软工实践寒假作业(2/2)
软件工程实践2021第二次寒假作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/FZUSESPR21 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/FZUSESPR21/homework/11672 |
| 这个作业的目标 | 任务一:阅读《构建之法》并提问[1] 阅读教材[2] 参考作业要求以及关于如何提问的链接,提出你仍然不懂的5到10个问题[3] 时间充裕则完成附加题 任务二:完成词频统计个人作业[1] 学习使用git以及github[2] 记录PSP表格[3] 制定自己的代码规范[4] Fork项目到自己的仓库[5] 分多次commit代码,完成项目[6] 代码性能分析改进[7] 学习并进行单元测试[8] 发起Pull Request |
| 作业正文 | https://www.cnblogs.com/fzu221801127/p/14470483.html |
| 其他参考文献 | ... |
part1:阅读《构建之法》并提问&附加题
-
我看了P25的对话,我不是很理解对话中提到了任何一个需求都可以表示成一个单元测试。我查了下百度有个叫‘需求覆盖’的说法,但也没说任何需求都可以对应一个单元测试,但根据经验,貌似任何需求都确实可以对应一个单元测试,感觉只要涉及某种输入输出情况肯定可以对应单元测试的。但对于性能的需求貌似不是用单元测试的吧,这个疑点不太明白?
-
还是P25的对话,最后两句对话可以得知单元测试如果不是写着玩玩的,在模板被使用下还是很有必要写单元测试的。我有个问题:我以前从来没写过单元测试,即使经常出现bug,但我总觉得单元测试从性价比上还不一定有找bug来得快?我查了下知乎关于开发要不要单元测试,发现很多人也说时间成本太高了,认真的话可能的有2/3时间在单元测试,而且有人说大部分公司都是选择不写单元测试的,即有这样一个现象:所有人都赞同单元测试非常重要,然而很少人做单元测试。根据我以往的经验,没有单元测试开发除了在用户没有具体提出的要求如输入异常检验这类东西没有实现好,其他功能在‘正确’使用下最后也都没有问题。所以我对单元测试的必要性不太认同,只觉得可以但没必要?
-
看了P32的效能分析,但效能分析什么时候终止,是主观判断吗? 我查了下效能分析貌似不能直接得出算法是否好,而是通过人对数据的判断,这样可以逐步升级算法。如果有被硬性要求还好说,但根据经验没有要求的话往往直接凭感觉已经优化到极致了就不优化了。难道效能分析程度是取决于人而不是需求吗?
-
书本中提到软件测试人员的代码能力要很强,我认为说法不太正确。书上的解释是因为测试人员是最后一道防线。感觉意思是测试人员写的代码没专业人员测试所以对原代码质量要求高,不然出问题就麻烦了。但我还是不太懂,这不就是在说没有经过专业测试的代码必须由代码质量高的人写才安全,这貌似和测试人员代码质量要求高没什么关系,而是没人能测试的代码质量要求高才对?
-
P324页形容全栈工程师为‘一个乐团的优秀小提琴手在交响乐演出的时候在台上跑来跑去,搞定其他所有乐器’,有这个问题:我认为这个形容不够贴切,软件又不是边开发用户边使用,应该形容成‘一个电音从业者,使用用各种演奏声音合成一个乐曲然后发布’。这样一来全栈人员的就有其存在意义了。虽然很明显,全栈开发不了太大的项目。但我有个困惑,很多知名的软件一开始立项和前期研发只有一两个开发人员,但后期产品火爆再招人不断升级产品不也是最开始的那个全栈起了个好头吗,全栈不也可以成就一个大项目嘛。
附加题(大家知道了软件和软件工程的起源,请问软件工程发展的过程中有什么你觉得有趣的冷知识和故事?):
资料引用:史上第一位程序员是名贵族小姐,话说这位贵族小姐,她来头不小。是19世纪英国著名诗人拜伦的女儿,她是一名数学家,也是世界上第一位程序员。她的名字是AdaLovelace。(由于名字较长,下面简称阿达)阿达一生做出的成就不少。她设计了巴贝奇分析机上解伯努利方程的一个程序,证明了计算机狂人巴贝奇的分析其可以用于许多问题的求解。
后来她在1843年发表的论文里提到了一个叫循环和子程序的概念,并且她相信以后创作复杂音乐、制图和科学研究是可以通过机器来创作的,这在当时是大胆的预见,但在今天都逐渐成为了现实。
现在看来,阿达首先为计算机拟定的“算法”,以及写作的那份“程序设计流程图”都是极为难得和珍贵的,也是史上第一件计算机程序。
后来据说国防部花了10年时间,把所需软件的全部功能混合在一种计算机语言里,为的是想让它能成为军方数千种电脑的标准。
于是在1981年,为了纪念这位程序员,这种语言被正式命名为ADA(阿达)语言,艾达·洛夫雷斯也被公认为“世界上第一位软件工程师”。
个人见解:难以想象一个200多年前出生的人可以预见通过机器创作复杂音乐、制图和科学研究这一未来,循环、子程序、‘算法’、‘程序设计流程图’都不禁让我怀疑这是不是一个穿越到过去的程序员。第一个程序员是数学家,是诗人之子女,那现在的程序会不会在未来和诗歌一样成为古诗、古画之类的待遇,成为一种源远流长的艺术?毕竟程序员或者计算机科学家出圈的太少了,或者几乎没有,中学科比都是都是文学家、数学家、政治家、化学家,貌似没有计算机科学家,计算机程序的历史比大多学科短,在很久以后可能变成实用性低的一门艺术了吧,相关从业者也和诗人一样极为稀少了吧。
part2:WordCount编程
Github项目地址
这边我的主体开发都是在分支branchone里面完成的,其中version2.2版本之前的所有代码都可以完全看到我的WordCount()、Lib()、LibTest()类,其中LibTest()是单元测试(后面的提交版本会ignore掉)。
https://github.com/fzu221801127/PersonalProject-Java/tree/test3
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| • Estimate | • 估计这个任务需要多少时间 | 1670 | 2350 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 500 | 500 |
| • Design Spec | • 生成设计文档 | 45 | 45 |
| • Design Review | • 设计复审 | 45 | 90 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 60 | 75 |
| • Design | • 具体设计 | 90 | 90 |
| • Coding | • 具体编码 | 360 | 400 |
| • Code Review | • 代码复审 | 60 | 100 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 240 | 300 |
| Reporting | 报告 | 100 | 200 |
| • Test Repor | • 测试报告 | 60 | 120 |
| • Size Measurement | • 计算工作量 | 20 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 1670 | 1970 |
代码规范制定链接
https://github.com/fzu221801127/PersonalProject-Java/blob/test3/221801127/codestyle.md
设计与实现过程
下图结合上面解题思路描述可以比较清晰看清思路:
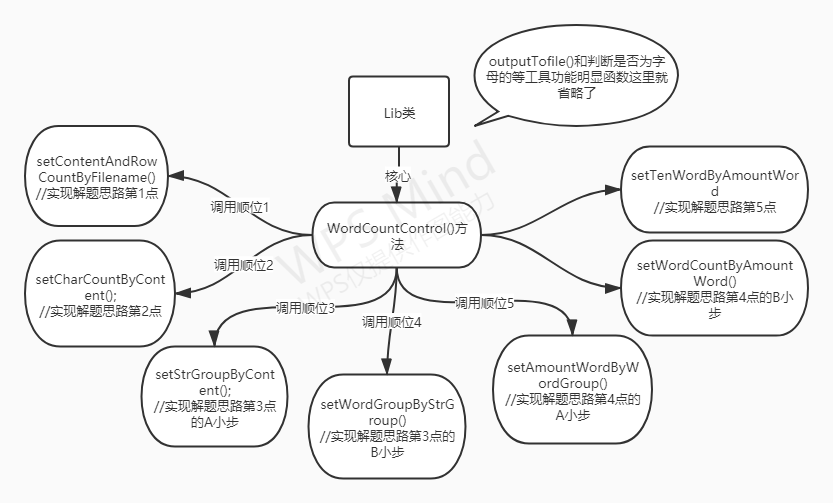
体现在代码中就是WordCountControl()方法内部是这样的:
this.setContentAndRowCountByFilename(this.inFilename);
this.setCharCountByContent(this.content);
this.setStrGroupByContent(this.content);
this.setWordGroupByStrGroup(this.strGroup);
this.setAmountWordByWordGroup(this.wordGroup);
this.setWordCountByAmountWord(this.getAmountWord());
this.setTenWordByAmountWord(this.amountWord);
环环相扣,看起来好像不太好,但每一步都需要前面几步得到的参数,这样的过程式编程在这题也是无可奈何之选。举个例子:排出10个次数最多的单词,我的方法就是:1、读文件获得文章内容(String)。2、分割文章内容成块(ArrayList
显然,这个过程需拆分成多个函数实现比较合理,并且这个过程所需函数基本包含了其他题给要求所需的函数。
而且还有一个特点,这些函数有一个调用顺序关系,于是我在写代码过程中这些方法是逐个实现的,然后每实现一个方法检查一下题目中的4个指标哪个所需条件基本满足了就去实现。并且每写一个函数就先单元测试一下,通过这次作业我发现每次实现一个函数都去单元测试调到100%确实有点累人,有时候人都快调崩溃了,但这样的好处也很明显,这样就可以从来不会因为前面函数有严重bug导致问题并且特别难找那种。
集中控制各函数实现题目需求的WordCountControl()代码如下:
逻辑就是处理输入输出并按顺序调用各个函数完成相应功能,其功能与调用的工具函数的功能可以看上面的两种图片。
/*集中控制各函数实现题目需求*/
public void WordCountControl(String argsInput, String argsOutput) throws IOException {
this.inFilename = argsInput;
this.outFilename = argsOutput;
Scanner in = new Scanner(System.in);
File f1 = new File(this.inFilename);
while (!f1.exists()) {
System.out.println("找不到路径为 " + this.inFilename + " 的文件,请重新输入input文件路径:");
this.inFilename = in.next();
f1 = new File(this.inFilename);
}
File f2 = new File(this.outFilename);
while (!f2.exists()) {
System.out.println("找不到路径为 " + this.outFilename + " 的文件,请重新输入output文件路径:");
this.outFilename = in.next();
f2 = new File(this.outFilename);
}
//this.inFilename = "C:/Users/谷雨/Desktop/input.txt";
//this.outFilename = "C:/Users/谷雨/Desktop/output.txt";
this.setContentAndRowCountByFilename(this.inFilename);
this.setCharCountByContent(this.content);
this.setStrGroupByContent(this.content);
this.setWordGroupByStrGroup(this.strGroup);
this.setAmountWordByWordGroup(this.wordGroup);
this.setWordCountByAmountWord(this.getAmountWord());
this.setTenWordByAmountWord(this.amountWord);
String temporaryData1 = "characters:" + getCharCount() + "\n" + "words:" + getWordCount() + "\n" +
"lines:" + getRowCount() + "\n";
ArrayList<String> temporaryData2 = this.tenWord;
this.outputTofile(this.outFilename, temporaryData1, temporaryData2);
System.out.println("characters:" + getCharCount());
System.out.println("words:" + getWordCount());
System.out.println("lines:" + getRowCount());
for (String s : this.tenWord) {
System.out.println(s.toLowerCase()+":"+this.amountWord2.get(s));
}
}
setTenWordByAmountWord()方法循环10次或单词个数次从Map对象中获取词频最高的10个或单词个数个单词代码,也是所有工具方法中最最最长的工具方法,对于这题也是性能改进往往最举足轻重的部分,如下:
/*获取词频最高的十个单词*/
public void setTenWordByAmountWord(HashMap<String,Integer> amountWord) {
this.tenWord = new ArrayList<String>();
String maxWord = "";
if (amountWord.size() >= 10) {
for (int i = 0; i < 10; i++) {
for (String s : amountWord.keySet()) {
if (maxWord.isEmpty()) {
maxWord = s;
}
else {
if (amountWord.get(maxWord) < amountWord.get(s)) {
maxWord = s;
}
else if (amountWord.get(maxWord) > amountWord.get(s)) {}
else if (amountWord.get(maxWord) == amountWord.get(s)){
if (maxWord.compareTo(s) > 0) {
maxWord = s;
}
else {}
}
}
}
amountWord.remove(maxWord);
this.tenWord.add(maxWord);
maxWord = "";
}
}
else {
int size = amountWord.size();
for (int i = 0; i < size; i++) {
for (String s : amountWord.keySet()) {
if (maxWord.isEmpty()) {
maxWord = s;
}
else {
if (amountWord.get(maxWord) < amountWord.get(s)) {
maxWord = s;
}
else if (amountWord.get(maxWord) > amountWord.get(s)) {}
else if (amountWord.get(maxWord) == amountWord.get(s)){
if (maxWord.compareTo(s) > 0) {
maxWord = s;
}
else {}
}
}
}
amountWord.remove(maxWord);
this.tenWord.add(maxWord);
maxWord = "";
}
}
}
性能改进
一开始是采用比较常规的做法来找出频率最高的单词的:用sort排序单词频率的Map对象。
但这个做法在单词种类很多的情况下,就比较费时间了,在单词较多时用Junit进行测试时也发现运行时间占据一大部分的是这个找10个频率最高单词的方法,于是要改进性能显然主要是改进搜索方法。
于是我采用了10次或单词个数次的for循环,每次for循环分别找出频率第一第二...的单词就行了。代码实现如下:
public void setTenWordByAmountWord(HashMap<String,Integer> amountWord) {
this.tenWord = new ArrayList<String>();
String maxWord = "";
if (amountWord.size() >= 10) {
for (int i = 0; i < 10; i++) {
for (String s : amountWord.keySet()) {
if (maxWord.isEmpty()) {
maxWord = s;
}
else {
if (amountWord.get(maxWord) < amountWord.get(s)) {
maxWord = s;
}
else if (amountWord.get(maxWord) > amountWord.get(s)) {}
else if (amountWord.get(maxWord) == amountWord.get(s)){
if (maxWord.compareTo(s) > 0) {
maxWord = s;
}
else {}
}
}
}
amountWord.remove(maxWord);
this.tenWord.add(maxWord);
maxWord = "";
}
}
else {
int size = amountWord.size();
for (int i = 0; i < size; i++) {
for (String s : amountWord.keySet()) {
if (maxWord.isEmpty()) {
maxWord = s;
}
else {
if (amountWord.get(maxWord) < amountWord.get(s)) {
maxWord = s;
}
else if (amountWord.get(maxWord) > amountWord.get(s)) {}
else if (amountWord.get(maxWord) == amountWord.get(s)){
if (maxWord.compareTo(s) > 0) {
maxWord = s;
}
else {}
}
}
}
amountWord.remove(maxWord);
this.tenWord.add(maxWord);
maxWord = "";
}
}
}
下面我一个什么都有,代码各种符号文章都有中文也有,并且高达1W行67W字符来测一下性能如下:
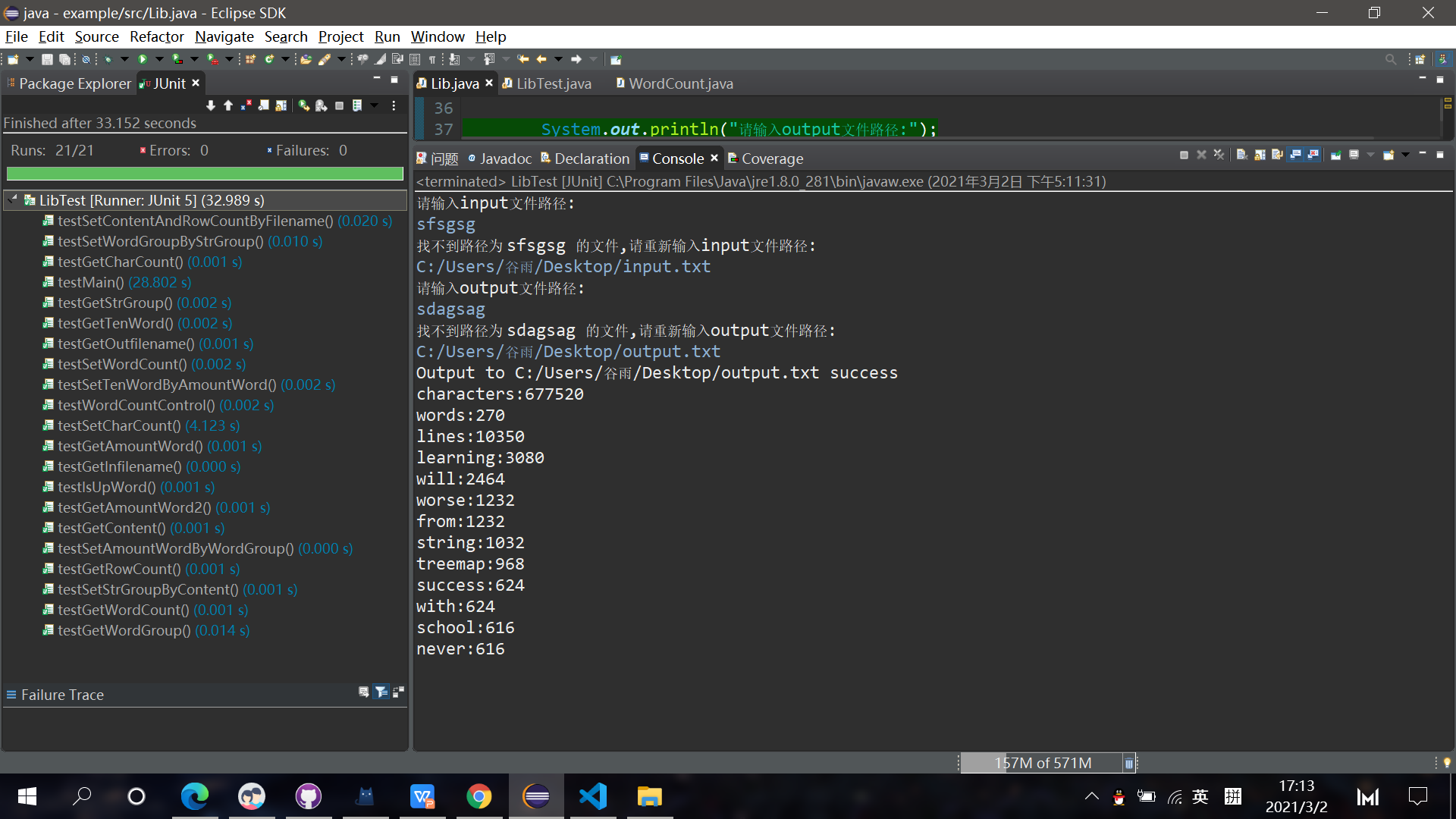
首先,单元测试里面的testMain方法先排除,因为那包含我输入文件名的时间,然后分析可知现在性能瓶颈不是排序单词的单元测试,而是testSetCharCount()的单元测试函数,该函数主要代码如下:
@Test
void testSetCharCount() throws IOException {
lib.setContentAndRowCountByFilename(inputTestFile);
lib.setCharCountByContent(lib.getContent());
}
显然现在最费时费空间的操作就是读取文件存入String和数出文件中的字符数量了,这个应该接近最优了,除非有更快的读文件方法,也就是找频率最高单词其他一些功能已经比较快了,所以读文件数字符数量操作才显得很慢,所以其他部分性能优化应该还不错了。
单元测试
我github上基本每次提交的代码都是单元测试弄到100%再commit的。
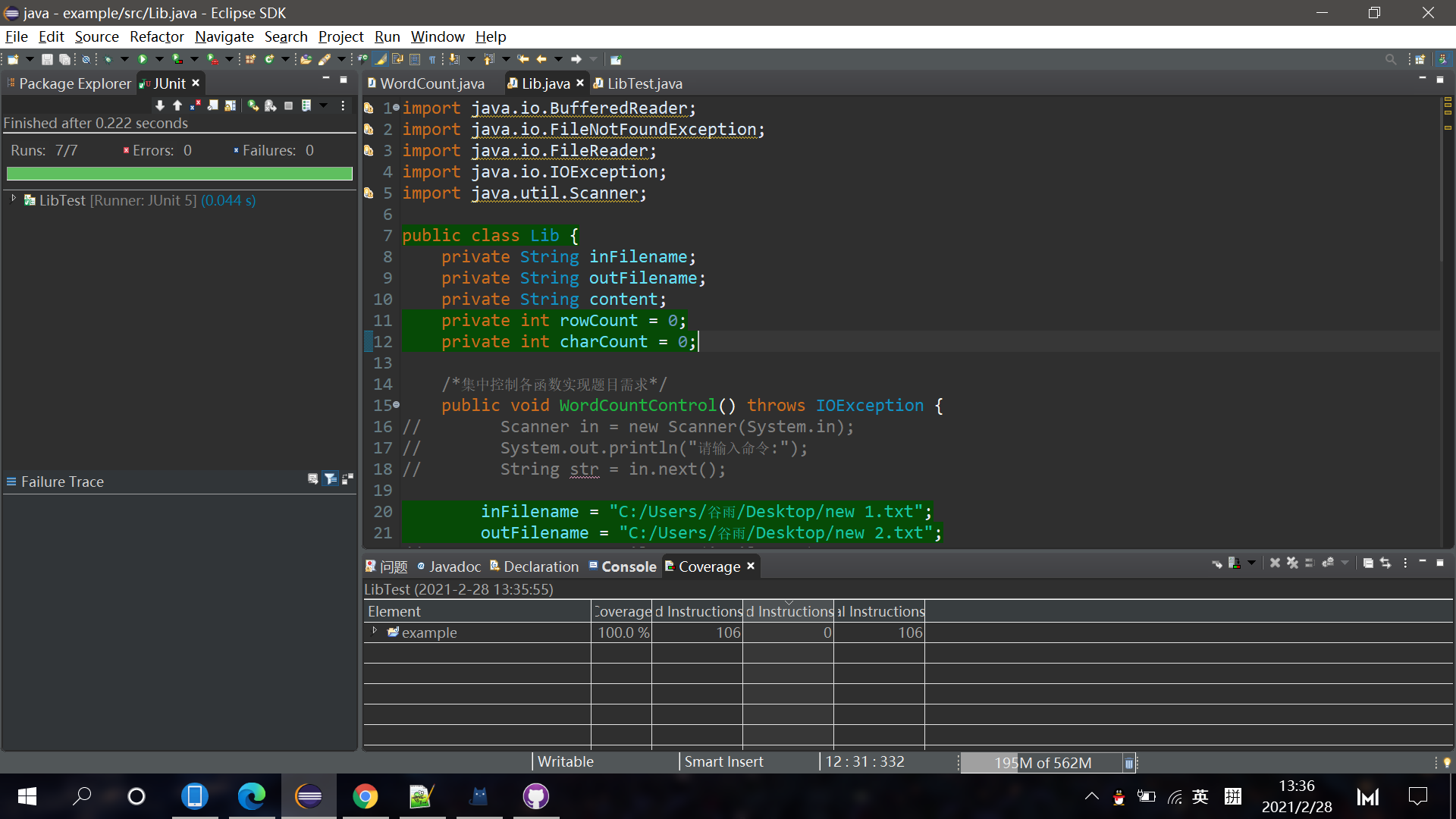
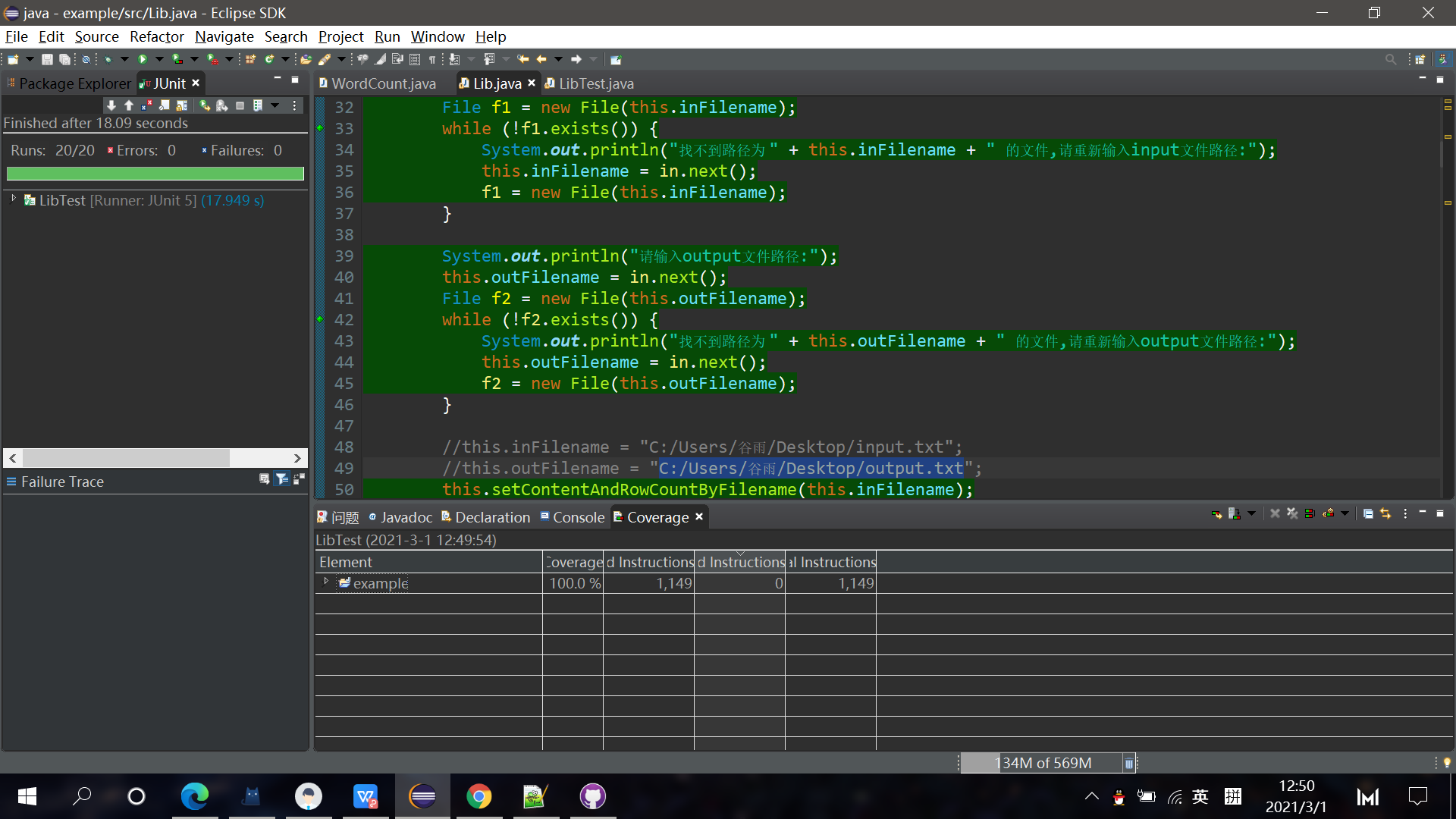
各个版本单元测试覆盖率截图如下:(虽然少了几张,但图片还是太多基本都是100%图片又很大张所以我这里只节选2张):
下面的覆盖率图对应的单元测试函数在我branchone分支里面
对应github上的branchone分支的Lib类初建的commit:
对应github上的branchone分支的version2.2的commit:
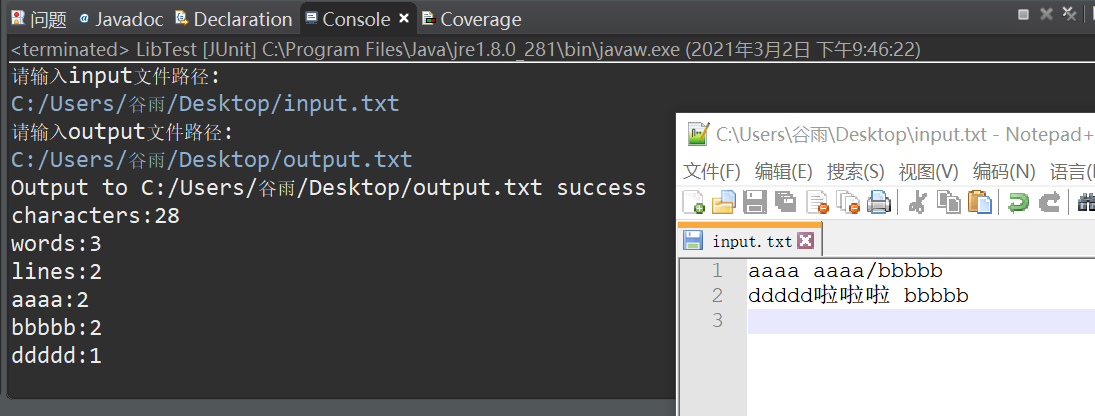
单元测试例1
input文本情况如下:
输出得到output文本情况如下:
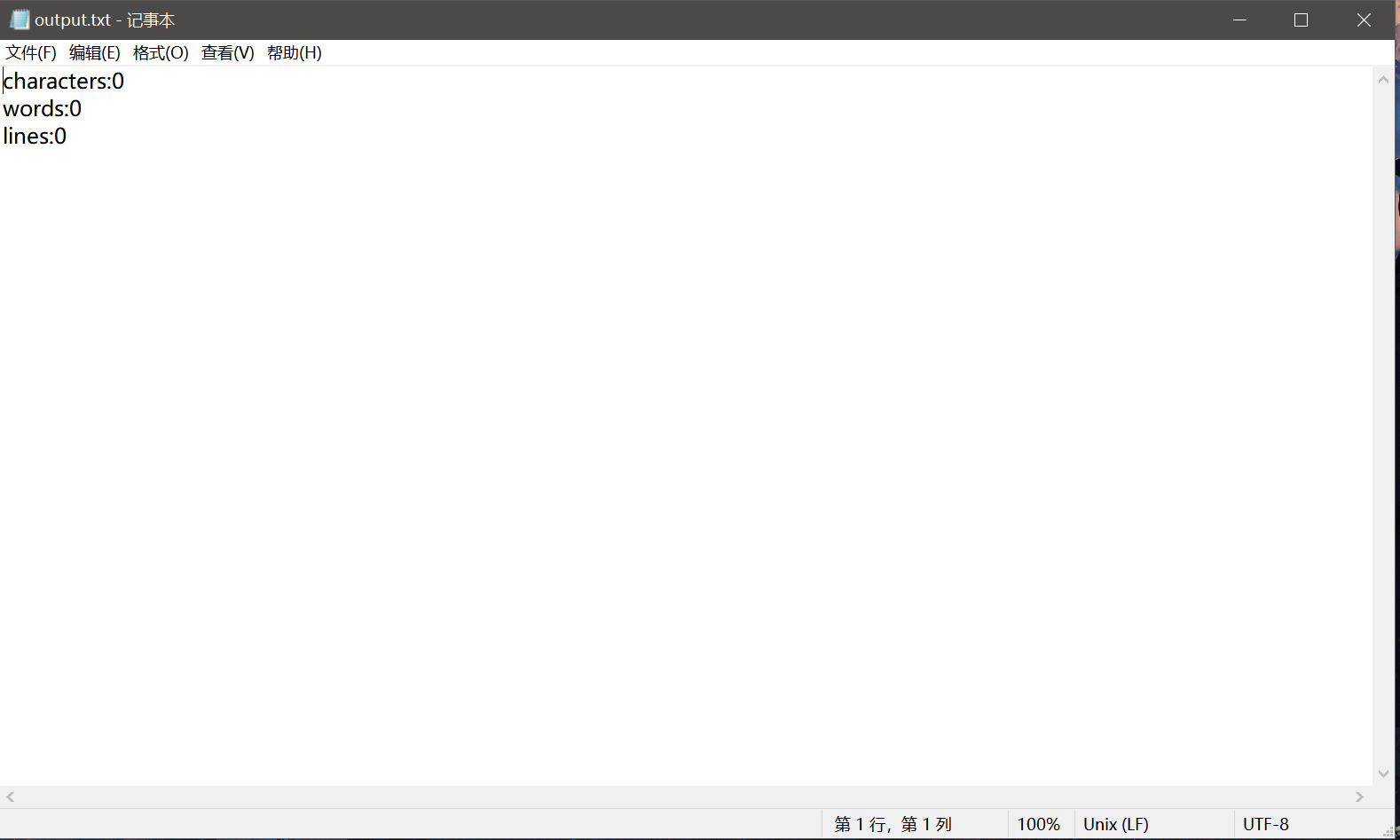
Console情况如下:
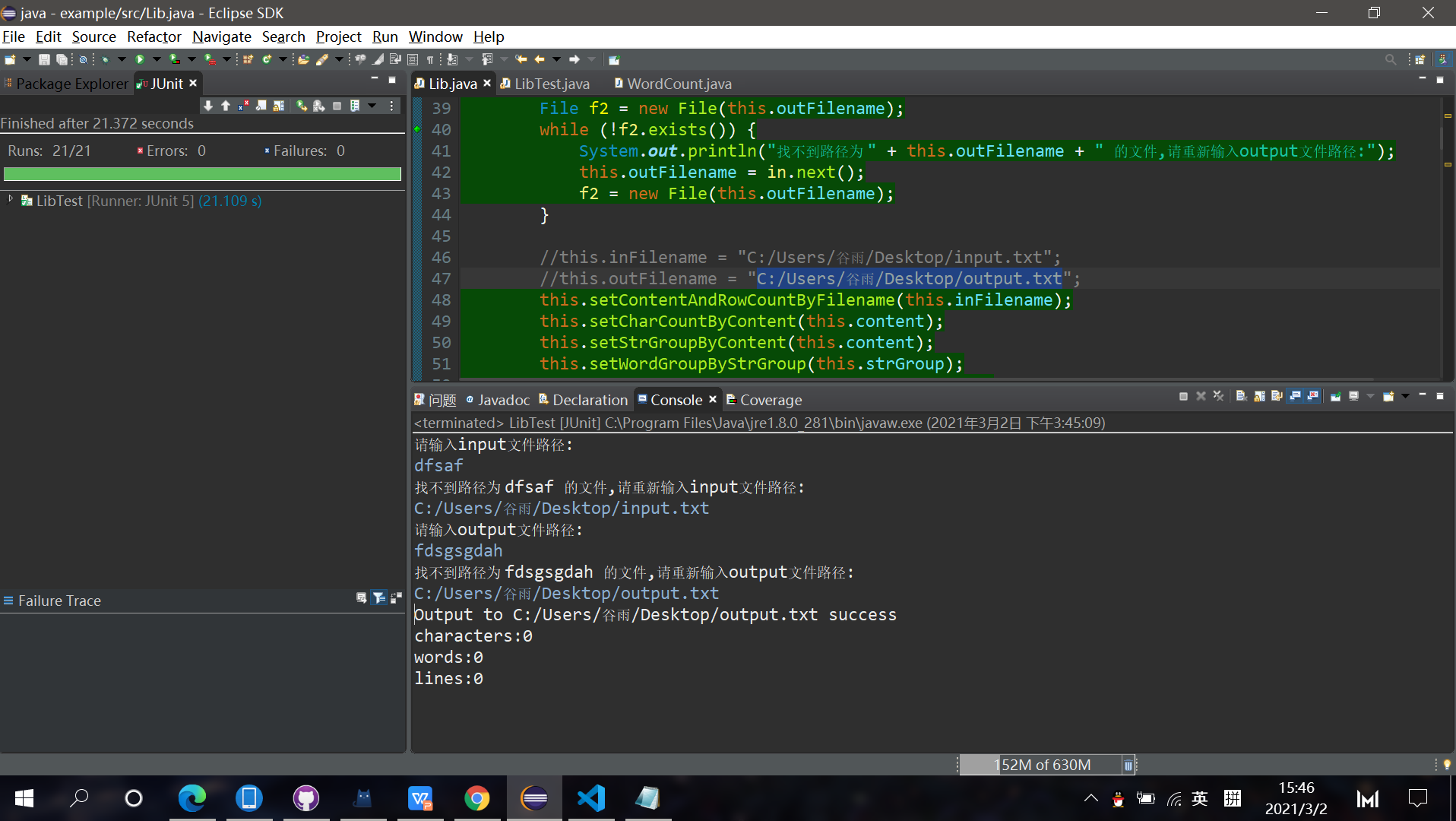
覆盖率如下(在故意输错文件路径引发文件判断的前提下,除了空文件情况下其他覆盖率都是100%,其实这边在测试函数里面随便写死传个非空文件就100%了):
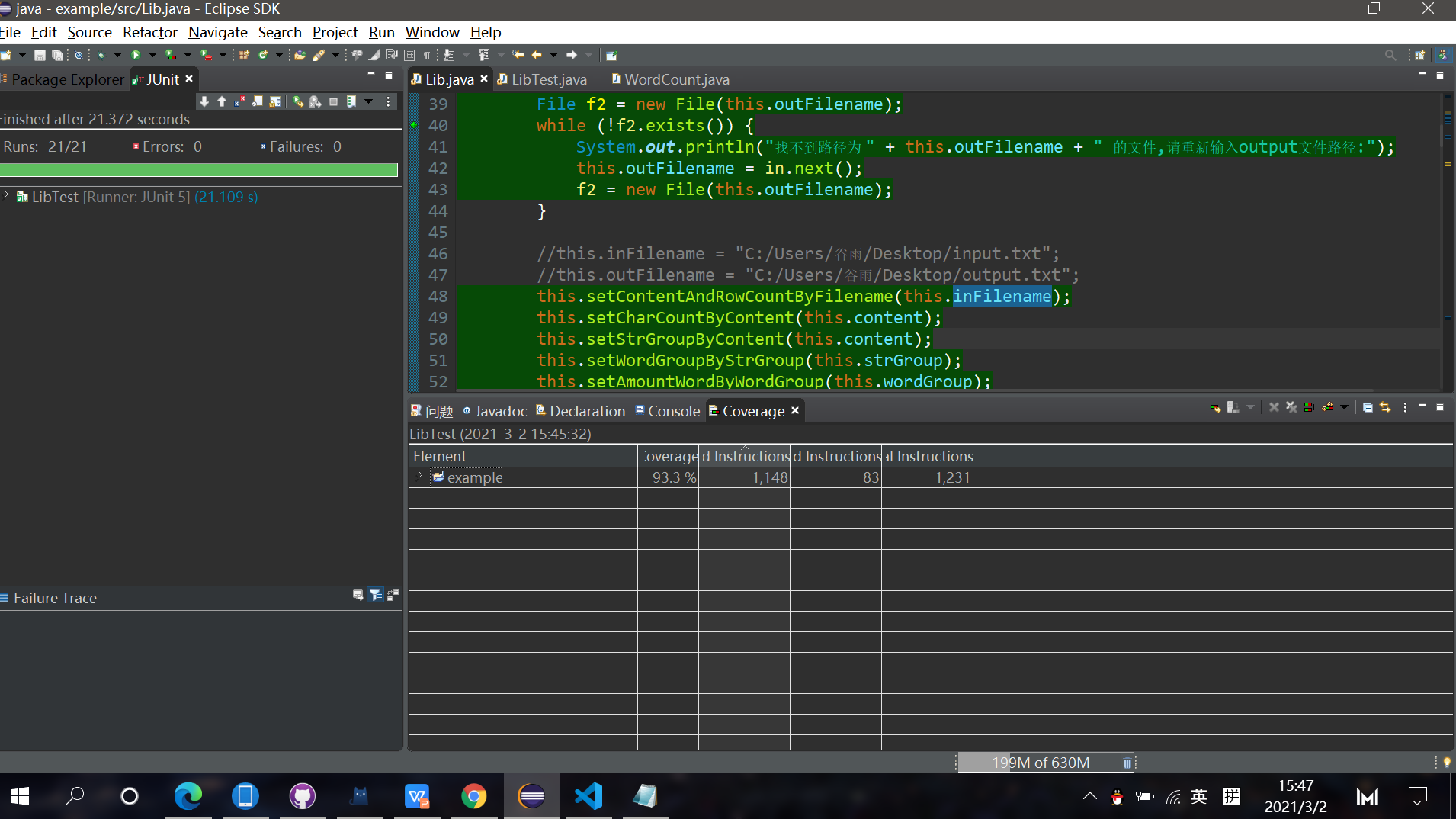
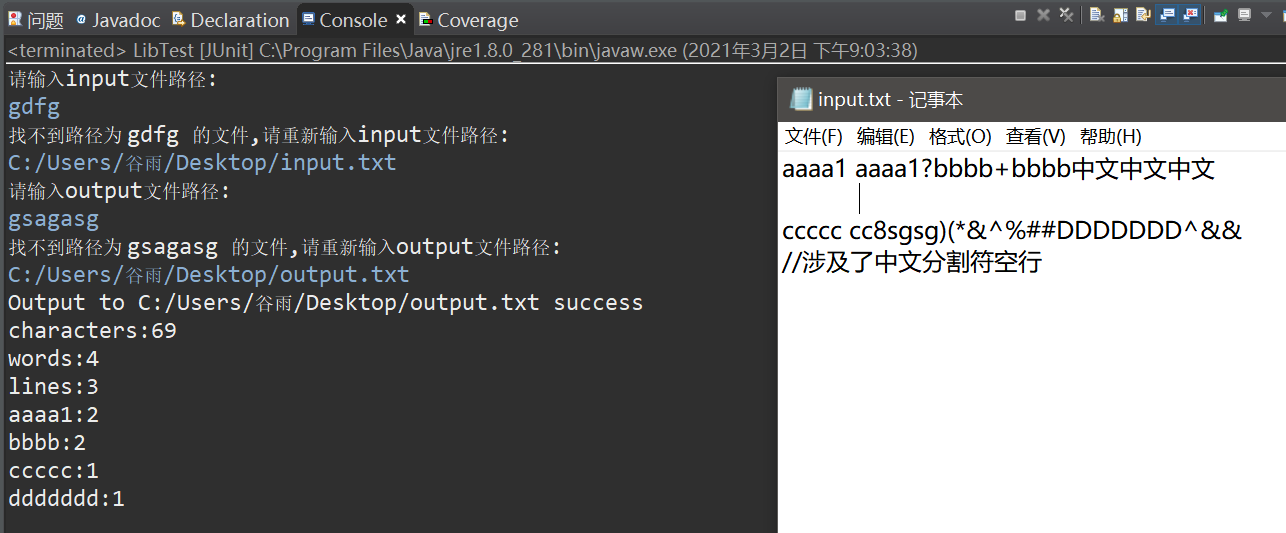
单元测试例2
input文本情况如下:
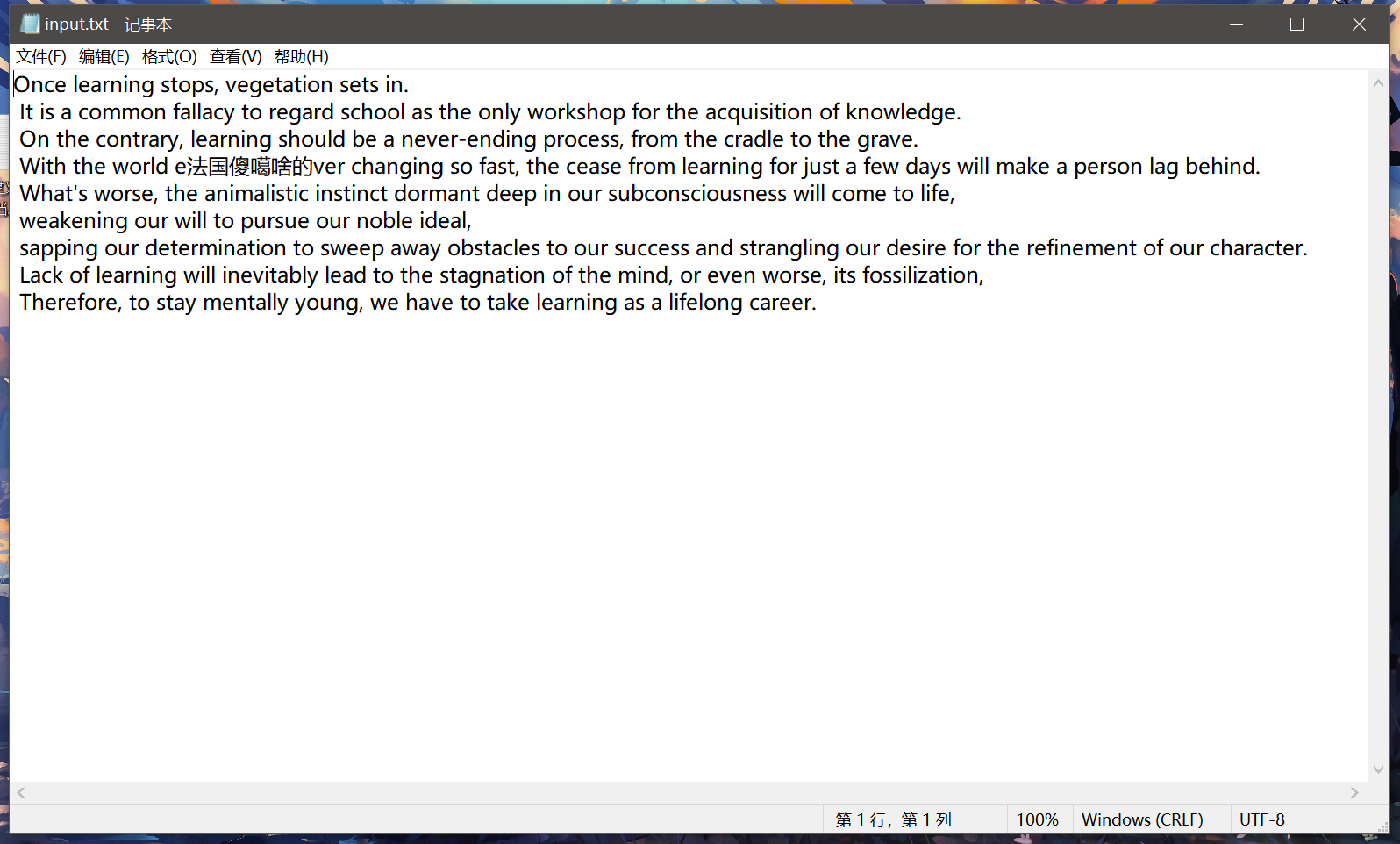
输出得到output文本情况如下(我数过了,确实是9行,5个learning,4个will):
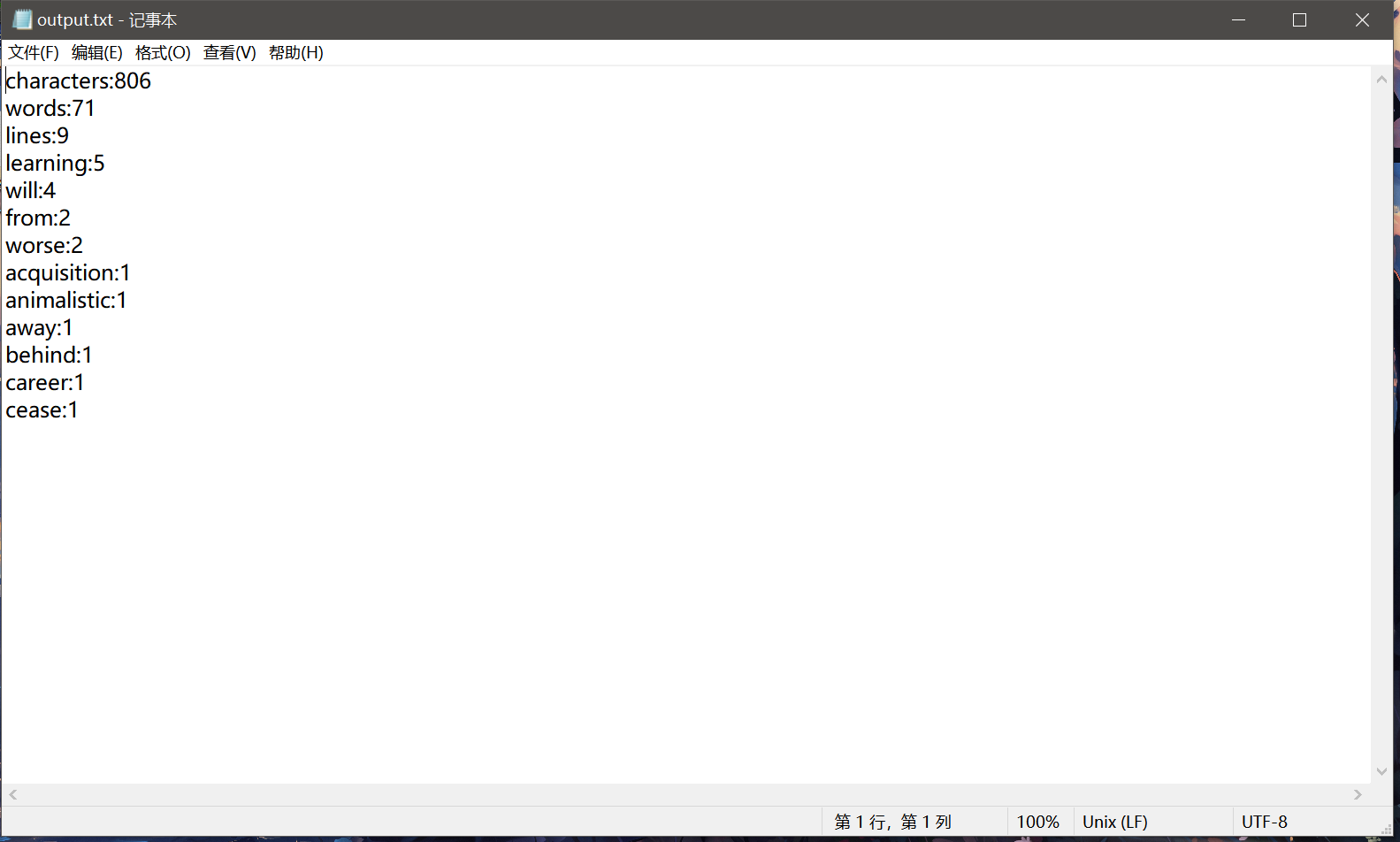
Console情况如下:
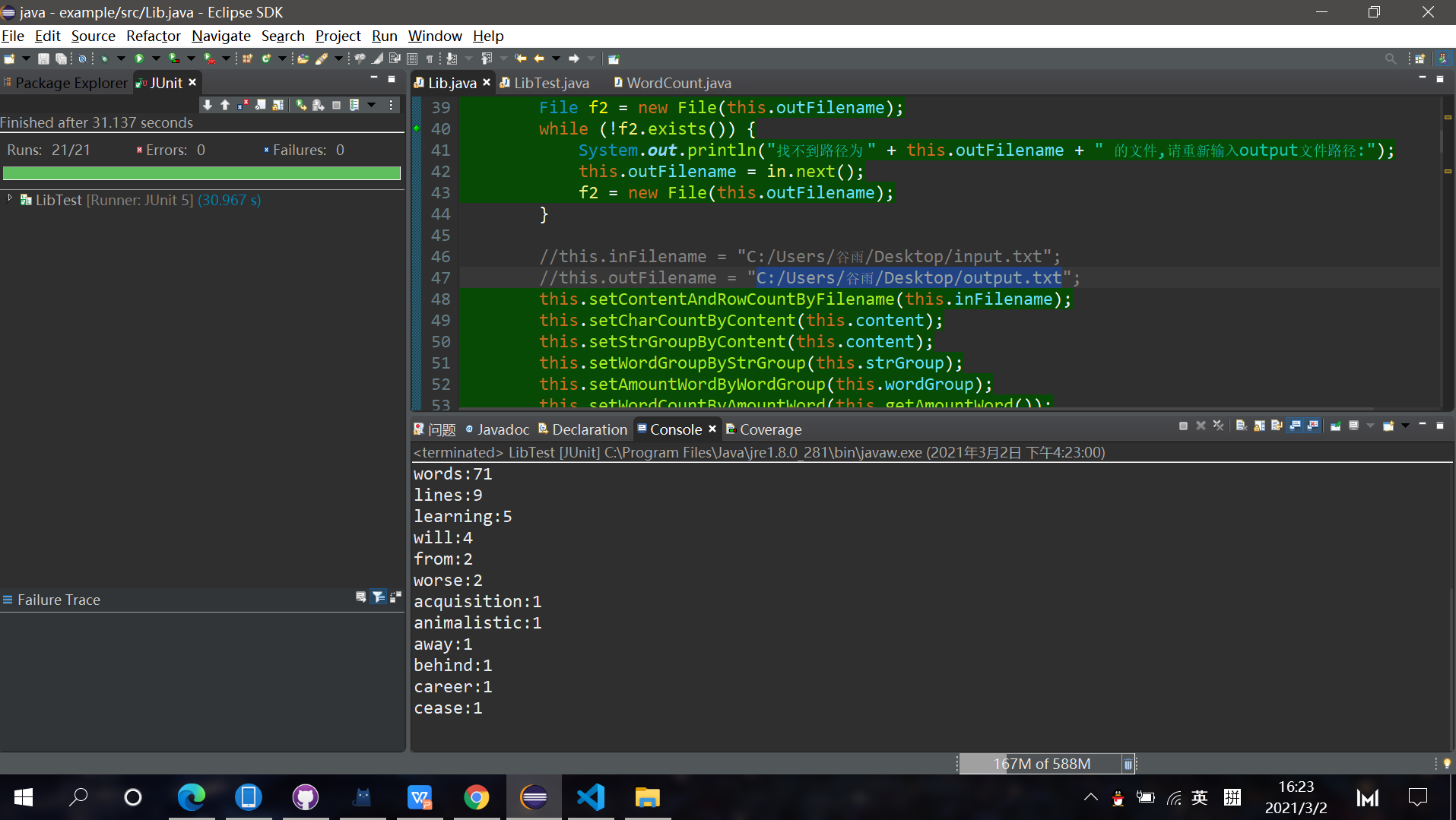
覆盖率如下:
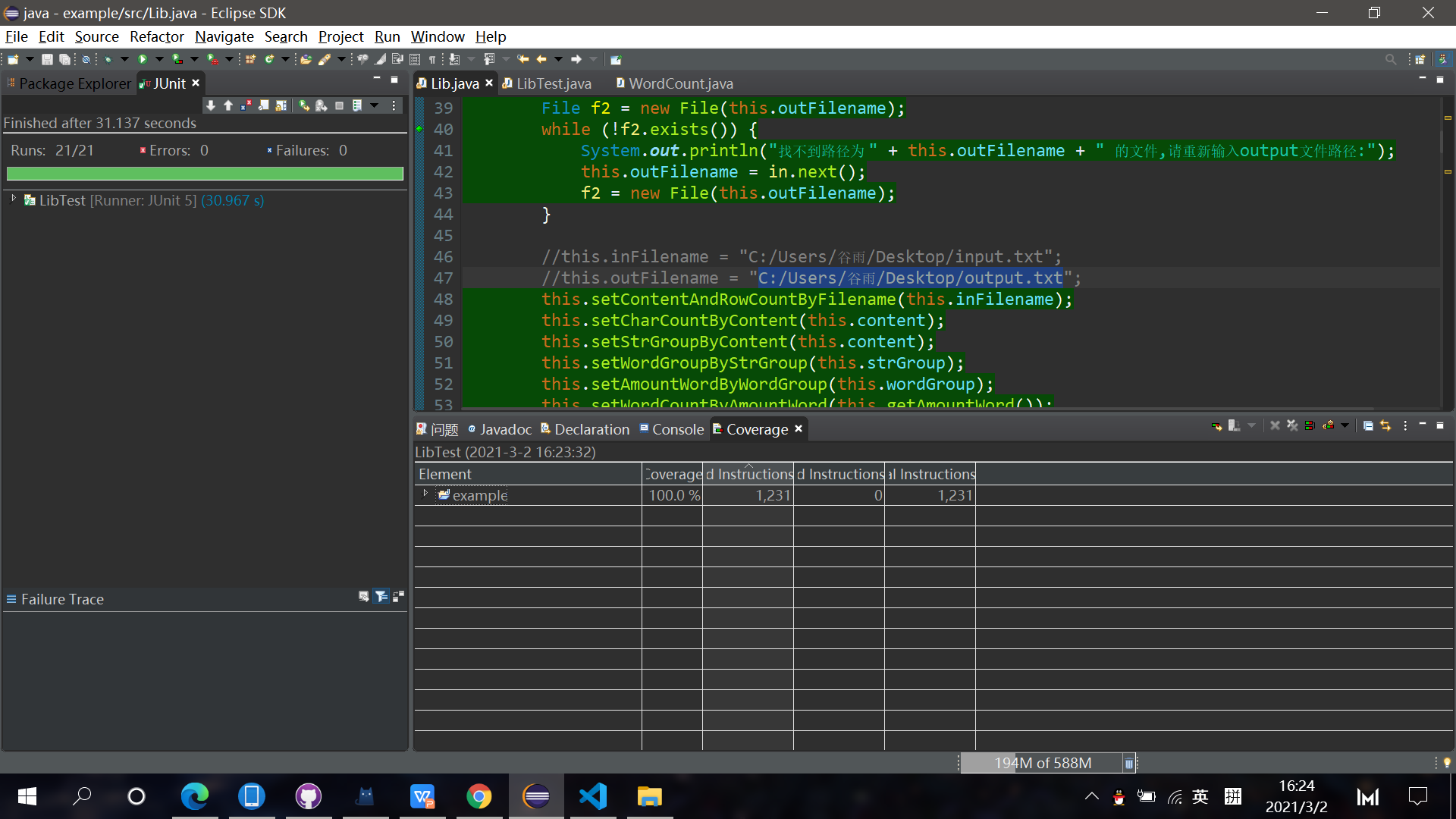
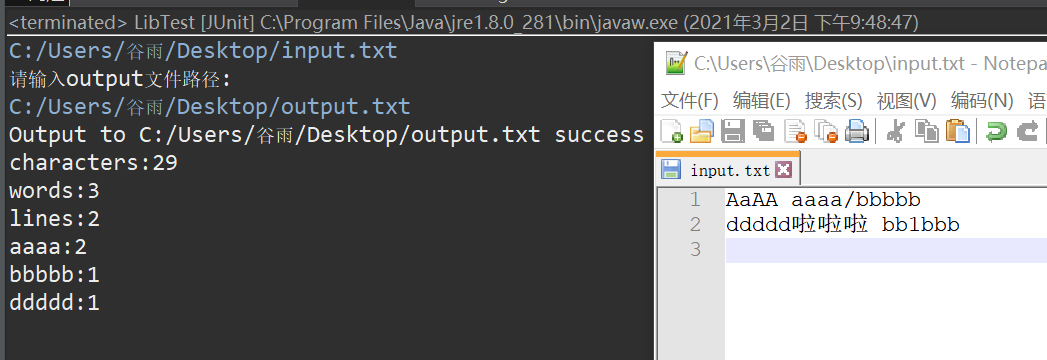
部分单元测试示例3,4,5
异常处理说明
有一个异常我没成功解决:中文后面紧跟的第一个字符会被吞掉,仿佛没有出现过,比如"good"如果在前面紧跟中文会变成"ood",但如果中文和单词之间有空格或其他字符就不会导致这个单词少个字母。
1.如果传入args的命令里面的文件路径找不到还可以在Console里面继续修改路径。(当然也可以选择停止运行,再重新运行一次args里面的路径可以找到的)(当然如果args什么也没传或指令缺漏,会数组越界异常)
this.inFilename = argsInput;
this.outFilename = argsOutput;
Scanner in = new Scanner(System.in);
File f1 = new File(this.inFilename);
while (!f1.exists()) {
System.out.println("找不到路径为 " + this.inFilename + " 的文件,请重新输入input文件路径:");
this.inFilename = in.next();
f1 = new File(this.inFilename);
}
File f2 = new File(this.outFilename);
while (!f2.exists()) {
System.out.println("找不到路径为 " + this.outFilename + " 的文件,请重新输入output文件路径:");
this.outFilename = in.next();
f2 = new File(this.outFilename);
}
2.当文件中有中文或其他非ASCII码时处理的代码如下:
/*通过文件路径获取1.文件文本内容content;2.文本行数rowCount;*/
public void setContentAndRowCountByFilename(String filename) throws IOException {
FileReader fr = new FileReader(filename);
BufferedReader br = new BufferedReader(fr);
String s;
/*读出每一行先去除中文再存入content中并决定是否需要rowCount++,这边题意看不太明白,我理解为中文不计入字符数即中文不算统计行数
时的非空白字符,即纯中文不算行。 */
while((s = br.readLine()) != null) {
//从s中去除非ascii字符
s = s.replaceAll("[^\\x0A\\x0D\\x20-\\x7E]", "");
content += s;
content += "\n";
if (!s.replaceAll(" ", "").isEmpty()) {
rowCount ++;
}
}
}
对应单元测试代码是:
@Test
void testSetContentAndRowCountByFilename() throws IOException {
lib.setContentAndRowCountByFilename(inputTestFile);
assertEquals(lib.getRowCount(), 2);
assertEquals(lib.getContent(), "ssss111 bbb222\n \naaaa333,ccccc\n\n");
}
心路历程与收获
单元测试使用果然如网上所说的,特别费时费力,每写完一个函数,我就添加一个对应单元测试,然后经常因为各种问题覆盖率没有100%,解决过程异常艰辛,数组越界、空指针异常,每次都是因为String指向null的空指针异常,所以以后String对象时可以赋空值""再用比较安全。
然后就是git和github的使用了,特别坑的一点就是gitignore与分支创建了,我代码写的好好的,写了都快最后版本了,然后我gitignore一下传到github,然后不小心开了其他完成度几乎为零的分支,然后我的本地文件就被覆盖了,这还不是问题,毕竟可以恢复嘛。但是,我恢复时发现,我gitignore过的文件恢复不了,只恢复了没gitignore的文件,然后我代码就用不了了,而且丢失了最新一两个版本的单元测试类,因为这个也被我gitignore了。使用这里我有个疑问,gitignore的文件可以恢复吗?我用了git reset还有github上找代码都没能恢复被gitignore后再commit的那些文件。
对了,还有一个特别坑的现象,我后来没用gitignore了,但我失误用eclipse打开的不是example而是example的上一级文件,于是第二天我的代码又自己出问题了,和github上面的最后一次commit不一样,明明我没修改过,而且代码直接不能运行了,发现是少了两个包,如下图:
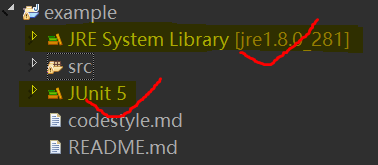
猜测是打开example上级文件上传时Junit包和Java自带包会被自动忽略,所以我如果中途打开了其他分支修改了本地代码,然后切回打开example上级文件的分支时从github拉取最新代码时拉取到的代码是没有Junit包和Java自带包。


