数据采集与融合技术实践作业4
102202143 梁锦盛
1.东方财富网信息爬取
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
一、作业代码与展示
1.编写代码文件
from selenium import webdriver
from selenium.webdriver.common.by import By
import mysql.connector
import time
# 设置 MySQL 连接
connection = mysql.connector.connect(
host="localhost",
user="root",
password="2896685056Qq!",
database="stock_data"
)
cursor = connection.cursor()
# 设置 Selenium 驱动
driver = webdriver.Chrome()
# 定义板块URL字典
board_urls = {
"沪深A股": "http://quote.eastmoney.com/center/gridlist.html#hs_a_board",
"上证A股": "http://quote.eastmoney.com/center/gridlist.html#sh_a_board",
"深证A股": "http://quote.eastmoney.com/center/gridlist.html#sz_a_board"
}
# 遍历每个板块页面并提取数据
for board_name, url in board_urls.items():
driver.get(url)
time.sleep(3) # 等待页面加载
# 获取表格每一行的股票数据
rows = driver.find_elements(By.XPATH, "//*[@id='table_wrapper-table']/tbody/tr")
for row in rows:
data = {
"bStockNo": row.find_element(By.XPATH, "./td[2]/a").text, # 股票代码
"bStockName": row.find_element(By.XPATH, "./td[3]/a").text, # 股票名称
"latestPrice": row.find_element(By.XPATH, "./td[5]").text, # 最新报价
"changeRate": row.find_element(By.XPATH, "./td[6]").text, # 涨跌幅
"changeAmount": row.find_element(By.XPATH, "./td[7]").text, # 涨跌额
"volume": row.find_element(By.XPATH, "./td[8]").text, # 成交量
"turnover": row.find_element(By.XPATH, "./td[9]").text, # 成交额
"amplitude": row.find_element(By.XPATH, "./td[10]").text, # 振幅
"highPrice": row.find_element(By.XPATH, "./td[11]/span").text, # 最高价
"lowPrice": row.find_element(By.XPATH, "./td[12]").text, # 最低价
"openPrice": row.find_element(By.XPATH, "./td[13]").text, # 今开
"prevClose": row.find_element(By.XPATH, "./td[14]").text # 昨收
}
# 移除百分号并转换为小数格式
data["changeRate"] = float(data["changeRate"].replace('%', '')) / 100 if '%' in data["changeRate"] else float(
data["changeRate"])
data["amplitude"] = float(data["amplitude"].replace('%', '')) / 100 if '%' in data["amplitude"] else float(
data["amplitude"])
print(data)
# 将数据插入 MySQL
cursor.execute("""
INSERT INTO stocks (bStockNo, bStockName, latestPrice, changeRate, changeAmount, volume, turnover, amplitude, highPrice, lowPrice, openPrice, prevClose, board)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
""", (data["bStockNo"], data["bStockName"], data["latestPrice"], data["changeRate"], data["changeAmount"],
data["volume"], data["turnover"], data["amplitude"], data["highPrice"], data["lowPrice"],
data["openPrice"], data["prevClose"], board_name))
# 提交事务
connection.commit()
# 关闭连接
cursor.close()
connection.close()
driver.quit()
2.运行结果


3.Gitee文件夹链接:https://gitee.com/liang-jinsheng-289668/project/tree/master/作业4
二、作业心得
完成这个作业,我懂得了任何使用selenium爬取不同页面的数据
2.mooc信息爬取
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
一、作业代码与展示
1.编写代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pymysql
import time
# 设置Chrome选项
options = webdriver.ChromeOptions()
options.add_argument('--disable-extensions')
options.add_argument('--no-sandbox')
driver = webdriver.Chrome(options=options)
# MySQL连接配置
db = pymysql.connect(
host='localhost',
user='root',
password='2896685056Qq!',
database='MoocData',
charset='utf8mb4'
)
cursor = db.cursor()
# 数据插入函数
def insert_data(course_info):
sql = """INSERT INTO Courses (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (%s, %s, %s, %s, %s, %s, %s)"""
cursor.execute(sql, course_info)
db.commit()
print(f"Data inserted: {course_info}")
# 登录函数
def login():
print("1")
driver.get("https://www.icourse163.org")
print("Accessing login page")
# 点击登录按钮
login_btn = driver.find_element(By.CLASS_NAME, "_3uWA6")
login_btn.click()
# 切换到登录框iframe
iframe = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.TAG_NAME, "iframe"))
)
driver.switch_to.frame(iframe)
# 输入用户名和密码
driver.find_element(By.ID, "phoneipt").send_keys("13015721181")
driver.find_element(By.XPATH,"//input[@type='password' and @name='email' and contains(@class, 'j-inputtext')]").send_keys("2896685056Qq!") # 输入密码
driver.find_element(By.ID, "submitBtn").click()
# 切换回主内容
driver.switch_to.default_content()
print("Login successful")
time.sleep(5)
# 主程序逻辑
def scrape_courses():
driver.get("https://www.icourse163.org")
print("Accessing course list page")
# 向下滚动以加载更多的_3KiL7类元素
scroll_pause_time = 3 # 每次滚动后等待的时间
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
try:
while True:
# 向下滚动页面
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(scroll_pause_time)
# 计算新的页面高度并比较
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# 等待新的_3KiL7类元素加载完成
courses = WebDriverWait(driver, 15).until(
EC.presence_of_all_elements_located((By.CLASS_NAME, "_3KiL7"))
)
for course in courses:
try:
# 基本信息提取
cCourse = course.find_element(By.CLASS_NAME, "_3EwZv").text
print(cCourse)
cCollege = course.find_element(By.CLASS_NAME, "_2lZi3").text
print(cCollege)
cCount = int(course.find_element(By.CLASS_NAME, "_3DcLu").text.replace("人参加", ""))
print(cCount)
# 进入课程详情页
course.find_element(By.CLASS_NAME, "_3EwZv").click()
driver.switch_to.window(driver.window_handles[-1])
# 等待详情页加载
WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.CLASS_NAME, "f-richEditorText"))
)
# 详情信息提取
cBrief = driver.find_element(By.CLASS_NAME, "f-richEditorText").text
print(cBrief)
cProcess = driver.find_element(By.CLASS_NAME, "text").text
print(cProcess)
cTeacher = driver.find_element(By.CLASS_NAME, "f-fc3").text
print(cTeacher)
cTeam = ", ".join(
[t.text for t in driver.find_elements(By.CLASS_NAME, "cnt h3")]
)
# 数据插入
course_info = (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
insert_data(course_info)
# 关闭详情页返回主页面
driver.close()
driver.switch_to.window(driver.window_handles[0])
except Exception as e:
print(f"Error processing course: {e}")
driver.switch_to.window(driver.window_handles[0])
# 检查是否存在下一页
if len(courses)==0:
break
time.sleep(3)
except Exception as e:
print(f"Error on page: {e}")
break
# 程序执行
try:
login()
scrape_courses()
finally:
driver.quit()
db.close()
2.运行结果


3.Gitee文件夹链接:https://gitee.com/liang-jinsheng-289668/project/tree/master/作业4
二、作业心得
我学会了如何使用selenium去逐个点击卡片进入不同页面并返回,并通过元素类名爬取不同的信息
3.Flume日志采集
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务
一、作业展示
任务一:Python脚本生成测试数据

任务二:配置Kafka
安装Kafka运行环境
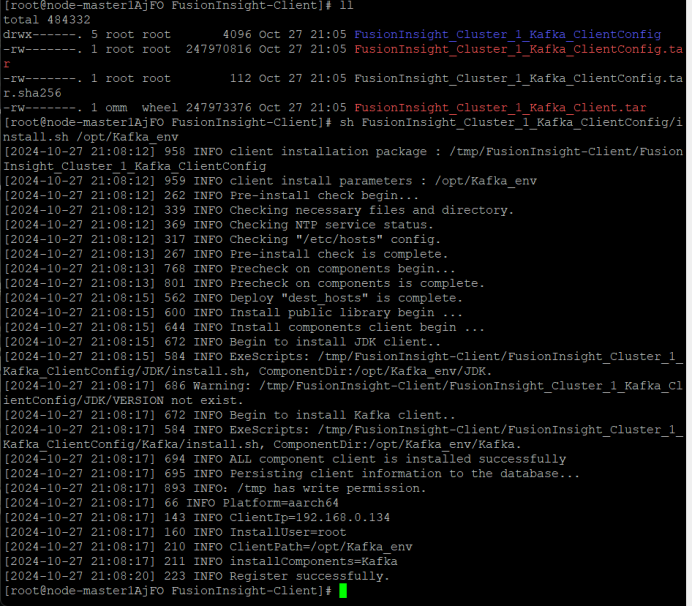
安装Kafka客户端

设置环境变量,在kafka中创建topic

任务三: 安装Flume客户端
安装Flume运行环境
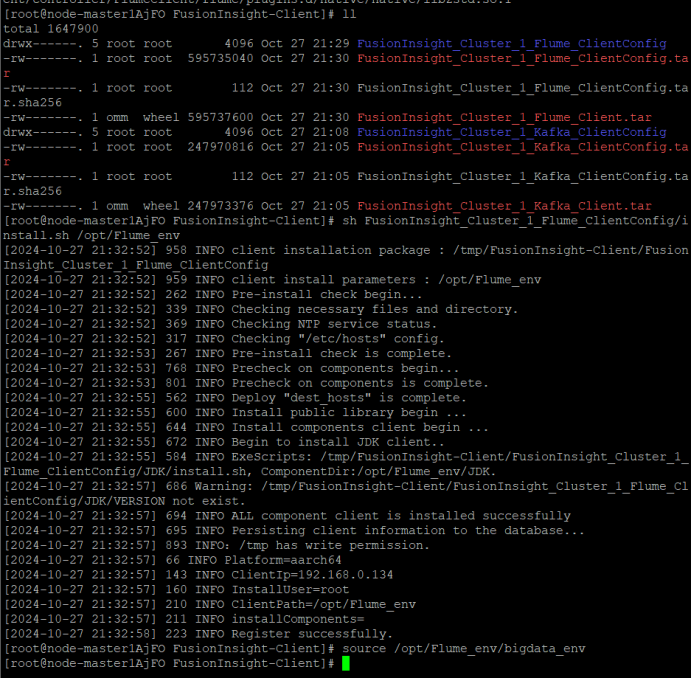
安装Flume到目录“/opt/FlumeClient”

任务四:配置Flume采集数据
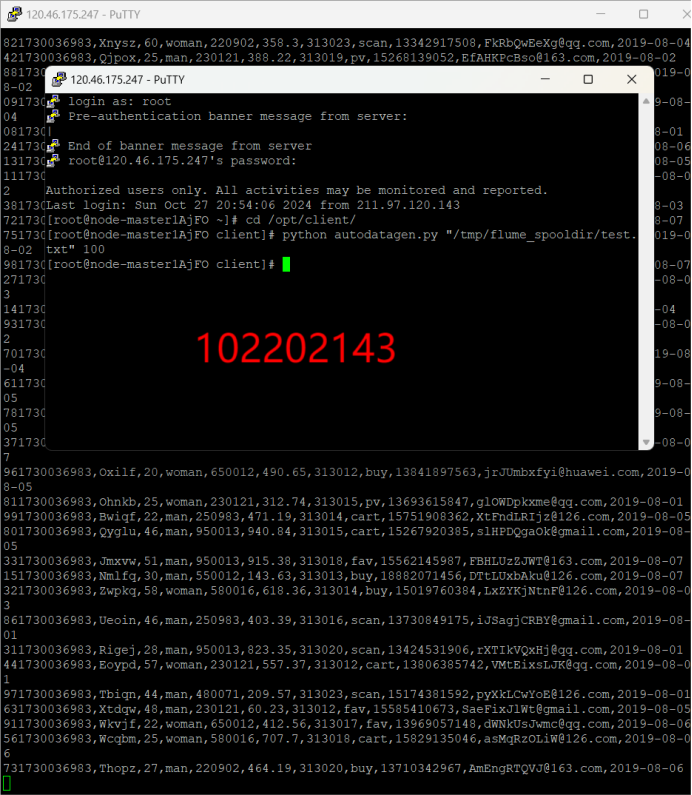
二、作业心得
完成这个作业,我了解了鲲鹏架构特点和优势,学会在华为云创建管理服务器实例,掌握 Hadoop 在鲲鹏服务器上的部署,包括 HDFS 的安装配置启动,学会配置优化参数及规划资源,还学会使用云平台工具服务,如云硬盘、弹性 IP 等。认识到实时分析重要性,了解其流程架构,体会到与离线分析的不同,需根据业务场景选择合适方式。培养了数据分析思维能力,认识到离线分析在企业中的应用,意识到要不断学习新技术适应变化,提高技术水平和耐心毅力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号