

2023数据采集与融合技术实践作业一
作业1
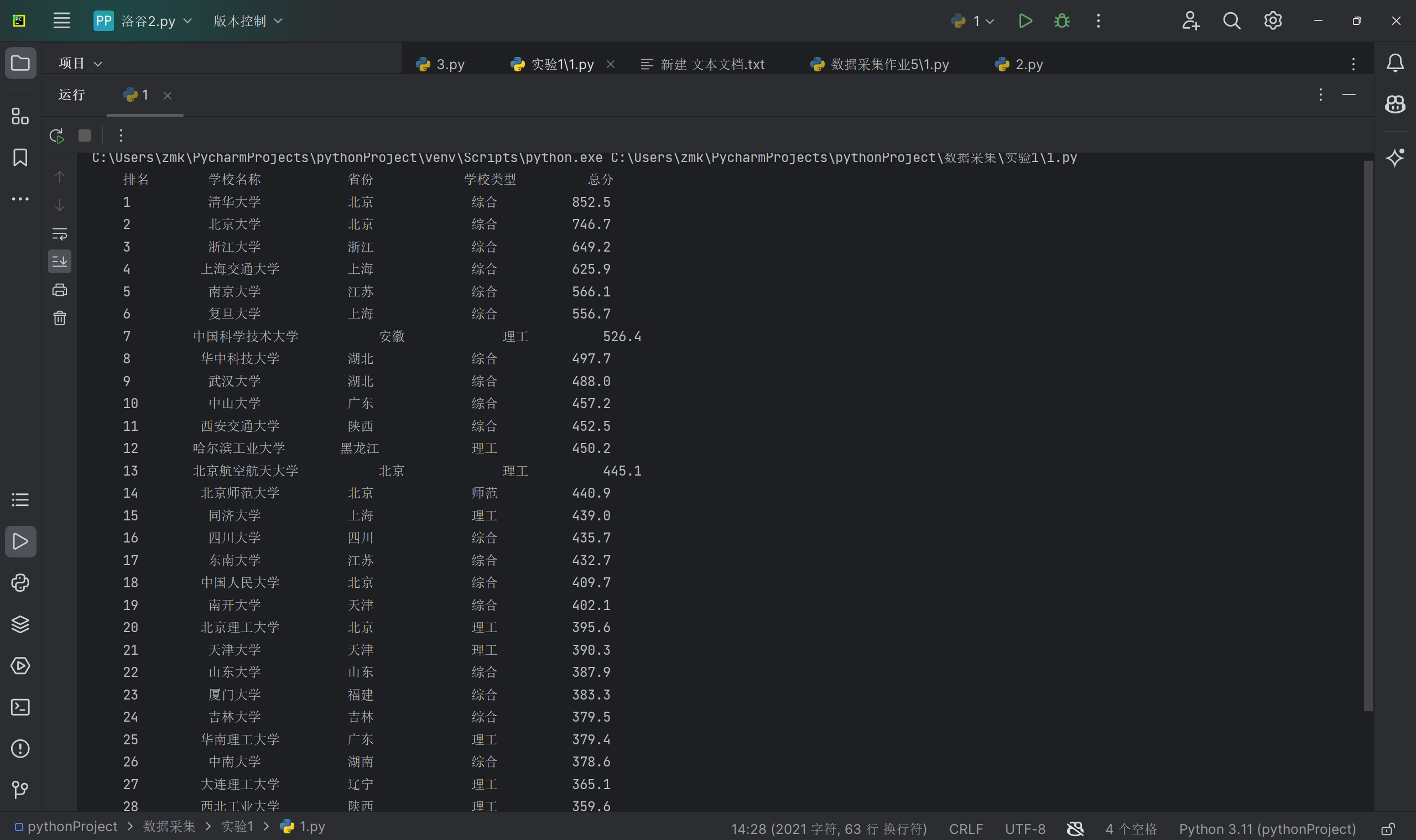
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2 | ... | ... | ... | ... |
代码
import requests # 方式1获取URL信息
import urllib.request # 方式2获取URL信息
from bs4 import BeautifulSoup
import bs4
# 从网络上获取大学排名网页内容。
def getHTMLText(url): # 获取URL信息,输出内容
# =========================方式1获取=========================
try:
res = requests.get(url) # 使用requests库爬取
res.raise_for_status() # 产生异常信息
res.encoding = res.apparent_encoding # 修改编码
return res.text # 返回网页编码
except Exception as err:
print(err)
# =========================方式2获取=========================
try:
req = urllib.request.Request(url)
# 打开URL网站的网址,读出二进制数据,二进制数据转为字符串
data = urllib.request.urlopen(req).read.decode()
return data
except Exception as err:
print(err)
# 提取网页内容中信息到合适的数据结构.
def fillUnivList(ulist, html): # 将html页面放到ulist列表中(核心)
# 解析网页文件(使用html解释器)
soup = BeautifulSoup(html, "html.parser")
# soup.prettify() # 把soup对象的文档树变换成一个字符串
# 数据结构:所用数据都封装在一个表格(标签tbody)中,单个学校信息在tr标签中,详细信息在td标签中
# 学校名称在a标签中,定义一个列表单独存放a标签内容
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag): # 如果tr标签的类型不是bs4库中定义的tag类型,则过滤掉
a = tr('a') # 把所用的a标签存为一个列表类型
tds = tr('td') # 将所有的td标签存为一个列表类型
ulist.append([tds[0].text.strip(), a[0].string.strip(), tds[2].text.strip(),
tds[3].text.strip(), tds[4].text.strip()])
# 使用strip()函数,它的作用是用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
# 利用数据结构展示并输出结果:定义函数
def printUnivList(ulist1, num): # 打印出ulist列表的信息,num表示希望将列表中的多少个元素打印出来
# 格式化输出
tplt = "{0:^10}\t{1:^10}\t{2:^12}\t{3:^12}\t{4:^10}"
print(tplt.format("排名", "学校名称", "省份", "学校类型", "总分"))
for i in range(num):
u = ulist1[i]
print(tplt.format(u[0], u[1], u[2], u[3], u[4]))
def main():
uinfo = [] # 将大学信息放到列表中
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 30) # 一个界面的数据
if __name__ == '__main__':
main()
运行截图
心得体会
第一次爬虫比较简单,网页容易找到标签,而且没有反爬机制。
作业2
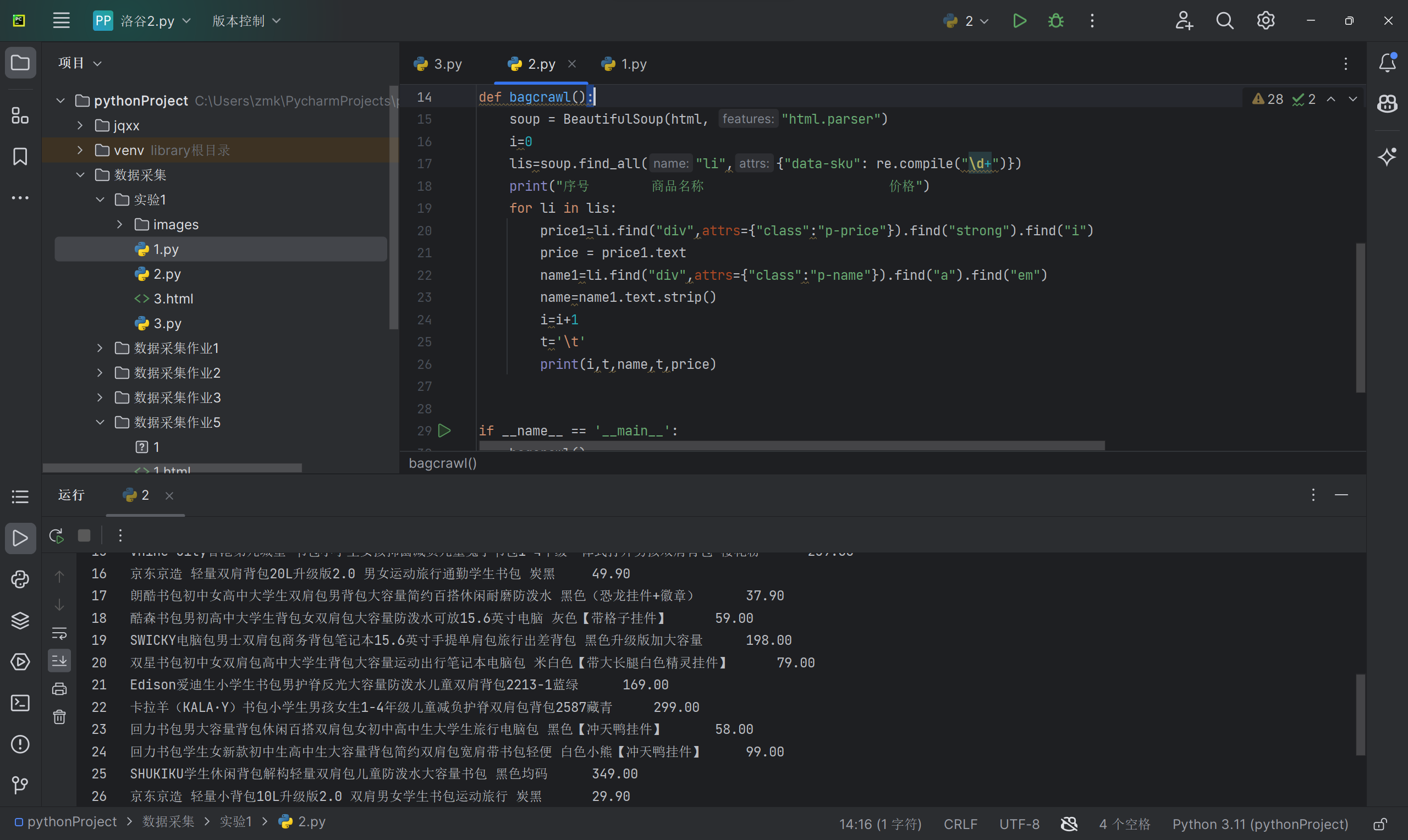
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2 | ... | ... |
代码
import urllib.request
from bs4 import BeautifulSoup
import re
import urllib.parse
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81"}
url="https://search.jd.com/Search?keyword=%E4%B9%A6%E5%8C%85&enc=utf-8&wq=shu&pvid=ea9bef8ed6114b1a9106f35315b8bf24"
req=urllib.request.Request(url,headers=headers) # Request可以加url
html=urllib.request.urlopen(req)
html=html.read()
html=html.decode()
def bagcrawl():
soup = BeautifulSoup(html, "html.parser")
i=0
lis=soup.find_all("li",{"data-sku": re.compile("\d+")})
print("序号 商品名称 价格")
for li in lis:
price1=li.find("div",attrs={"class":"p-price"}).find("strong").find("i")
price = price1.text
name1=li.find("div",attrs={"class":"p-name"}).find("a").find("em")
name=name1.text.strip()
i=i+1
t='\t'
print(i,t,name,t,price)
if __name__ == '__main__':
bagcrawl()
运行截图
心得体会
淘宝有点难爬,京东的好爬一点
作业3
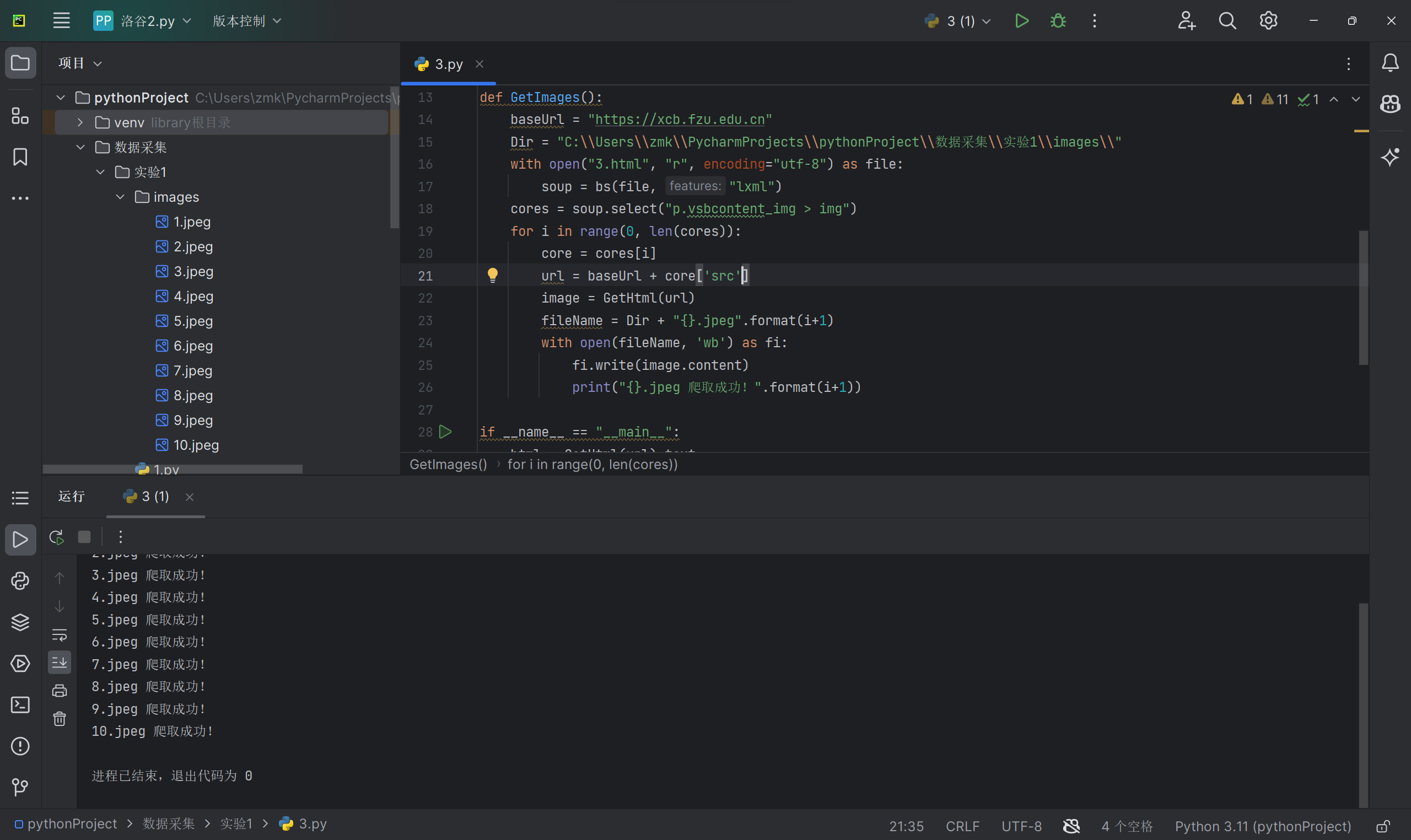
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
代码
import requests
from bs4 import BeautifulSoup as bs
import re
url = "https://xcb.fzu.edu.cn/info/1071/4504.htm"
def GetHtml(url):
session = requests.session()
response = session.get(url)
return response
def GetImages():
baseUrl = "https://xcb.fzu.edu.cn"
Dir = "C:\\Users\\zmk\\PycharmProjects\\pythonProject\\数据采集\\实验1\\images\\"
with open("3.html", "r", encoding="utf-8") as file:
soup = bs(file, "lxml")
cores = soup.select("p.vsbcontent_img > img")
for i in range(0, len(cores)):
core = cores[i]
url = baseUrl + core['src']
image = GetHtml(url)
fileName = Dir + "{}.jpeg".format(i+1)
with open(fileName, 'wb') as fi:
fi.write(image.content)
print("{}.jpeg 爬取成功!".format(i+1))
if __name__ == "__main__":
html = GetHtml(url).text
GetImages()
运行截图
心得体会
这里取巧了,该网页的图片都是以
<img 的形式保存的


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)