软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2020春S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 1.疫情统计程序 2.github初使用 3.代码规范制定 |
| 作业正文 | 软工实践寒假作业(2/2) |
| 其他参考文献 | CSDN、百度、博客园、缪雪峰的git教程 |
1.Gitub仓库地址
2.PSP表格
邹欣老师在《构建之法》中把枯燥的理论概念讲解得非常生动,寓教于乐,深入浅出,举出的例子也是形象而易懂,读完之后很受启发。
第一章中,作者为我们介绍了一些关于软件工程的基本知识。软件=程序+软件工程。
软件开发的不同阶段:玩具阶段→业余爱好阶段→探索阶段→成熟的产业阶段.
软件的特殊性:复杂性、不可见性、易变性、服从性、非连续性。
第二章主要学习了单元检测和个人开发流程PSP。PSP是卡耐基梅隆大学(CMU)的专家们针对软件工程师所提出的一套模型:Personal Software Process (PSP, 个人开发流程,或称个体软件过程)。
PSP特点:
(1)不局限于某一种软件技术,而是着眼于软件开发的流程,这样,开发不同应用的软件工程师可以互相比较。
(2)不依赖于考试,而主要靠工程师自己收集数据,然后分析、提高。
(3)在小型、初创的团队中,很难找到高质量的项目需求,这意味着给程序员的输入质量不高。在这种情况下,程序员的输出(程序/软件)往往质量也不高,然而这并不能全部由程序员负责。
(4)PSP依赖于数据(工程师输入数据的时间代价、数据可能遗失或者不准确的风险、可能会出现一些数据不利于工程师本人的情况)
(5)PSP目的是记录工程师如何实现需求的效率,而不是记录顾客对产品的满意度,工程师有可能很高效地开发出一个顾客不喜欢的软件。
第三章主要介绍了软件工程师个人能力的衡量与发展以及职业发展。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| Estimate | 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 400 | 500 |
| Analysis | 需求分析 (包括学习新技术) | 240 | 270 |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 | 60 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 120 | 60 |
| Design | 具体设计 | 90 | 100 |
| Coding | 具体编码 | 720 | 600 |
| Code Review | 代码复审 | 60 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 300 | 360 |
| Reporting | 报告 | 120 | 240 |
| Test Repor | 测试报告 | 30 | 40 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 2370 | 2460 |
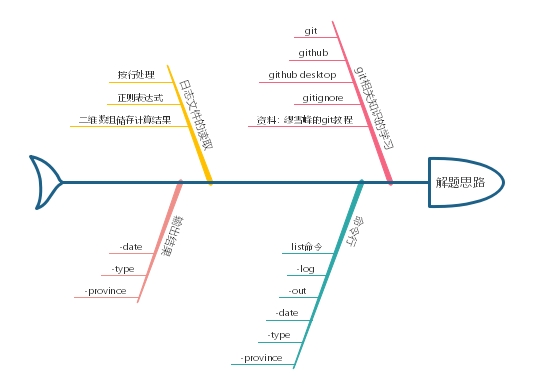
3.解题思路描述
- git、github、github desktop的学习
对git了解很少,首先学习这个部分的新知识。老师给的知识链接对于零基础的我看的有点模糊,所以花了一部分时间查找资料。在缪雪峰的git教程里学习有关git部分的所有知识,包括git命令行的使用、gitignore等等。 - 命令行参数处理
百度学习main函数参数的相关知识。
Java中参数是以字符串数组形式传入,根据题目要求
list命令 支持以下命令行参数:
-log 指定日志目录的位置,该项必会附带,请直接使用传入的路径,而不是自己设置路径
-out 指定输出文件路径和文件名,该项必会附带,请直接使用传入的路径,而不是自己设置路径
-date 指定日期,不设置则默认为所提供日志最新的一天。你需要确保你处理了指定日期之前的所有log文件
-type 可选择[ip: infection patients 感染患者,sp: suspected patients 疑似患者,cure:治愈 ,dead:死亡患者],使用缩写选择,如 -type ip 表示只列出感染患者的情况,-type sp cure则会按顺序【sp, cure】列出疑似患者和治愈患者的情况,不指定该项默认会列出所有情况。
-province 指定列出的省,如-province 福建,则只列出福建,-province 全国 浙江则只会列出全国、浙江
使用一个字符串数组保存读取到的命令以便后续处理。第一个参数必是list,是用来判断命令的。以-开头的参数开始处理,根据上面的要求可得知一个参数的值可以为多个。这里用if-else语句匹配相应的参数,进行相应的处理。
3. 日志文件的读取
根据题目要求,日志文件以日期名命名,日志的形式有以下8种
<省> 新增 感染患者 n人
<省> 新增 疑似患者 n人
<省1> 感染患者 流入 <省2> n人
<省1> 疑似患者 流入 <省2> n人
<省> 死亡 n人
<省> 治愈 n人
<省> 疑似患者 确诊感染 n人
<省> 排除 疑似患者 n人
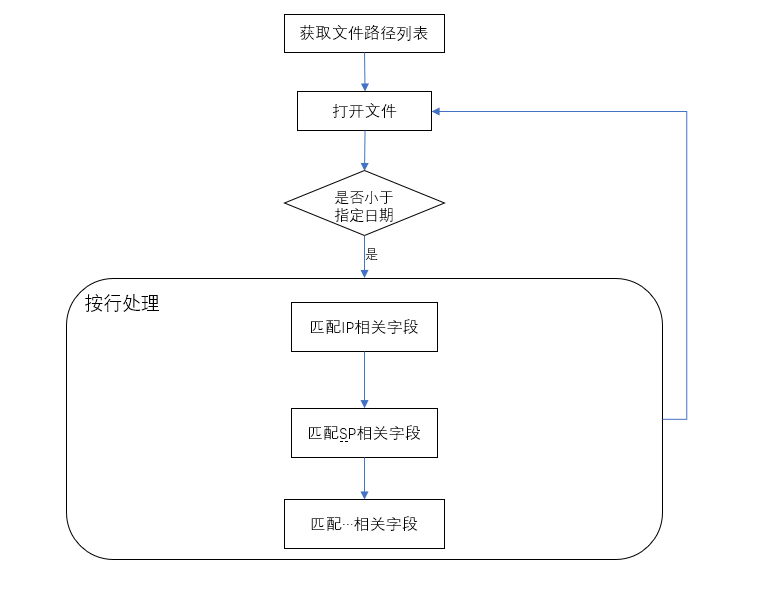
首先是根据-log获取文件路径,结合-date打开相应的文件。然后按行读取日志文件的内容,使用正则表达式匹配,匹配成功则进行相应的计算操作,将结果保存在一个二维数组里。
4. 输出结果
不同参数输出结果不同
-date没有参数,输出最新一天的情况
-type有多个参数,按序输出;没有参数,输出所有类型
-province的参数全国总是排第一个,别的省按拼音先后排序;没有参数,输出全国+文件中包含的省份的情况,
4.设计实现过程
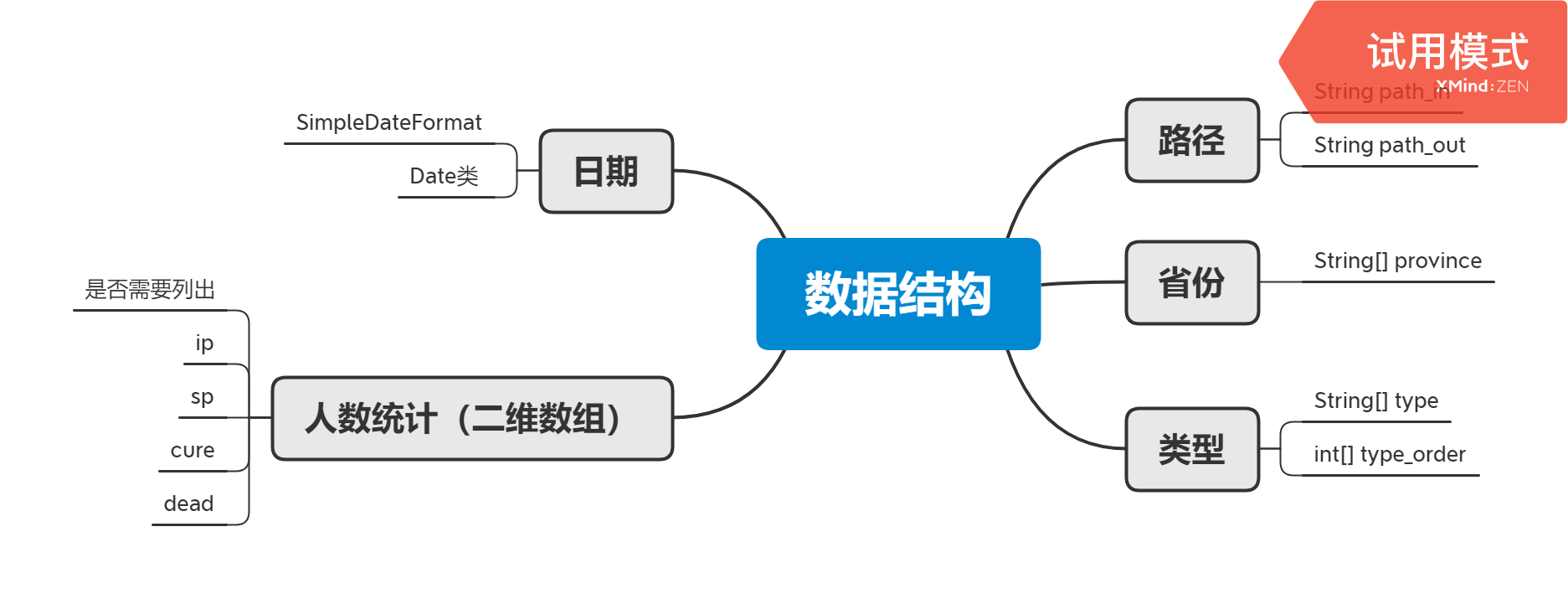
- 数据结构
- 文件读取
readFile方法:
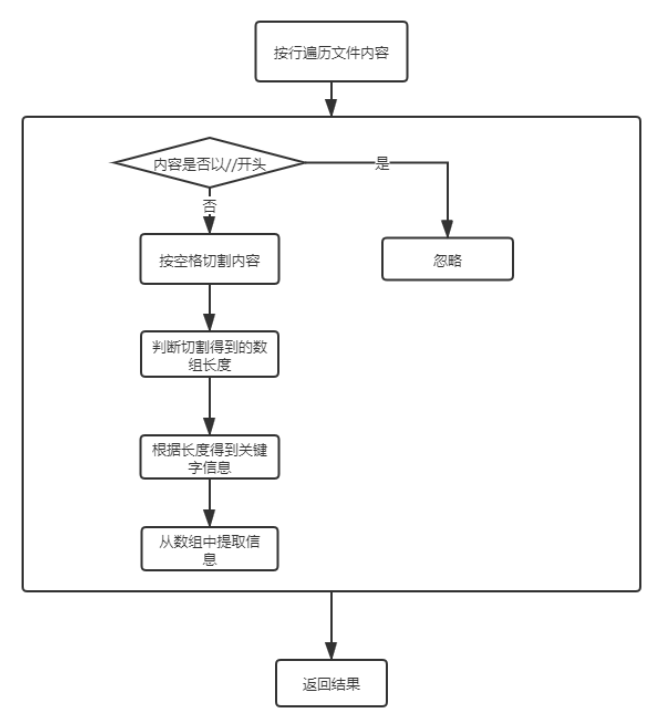
- 命令行处理
ProcCmd方法:
- 输出结果
writeFile方法:
5. 关键代码与思路
-
数据结构
public String path_in;//读取日志目录 public String path_out;//输出日志目录 //获取格式化日期 Date dt = new Date(System.currentTimeMillis()); String strDateFormat = "yyyy-MM-dd"; SimpleDateFormat sdf = new SimpleDateFormat(strDateFormat); String date=sdf.format(dt); public String[] province = { "全国", "安徽", "澳门" ,"北京", "重庆", "福建","甘肃","广东", "广西", "贵州", "海南", "河北", "河南", "黑龙江", "湖北", "湖南", "吉林", "江苏", "江西", "辽宁", "内蒙古", "宁夏", "青海", "山东", "山西", "陕西", "上海","四川", "台湾", "天津", "西藏", "香港", "新疆", "云南", "浙江"}; /*二维数组 * 一维表示省份 * 二维分别表示{是否需要列出,ip,sp,cure,dead}*/ public int[][] situation=new int[35][6]; //类型输出顺序,默认ip,sp,cure,dead public int type_order[]= {1,2,3,4}; public String[] type= {"感染患者", "疑似患者", "治愈", "死亡"}; -
处理命令行参数
//处理参数 public boolean ProcessPara(){ //判断命令是否正确 if(!args[0].equals("list")){ System.out.println("命令错误"); return false; } int i; for(i = 1;i<args.length;i++){ //读取-log if(args[i].equals("-log")){ path_in=args[++i]; } //读取-out else if(args[i].equals("-out")){ path_out=args[++i]; } //读取-date else if(args[i].equals("-date")){ i=getDate(++i); if(i==-1) { System.out.println("日期超出范围!"); return false; } } //设置-type输出顺序 else if(args[i].equals("-type")){ i=setType(++i); } //读取-province else if(args[i].equals("-province")){ i=getProvince(++i); } } return true; } -
日志文件的读取
//读取日志 public void readLog() { File file=new File(path_in); File[] listFiles=file.listFiles(); String path; int i=0; while(i<listFiles.length){ path=listFiles[i].getName(); if(path.compareTo(date)<=0) { try { BufferedReader b=new BufferedReader(new InputStreamReader( new FileInputStream(new File(path_in+path)), "UTF-8")); String line; while((line=b.readLine())!=null) { if(!line.startsWith("//")) { String p1 = "(\\S+) 新增 感染患者 (\\d+)人"; String p2 = "(\\S+) 新增 疑似患者 (\\d+)人"; String p3 = "(\\S+) 治愈 (\\d+)人"; String p4 = "(\\S+) 死亡 (\\d+)人"; String p5 = "(\\S+) 感染患者 流入 (\\S+) (\\d+)人"; String p6 = "(\\S+) 疑似患者 流入 (\\S+) (\\d+)人"; String p7 = "(\\S+) 疑似患者 确诊感染 (\\d+)人"; String p8 = "(\\S+) 排除 疑似患者 (\\d+)人"; if(Pattern.matches(p1, line)) IP(line); if(Pattern.matches(p2, line)) SP(line); if(Pattern.matches(p3, line)) Cure(line); if(Pattern.matches(p4, line)) Dead(line); if(Pattern.matches(p5, line)) IPgo(line); if(Pattern.matches(p6, line)) SPgo(line); if(Pattern.matches(p7, line)) SPtoIP(line); if(Pattern.matches(p8, line)) notSP(line); } } b.close(); } catch (UnsupportedEncodingException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } catch (FileNotFoundException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } catch (IOException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } } i++; } } -
输出日志
//输出日志 public void writeLog(){ try { FileWriter fw=null; fw=new FileWriter(path_out); if(situation[0][0]==-1) situation[0][0]=1; int i=0; while(i<35) { if(situation[i][0]==1) { //System.out.println("a"); fw.write(province[i]+" "); for(int k=1;k<5;k++) for(int j=0;j<4;j++) { if(type_order[j]==k) { String string=type[j]+situation[i][j+1]+"人"+" "; fw.write(string); break; //System.out.println(string); } } fw.write("\n"); } i++; } fw.write("// 该文档并非真实数据,仅供测试使用"); fw.close(); }catch (Exception e) { // TODO: handle exception e.printStackTrace(); } }
6.单元测试截图和描述
学习资料:
关于单元测试和回归测试
Eclipse中进行单元测试
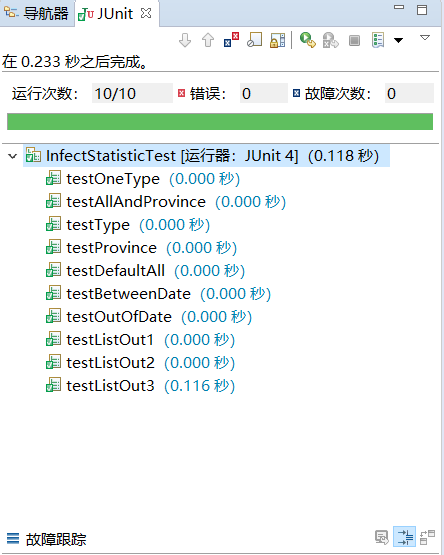
测试结果:
-
测试ListOut1.txt
/*全国 感染患者15人 疑似患者22人 治愈2人 死亡1人 * 福建 感染患者5人 疑似患者7人 治愈0人 死亡0人 * 湖北 感染患者10人 疑似患者15人 治愈2人 死亡1人 * // 该文档并非真实数据,仅供测试使用 * // 命令:list -log D:\log\ -out D:\ListOut1.txt -date 2020-01-22 */ @Test public void testListOut1() { InfectStatistic.main("list -log D:\\log\\ -out D:\\ListOut1.txt -date 2020-01-22".split(" ")); }

-
测试ListOut2.txt
/* 福建 感染患者5人 疑似患者7人 治愈0人 死亡0人 河北 感染患者0人 疑似患者0人 治愈0人 死亡0人 // 该文档并非真实数据,仅供测试使用 // 命令:list -log D:\log\ -out D:\ListOut2.txt -date 2020-01-22 -province 福建 河北 */ @Test public void testListOut2() { InfectStatistic.main("list -log D:\\log\\ -out D:\\ListOut2.txt -date 2020-01-22 -province 福建 河北".split(" ")); }

-
测试ListOut3.txt
/* 全国 治愈4人 死亡3人 感染患者42人 福建 治愈1人 死亡0人 感染患者9人 浙江 治愈0人 死亡0人 感染患者0人 // 该文档并非真实数据,仅供测试使用 // 命令:list -log D:\log\ -out D:\ListOut7.txt -date 2020-01-23 -type cure dead ip -province 全国 浙江 福建 */ @Test public void testListOut3() { InfectStatistic.main("list -log D:\\log\\ -out D:\\ListOut3.txt -date 2020-01-23 -type cure dead ip -province 全国 浙江 福建".split(" ")); }

-
默认不存在-date,-type,-province的输出结果
//默认不存在-date,-type,-province的输出结果 @Test public void testDefaultAll() { InfectStatistic.main("list -log D:\\log\\ -out D:\\output4.txt".split(" ")); }

-
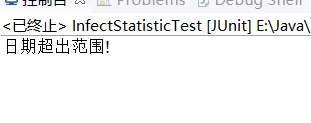
测试超出最晚日志日期
//测试超出最晚日志日期 @Test public void testOutOfDate() { InfectStatistic.main("list -log D:\\log\\ -out D:\\output5.txt -date 2020-02-22".split(" ")); }
-
测试日期不存在对应的日志文件
//测试日期不存在对应的日志文件 @Test public void testBetweenDate() { InfectStatistic.main("list -log D:\\log\\ -out D:\\output6.txt -date 2020-01-25".split(" ")); }

-
测试只列出指定省份:全国、浙江、福建
//测试只列出指定省份:全国、浙江、福建 @Test public void testAllAndProvince() { InfectStatistic.main("list -log D:\\log\\ -out D:\\output7.txt -province 全国 浙江 福建".split(" ")); }

-
测试不列全国,列省份
//测试不列全国,列省份 @Test public void testProvince() { InfectStatistic.main("list -log D:\\log\\ -out D:\\output8.txt -province 福建 江苏".split(" ")); }

-
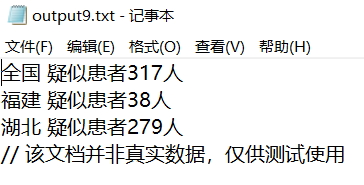
测试-type指定一个时
//测试-type指定一个时 @Test public void testOneType() { InfectStatistic.main("list -log D:\\log\\ -out D:\\output9.txt -type sp".split(" ")); }
-
测试-type指定多个时的输出顺序
//测试-type指定多个时的输出顺序 @Test public void testType() { InfectStatistic.main("list -log D:\\log\\ -out D:\\output10.txt -type cure sp ip".split(" ")); }

7.单元测试覆盖率优化和性能测试
学习资料:eclipse中代码测试覆盖率
覆盖率:
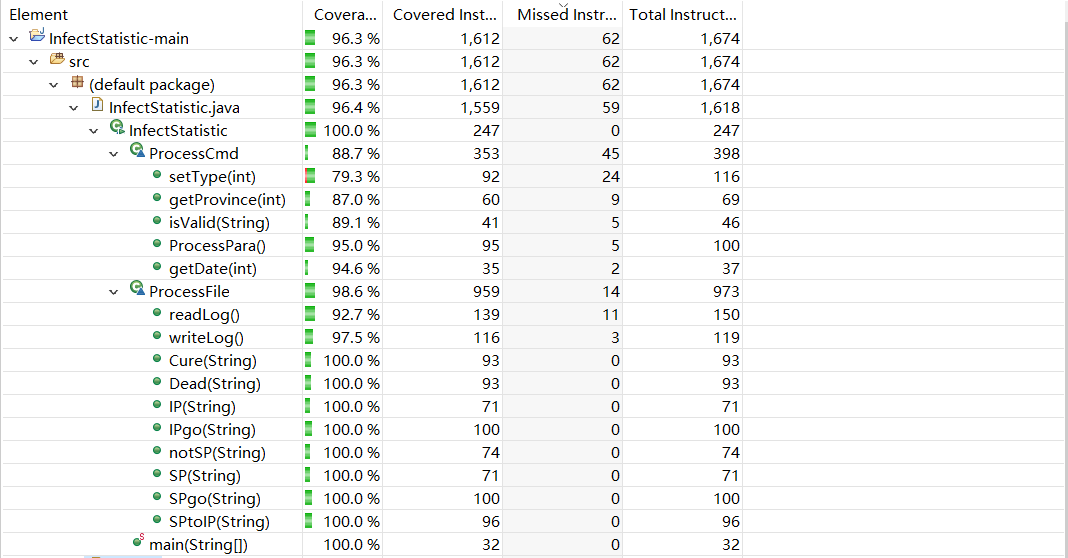
- Coverage:代码测试覆盖率
- Covered Instructions:覆盖到的指令行
- Missed Instructions:没覆盖的指令行
- Total Instructions:总指令行数
性能测试: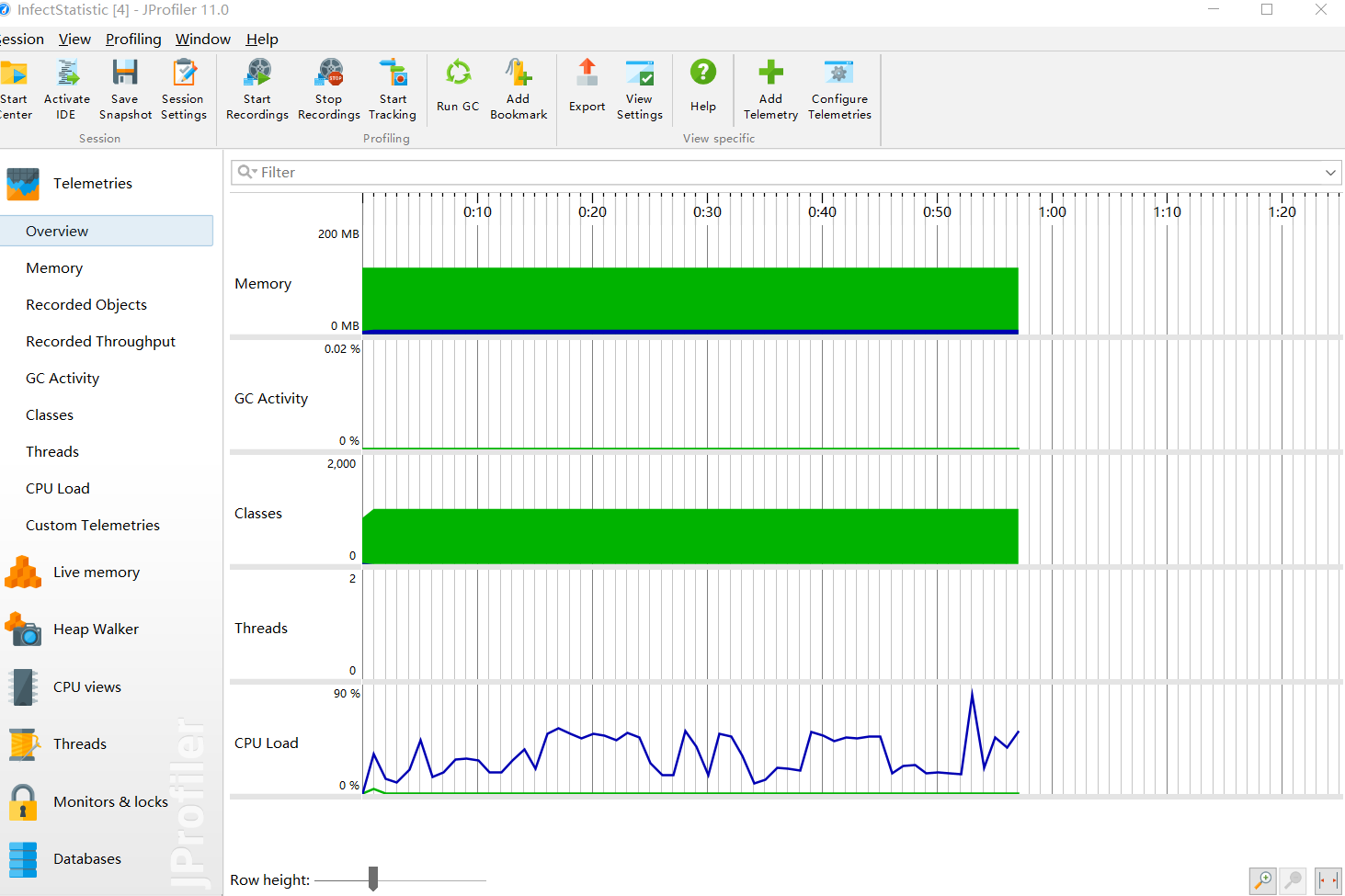
内存使用情况:
8.代码规范
https://github.com/FZU-YXJ/InfectStatistic-main/blob/master/041701320/codestyle.md
9.心路历程与收获
第一遍读题,毫无思路,有很多不理解的概念。什么是git,什么是github,GitHub desktop是用来干嘛的?fork是什么,commit是什么?pull request是什么? 命令行要怎么处理?单元测试是什么东西?作业中给的链接的知识点看了也不是能理解的很清楚,所以我只能自学许多知识。与此同时,还面临着java语法的遗忘。这次的作业让我收获很多,从一开始看缪雪峰的git教程,到后面学习命令行参数的处理,复习java对文件的读写操作,最后又学习了利用JUnite 4进行单元测试,利用JProfiler进行性能测试......勉勉强强掌握了这次作业要求的技能,学会使用GitHub,复习了java,学习了单元检测和性能测试的方法,以及对《构建之法》这本书的学习。
正如《构建之法》中所说,软件=程序+软件工程:正是因为对软件开发活动(构建管理、源代码管理、软件设计、软件测试、项目管理)相关的内容的完成,才能完成把整个程序转化成为一个可用的软件的过程。软件工程包括了开发、运用、维护软件的过程中的很多技术、做法、习惯和思想。软件工程把这些相关的技术和过程统一到一个体系中,叫“软件开发流程”,软件开发流程的目的是为了提高软件开发、运营和维护的效率,以及提升用户满意度、软件的可靠性和可维护性。
《构建之法》第二章的个人技术和流程以及软件工程师的成长,改变了我长期以来对我这个专业发展方向的很多困惑和误解,我一直觉得我作为一个程序员只要学如何写代码,顶多把数据结构和算法掌握清楚、操作系统和计算机网络的知识学习扎实,会写前端会折腾数据库就可以了。读了这本书之后我才明白自己其实离一个优秀的程序员还差得很远,努力得还远远不够。而且光局限自己把代码写好是远远不够的,团队协作、小组敏捷开发、迭代会议、单元测试和代码复审这些部分都是我之前完全不了解的。
例如代码复审,目的是找出代码错误、发现逻辑错误、发现算法错误、发现潜在的错误和回归性错误、发现可能需要改进的地方、传授经验。“敏捷流程”是一系列价值观和方法论的集合。步骤大概就是,找项目,分配任务,每日例会报告目标和完成的任务,和自己遇到的问题。统一流程Rational Unified Process,团队的各种成员在一个复杂的软件项目中的不同阶段做不同的事。这些不同类型的工作在RUP中叫做规程或者工作流。分为四个阶段:初始阶段(达到生命周期目标里程碑)、细化阶段(达到生命周期结构里程碑)、构造阶段(达到初始功能里程碑)、交付阶段(达到产品发布里程碑)。MSF是微软解决方案框架。MSF过程模型是从传统的软件开发瀑布模型和螺旋模型发展而来的。MSF过程模型的基本元素是阶段和里程碑。
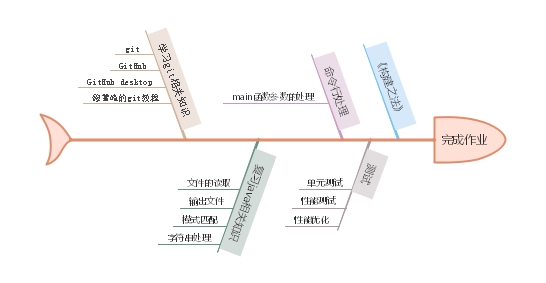
心路历程:
10.技术路线图相关的5个仓库
| 名称 | 链接 | 简介 |
|---|---|---|
| 很棒的机器学习 | 链接 | 精选的很棒的机器学习框架,库和软件的列表(按语言) |
| 算法/python | 链接 | 用python实现所有的算法 |
| Deep Learning for humans | 链接 | 用Python编写的高级神经网络API,能够在TensorFlow,CNTK或Theano之上运行。它的开发着眼于实现快速实验。能够以最小的延迟将想法付诸实践。 |
| tensorflow | 链接 | TensorFlow提供了稳定的Python 和C ++ API,以及其他语言的非保证的向后兼容API。是用于机器学习的端到端开源平台。 |
| 神经网络和深度学习 | 链接 | 包含《神经网络与深度学习》一书的代码示例。该代码是为python2.6或2.7编写的。 |
[20320/codestyle.md
