结对作业二
结对作业二
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/FZUSESPR21 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/FZUSESPR21/homework/11891 |
| 结对学号 | 221801106 、221801127 |
| 这个作业的目标 | 对结对作业一的建模的项目进行编程实现,实现了论文查询,热词可视化统计,热词排行,论文增删收藏等功能,采取web端,用到的技术是mysql+jsp+servlet |
| 其他参考文献 | ... |
| 项目部署地址 | http://120.77.182.55:8080/demo_war_exploded 账号:admin密码:123456,或者可以注册一个账号 |
1.git仓库链接和代码规范链接和项目部署地址
2.PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| •Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 810 | 1055 |
| •Analysis | 需求分析 (包括学习新技术) | 10 | 5 |
| •Design Spec | 生成设计文档 | 30 | 20 |
| •Design Review | 设计复审 | 30 | 30 |
| •Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| •Design | 具体设计 | 100 | 60 |
| •Coding | 具体编码 | 500 | 700 |
| •Code Review | 代码复审 | 100 | 200 |
| •Test | 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Report | 报告 | 60 | 55 |
| •Test Report | 测试报告 | 30 | 30 |
| •Size Measurement | 计算工作量 | 10 | 15 |
| •Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 10 |
| 合计 | 890 | 1030 |
3.成品展示
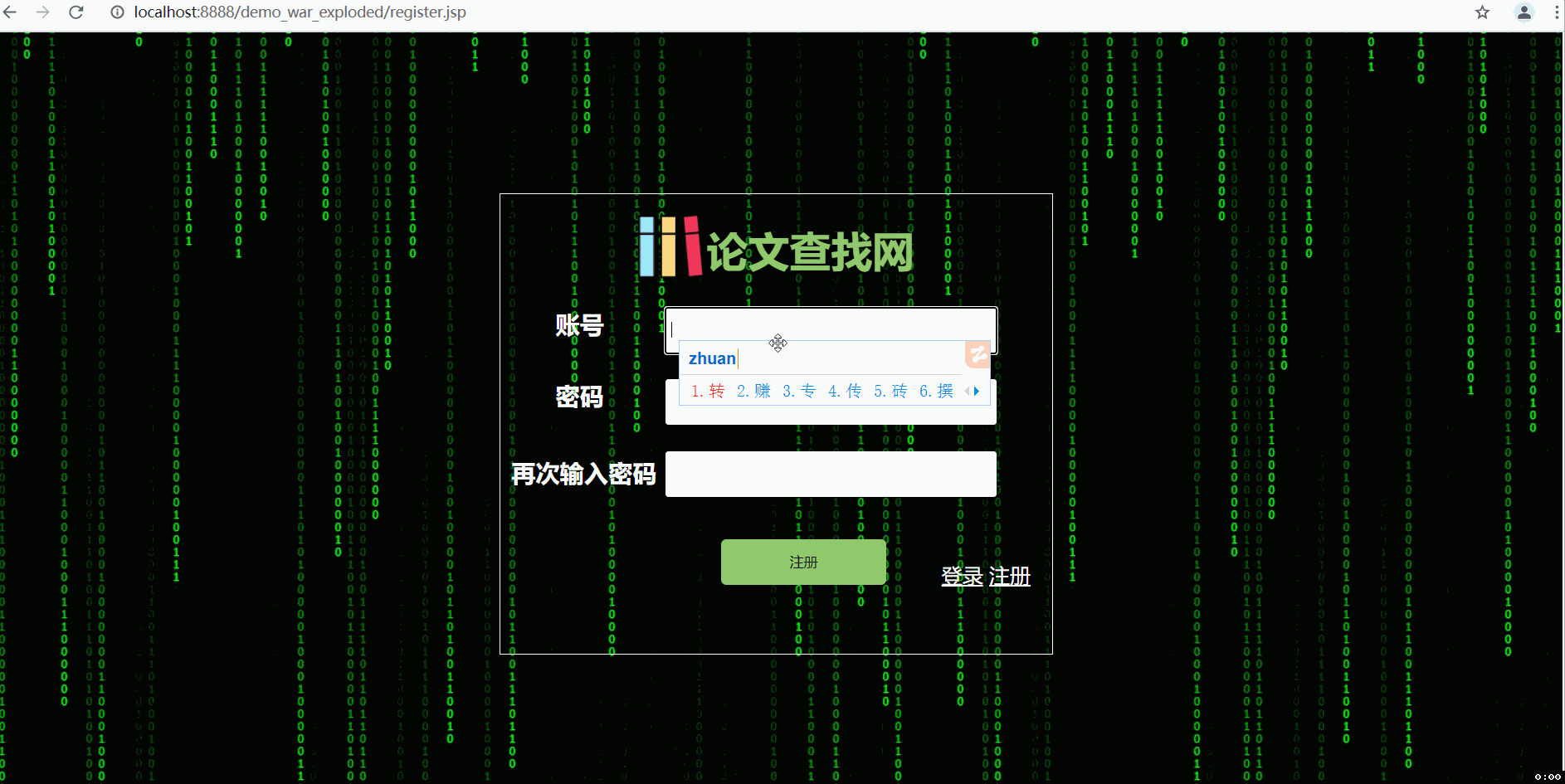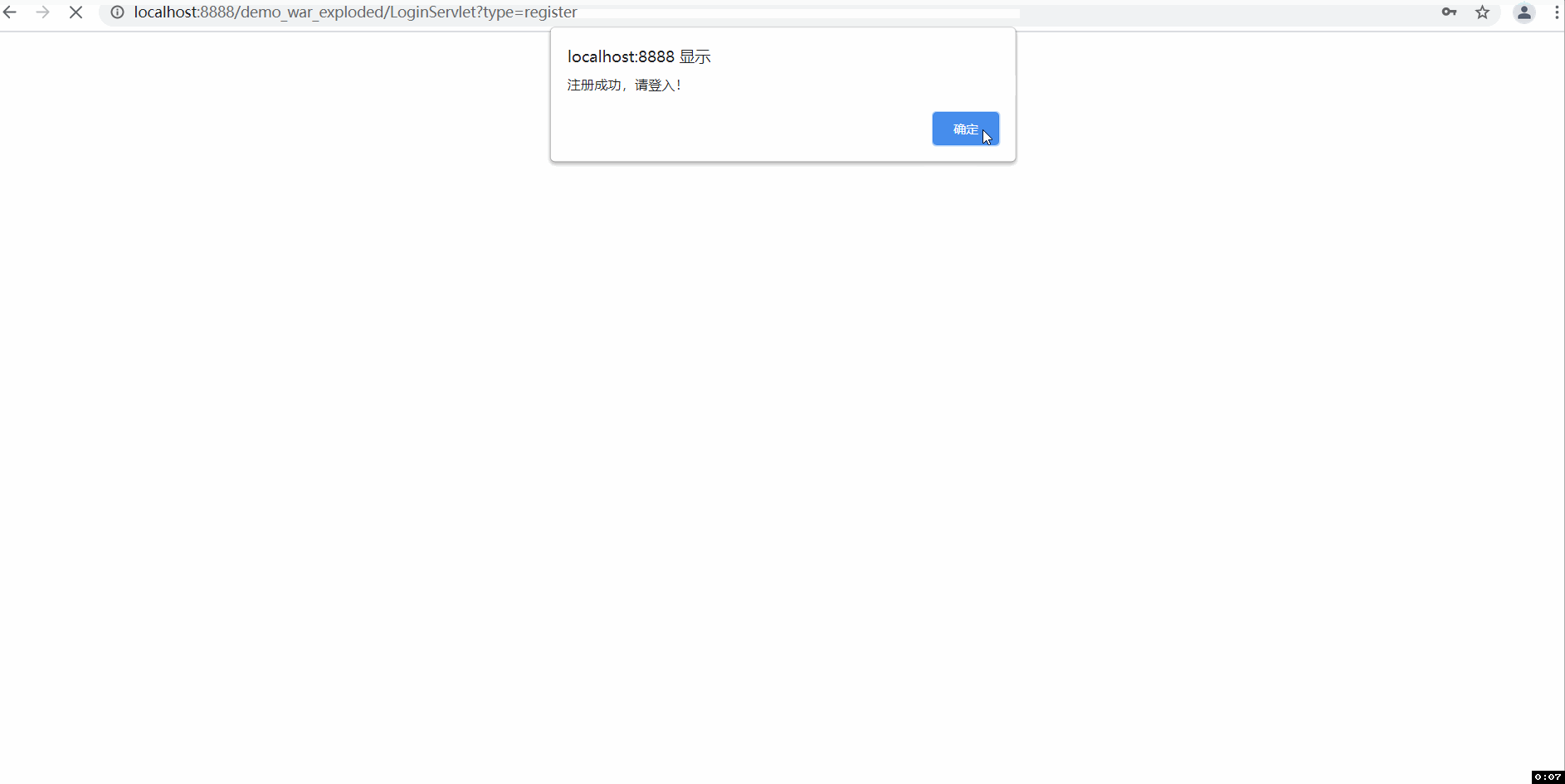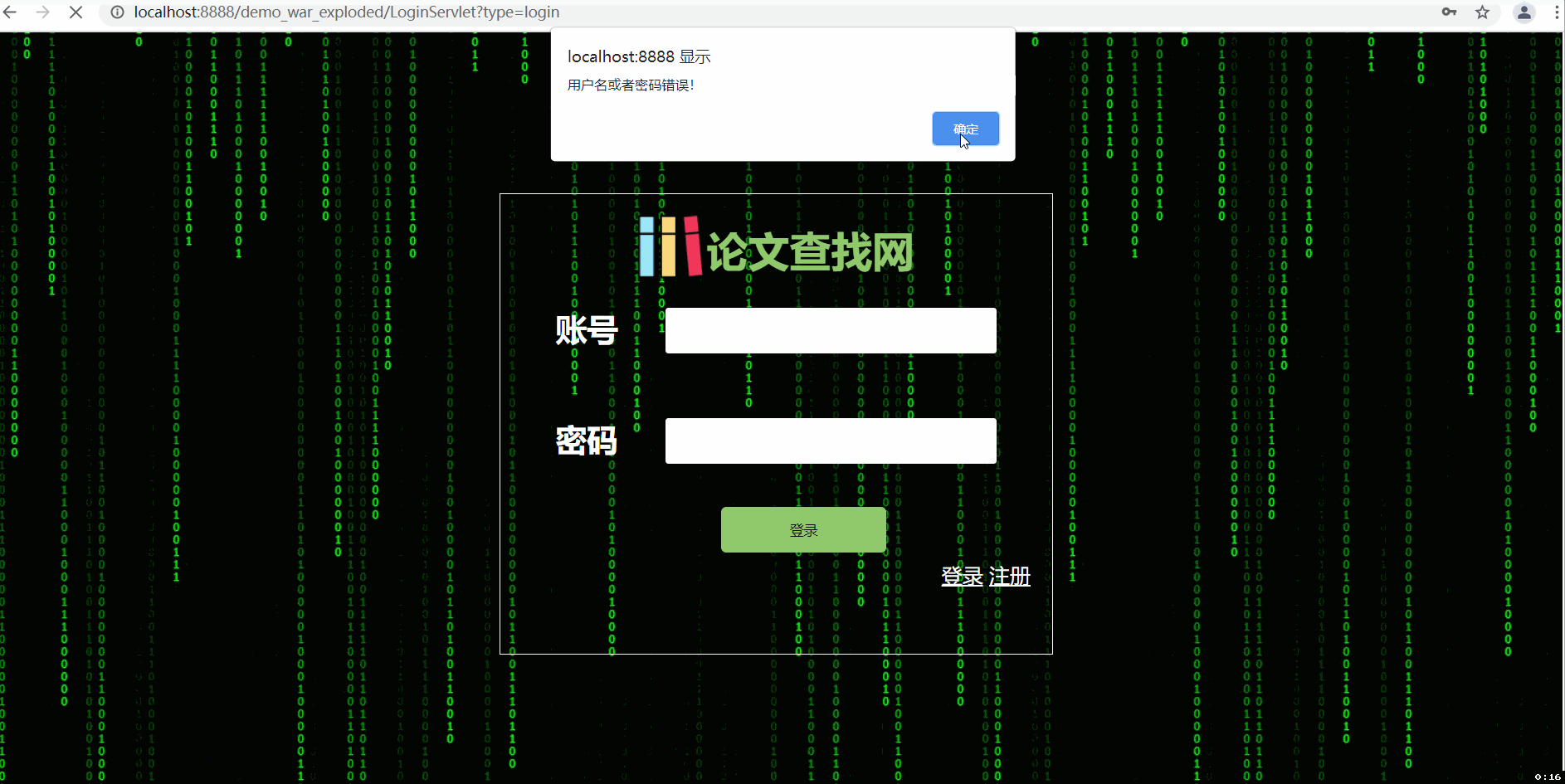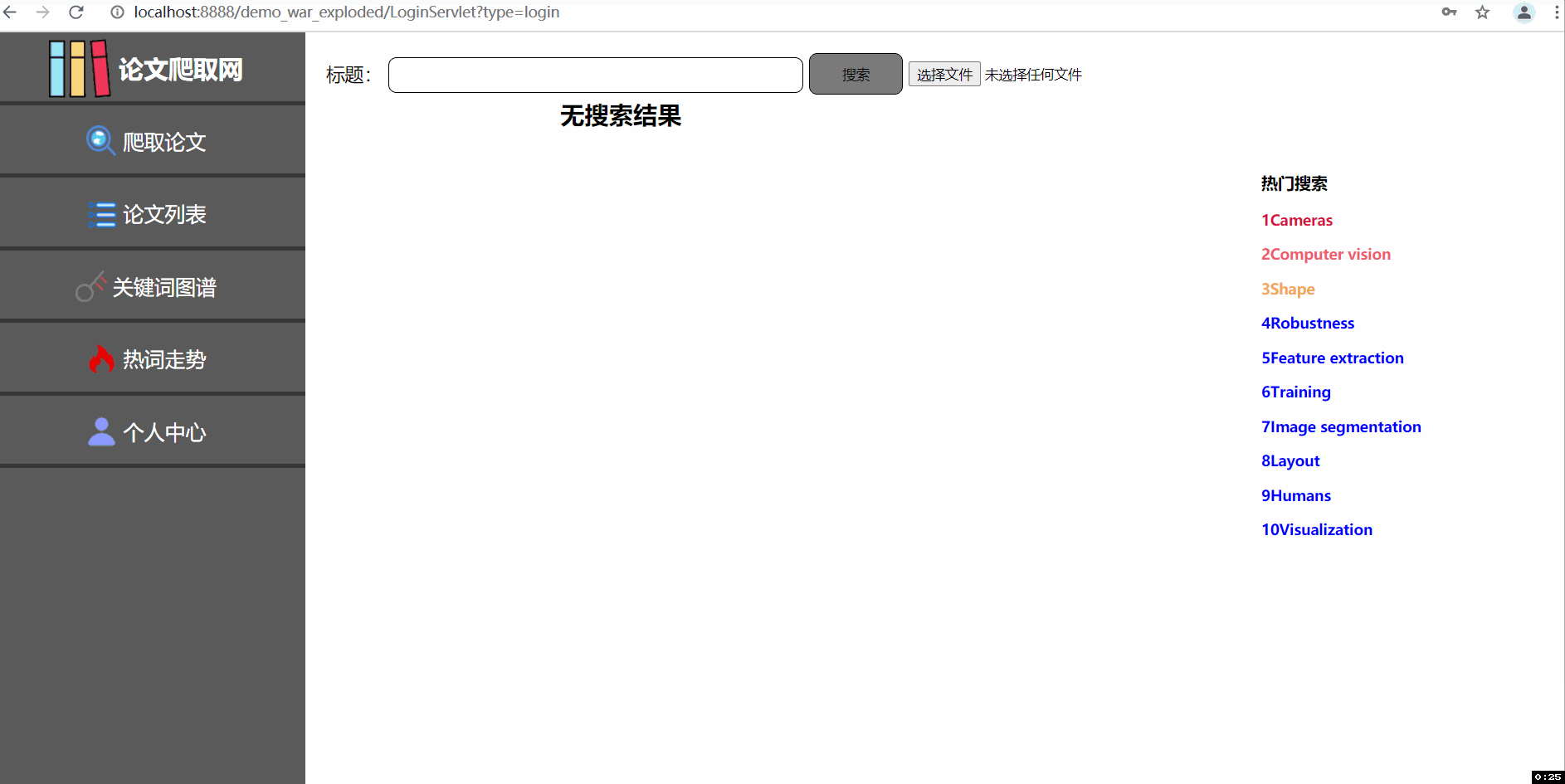
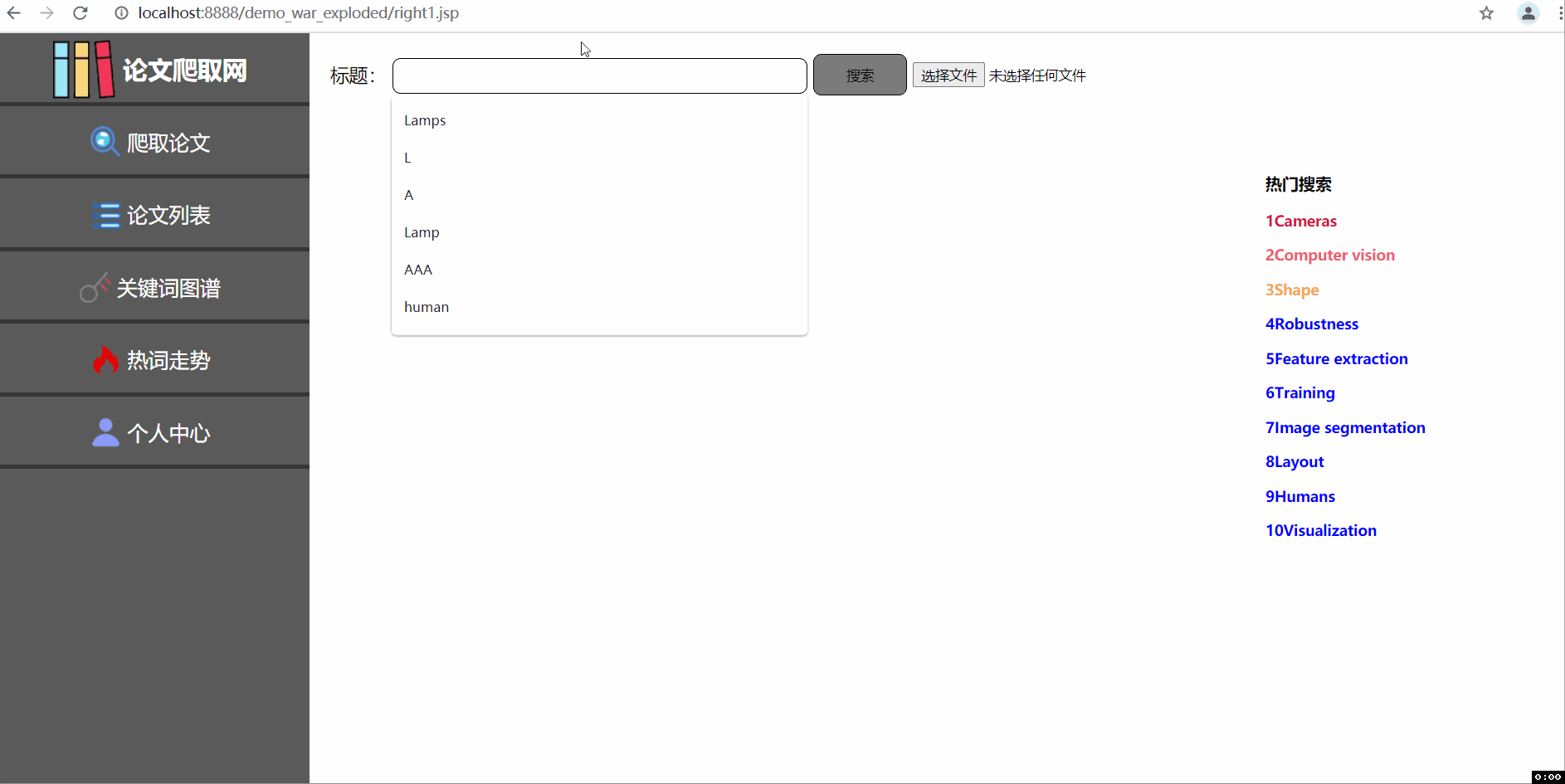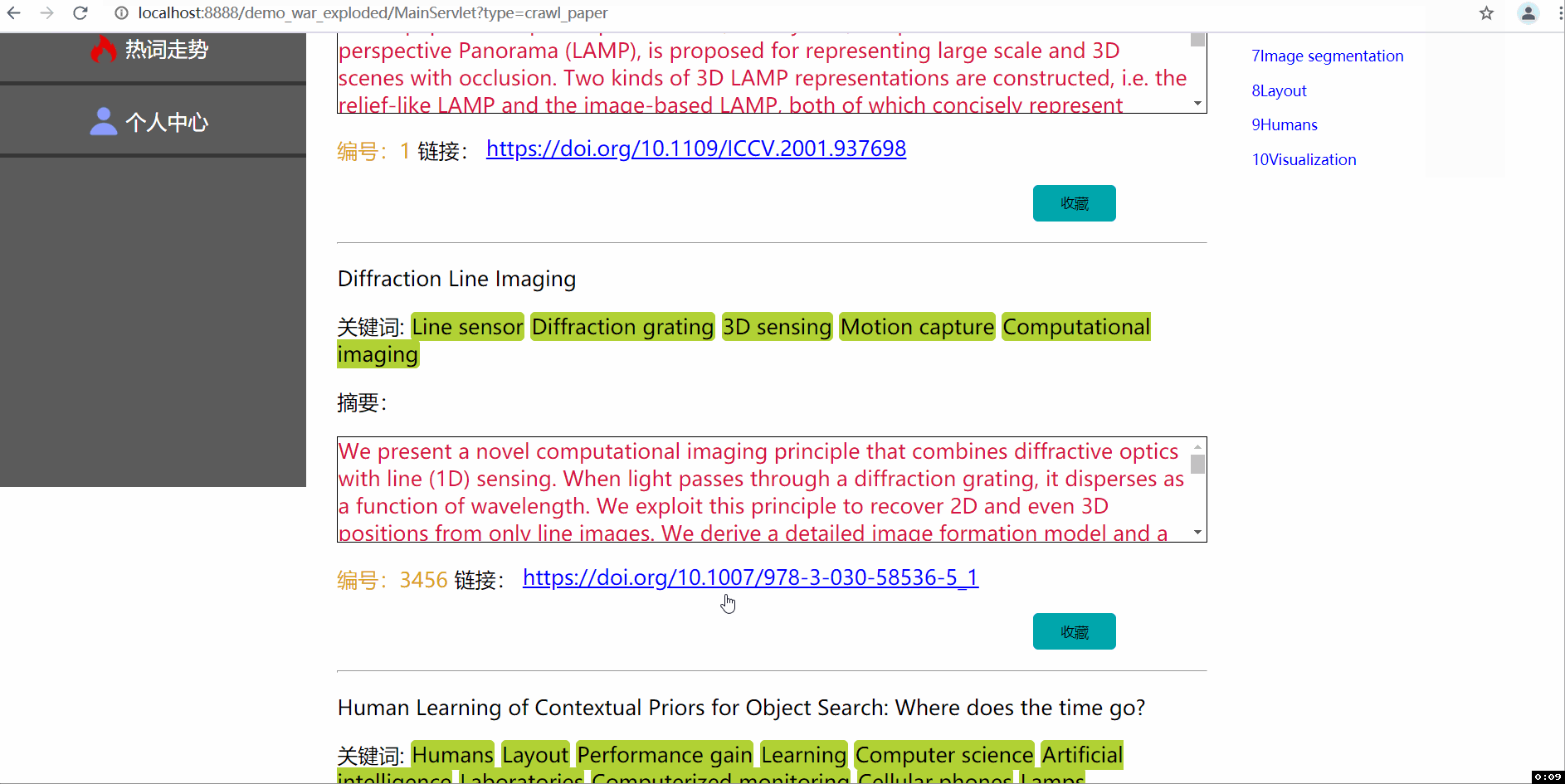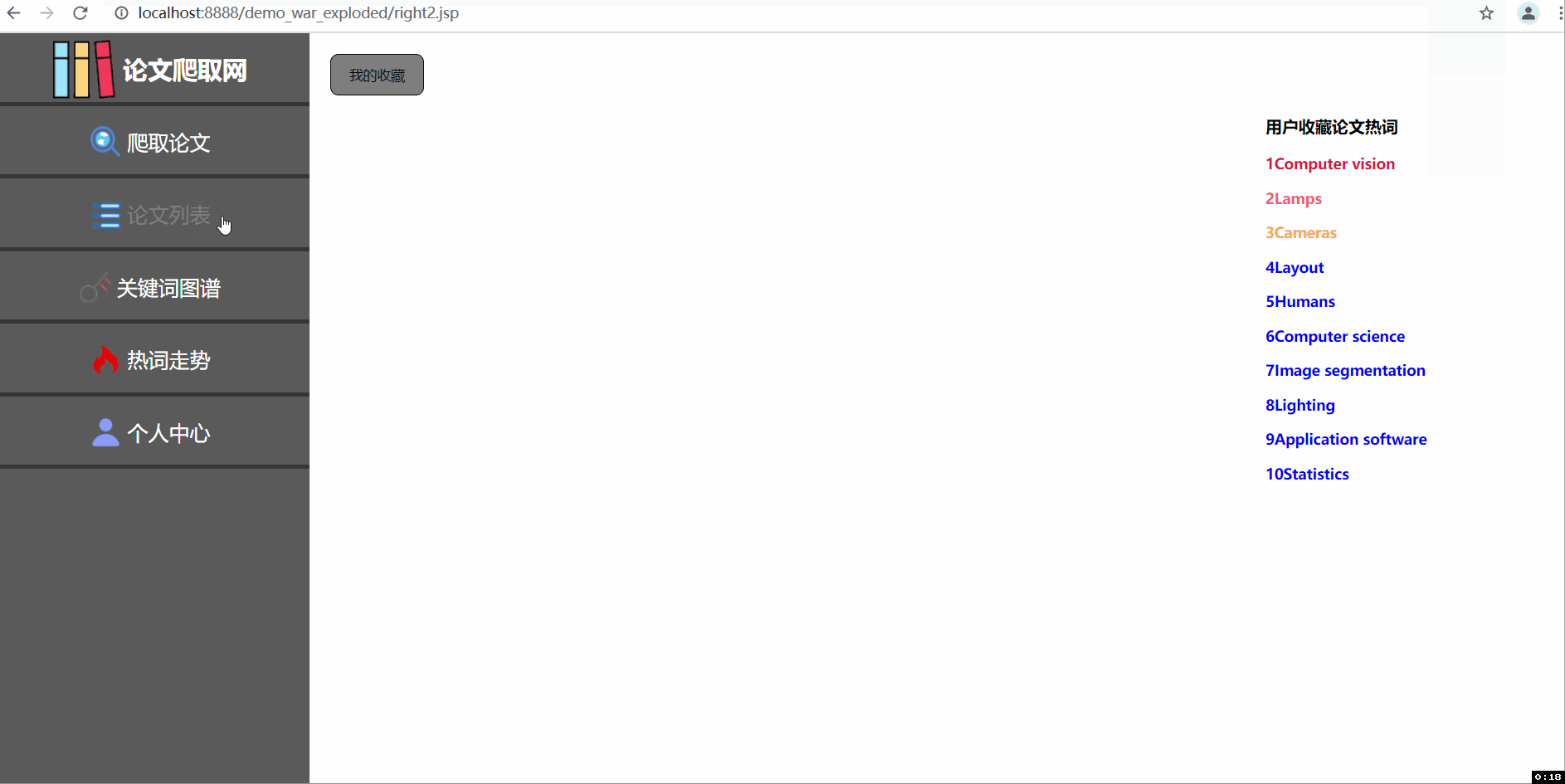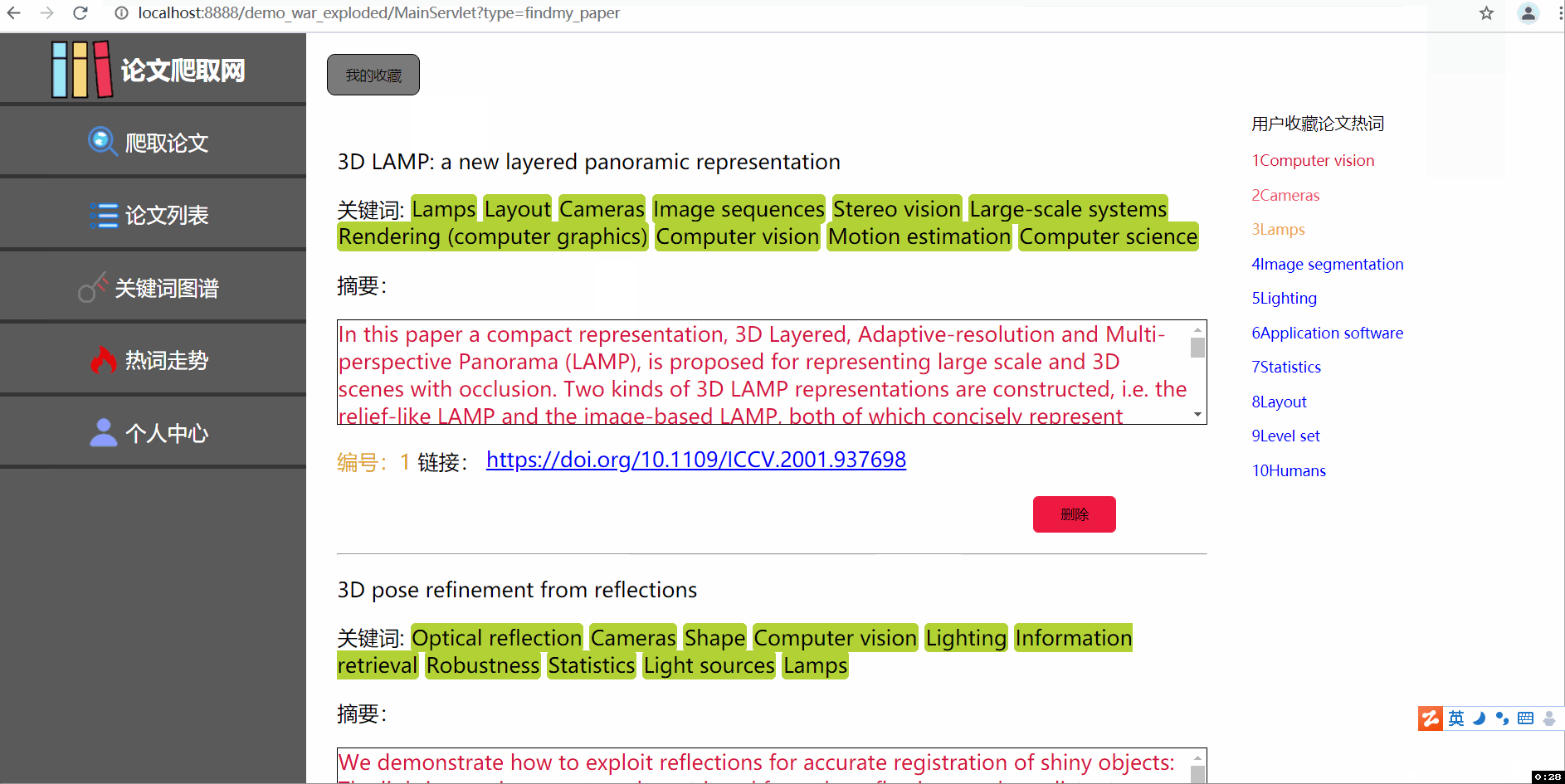

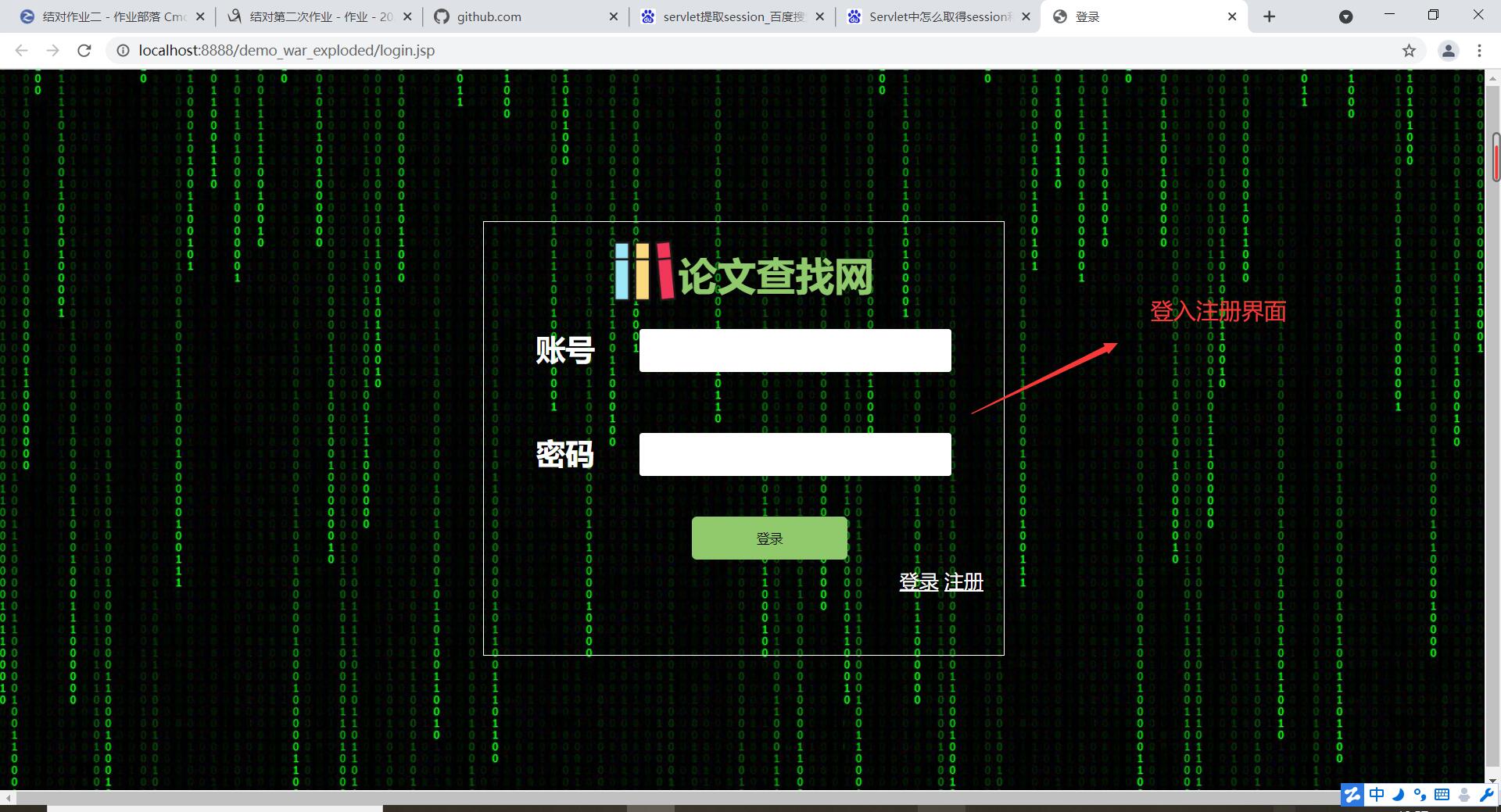
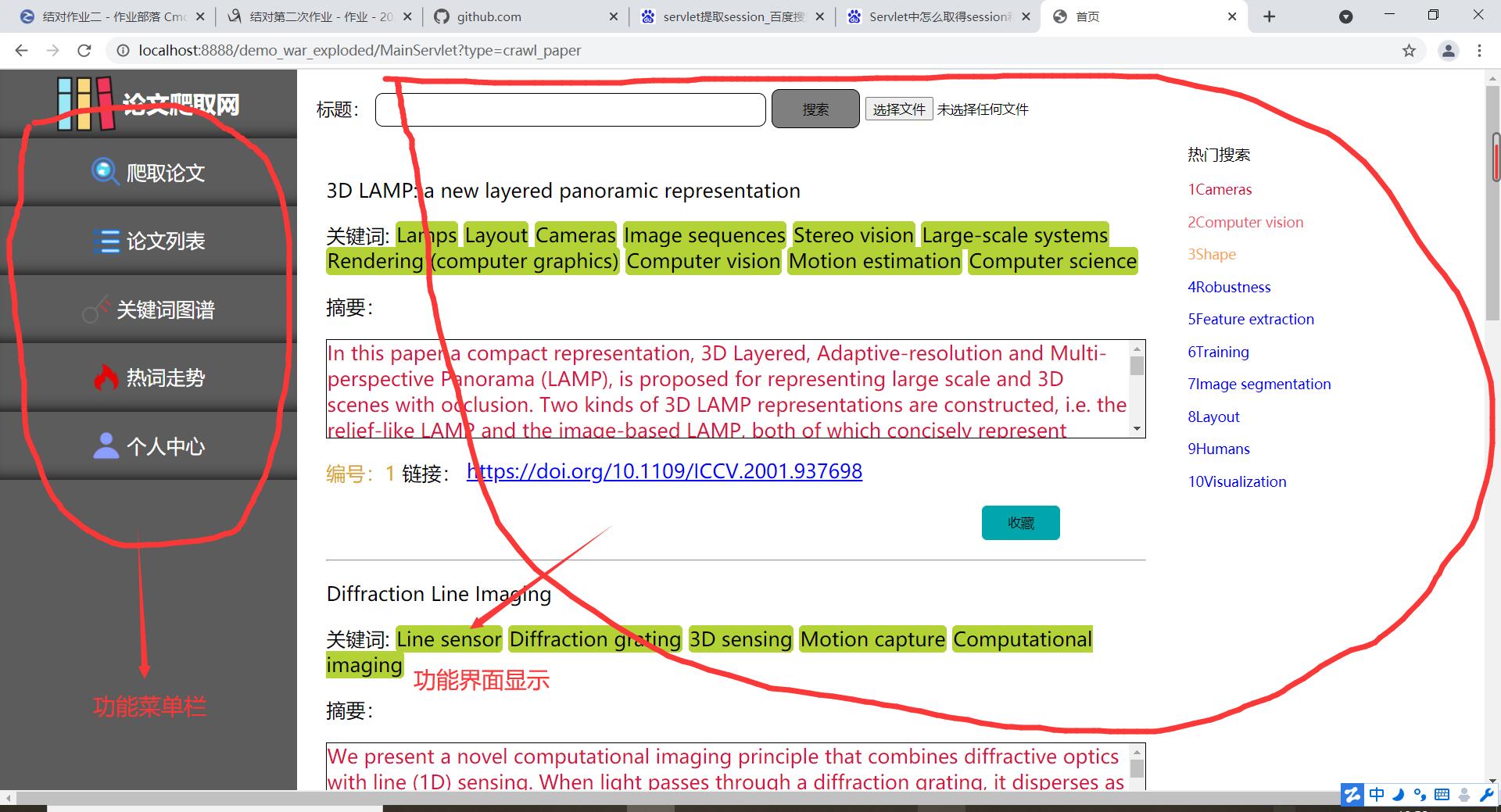
--三张动图分别是关于平台登入注册界面、论文查询收藏及删除功能(包括热词搜索和用户收藏论文的热词爬取)、三大分会论文热词可视化统计及用户管理中心。
4.结对讨论过程描述
- 刚刚拿到题目的时候,感觉挺难的,要涉及爬取,去网上找论文等等七七八八的东西,这些都还不会,就是一点构思都没有,都得通过网络查询。之前第一次结对作业整的功能稍微有点多,有的功能虽然较实用,但是感觉能力有限,设计的时候先砍掉了一些,日后有空有能力再去实现。开始讨论的时候根据老师的要求和推荐就打算使用最近在学的javaEE的servlet+jsp,老师之前有布置过一次相关的作业,有了解这个东西的使用(后来学习了spring框架,但是之前已经有这个方式编码了一些)
- 讨论的时候觉得也挺好分工的,一个人后端,一个人前端。作业布置后的两三天开始开动了。当时的时候根据能力,后端决定将老师给的论文json数据解析统计并导入数据库,因为每次调用论文都从文件取太麻烦了。前端的话采取html+css的静态代码加一点java。当时讨论决定先分开写,后端任务主要是论文解析,数据库建立,还有写论文统计和数据交互的接口;前端主要写登入注册界面以及用户功能界面,等写的差不多了再整合(这点后来在前后端交接的时候比较麻烦,出了些问题,有一说一应该完成一个模块就交接一次比较合理)


5.设计实现过程
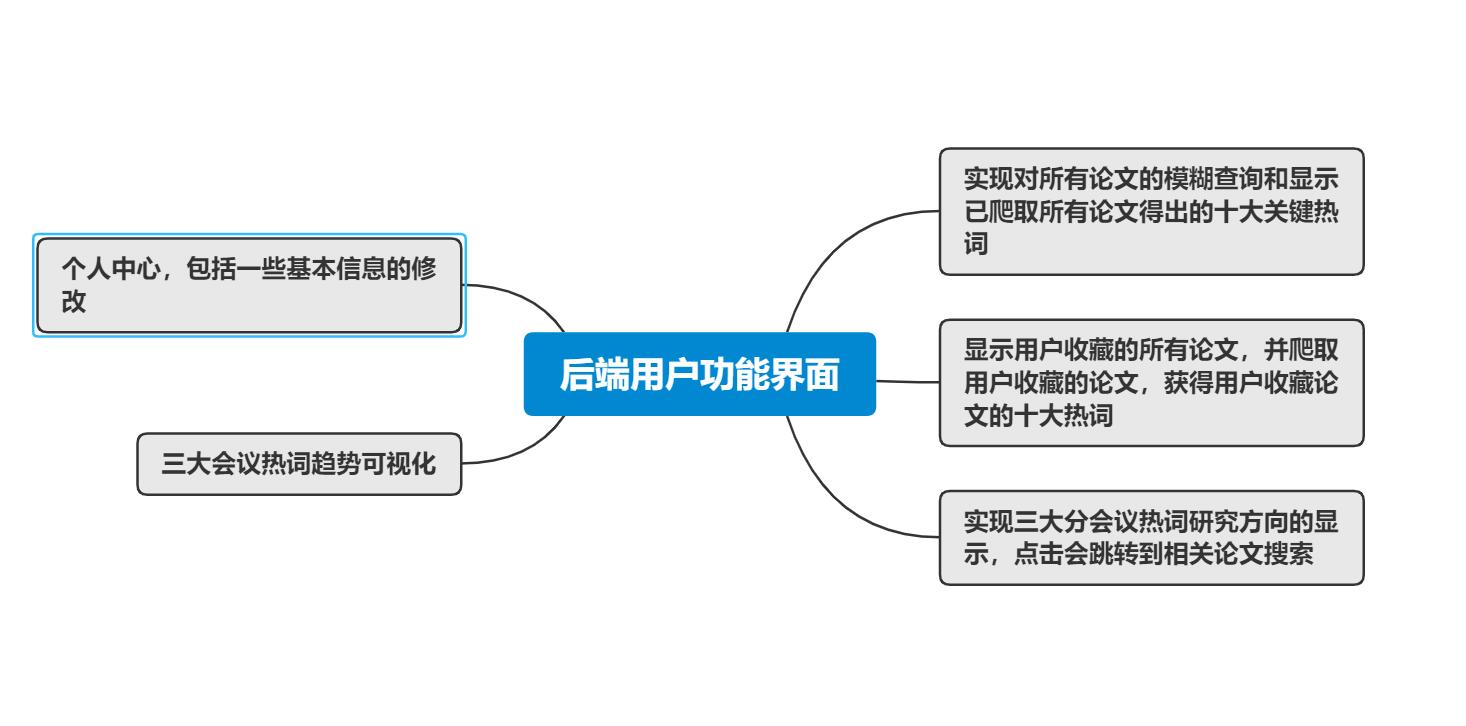
设计的话,前端延续上一次结对作业的建模,设计为两个主要界面,一个是登入注册界面,一个是用户功能界面。功能界面采取的时候左边菜单栏超链接跳转,右边显示具体功能。除了开始的登入注册界面之外,具体要实现的功能界面分为五个模块:
-
1实现对所有论文的模糊查询和显示已爬取所有论文得出的十大关键热词(所有论文指代助教提供的论文文件,里面㪰一万多篇统计好的)
-
2显示用户收藏的所有论文,并爬取用户收藏的论文,获得用户收藏论文的十大热词
-
3实现三大分会议热词研究方向的显示,点击会跳转到相关论文搜索
-
4三大会议热词趋势可视化
-
5个人中心,包括一些基本信息的修改
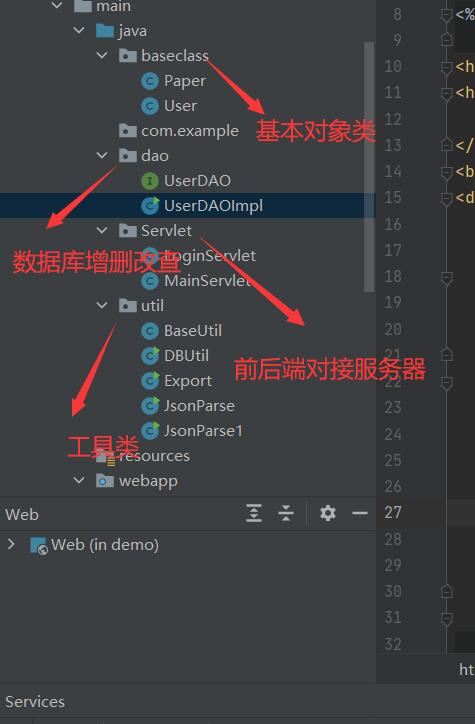
后端的话建立了用户数据表,以爬取的论文表,以及爬取结果表。后端代码结构上建立
dao包/servlet包/util包/pojo(baseClass)包,分别用来存储和数据库查询有关接口/前后端对接接口/工具类/自定义对象类。
-
功能结构图
6.代码说明
public interface UserDAO {
List<Paper> findPaper(String input) throws SQLException; //模糊查询从论文库里面找论文
List<Paper> findUserPaper(String username) throws SQLException; //找用户收藏的论文
User findUser(String name,String password)throws SQLException; //找是否存在这个用户,是的话返回用户类,不是的话返回null
boolean InsertUser(String name,String password)throws SQLException; //插入用户
public void updateUserInfo(List<String> keys,List<String> values,String name) throws SQLException; //修改用户单个信息(一次性多个字段修改,名字得放最后)
public boolean UserInsertPaper(String username,int paperNumber) throws SQLException; //添加用户收藏论文
public void UserDeletePaper(String username,int paperNumber) throws SQLException; //删除用户类收藏论文
public List<String> returnUserTenHotwords(String username) throws SQLException; //用来统计返回用户收藏论文里面的十大关键热词
public void writeTenhotwordsIntoDB(List<Map.Entry<String,Integer>> tenhotwords,String type) throws SQLException; //将总的和三大会议的十大热词存到数据库里面
public List<Map.Entry<String,Integer>> getTenHotwords(String type) throws SQLException; //读取十大热词
}
--1上述代码是所有有关数据库连接交互的接口
public List<Paper> findPaper(String input) throws SQLException {//模糊查询(目前只针对作者 )
List<Paper> papers = new ArrayList<>();
Connection connection = DBUtil.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement("select * from papers where title like ? or abstract like ? or keywords like ?");
preparedStatement.setString(1,"%"+input+"%");
preparedStatement.setString(2,"%"+input+"%");
preparedStatement.setString(3,"%"+input+"%");
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
Paper paper = new Paper();
paper.论文名称 = resultSet.getString("title");
paper.ID = resultSet.getInt("number");
paper.摘要 = resultSet.getString("abstract");
paper.会议和年份 = resultSet.getString("meetingtype") + " " + resultSet.getString("meetingyear");
paper.发布时间 = resultSet.getString("releasetime");
paper.原文链接 = resultSet.getString("link");
String[] keywords = resultSet.getString("keywords").split(",");
paper.关键词 = keywords;
papers.add(paper);
}
preparedStatement.close();
connection.close();
return papers;
}
--2上述代码段是进行论文模糊查询的函数,依据论文的关键词,标题和摘要进行模糊查询
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
switch (request.getParameter("type")){
case "crawl_paper":{
try {
List<Paper> list = userDAO.findPaper(request.getParameter("search_all_paper").trim());
if (list.size() == 0)
list = null;
request.setAttribute("right1Search",list);
if (request.getAttribute("login_error")!=null){
System.out.println(request.getAttribute("login_error"+"!!!!!!!!!!!!!!!!!!!!!!!!!!!!"));
}
request.getRequestDispatcher("/right1.jsp").forward(request, response);
} catch (SQLException throwables) {
throwables.printStackTrace();
}
break;
} //case结束
case "findmy_paper":{
...
break;
} //case结束
case "collect":{
...
break;
} //case结束
case "delete":{
...
break;
} //case结束
case "changeMessage":{
...
break;
}
case "changePassword":{
...
break;
}
}
}
--3和用户功能交互的Mainservlet的结构,采取在传来的路径后面添加?type=XXX 的方式
public class JsonParse {//将json文件写入数据库
Paper paper;
JSONObject jsonObject;
String url;
int number;
public JsonParse(int number,String url){
this.number = number;
this.url = url;
}
public void testPaper() throws IOException { //获取paper类
paper = getBean(Paper.class);
// System.out.println(paper);
}
private <T> T getBean(Class<T> t) throws IOException {
File file = new File(url);
String jsonString = FileUtils.readFileToString(file);
jsonObject = JSON.parseObject(jsonString);
return JSON.parseObject(jsonString,t);
}
public void writeDB() throws SQLException { //将文件读入的paper类写入数据库
String temp[] = paper.会议和年份.split(" ");
String temp1[] = paper.关键词;
StringBuffer stringBuffer = new StringBuffer();
for (String keyword : temp1){
stringBuffer.append(keyword+",");
}
String keywords = stringBuffer.toString();
Connection connection = DBUtil.getConnection();
Statement statement = connection.createStatement();
String sql = String.format("insert into papers values (%d,'%s','%s','%s','%s','%s','%s','%s')",number,paper.摘要,temp[0],temp[1],keywords,paper.发布时间,paper.论文名称,paper.原文链接);
statement.execute(sql);
statement.close();
connection.close();
}
}
--上述代码为根据制定路径解析改路径文件夹下所有的json文件,这个类主要是解析ECCV会议的论文json数据,这些json数据比较工整,直接建一个类用fastjson里面的JSON.parseObject()方法进行解析
<div id="main" style="width: 800px;height: 500px; float: left; margin-left: 100px;">CVPR</div>
<div id="main2" style="width: 800px;height: 500px; float: left; margin-left: 100px;margin-top: 50px">ECCV</div>
<div id="main3" style="width: 800px;height: 500px; float: left; margin-left: 100px;margin-top: 50px">ICCV</div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
option = {
title: {
text: 'CVPR热词'
},
tooltip: {},
legend: {
data:['热词']
},
xAxis: {
data: ["<%=s1.get(0).getKey()%>","<%=s1.get(1).getKey()%>","<%=s1.get(2).getKey()%>","<%=s1.get(3).getKey()%>","<%=s1.get(4).getKey()%>","<%=s1.get(5).getKey()%>","<%=s1.get(6).getKey()%>","<%=s1.get(7).getKey()%>","<%=s1.get(8).getKey()%>","<%=s1.get(9).getKey()%>"],
axisLabel: {
interval:0,
rotate:20
}
},
yAxis: {},
series: [{
name: '热词',
type: 'bar',
data: [<%=s1.get(0).getValue()%>, <%=s1.get(1).getValue()%>, <%=s1.get(2).getValue()%>, <%=s1.get(3).getValue()%>, <%=s1.get(4).getValue()%>, <%=s1.get(5).getValue()%>,<%=s1.get(6).getValue()%>,<%=s1.get(7).getValue()%>,<%=s1.get(8).getValue()%>,<%=s1.get(9).getValue()%>]
}]
};
myChart.setOption(option);
</script>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var chartDom2 = document.getElementById('main2');
var myChart2 = echarts.init(chartDom2);
var option2;
option2 = {
title: {
text: 'ECCV热词'
},
tooltip: {},
legend: {
data:['热词']
},
xAxis: {
data: ["<%=s2.get(0).getKey()%>","<%=s2.get(1).getKey()%>","<%=s2.get(2).getKey()%>","<%=s2.get(3).getKey()%>","<%=s2.get(4).getKey()%>","<%=s2.get(5).getKey()%>","<%=s2.get(6).getKey()%>","<%=s2.get(7).getKey()%>","<%=s2.get(8).getKey()%>","<%=s2.get(9).getKey()%>"],
axisLabel: {
interval:0,
rotate:20
}
},
yAxis: {},
series: [{
name: '热词',
type: 'bar',
data: [<%=s2.get(0).getValue()%>, <%=s2.get(1).getValue()%>, <%=s2.get(2).getValue()%>, <%=s2.get(3).getValue()%>, <%=s2.get(4).getValue()%>, <%=s2.get(5).getValue()%>,<%=s2.get(6).getValue()%>,<%=s2.get(7).getValue()%>,<%=s2.get(8).getValue()%>,<%=s2.get(9).getValue()%>]
}],
};
myChart2.setOption(option2);
</script>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var chartDom3 = document.getElementById('main3');
var myChart3 = echarts.init(chartDom3);
var option3;
option3 = {
title: {
text: 'ICCV热词'
},
tooltip: {},
legend: {
data:['热词']
},
xAxis: {
data: ["<%=s3.get(0).getKey()%>","<%=s3.get(1).getKey()%>","<%=s3.get(2).getKey()%>","<%=s3.get(3).getKey()%>","<%=s3.get(4).getKey()%>","<%=s3.get(5).getKey()%>","<%=s3.get(6).getKey()%>","<%=s3.get(7).getKey()%>","<%=s3.get(8).getKey()%>","<%=s3.get(9).getKey()%>"],
axisLabel: {
interval:0,
rotate:20
}
},
yAxis: {},
series: [{
name: '热词',
type: 'bar',
data: [<%=s3.get(0).getValue()%>, <%=s3.get(1).getValue()%>, <%=s3.get(2).getValue()%>, <%=s3.get(3).getValue()%>, <%=s3.get(4).getValue()%>, <%=s3.get(5).getValue()%>,<%=s3.get(6).getValue()%>,<%=s3.get(7).getValue()%>,<%=s3.get(8).getValue()%>,<%=s3.get(9).getValue()%>]
}],
grid: {
y2: 140
},
};
myChart3.setOption(option3);
</script>
--使用echarts表格来显示热词
<%
if (request.getAttribute("right1Search") == null) {
out.println("<h3 style=\"margin-left:20%;\">无搜索结果<h3>");
}
// else{
// List<Paper> list = (List<Paper>) request.getAttribute("right1Search");
// out.println("<p>"+list.size()+"</p>");
// }
else {
List<Paper> list = (List<Paper>) request.getAttribute("right1Search");
out.println("<div id = \"contentbyshearch\">");
for (int i = 0; i < list.size()&&i<20; i++){
out.println("<p style=\"color: black\">"+list.get(i).论文名称+"</p>");
out.println("<P>");
out.println("关键词:");
for (String s : list.get(i).关键词){
out.println("<label style=\"background-color: #B2D235;border-radius:5px 5px 5px 5px;border:1px solid #B2D235;\">"+s+"</label>");
}
out.println("</p>");
// out.println("<p style=\"color: #D71345\">");
// out.println("摘要:"+list.get(i).摘要);
// out.println("</p>");
out.println("<p>摘要:</p>");
out.println("<p style=\"overflow-y: scroll;height: 100px;color: #D71345;border:1px solid black\">");
out.println(list.get(i).摘要);
out.println("</p>");
out.println("<p>");
out.println("<span style=\"color: goldenrod\">编号:"+list.get(i).ID+"</span>");
out.println("<span>链接:</span>");
out.println("<a href=\"https://arxiv.org/pdf/2103.05494.pdf\" target=\"_blank\" style=\"display: inline;background-color: white;color: blue;\">"+list.get(i).原文链接+"</a>");
out.println("</p>");
%>
--使用for循环在jsp中输出搜索到的文章
7.心路历程和收获
- 221801127的心路历程:第一次写前端,心里一点底都没有,Axure构建出来的界面即使看起来很朴素,但具体写起来,还是有很多意想不到在的惊喜(惊吓),由于之前Axure的界面不是按模板来的,所以前端就只能手写了,一开始不是很熟练,一些位置啊,阴影啊,大小的使用都不熟练,很多场景下某些位置或大小属性会比较奇怪,出乎意料,往往达不到我想象的效果,甚至根本没有效果,但越写到后面,越明白套路了,也越来越会偷懒了,比如一开始CSS分开写,后来干脆不写外部CSS文件直接style属性改多香啊,就是复用性可读性可修改性比较那个一点。但纯写前端心态还好,到了对接后端接口,问题就来了,一会前端显示不太对劲,一会servlet不太对劲,一会后端函数不太对劲,一会白屏,一会500错误,一会突然发现前端和后端交互需要的一些参数不全,或较难传完整,于是对接这块花了很多时间,并且有些本来写好的功能因为一些原因给砍了,前端后端都写了,但出于时间和技术就未能完美实现。
- 221801127的收获:这次结对不仅帮我的锻炼了前端的最基础的html和css,并且学会使用echarts。而且还加深了,前端和后端通过交互时的表单属性和内容使用,jsp动态加载页面内容,jsp和servlet通过request,session进行通讯交互的方法,对了除了技术上,还体会了结对编程指指点点的乐趣。
- 221801106的心路历程:之前在java的实践时候写过一次后端,这一次团队作业和结对编程也都是写后端。感觉自己对后端的结构和逻辑还是挺清楚的。个人编程的时间开始得比较晚一点,然后集中在几天写完了后端的代码,不过有一点我没有做得好,就是服务器连接那部分没有怎么考虑,是最后前后端都写好了对接编程的时候一起打的,感觉这部分应该算是我的工作,或者应该要结对编程。在写后端的时候框架和javaEE课上老师作业建立的是一样的。写的过程中也遇到了挺多的问题,比如数据库非string报错,没有考虑读入的字符串可能含有''。在mysql那边出了一些错,特别是空指针的错误,自己设计的逻辑真的还不够完善。在json解析那边也出现过json文件某个字段没有或者结构不同的错误,花了挺多时间在纠错,终归是自己项目经验少的原因。
- 221801106的收获:对数据库建表还有增删改查更熟悉了,和数据库有关的报错大部分都能很快找到了。对于hashmap和list的使用印象加深,java代码容易出现的一些bug也记住了。然后是对于jsp和servlet这种方式的构建更清晰了。自己写后端的时候bug挺好找的,但是在前后端交接的时候出现了一些没有考虑的问题。
8.评价结对队友
22180106对221801127评价:挺负责的,会经常催我打代码。就是有时候有点凶,太专注了没注意队友的感觉。主要还是我个人不太行,太菜了。
22180127对221801106评价:
这次感觉写后端bug出的数量并不多,毕竟我上我肯定是一堆bug,而前端没有这些问题,并且对接时代码出问题一般在servlet或后端函数,所以结对对接时我态度比较嘴臭,但后端同学还是十分温顺,认真合作,他说他不太行是谦虚之语,后端看着都头晕我上肯定不行。


