式化'''
# pending_format = ["涨跌幅","成交量","成交额"]
try: # 实际运行过程可能会出现数据缺失的情况
info[self.dic["涨跌幅"]] = str(info[self.dic["涨跌幅"]]) + "%" # 更改为百分数形式
info[self.dic["成交量"]] = str('%.2f' %(info[self.dic["成交量"]]/1e4))+ "万" # 保留两位小数+单位
info[self.dic["成交额"]] = str('%.1f' %(info[self.dic["成交额"]]/1e8))+ "亿" # 保留一位小数+单位
return info
except:
return info
def get_datas(self,infos):
'''从单页所需信息范围中提取数据存为列表'''
datas = []
num = 1 # num为序号
for info in infos: # infos为元组,info为字典
info = self.format_data(info)
data = [num] # 初始化为序号
num += 1 # 序号递增
for value in self.dic.values():
data.append(info[value])
datas.append(data) # 二维列表,元素为由单个股票信息构成的列表
return datas
def get_pages_stock(self,pagenum):
'''整合上述方法,实现提取指定板块的多页股票信息'''
infos = []
for i in range(1,pagenum+1):
url = self.get_onepage_url(i)
html_text = self.get_html_text(url)
infos.extend(self.extract_infos(html_text)) # 利用列表的追加方法,整合多个由字典组成的列表
stock_datas = self.get_datas(infos)
return stock_datas
def write_excel(self,stock_datas,filename):
'''将提取数据写入本地excel文件'''
current_path = os.getcwd() # 获取当前路径,作为控制台输出提示
df = pd.DataFrame(stock_datas)
df.columns = self.titles
try:
df.to_excel(filename,index=False)
print("datas saved in {}".format(current_path))
except Exception as err:
print(err)
def show_results(self,stock_datas):
'''展现结果,格式话输出所提取的数据'''
df = pd.DataFrame(stock_datas)
df.columns = self.titles
pd.set_option('display.max_columns', len(self.titles)) # 设置显示的最大列数参数
pd.set_option('display.max_rows', 100) # 设置显示的最大的行数参数
pd.set_option('display.width', 200) # 设置的显示的宽度,防止轻易换行
print(df)
if __name__ == "__main__":
optional = ["沪深A股","上证A股","深证A股"]
spider = SpiderStock(optional[0]) # 设置爬取哪个板块
pagenum = 5 # 设置爬取页数
stock_datas = spider.get_pages_stock(pagenum)
filename = 'stock_datas.xlsx'
spider.write_excel(stock_datas, filename)
spider.show_results(stock_datas)
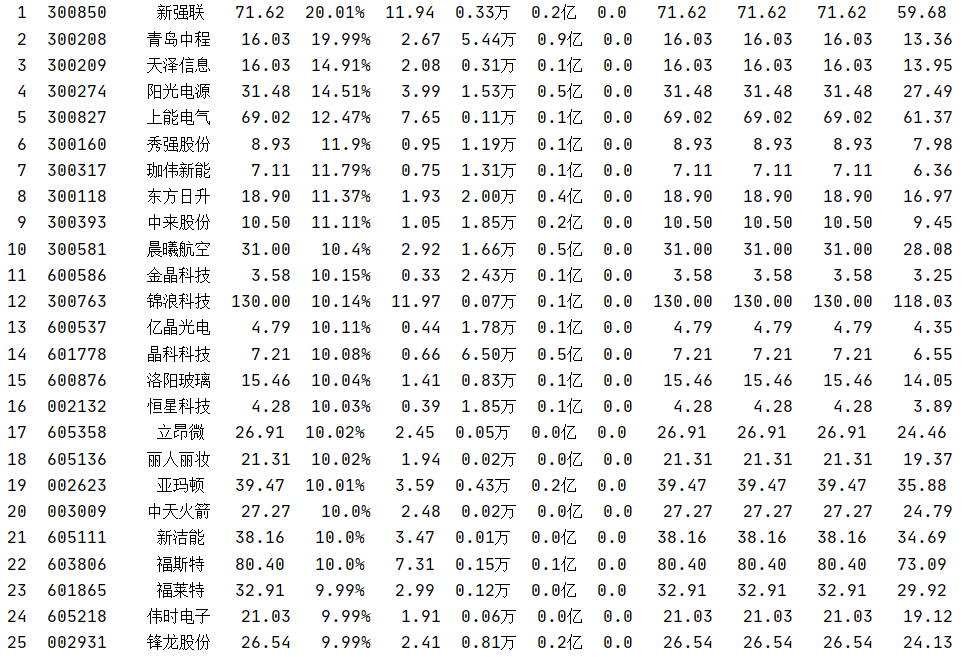
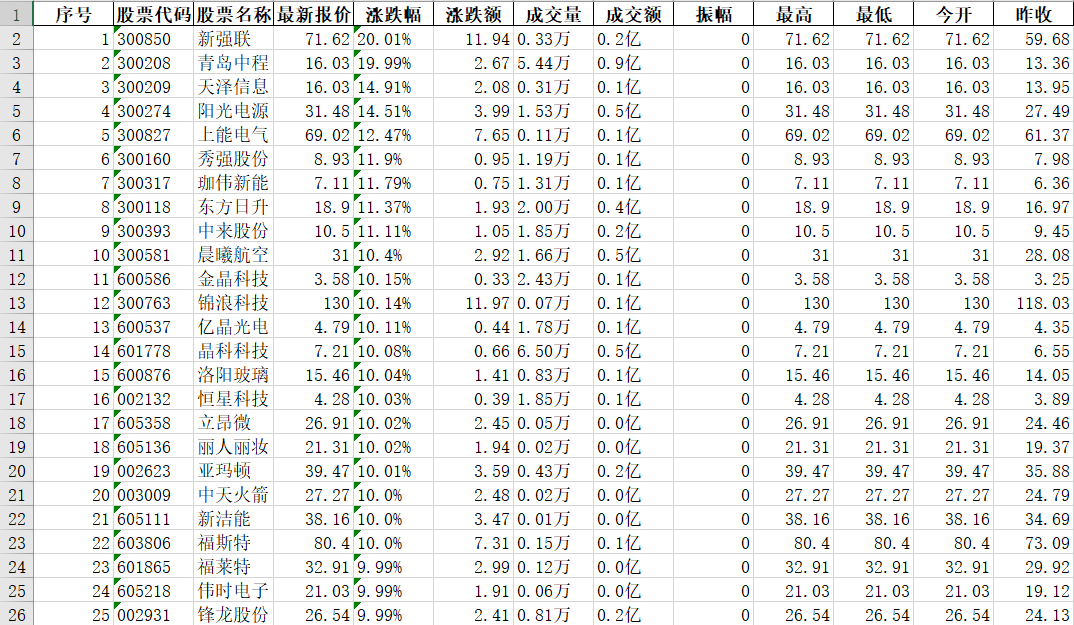
运行结果部分截图:
在工作日期间由于网页信息是动态变化的,所以程序运行结果也是动态变化的
控制台输出
excel保存
2)心得体会:
通过这次实验主要学会了如何通过网页调试工具(f12功能键)抓包来获取异步加载数据的网页信息。分析目标网站资源所在位置以及url参数信息是这次实验的重点,也是这次我花了最多时间去研究的地方。抓包方面,这次实验主要抓取的是json包,抓取之前进行"清除会话"操作(不同网页调试工具名称有所差异),抓取完毕点击"停止分析会话操作",然后查看各个会话包的大小以及字段名称可以帮助初步定位目标位置,再通过查看会话包的正文或者预览去与网页呈现信息比对可以判定是否是目标会话包。例如: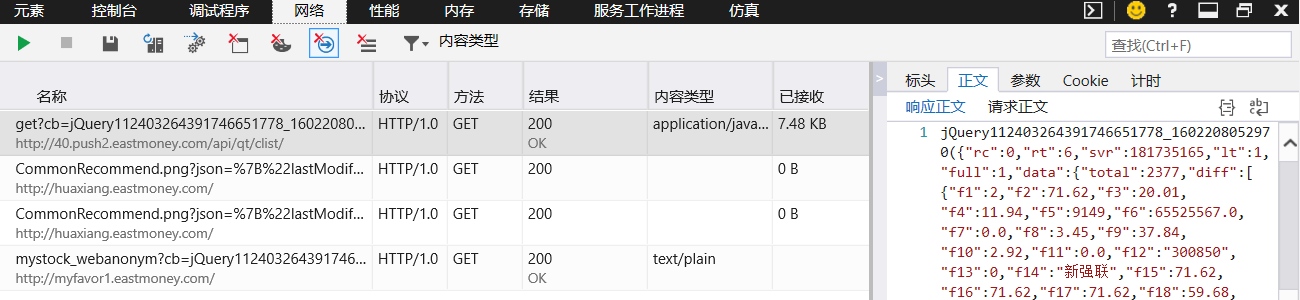
至于网页url比对方面,方法可以说是控制变量法去比对,例如页数字段(这里是pn),就是通过爬取同一板块不同页数的url去比对差异,板块字段(这里是fs),就是通过爬取不同板块以及同一板块的url比对去发现共性和差异。
另外,原url中通常都有很多冗余字段,可以通过多次试验进行删减。
tips(引用):
1、分析网页最重要的是要先找到url地址。之后再去弄懂各个参数的具体含义,扩展获取更多的数据。
2、分析过程中要细心,有耐心,多用查找功能。找不到了再到网页源码中看看,说不定会有意想不到的收获。
3、异步加载数据的网页,一般在JS或XHR中取找url
作业③
1)爬取特定id股票信息实验
要求:根据自选3位数+学号后3位选取股票,获取印股票信息。抓包方法同作②。
法一:
程序主要思路:
代码:
import requests
import re
class SpiderIdStock(object):
'''创建一个实现爬取东方财富网站特定股票代码的类'''
def __init__(self,fs_name):
'''设置共同属性'''
self.id = "104" # 学号后三位数
self.header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
} # UA伪装浏览器
self.fs_type = {
"沪深A股": "m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23",
"上证A股": "m:1+t:2,m:1+t:23",
"深证A股": "m:0+t:6,m:0+t:13,m:0+t:80"
} # 东方财富网行情中心的板块变化体现在fs字段,通过f12抓包可得以上编码,其余板块依此类推
self.dic = {
"股票代码号": 'f12', "股票名称": 'f14',
"今日开": 'f17',"今日最高": 'f15', "今日最低": 'f16'
} # json网页中的字典键值对应含义
self.fs_code = self.fs_type[fs_name]
def get_html_text(self,url):
'''获取网址字符内容'''
req = requests.get(url, headers=self.header, timeout=30)
req.raise_for_status() # 若状态码不是200抛出HttpError异常
# req.encoding = req.apparent_encoding # 分析编码比较耗时,可手动设置
req.encoding = 'utf-8' # 手动设置编码方式
return req.text
def get_onepage_url(self,page):
'''获取网站指定板块号单页网址'''
url_page = "http://5.push2.eastmoney.com/api/qt/clist/get?pn={0:d}&pz=20&po=1&np=1".format(page)
url_fs = "&fltt=2&invt=2&fid=f3&fs={}&fields=f12,f14,f15,f16,f17".format(self.fs_code)
url = url_page + url_fs
return url
def extract_infos(self,req_text):
'''从所有网页字符内容中提取所需信息范围'''
pattern = "\[(.*?)\]"
string = re.findall(pattern,req_text)[0]
infos = list(eval(string)) # 所有信息一次被匹配,findall方法返回的列表中有且只有一个字符串元素
return infos # eval返回该字符串所代表的python对象(元组),为便于后续操作再将元组转化为列表
def search_stock(self):
'''从指定板块中查找第一个符合id条件的股票信息'''
out = False
max_pagenum = 210
for i in range(1,max_pagenum+1):
url = self.get_onepage_url(i)
infos = self.extract_infos(self.get_html_text(url))
for info in infos: # infos为元组,info为字典
if info[self.dic["股票代码号"]][-3:] == self.id:
self.format_output(info)
out = True
break
if out:
break
def format_output(self,info):
'''格式化输出'''
form = "{:<8}\t{:<8}\t{:<8}\t{:<8}\t{:<8}"
print(form.format("股票代码号","股票名称","今日开","今日最高","今日最低"))
print(form.format(info[self.dic["股票代码号"]],info[self.dic["股票名称"]],
info[self.dic["今日开"]],info[self.dic["今日最高"]],info[self.dic["今日最低"]]))
if __name__ == "__main__":
optional = ["沪深A股","上证A股","深证A股"]
spider = SpiderIdStock(optional[0]) # 设置爬取哪个板块
spider.search_stock() # 该方法中调用了其他方法
运行结果部分截图:

法二:
程序主要思路:
代码:
import requests
import re
class SpiderIdStock(object):
'''创建一个实现爬取东方财富网站特定股票代码的类'''
def __init__(self,stock_url):
'''设置共同属性'''
self.url = stock_url
self.header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
} # UA伪装浏览器
def get_html_text(self):
'''获取网址字符内容'''
req = requests.get(self.url, headers=self.header, timeout=30)
req.raise_for_status() # 若状态码不是200抛出HttpError异常
# req.encoding = req.apparent_encoding # 分析编码比较耗时,可手动设置
req.encoding = 'utf-8' # 手动设置编码方式
return req.text
def extract_infos(self):
'''从所有网页字符内容中提取所需信息范围'''
req_text = self.get_html_text()
pattern = '\[(".*?")\]'
string = re.findall(pattern,req_text)[0] # 所有信息一次被匹配,findall方法返回的列表中有且只有一个字符串元素
infos = (eval(string)) # 转化为元组
return infos
def format_output(self):
'''格式化输出'''
try:
form = "{:<8}\t{:<8}\t{:<8}\t{:<8}\t{:<8}"
print(form.format("股票代码号","股票名称","今日开","今日最高","今日最低"))
print(form.format(stock_code,stock_name,open_price,max_price,min_price))
except Exception as err:
print(err)
if __name__ == "__main__":
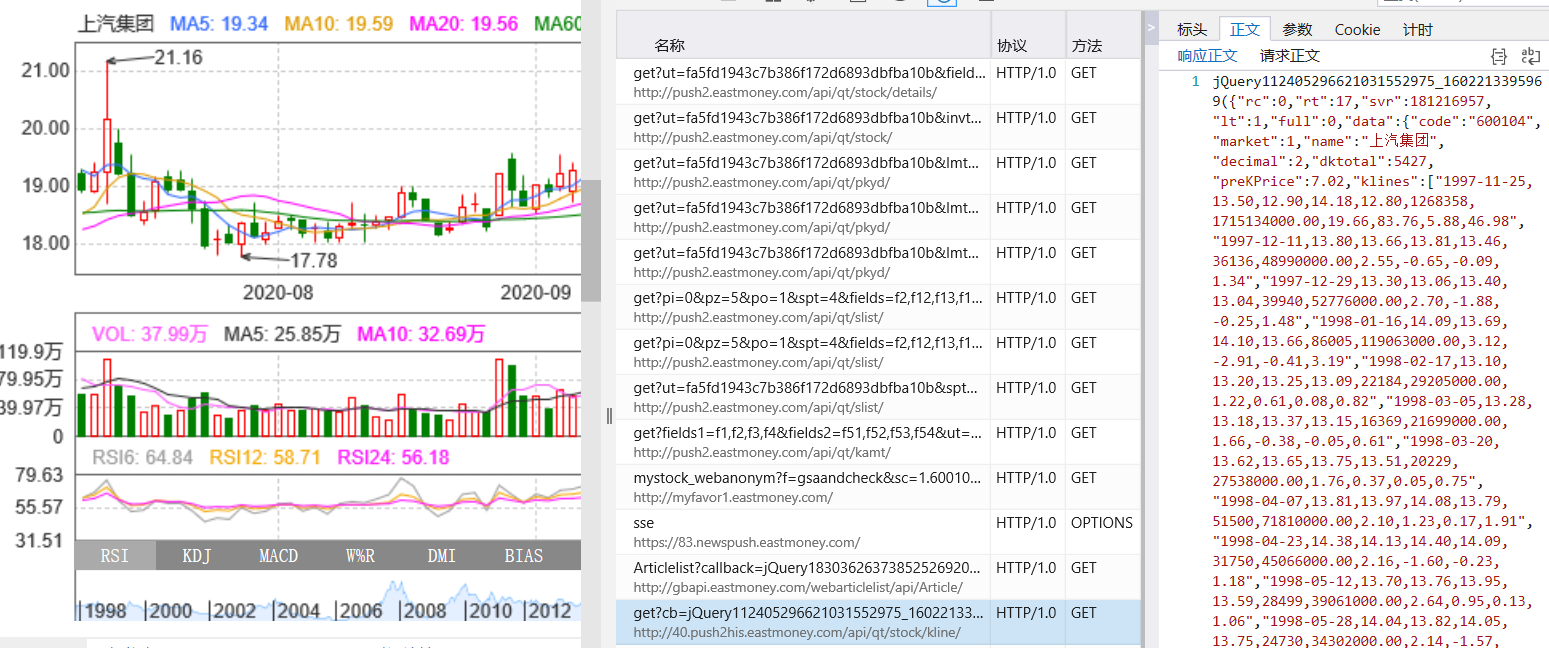
stock_code = "600104" # 指定股票代码,后三位为学号
stock_name = "上汽集团"
# json抓包得到股票代码所对应的url
stock_url = "http://93.push2his.eastmoney.com/api/qt/stock/kline/get?cb=jQuery112405532698181492186_1602167500190&secid=1.600104&ut=fa5fd1943c7b386f172d6893dbfba10b\
&fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf59%2Cf60%2Cf61&klt=101&fqt=0&beg=0&end=20500101&smplmt=460&lmt=1000000&_=1602167500227"
spider = SpiderIdStock(stock_url)
data = spider.extract_infos()[-1].split(",") # 获取有记录的最新日期的数据,以列表形式返回
open_price,max_price,min_price = data[1],data[3],data[4]
spider.format_output()
运行结果同法一:

2)心得体会:
刚拿到这题的时候我愣了好一下,既然抓包方法跟第二题一样那选取指定股票代码岂不就是在第二题的基础上加一个条件判断的事情?我一开始就是这样去做的(法一)。
后来经过大佬的指点,明白了这题新的抓包(法二)。
tips:多和同学交流

