10组-Alpha冲刺-4/6
一、基本情况
- 队名:要有格局才对
- 组长博客
- 小组人数:10
二、冲刺概况汇报
根据拟定的团队分工
- 在充分尊重大家意愿的前提下、团队分工如下(用名字唯一标识符标识):
- 前端组:萍、翁
- 后端组:石、林
- 数据组:硕、源、松、熙
- 管理组:苏、唐
- alpha_4汇总:
- 由于项目进入收尾阶段、不要求组员每人绘制燃尽图了、统一统计至组长处汇总
![]()
|组名|第一阶段分工|第二阶段|第三阶段|alpha_1阶段|主任务|
| -- | -- | -- | -- | -- | - |
|前端组|原型设计、视频|接口调试|原型实现、UI优化|前端相关|前端相关 |
|数据组|爬取可行性分析测试|数据收集|数据分析|数据相关|数据相关 |
|后端组|数据库搭建|后端构建、接口文档说明|后端完善|后端相关|后端相关 |
|管理组(含测试组)|博客撰写、规划|各组协调|测试优化、部署|测试、端茶倒水| 测试管理相关|
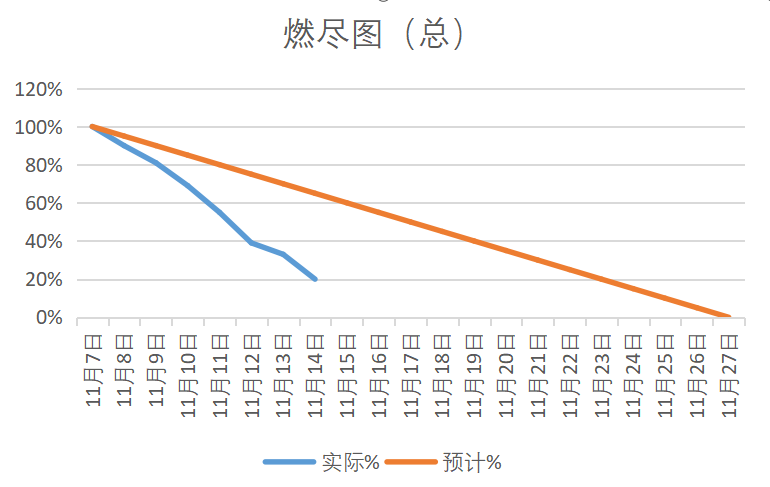
姓名:苏伟煌(组长)
- 过去两天完成了哪些任务:
- 文字描述:
- 1.基本分工部署
- 2.GitHub部署
- 3.缓解组员紧张情绪
- 4.帮组测试组解决药监局爬取攻坚
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- main:大家都有考试、成绩很重要、暂不作过多计划分工
- 继续爬取
- 重构代码
- 前端初步
- 还剩下哪些任务
- 同上
- 说点实际的:微机接口考试、图形学考试、面向对象考试、人工智能。
- 遇到了哪些困难
- 药监局攻坚爬取、最后用抓包手段解决
- 有哪些收获和疑问
- 收获:知道了用抓包的手段也可以在手机这种平台爬取数据、很冷门的技巧,算是作为组长为数不多的小贡献
- 疑问:药监局这种官方网站也会百疏一漏吗
| 第N轮 | 新增代码(行) | 累计代码(行) | 本轮学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1/6 | 0 | 0 | 5 | 5 | 网页的基本布局以及路由跳转 |
| 2/6 | 208 | 208 | 4 | 9 | 网页的基本布局以及路由跳转 |
| 3/6 | 211 | 419 | 6 | 15 | 网页的基本布局以及路由跳转 |
| 4/6 | 200 | 619 | 6 | 15 | 修改readme |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:王毅萍
- 过去两天完成了哪些任务:
- 文字描述:
- 1.基本前端分工部署
- 2.GitHub前端部署
- 3.帮组测试组解决药监局爬取攻坚
- 展示GitHub当日代码/文档签入记录:

- 接下来的计划
- main:完成前端素材积累和初步测试
- 代码重构
- 继续UI完善
- 前端初步
- 还剩下哪些任务
- 同上
- 前端完善。
- 学习vue框架、pyecharts
- 遇到了哪些困难
- 账号密码token连接故障
- 有哪些收获和疑问
- 收获:和后端组沟通解决了跨域问题
- 疑问:之前测试组猪尾巴的前端跨域问题和这次有些类似、但是合理的解决方法应该是后端修改
| 第阶段 | 新增代码(行) | 累计代码(行) | 本轮学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1/6 | 208 | 208 | 0 | 0 | 网页的基本布局以及路由跳转 |
| 2/6 | 0 | 208 | 0 | 0 | 无 |
| 3/6 | 210 | 418 | 5 | 5 | 无 |
| 4/6 | 200 | 618 | 5 | 5 | 无 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:翁敏
- 过去两天完成了哪些任务:
- 文字描述:
- 1.代码重构
- 3.了解vue大致的框架,完成了基本的环境的配置。
- 4.再github上查找了一些别人网站设计的思路。
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 1.找一些vue系列的相关视频学习,尽早入门,可以将知识运用到项目开发
- 2.去vue官网看文档学习,查找有没有好用的插件
- 3.我想复习下周的两门考试,这个目前来说对我比较重要,如果时间允许还是会尽量多打代码构思如何尽快完成本组课题的项目开发
- 还剩下哪些任务
- 1.了解vue各个模块知识,能够运用到本次项目中
- 2.还有很多考试和大作业还没有完成,任重道远
- 3.还没有完全清楚了解如何使用vue完成网站开发。

- 遇到了哪些困难
- 1.vue_cli安装完成,再执行rpm run serve时,报错,大概意思是config配置报错(还是啥的),找了很多资料,还是无法解决,最终remake重装了
- 2.对一些vue代码模块使用不明白,再没有文档或者视频的介绍情况下还是比较难以理解的。
- 有哪些收获和疑问
- 1.重装vue_cli时候,直接把nodejs也给删了(因为我觉得我当初nodejs安装的路径也有问题)于是就小心翼翼对着文档安装nj和vue,看了别人的优秀文档,自愧不如,自己确实跟着学习到了很多东西,以前不懂的那些命令行指令各个字母串接再一起是什么意思,别人的文档都一一阐述了,得到很多收获。
- 2.跟着视频做了vue构建视频的demo,vue确实很方便,以前用js进行页面跳转比较麻烦,vue内部自带router模块方便快捷(不懂这样描述是否正确)
学习进度条
| alpha轮次 | 新增代码(行) | 累计代码(行) | 本轮学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1/6 | 462 | 462 | 11 | 11 | 对前端原型进行架构,接口调试,以及安排分工前端组同学的任务 |
| 2/6 | 300 | 762 | 4 | 15 | 对前端原型进行架构分析与设计 |
| 3/6 | 200 | 962 | 2 | 17 | 对前端原型进行架构分析与设计 |
| 4/6 | 200 | 1162 | 2 | 17 | 对前端原型进行架构分析与设计 |
PSP
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 1020 | 1000 |
| Development | 开发 | 300 | 250 |
| · Analysis | · 需求分析 (包括学习新技术) | 200 | 100 |
| · Design Spec | · 生成设计文档 | 10 | 10 |
| · Design Review | · 设计复审 | 50 | 50 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 50 | 50 |
| · Design | · 具体设计 | 100 | 200 |
| · Coding | · 具体编码 | 100 | 300 |
| · Code Review | · 代码复审 | 50 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 50 | 50 |
| Reporting | 报告 | 30 | 50 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| · 合计 | 1020 | 1160 |
姓名:陈本源(数据组)
- 过去两天完成了哪些任务:
- 文字描述:
- 1.爬虫爬取淘宝(几十万条数据)
- 2.爬虫爬取比价网(几十万条数据)
- 3.bug修复,代码重构
- 展示GitHub当日代码/文档签入记录:

- 接下来的计划
- 1.进行数据清洗
- 2.开始学习PyEcharts,对爬取到的数据,进行数据分析
- 还剩下哪些任务
- 1.对数据进行处理与分析
- 2.生成可视化图
- 遇到了哪些困难
- 1.再爬取淘宝的过程中,由于网站的反爬机制,设置了cookies,成功爬取到页面的相关信息,但是由于本次任务爬取的数据量实在太过庞大,频繁的访问淘宝的url,导致连接多次被主动中断,甚至出现ip被封,针对此问题本来打算使用selenium,通过动态模拟用户点击行为,对页面进行渲染,从而绕过反爬机制,实现爬取,但是该方法耗时长,对于本次任务需要爬取的巨大数据量显然不适合。后又发现设置time.sleep设置url访问间隔,但也同样浪费时间,最后采用python自带的fake_useragent库,通过设置随机头对url进行访问,大大降低了服务器对机器爬虫的认定概率,从而实现爬取53w条
- 2.爬取比价网的过程中,同样也是遇到了ip访问限制,使用download_delay解决。
- 有哪些收获和疑问
- 1.随机头方法在scrapy爬虫框架中,似乎起不到什么作用,导致爬取比价网的过程很煎熬,
- 2.了解了ip限制的解决方法。
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 442 | 442 | 10 | 10 | 和另一位组员一起对京东的药品信息数据进行爬取 |
| 2/6 | 0 | 442 | 10 | 20 | 京东爬取 |
| 3/6 | 0 | 442 | 4 | 24 | bug修复 |
| 4/6 | 0 | 442 | 4 | 24 | bug修复 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:石致彬
- 过去两天完成了哪些任务:
- 文字描述:
- 1.学习spring框架配置及一些工具的使用
- 2.学习spring系列框架
- 3.初步设计了所需要的表
- 4.初步建立了数据库
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 1.学习Web方面的知识
- 2.编写接口供数据组使用向数据库中添加数据
- 3.编写接口供数据查询使用
- 还剩下哪些任务
- 1.学习web知识
- 2.编写接口
- 3.学习云服务器的使用
- 4.配置云服务器的环境
- 5.部署到云服务器
- 遇到了哪些困难
- 1.时间不够考试太多
- 2.服务器太贵了
- 有哪些收获和疑问
- 1.学习了数据库的相关知识
- 2.学习了用Java操作数据库
- 3.疑问:我们真的做得完吗
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 563 | 563 | 14 | 14 | 和另一位组员合作对数据库进行搭建,以及后端的搭建 |
| 2/6 | 443 | 1006 | 12 | 26 | 学习了新技术 |
| 3/6 | 431 | 1437 | 2 | 28 | 学习spring系列框架 |
| 4/6 | 200 | 1637 | 2 | 28 | 学习spring系列框架 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:黄艇淞(数据组)
- 过去两天完成了哪些任务:
- 文字描述:
- 1.bug修复,数据清洗
- 2.爬虫爬取比价网(几十万条数据)
- 3.数据发送至后端
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 1.开始学习PyEcharts,对爬取到的数据,进行数据分析
- 还剩下哪些任务
- 1.对数据进行处理与分析
- 2.生成可视化图

- 遇到了哪些困难
- 1.再爬取淘宝的过程中,由于网站的反爬机制,设置了cookies,成功爬取到页面的相关信息,但是由于本次任务爬取的数据量实在太过庞大,频繁的访问淘宝的url,导致连接多次被主动中断,甚至出现ip被封,针对此问题本来打算使用selenium,通过动态模拟用户点击行为,对页面进行渲染,从而绕过反爬机制,实现爬取,但是该方法耗时长,对于本次任务需要爬取的巨大数据量显然不适合。后又发现设置time.sleep设置url访问间隔,但也同样浪费时间,最后采用python自带的fake_useragent库,通过设置随机头对url进行访问,大大降低了服务器对机器爬虫的认定概率,从而实现爬取53w条
- 2.爬取比价网的过程中,同样也是遇到了ip访问限制,使用download_delay解决。
- 有哪些收获和疑问
- 1.随机头方法在scrapy爬虫框架中,似乎起不到什么作用,导致爬取比价网的过程很煎熬,
- 2.了解了ip限制的解决方法。
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 352 | 352 | 7 | 7 | 和另一位组员一起对京东的药品信息数据进行爬取 |
| 2/6 | 352 | 704 | 1 | 8 | 继续和另一位组员一起对京东的药品信息数据进行爬取 |
| 3/6 | 212 | 916 | 5 | 13 | 数据清洗 |
| 4/6 | 200 | 1116 | 5 | 13 | 数据清洗 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:唐劲霆(管理组)
- 过去两天完成了哪些任务:
- 文字描述:
- 1.继续制作可视化数据分析图。
- 2.博客编写。
- 展示GitHub当日代码/文档签入记录:

- 接下来的计划
- 1.继续学习制作可视化分析的相关知识。
- 2.制作更多的可视化分析图表。
- 3.对功能进行测试。
- 还剩下哪些任务
- 1.对功能进行测试。
- 2.制作更多的可视化分析图表。
- 3.任务分工,问题商讨。
- 遇到了哪些困难
- 1.数据可视化分析的方法较多,选择上有一定的纠结。
- 2.考虑需要绘制哪些数据的可视化分析。
- 有哪些收获和疑问
- 1.学习了一些关于可视化分析的知识。
- 2.对JavaScript语言的掌握加深。
学习进度条
| alpha轮次 | 新增代码(行) | 累计代码(行) | 本轮学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1/6 | 208 | 208 | 0 | 0 | 各分工组反馈的问题商讨解决,后端初步测试,博客整合 |
| 2/6 | 314 | 522 | 6 | 6 | 学习制作可视化分析的相关知识,尝试制作可视化分析图表 |
| 3/6 | 321 | 843 | 3 | 9 | 制作更多数据可视化分析图表 |
| 4/6 | 0 | 843 | 3 | 9 | 制作更多数据可视化分析图表 |
PSP
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 80 | 100 |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 300 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 | 15 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 60 | 80 |
| · Coding | · 具体编码 | 140 | 120 |
| · Code Review | · 代码复审 | 20 | 25 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 15 |
| Reporting | 报告 | 60 | 60 |
| · Test Repor | · 测试报告 | 0 | 0 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| · 合计 | 670 | 750 |
姓名:林志煌
- 过去两天完成了哪些任务:
- 文字描述:
- 1.代码重构
- 2.写了简单的登录界面
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 1.继续完善界面
- 2.增加其他功能
- 还剩下哪些任务
- 1.完善
- 2.增加功能
- 遇到了哪些困难
- 1.知识点大多都忘了,只能边查边做
- 2.模板几乎都是要收费的
- 有哪些收获和疑问
- 1.收获:复习了以前的知识,算是小巩固
- 2.疑问:暂时没啥疑问

| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 362 | 362 | 10 | 10 | 和另一位组员合作对数据库进行搭建,以及后端的搭建 |
| 2/6 | 12 | 374 | 2 | 12 | 无 |
| 3/6 | 110 | 484 | 2 | 14 | 无 |
| 4/6 | 100 | 584 | 2 | 14 | 数据库重构 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:陈硕
- 过去两天完成了哪些任务:
- 文字描述:
- 1.数据清洗
- 2.数据可视化分析
- 3.数据发送至后端
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 1.进行数据清洗
- 2.开始学习PyEcharts,对爬取到的数据,进行数据分析
- 还剩下哪些任务
- 1.对数据进行处理与分析
- 2.生成可视化图

- 遇到了哪些困难
- 1.爬虫团队在爬取淘宝的过程中,由于网站的反爬机制,设置了cookies,成功爬取到页面的相关信息,但是由于本次任务爬取的数据量实在太过庞大,频繁的访问淘宝的url,导致连接多次被主动中断,甚至出现ip被封,针对此问题本来打算使用selenium,通过动态模拟用户点击行为,对页面进行渲染,从而绕过反爬机制,实现爬取,但是该方法耗时长,对于本次任务需要爬取的巨大数据量显然不适合。后又发现设置time.sleep设置url访问间隔,但也同样浪费时间,最后采用python自带的fake_useragent库,通过设置随机头对url进行访问,大大降低了服务器对机器爬虫的认定概率,从而实现爬取53w条
- 2.爬取比价网的过程中,同样也是遇到了ip访问限制,使用download_delay解决。
- 有哪些收获和疑问
- 1.随机头方法在scrapy爬虫框架中,似乎起不到什么作用,导致爬取比价网的过程很煎熬,
- 2.了解了ip限制的解决方法。
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 410 | 410 | 9 | 9 | 和另一位组员一起对淘宝的药品信息数据进行爬取 |
| 2/6 | 410 | 820 | 2 | 11 | 和另一位组员一起对淘宝的药品信息数据进行爬取 |
| 3/6 | 210 | 630 | 3 | 14 | 数据清洗 |
| 4/6 | 0 | 630 | 3 | 14 | 数据清洗 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:林泽熙
- 过去两天完成了哪些任务:
- 文字描述:
- 1.数据清洗,bug修复
- 2.数据发送至后端
- 展示GitHub当日代码/文档签入记录:
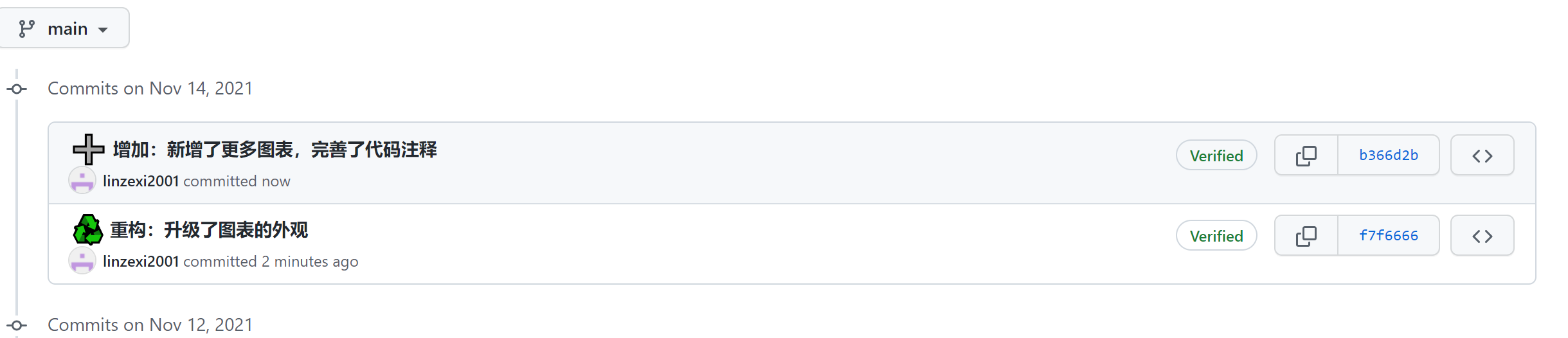
- 接下来的计划
- 1.进行数据清洗
- 2.开始学习Pyecharts
- 还剩下哪些任务
- 1.数据处理与分析
- 2.数据可视化
- 遇到了哪些困难
- 1.爬虫团队在爬取淘宝的过程中,由于网站的反爬机制,设置了cookies,成功爬取到页面的相关信息,但是由于本次任务爬取的数据量实在太过庞大,频繁的访问淘宝的url,导致连接多次被主动中断,甚至出现ip被封,针对此问题本来打算使用selenium,通过动态模拟用户点击行为,对页面进行渲染,从而绕过反爬机制,实现爬取,但是该方法耗时长,对于本次任务需要爬取的巨大数据量显然不适合。后又发现设置time.sleep设置url访问间隔,但也同样浪费时间,最后采用python自带的fake_useragent库,通过设置随机头对url进行访问,大大降低了服务器对机器爬虫的认定概率,从而实现爬取53w条
- 2.github使用不熟悉
- 3.复现了组长的抓包爬取药监局手段,完善了json字段
- 有哪些收获和疑问
- 1.了解了ip限制的解决方法。
- 2.python第三方库功能强大,需要自己多多了解和使用
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 411 | 411 | 10 | 10 | 和另一位组员一起对淘宝的药品信息数据进行爬取 |
| 2/6 | 10 | 421 | 1 | 11 | 重构代码 |
| 3/6 | 110 | 531 | 2 | 13 | 数据清洗 |
| 4/6 | 0 | 531 | 2 | 13 | 数据清洗 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
三、冲刺成果展示
PSP & 学习进度条(学习进度条每周追加)
PSP(全队)
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 300 | 720 |
| · Estimate | · 估计这个任务需要多少时间 | 12000 | 16000 |
| Development | 开发 | 7000 | 7000 |
| · Analysis | · 需求分析 (包括学习新技术) | 50 | 550 |
| · Design Spec | · 生成设计文档 | 50 | 550 |
| · Design Review | · 设计复审 | 50 | 550 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 4300 | 550 |
| · Design | · 具体设计 | 1200 | 1200 |
| · Coding | · 具体编码 | 3600 | 7200 |
| · Code Review | · 代码复审 | 500 | 500 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | 500 |
| Reporting | 报告 | 900 | 1800 |
| · Test Repor | · 测试报告 | 30 0 | 600 |
| · Size Measurement | · 计算工作量 | 100 | 200 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 18000 |
-
组内最新成果展示
![]()
-
站立会议合照
![]()
-
会议耗时记录(每次追加记录)


| 第N次alpha会议 | 耗时(分钟) |
|---|---|
| 1/6 | 8 |
| 2/6 | 10 |
| 3/6 | 12 |
| 4/6 | 10 |
| 5/6 | |
| 6/6 |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号