网络爬虫第一次作业——结合三次小作业
作业①:
1)UniversityRanking实验
要求:爬取给定网址http://www.shanghairanking.cn/rankings/bcur/2020 的数据,屏幕打印爬取的大学排名信息。
程序主要思路:
代码:
import urllib.request
from bs4 import BeautifulSoup
class SpiderUniversity(object):
'''创建一个爬取给定网址大学排名信息的类'''
def __init__(self,url):
'''共同属性是网址url'''
self.url = url
def get_html(self):
'''获取网址字符内容'''
header= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
req = urllib.request.Request(self.url, headers=header)
html = urllib.request.urlopen(req).read()
return html.decode()
def parse_html(self):
'''解析网址字符内容,提取需要的信息'''
html = self.get_html()
soup = BeautifulSoup(html, "html.parser")
tags = soup.find_all("td") #该网址所需信息都包含在td标签内
return tags
def output(self,tags):
'''将提取到的信息设置好格式在控制台输出'''
colnames = ['排名','学校名称','省市','学校类型','总分','办学层次'] #td标签包含的所有属性
sep = " " #控制格式的分隔符
seps = [14*sep,12*sep,14*sep,12*sep]
colnum = len(colnames)
datanum = len(tags)
for i in range(colnum-1):
try:
print(colnames[i],end=seps[i])
except:
print(colnames[i])
for i in range(0,datanum,colnum):
for j in range(i,colnum+i-1):
string = tags[j].text.strip()
print(string, end=(16-len(string))*sep)
print()
if __name__ == "__main__":
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
spider = SpiderUniversity(url)
tags = spider.parse_html()
spider.output(tags)
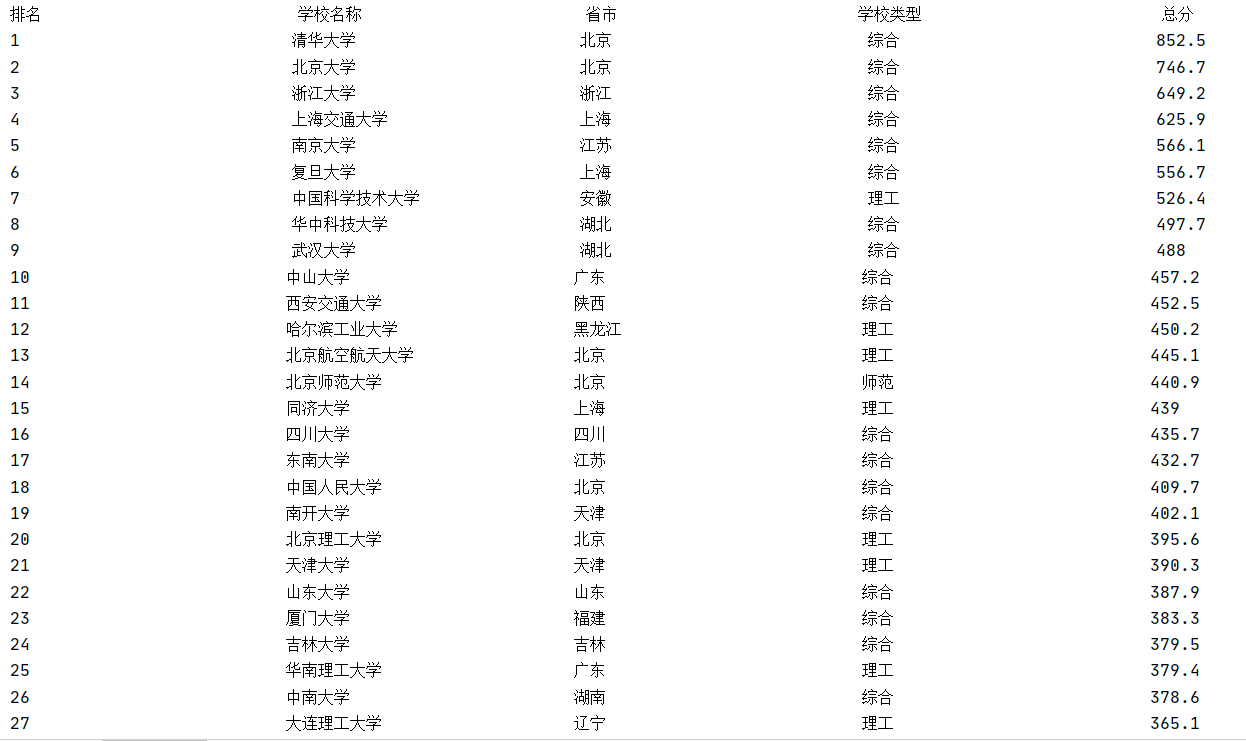
运行结果部分截图:
没利用中文空格chr(12288)尝试对齐真实太难了。原因是这样:在print中,空格是ASCII码为20的space,也就是半角空格。它的长度等于每个字母或数字的宽度,但远比汉字的宽度小,所以导致输出后的字符串长度参差不齐。

将填充符修改为中文空格后(输出代码即output方法修改如下)
def output(colnames,tags):
'''将提取到的信息设置好格式在控制台输出'''
colnames = ['排名','学校名称','省市','学校类型','总分','办学层次'] #td标签包含的所有属性
sep = chr(12288) #控制格式的分隔符
seps = [16*sep,14*sep,15*sep,15*sep]
colnum = len(colnames)
datanum = len(tags)
for i in range(colnum-1):
try:
print(colnames[i],end=seps[i])
except:
print(colnames[i])
for i in range(0,datanum,colnum):
for j in range(i,colnum+i-1):
string = tags[j].text.strip()
print(string, end=(18-len(string))*sep)
print()
输出效果:
2)心得体会:
html都是以标签对的形式存储信息,因此找到信息所处位置的标签特征很关键。这里,我抓住了所需信息都存储在<td>...</td>标签对中的特征。
主要收获如下:
1、学习了编写爬虫程序的一般思路
2、初步掌握了html标签对的结构形式
3、熟悉了urllib.request以及bs4.BeautifulSoup的使用,学会如何用request获取网页内容并解码和利用BeautifulSoup遍历标签树进行解析
作业②:
1)GoodsPrices实验
要求:自己选择某个商城商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。(这里选择京东商城)
程序主要思路:
代码:
import requests
import re
class SpiderGoods(object):
'''创建爬取京东搜索页面中的商品名和价格的类'''
def __init__(self,url,pagenums=1):
'''共同属性有网址url以及要搜索的总页数的pagenums'''
self.url = url
self.pagenums = pagenums
def get_html_text(self,url):
'''获取网址字符内容,此处要获取页面的完整商品信息还要利用selenium模仿滚动条下拉'''
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
req = requests.get(url, headers=head,timeout=30)
req.raise_for_status()
# req.encoding = req.apparent_encoding # 分析编码比较耗时,可手动设置
req.encoding = 'utf-8'
return req.text
def search_keyword(self,name): #https://search.jd.com/Search?keyword=book&page=4
'''返回京东指定关键词url'''
# name_code = urllib.request.quote(name) #对汉字进行编码,这里支持中文所以不需要
self.url += "?keyword=" + name #京东搜索接口
return self.url
def turn_page(self,pagenum):
'''返回京东对应关键词搜索的制定页码url'''
page_num = 2*pagenum - 1; #理论页数与真实页数的映射关系
return self.url + "&page=" + str(page_num)
def name_filter(self,string):
'''利用正则表达式过滤出商品名称'''
reg = r'<li.+?data-sku.+?>' #商品正文开始标志
m = re.search(reg,string)
start = m.end()
string = string[start:] #从商品正文开始过滤
pattern = re.compile(r'(<em>[^¥][\s\S]*?</em>)')
string = ','.join(pattern.findall(string)) #将列表类型转化为字符串以便后续处理
reg = r"(<span .*?>.*?</span>)|<[\s\S]+?>|(\s)"
names = re.sub(reg,'',string).split(",")
return names
def price_filter(self,string):
'''利用正则表达式过滤出商品价格'''
reg = r"(<span .*?>[\s\S]*?</span>)"
string = re.sub(reg, '', string)
reg = r'<i>(\d+\.?\d*)</i>'
pattern = re.compile(reg)
prices = pattern.findall(string)
return prices
def output(self,names,prices):
'''格式化输出函数'''
colnames = ['序号','价格','商品名']
form = "{0:<3}{1:^20}{2:^30}"
print(form.format(colnames[0],colnames[1],colnames[2]))
for i in range(len(names)):
print(form.format(str(i+1),prices[i],names[i]))
def search_pages_info(self):
'''给出指定url、搜索页数的所有商品信息'''
for i in range(1,self.pagenums+1): #从第一页遍历到给定的搜索页数pagenums
info_html = self.get_html_text(self.turn_page(i))
names = self.name_filter(str(info_html))
prices = self.price_filter(str(info_html))
print("{:-^100}".format(i)) #分页输出标记
self.output(names,prices)
if __name__ == "__main__":
url = "https://search.jd.com/Search"
pagenums = 5
key = "书包"
spider = SpiderGoods(url,pagenums)
spider.search_keyword(key)
spider.search_pages_info() #该方法中调用了其他类方法
运行结果部分截图:

2)心得体会:
通过比对不同关键词搜索结果的url,以及同一关键词不同页数的url,可以发现该商城提供的搜索接口和翻页接口,比方说这里京东商城的关键词字段是keyword,页数字段是page,并且keyword支持中文(无需另外编码)以及页数n对应的page=2n-1。
信息提取方面,通过观察我发现了商品名和价格所在的标签特征,由此体会到熟悉目标html结构是成功提取信息的重中之重。
主要收获:
1、学习了如何调用京东等网站的搜索接口以及翻页接口
2、学习了应对一些类似网站的反爬技巧例如加header以及cookie。
3、练习了如何使用正则表达式提取所需信息
作业③
要求:爬取一个给定网页http://xcb.fzu.edu.cn/html/2019ztjy或者自选网页的所有JPG格式文件(这里选择福州大学党委宣传部网页http://xcb.fzu.edu.cn)
程序主要思路:
代码:
import requests
import re
import os
class SpiderJpg(object):
'''创建爬取JPG格式图片的爬虫类'''
def __init__(self,url,header):
'''共同属性有网址url以及UA字段'''
self.url = url
self.header = header
def get_html_text(self):
'''获取网址字符内容'''
req = requests.get(self.url, headers=self.header, timeout=30)
req.raise_for_status()
# req.encoding = req.apparent_encoding # 分析编码比较耗时,可手动设置
req.encoding = 'utf-8'
return req.text
def extract_jpg(self,html_text):
'''从网页所有字符内容中解析出与jpg图片有关的字符内容'''
reg = r'<li>.+href="#".+jpg.+</li>'
html_text = re.sub(reg,'',html_text) # 去掉注释字段中的重复图片
reg = r'"(/.+\.jpg)"|src="(.+\.jpg)'
pattern = re.compile(reg,re.I) # re.I忽略大小写
return pattern.findall(html_text)
def download_jpg(self,imgs):
'''利用解析出的与jpg图片有关的字符内容将图片保存到本地'''
current_path = os.getcwd() # 获取当前路径,作为控制台输出提示
print('There are {} pictures in total'.format(len(imgs)))
for img in imgs:
img_url = url + max(img) if max(img)[0] == '/' else max(img) # 如果是相对路径则要拼接url成绝对路径否则不需要
img_name = img_url.split("/")[-1] # 文件名选取
print('{}:{}'.format(img_name,img_url))
img_con = requests.get(img_url, headers=self.header).content
with open(img_name, 'wb') as f: # 以二进制方式写入文件
f.write(img_con)
print('{} Downloaded in {}'.format(img_name, current_path))
if __name__ == '__main__':
url = "http://xcb.fzu.edu.cn"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"
}
spider = SpiderJpg(url,header)
html_text = spider.get_html_text()
imgs = spider.extract_jpg(html_text)
spider.download_jpg(imgs)
运行结果部分截图:
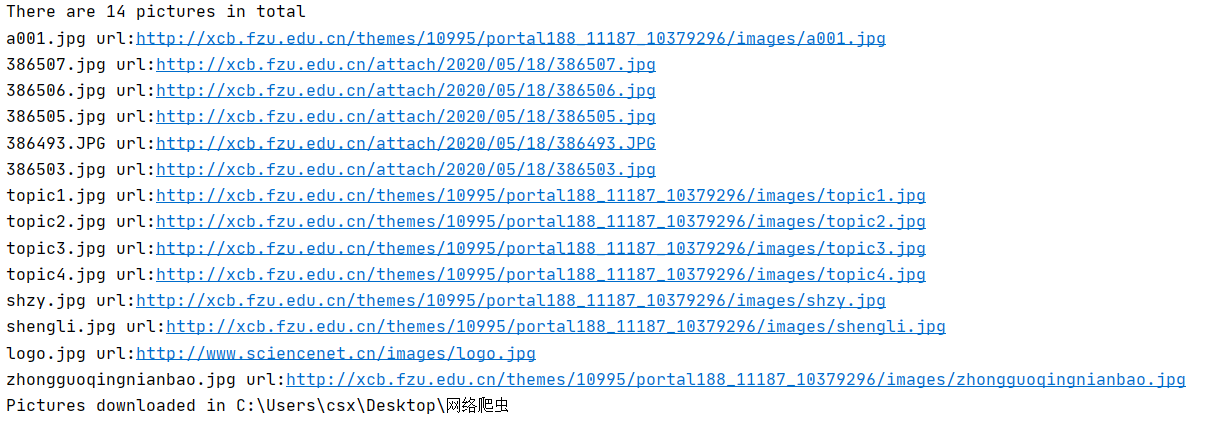
实际上程序文件(.py)会与图片在同一文件夹,这里为方便展示,将文件夹中的py文件暂时移出了(程序中使用默认的相对路径)
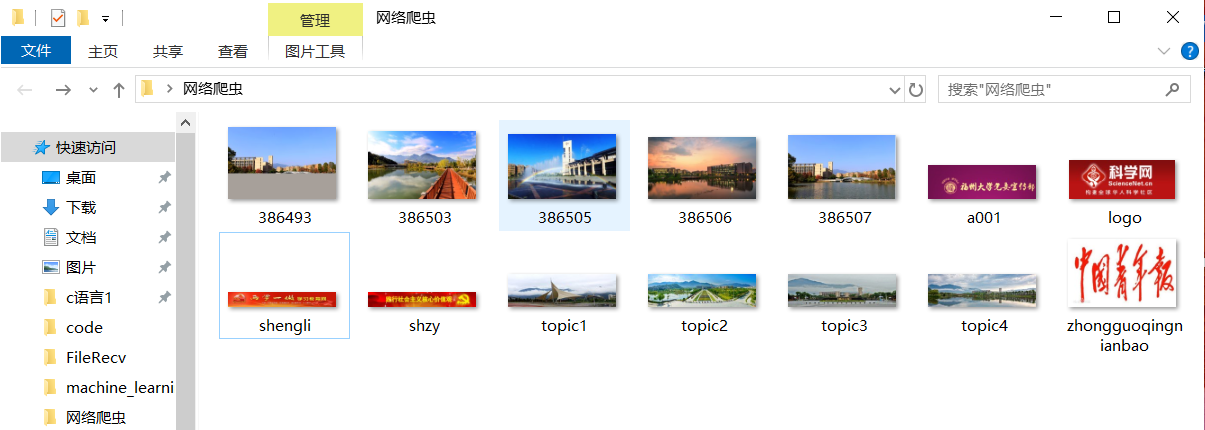
2)心得体会:
观察目标网页的html结构,可以发现提取所有jpg格式图片有几个难点:
(1)后缀名有大小写,jpg和JPG
(2)目标jpg路径同时存在绝对路径和相对路径
(3)html文本中注释字段有重复的图片,例如http://xcb.fzu.edu.cn/themes/10995/portal188_11187_10379296/images/topic1.jpg和http://xcb.fzu.edu.cn/themes/10995/portal188_11187_10379296/images/cast1.jpg
我通过对整体html结构以及图片链接所在位置html结构的分析,过滤重复图片,完善爬取规则,最后终于做到了对该网页jpg格式图片不重不漏的爬取
主要收获:
1、加强了正则表达式在设计爬取规则中的应用
2、学会如何通过爬取到的url链接将图片文件保存到本地

 浙公网安备 33010602011771号
浙公网安备 33010602011771号