

威胁建模之WEB应用自动化截图
1、需求场景
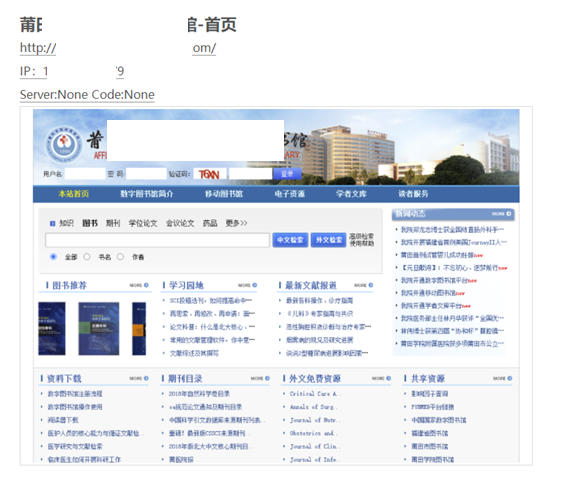
给定一个包含大量IP地址/域名、端口、协议的文件,设计一个流程提取文件中的关键信息,并使用工具自动化批量访问目标WEB应用形成截图。
- 输入示例

- 输出示例
2、实现思路
- 数据分析
表格的数据存在一定程度的冗余,需要做去重操作,主要在于保留{IP,port}的二元组还是{IP,port,Protocol}的三元组。做一个对比如下表所示:
| Type | Advantage | Shortcoming |
|---|---|---|
| 二元组 | 兼容性强,无需考虑Protocol一列可能随着版本更新而发生改变导致的兼容问题 | 数据会有一定程度的冗余 |
| 三元组 | 最大程度去重,可以最大程度排除无用数据 | Protocol需要做严格的分类,对于不同来源的数据集兼容性不会太好 |
-
排序
python使用set方法去重会导致乱序,这对于用户体验是一种影响。大量数据处理时做检查时,按序检查可以有更高的效率,在去重后还是要注意保留原始数据的顺序。 -
访问并截图
python访问大量网站一般来说我们都会想到python的requests模块,但是对于需要网站截图这种情况,使用selenium的webdriver效果会更好一些。
原因也很简单,requests模块只能爬取html信息,对于CSS和JS不做处理。而selenium的webdriver可以模拟人为操作,访问网站并截图,自然也就不会只看html了。 -
多线程并发
很明显本次课题的任务脚本属于I/O密集型,大部分时间都在网络上跑,CPU的运行效率是偏低的。所以利用多线程,可以更快地完成任务。 -
保存并生成html文件
使用python的文件操作在目录下创建一个后缀html的文件,并用python自动写入即可完成。
3、脚本逻辑

4、脚本源码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pandas as pd
import time
import threading
import os
def urlGet(filePath):
"""
:param filePath: 字符串,文件路径,仅限xlsx类型文件,
:return:列表,去重[ip:port]
"""
url = pd.read_excel(filePath, usecols=[0, 2])
urlList = url.values.tolist()
urlPort = []
for url in urlList:
urlPort.append(url[0] + ':' + str(url[1]))
urlPortList_Nodup = list(set(urlPort))
urlPortList_Nodup.sort(key=urlPort.index)
return (urlPortList_Nodup)
def screenShot(urlPortList, step, time):
"""
:param urlPortList: 列表,[ip:port]
:param step: int,步长
:param time: int,时长
:return: 空
"""
global screenshotList
for urlPort in urlPortList[::step]:
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--start-maximized')
chrome_options.add_argument('--ignore-certificate-errors')
driver = webdriver.Chrome(options=chrome_options)
try:
# print('https://'+urlPort)#
driver.set_page_load_timeout(time)
driver.get("https://" + urlPort)
imgPath = "./img/s" + urlPort.replace(":", "_") + ".png"
driver.get_screenshot_as_file(imgPath)
except Exception as e:
# print(e)
# print('http://'+urlPort)
try:
driver.set_page_load_timeout(time)
driver.get("http://" + urlPort)
imgPath = "./img/" + urlPort.replace(":", "_") + ".png"
driver.get_screenshot_as_file(imgPath)
except Exception as e:
print(e)
# print('time out,try by yourself')
finally:
driver.quit()
# time.sleep(0.05)
# print('one finished')
def createThreads(urlPortList, step, time):
"""
:param urlPortList:列表,[ip:port]
:param step: int,步长
:param time: int,时长
:return: 列表,长度和步长数相等的线程列表
"""
threads = []
for i in range(step):
t = threading.Thread(target=screenShot, args=(urlPortList[i::], step, time))
threads.append(t)
return threads
def changeToHtml(urlPortList):
"""
:param urlPortList: 列表,[ip:port]
:return: 空
"""
newfile = './report.html'
with open(newfile, 'w') as f:
f.write('<div>')
for urlPort in urlPortList:
imgPathHttps = "./img/s" + urlPort.replace(":", "_") + ".png"
imgPathHttp = "./img/" + urlPort.replace(":", "_") + ".png"
f.write('IP and Port:' + urlPort + '<br>')
if (os.path.isfile(imgPathHttps) == False):
if (os.path.isfile(imgPathHttp) == False):
f.write('Time out,extend request time or try by yourself<br>\n')
else:
f.write("网址:<a href=http://%s>http://%s</a><br>" % (urlPort, urlPort))
f.write("<img src='%s'><br>\n" % imgPathHttp)
else:
f.write("网址:<a href=https://%s>https://%s</a><br>" % (urlPort, urlPort))
f.write("<img src='%s'><br>\n" % imgPathHttps)
f.write('</div>')
def main():
time1 = time.time()
urlPortList = urlGet('./data_1500.xlsx')
print(len(urlPortList))
try:
threads = createThreads(urlPortList, 20, 3)
for t in threads:
t.start()
for t in threads:
t.join()
changeToHtml(urlPortList)
print("end")
time2 = time.time()
print(time2 - time1)
except Exception as e:
print(e)
time2 = time.time()
print(time2 - time1)
if __name__ == '__main__':
main()
5、脚本运行环境
前置条件
- windows系统
- chrome浏览器、chromedriver
- 脚本源码所需要的python模块
- chromedriver路径需要添加进系统环境变量
- 数据集和脚本在同一级别目录下
运行方法
-
102 urlPortList = urlGet('./data_1500.xlsx') #在此更改需要扫描的数据集 -
105 threads = createThreads(urlPortList, 20, 3) #在此输入线程数和超时时间 -
运行脚本,脚本同级别目录下生成reprot.html文件
6、脚本运行结果
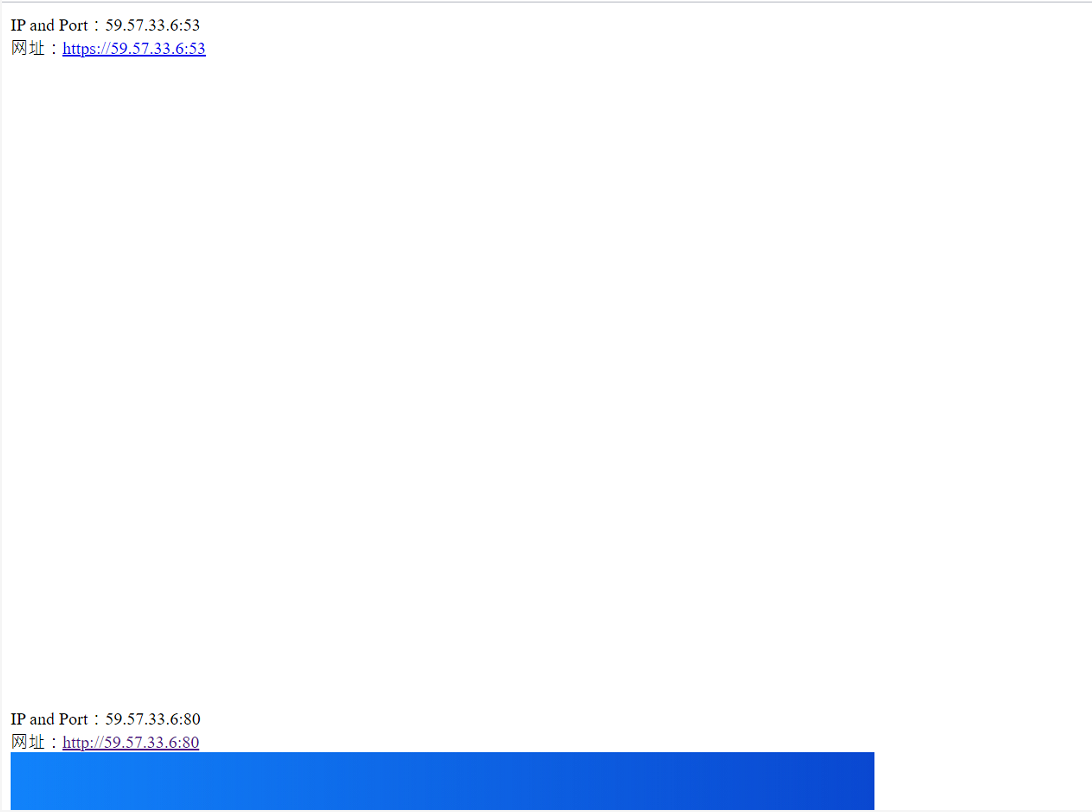
7、学无止境
脚本可以添加的功能:
- 各种浏览器兼容
- 数据集类型兼容
- 系统环境兼容
- HTTP返回值捕捉实现更精准的分析
- 更好看的html文件
- 多线程与多进程的进一步课题研究
