


第一次个人编程作业
目录
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 480 | 800 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 150 |
| Design Spec | 生成设计文档 | 20 | 30 |
| Design Review | 设计复审 | 30 | 45 |
| Coding Standard | 代码规范(为开发制定合适的规范) | 15 | 25 |
| Design | 具体设计 | 100 | 110 |
| Coding | 具体编码 | 120 | 180 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 150 | 200 |
| Reporting | 报告 | 40 | 60 |
| Test Repor | 测试报告 | 10 | 10 |
| Size Measurement | 计算工作量 | 20 | 25 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 30 |
| Total | 总计 | 1195 | 1765 |
模块接口的设计与实现过程
函数
- get_name()正则匹配re.search()
- get_phone()正则匹配re.search()
- get_province()查询一级地址表
- get_city()查询二级地址表
- get_village()正则匹配re.search()
- get_town()正则匹配re.search()
- get_road()正则匹配re.search()
- get_num()正则匹配re.search()
- main()
实现过程
因为python在处理字符串上的优越性,优先使用python进行程序编写。
从2个方面出发去设计这个程序的框架。
用面向过程的设计方法设计程序主体结构main()函数。假设能够合理地从字符串中筛选出想要的信息,要进行怎样的处理。
大致流程为:获取信息->判断非空->利用re.sub()对字符串进行部分删除,返回空则跳过该步(可以有效减少程序的分支和特判情况)->将获取到的信息添加进dict{}中->继续提取信息
用面向对象的设计方法设计各个get_函数。如何筛选出想要的信息
大致流程为:一级和二级地址用查表的方式从字典中读取->其余因为地址表只有2级的原因退而求其次使用正则匹配(会出现匹配不准确的情况)
流程图(大概)

性能分析
在做性能分析之前,我预计时间占比最大的2个函数应该是get_province和get_city。因为这2个函数需要在字典树中进行多次比对,但是很出乎意料,只做一次测试的结果显示并不是这2个函数。

这其实是不符合常理的,因为虽然其他的函数中也有多次判定,但时间应该不会超过查找字典树。所以我把主函数循环了一千次,观察1000次的时间占比。

观察到了预期的结果,为了更直观的表示,我在舍友的编译环境下再测了一遍并拿来了更直观的图。(鼠标左键单击该图片可在状态栏中选择全屏看图哦,再点击新页面的放大镜放大查看图片即可看清图中各元素)

至于性能优化的部分,我要说,时间占比最大的其实反而不是我自己设计的函数,而是print函数

高达37%的时间占比。而且其实在我循环1000次以后,我们可以观察到并没有一个函数的调用呈指数型增长,都是线性增长,就算删去几个,对时间复杂度也没有本质的优化。
如果要进一步进行优化的话可能只能从字典树入手,但考虑到字典树的规模(约400个元素),就算换成哈夫曼树,优化的时间也是十分有限的。(还有一部分原因是我不会设计哈夫曼树)
性能优化部分的思考就止步于此了
单元测试
单元测试的类型1(五级地址)代码部分编辑如下:
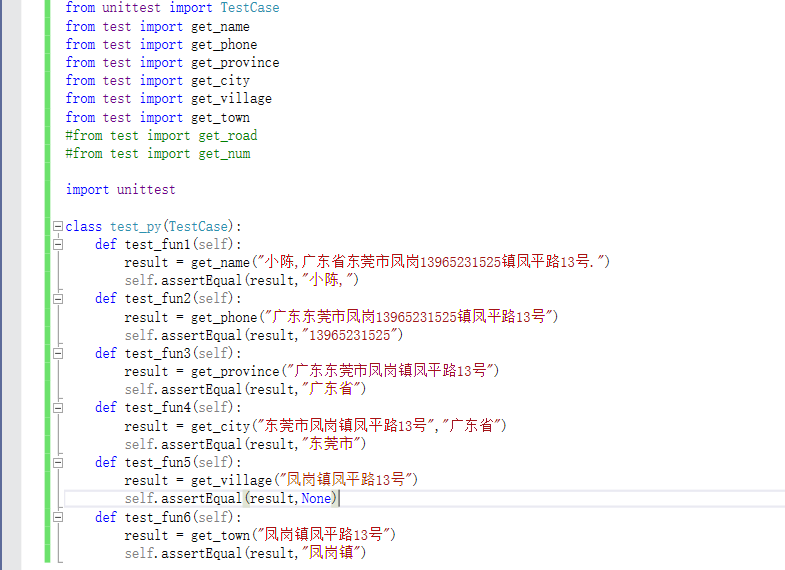
测试样例为1!小陈,广东省东莞市凤岗13965231525镇凤平路13号.
单元测试工具为python的unittest,得到结果如下图(json格式输出)

没有观察到failed的提示,注意图中的6个. 表示预期结果与代码输出相符
单元测试的类型2(七级地址)代码部分编辑如下:

结果如下(json格式输出):

(博客要求中要基于白盒测试做至少10例测试,而我们都有用大佬们设计的测试工具完成1150例样例测试,我觉得这个部分的意义是相同的,附上跑分截图:)

从跑分结果来看,其实我还是有一部分没有办法实现完全测试成功,有以下3点原因:
1、正则匹配提取地址有局限性,例如:福建莆田水关头丰美小区32号楼(并没有该样例,只是举个例子) 因为省略了县级的地址,导致在进行正则匹配的时候直接匹配到 “水关头丰美小区”并当作县级元素,很明显这是错的,但这却是难以避免的。
2、地址表的不完善导致最后50个类型3的测试点无法通过
3、一些地名的正则匹配字没有考虑进去,也就是打表打的不够。
(ps:上为连续测试跑分,下为单点测试跑分,如果大哥们在帮我测评的时候跑分与这张图不符,求求你们一定在我博客下面通知我一下,我马上连滚带爬过来私聊你,求求你们给我个挣扎的机会。)
覆盖率截图
下图为类型1的覆盖率截图:

下图为类型2的覆盖率截图:

这是符合预期的,因为类型1并没有参与7级地址的划分,而代码中有一部分是为7级划分编辑的,自然会有低一点的覆盖率。(类型3因为受限于二级地址表,没有办法实现反向查询的效果所以就没有覆盖率截图了)
异常处理
try:
type = string_input[0] #记录类型
except:
print("错误,禁止输入空字符串")
return -1

当输入空字符串的时候因为type无法获取到相关的值所以进程会中断,在此设计一个异常处理可以有效避免。
本次作业完,谢谢!!
10.2更新补充
因为测评工具更新,故补充一张在新的测评工具下的得分截图

(测试模式为mode slow,如果结果有出入,还请多找我聊聊)

