

数据采集与融合技术作业2
102202143 梁锦盛
1.中国气象网信息爬取
在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
一、作业代码与展示
1.编写代码文件
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import csv
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return []
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
weather_data = []
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req).read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
weather_data.append([city, date, weather, temp])
except Exception as err:
print("Error parsing data for", city, ":", err)
except Exception as err:
print("Error fetching data for", city, ":", err)
return weather_data
def process_and_export(self, cities, filename="weather_data.csv"):
all_weather_data = []
for city in cities:
city_weather_data = self.forecastCity(city)
all_weather_data.extend(city_weather_data)
# Write all data to CSV
with open(filename, 'w', newline='', encoding='utf-8') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(["City", "Date", "Weather", "Temperature"]) # Write header
writer.writerows(all_weather_data) # Write data rows
print(f"Data successfully exported to {filename}")
# 使用实例抓取并导出指定城市的天气数据
ws = WeatherForecast()
ws.process_and_export(["北京", "上海", "广州", "深圳"], "weather_data.csv")
print("Completed")
2.运行结果
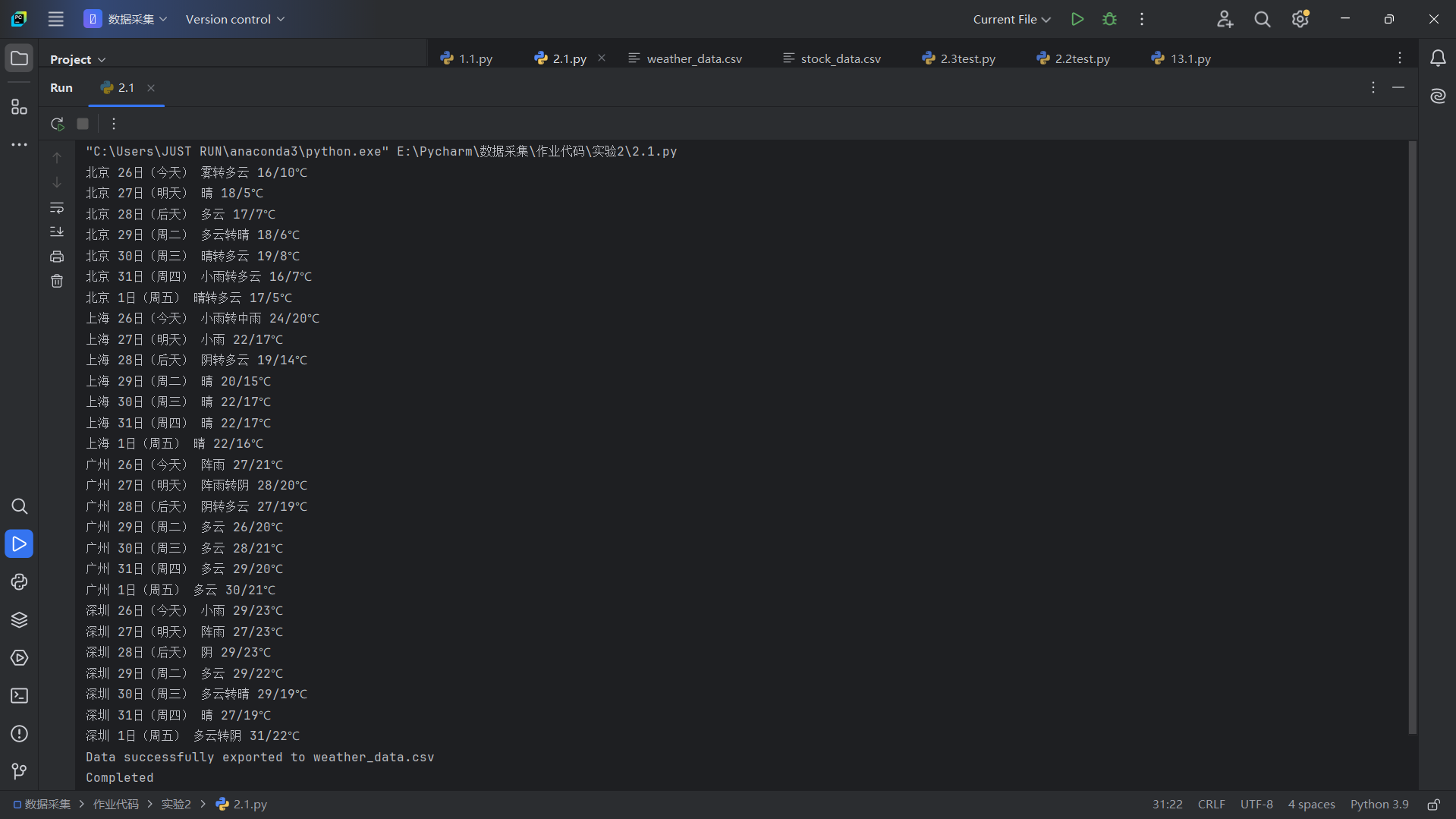
3.Gitee文件夹链接:https://gitee.com/liang-jinsheng-289668/project/tree/master/作业2/2.1
二、作业心得
完成这个作业,我对任何将数据存储到文件里有了更深刻的理解,这将帮助我更好地将爬取到的数据长期保存,将其保存到文件里也能够帮助我更好地去分析数据。
2.东方财富网信息爬取
用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
一、作业代码与展示
1.找到api
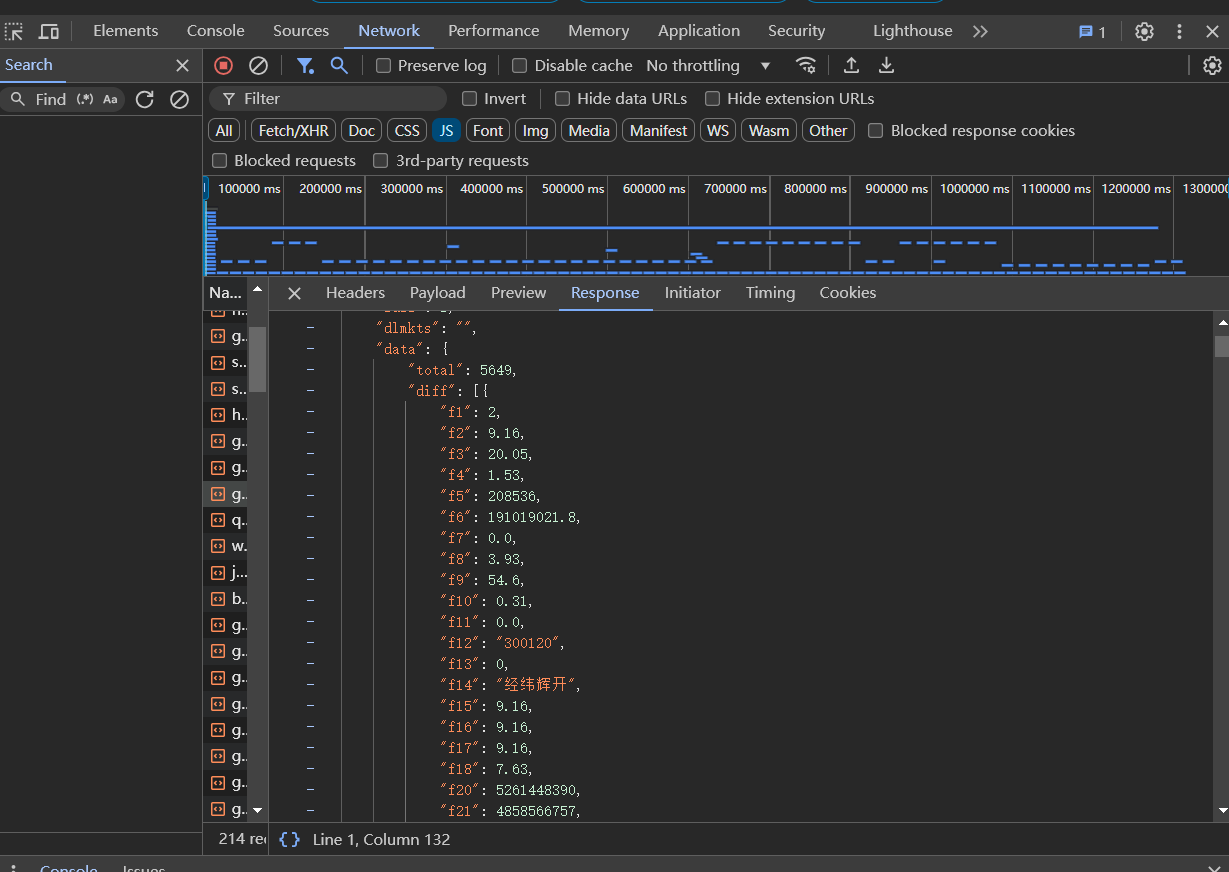
2.找到cookie

3.找到请求头
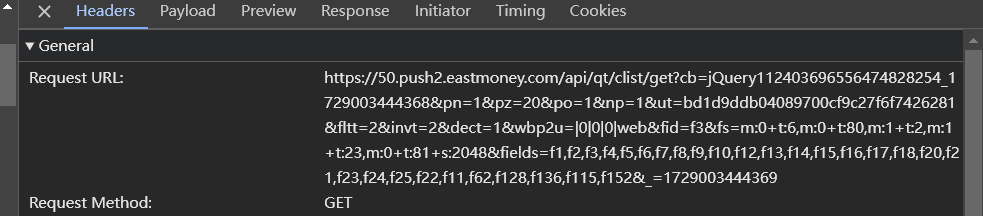
4.编写代码
import requests
import json
import pandas as pd
# 使用提供的cookie
cookies = {
'qgqp_b_id': '2d31e8f17cf8a3447185efdf4e253235',
'st_si': '66228653710444',
'st_asi': 'delete',
'st_pvi': '25044947399556',
'st_sp': '2024-10-15 16:41:44',
'st_inirUrl': 'https://www.eastmoney.com/',
'st_sn': '13',
'st_psi': '20241015165715752-111000300841-2878299811'
}
# 模拟请求的Headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
# 翻页爬取数据的函数
def scrape_data(page_number):
url = f'https://1.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409952374347191637_1728983306168&pn={page_number}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_={1728983306169 + page_number}'
response = requests.get(url, headers=headers, cookies=cookies)
# 检查是否成功获取页面
if response.status_code == 200:
json_data = response.text
# 提取JSON格式的有效数据,去掉回调函数名称
json_data = json_data[json_data.index('(') + 1: -2] # 去掉回调函数的包裹
data = json.loads(json_data) # 解析JSON数据
return data
else:
print(f'Failed to retrieve page {page_number}. Status code: {response.status_code}')
return None
# 爬取多页数据并存储到DataFrame
def scrape_multiple_pages(max_pages=5):
all_data = [] # 用于存储所有页的数据
for page_number in range(1, max_pages + 1): # 从第一页开始,直到 max_pages
print(f"正在爬取第 {page_number} 页数据...")
data = scrape_data(page_number)
if data and 'data' in data and 'diff' in data['data']:
for stock in data['data']['diff']:
stock_info = {
'名称': stock.get('f14'), # 股票名称
'最新价': stock.get('f2'), # 最新价
'涨跌幅': stock.get('f3'), # 涨跌幅
'成交量(手)': stock.get('f4'), # 成交量(手)
'成交额': stock.get('f5'), # 成交额
'振幅': stock.get('f6'), # 振幅
'最高价': stock.get('f7'), # 最高价
'最低价': stock.get('f8') # 最低价
}
all_data.append(stock_info) # 将每条数据追加到列表中
else:
print(f"第 {page_number} 页没有数据或请求失败")
break # 如果某页没有数据,终止循环
return all_data
# 开始爬取数据
max_pages = 5 # 假设你想爬取前 5 页
all_stock_data = scrape_multiple_pages(max_pages)
# 将数据存储到CSV文件
df = pd.DataFrame(all_stock_data)
df.to_csv('stock_data.csv', index=False, encoding='utf-8-sig') # 指定编码为 utf-8-sig,以便在 Excel 中正常显示
print("所有数据已爬取并存储到 stock_data.csv 文件中!")
5.运行结果
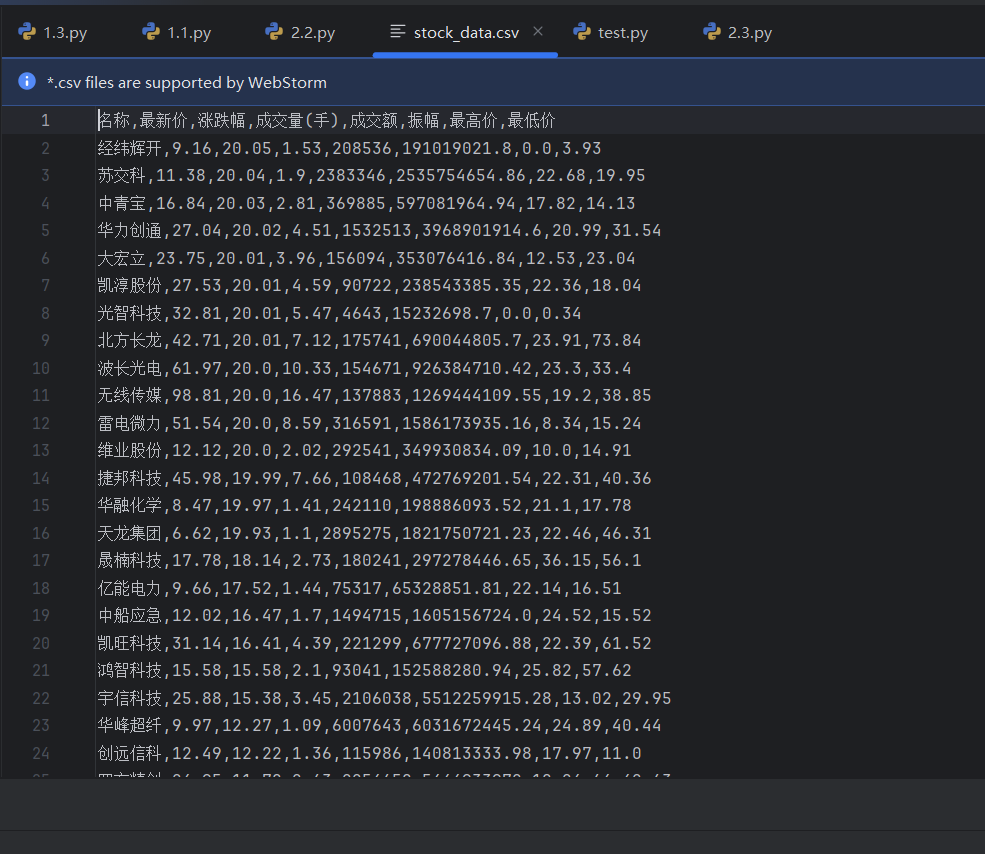
6.Gitee文件夹链接:https://gitee.com/liang-jinsheng-289668/project/tree/master/作业2/2.2
二、作业心得
我学会了如何去寻找api并从中解析提取数据,这使得我在爬取页面源代码中不存在的信息时更加得心应手
3.中国大学2021主榜信息爬取
爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
一、作业代码与展示
1.找到api
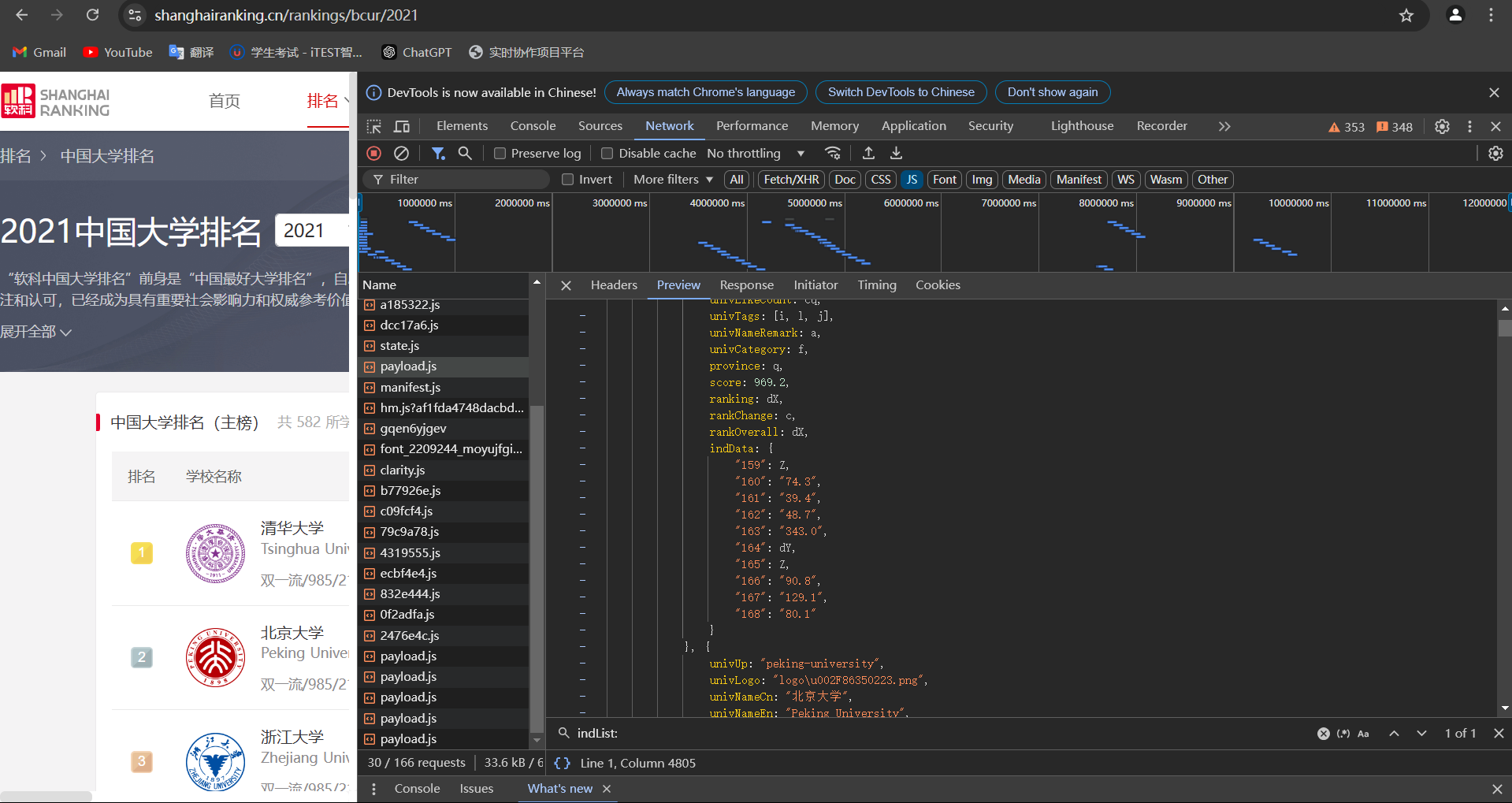
2.分析api文件,发现一些值被映射成码,需要将码还原成原来的值,第一行对应码,最后一行就是其原来的值
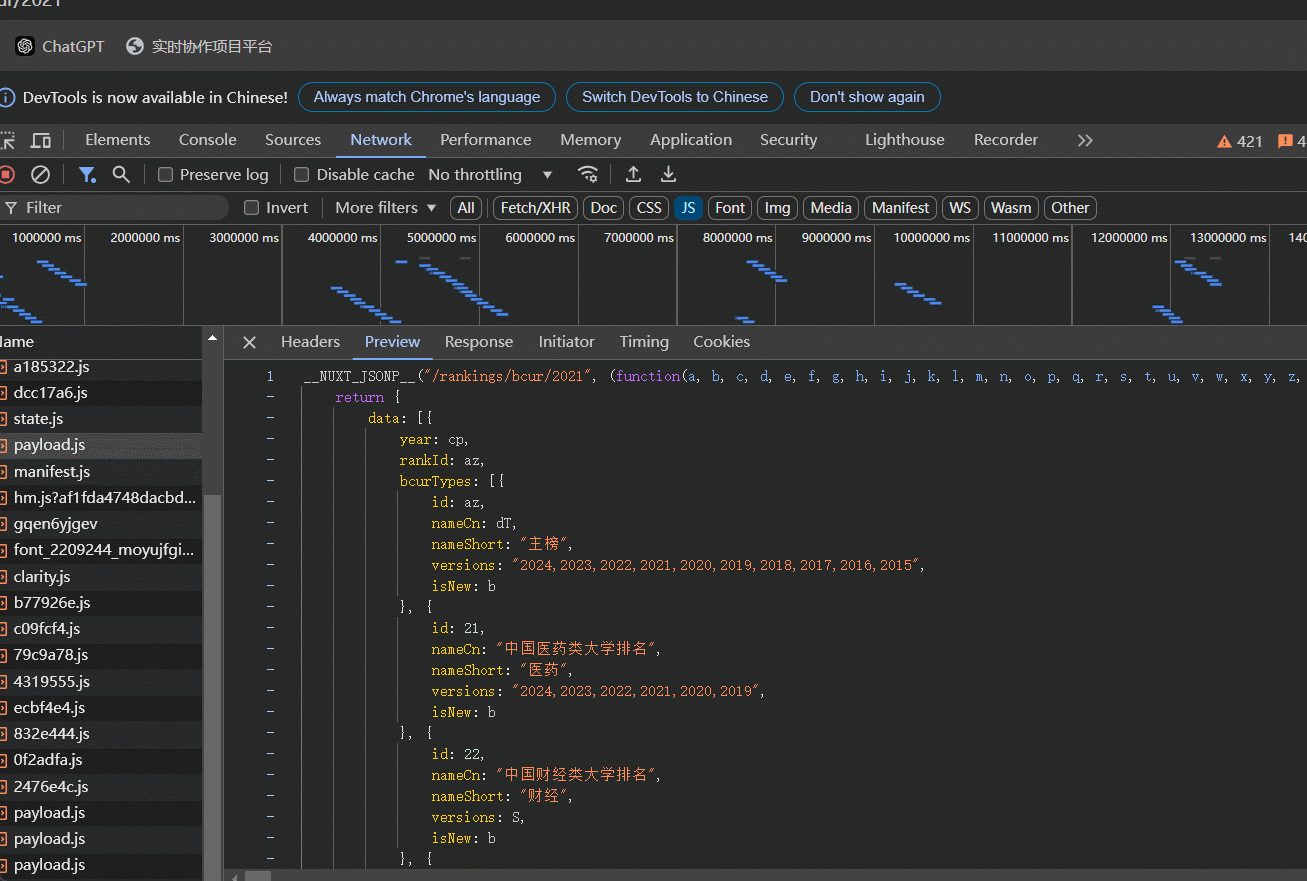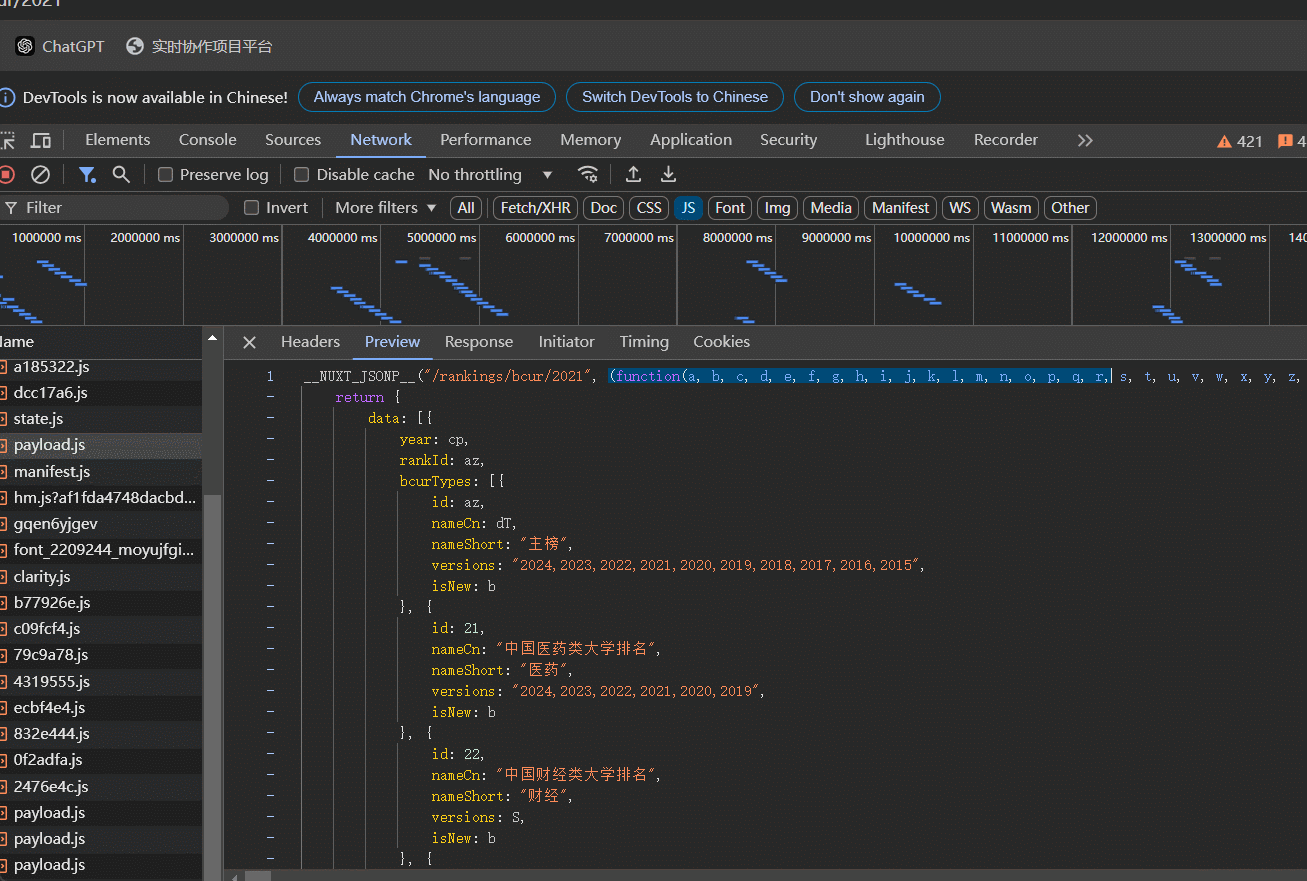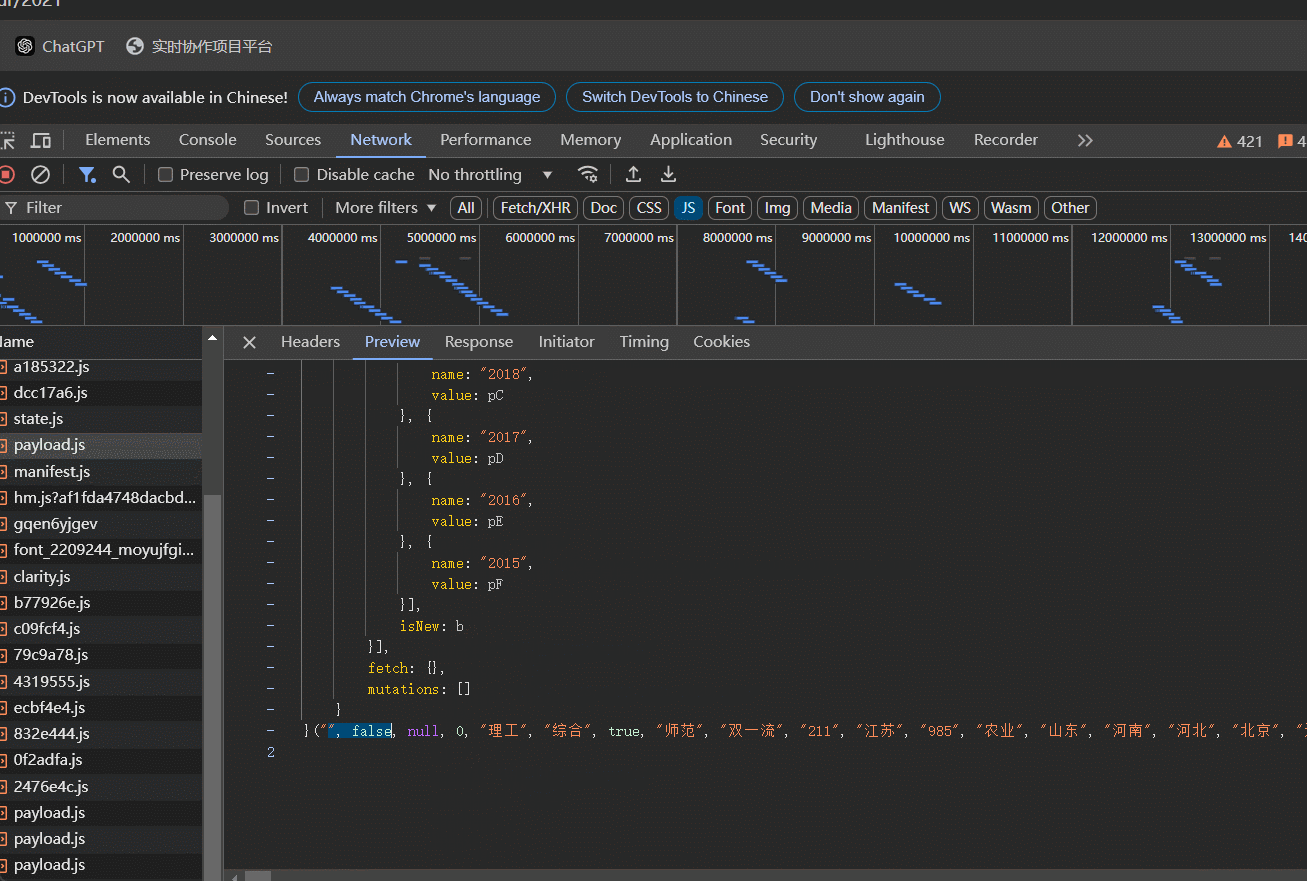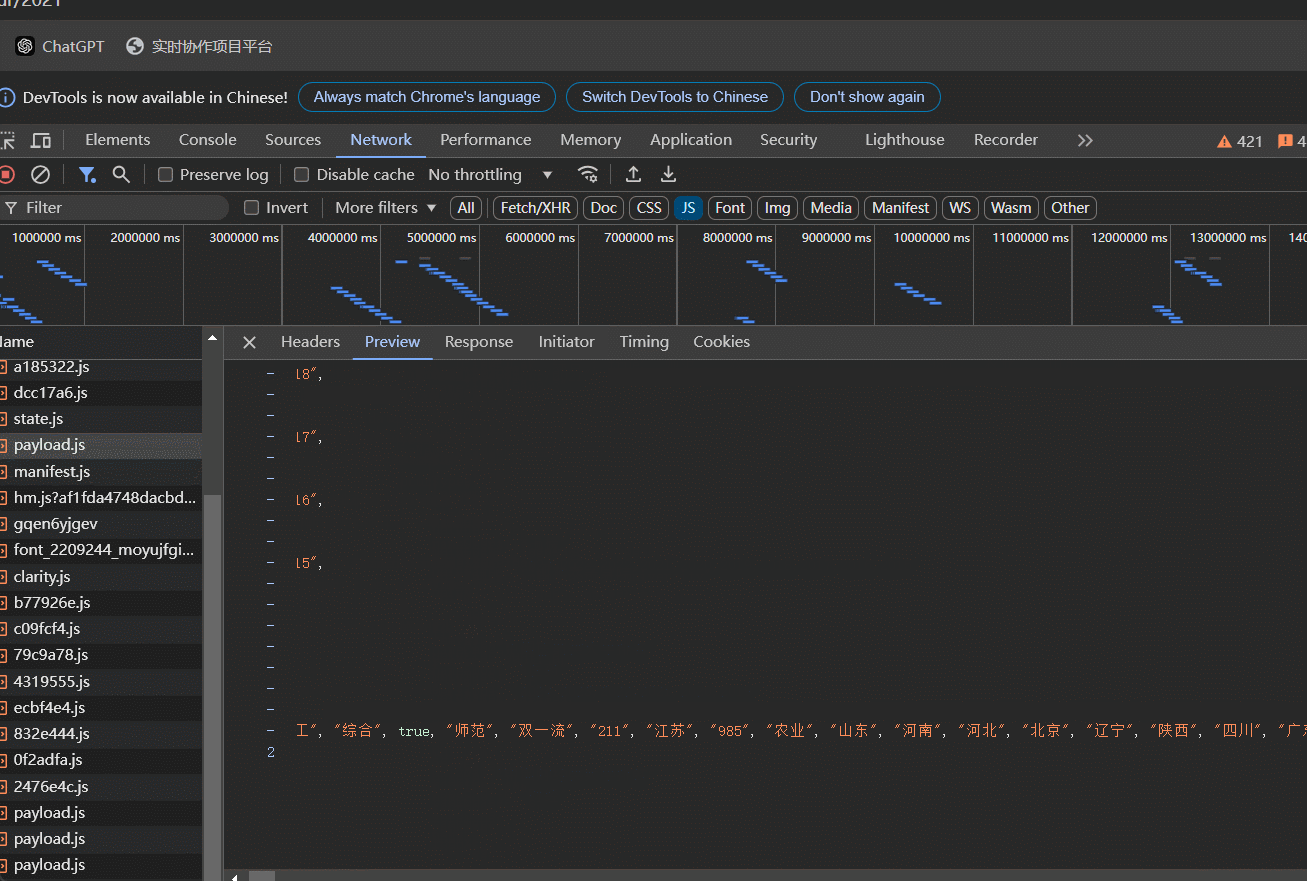
2.编写代码
# -*- coding: utf-8 -*-
import requests
import json
import re
import csv
# 定义请求的 URL 和 Headers
url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js"
headers = {
"Cookie": "_clck=12scz9o%7C2%7Cfq2%7C0%7C1749; Hm_lvt_af1fda4748dacbd3ee2e3a69c3496570=1729007101,1729920600; Hm_lpvt_af1fda4748dacbd3ee2e3a69c3496570=1729920600; HMACCOUNT=97E046AA3995ACB0",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
}
# 发送请求
response = requests.get(url, headers=headers)
text = response.text
obj = re.compile(r'univData:(?P<data>.*?)indList:', re.S)
data1 = obj.findall(text)
obj1 = re.compile(r'.*?univNameCn:(?P<name>.*?),.*?univCategory:(?P<type>.*?),.*?province:(?P<province>.*?),.*?score:(?P<score>.*?),.*?ranking:(?P<ranking>.*?),', re.S)
data2 = obj1.finditer(data1[0]) if data1 else []
a="a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z, A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, _, $, aa, ab, ac, ad, ae, af, ag, ah, ai, aj, ak, al, am, an, ao, ap, aq, ar, as, at, au, av, aw, ax, ay, az, aA, aB, aC, aD, aE, aF, aG, aH, aI, aJ, aK, aL, aM, aN, aO, aP, aQ, aR, aS, aT, aU, aV, aW, aX, aY, aZ, a_, a$, ba, bb, bc, bd, be, bf, bg, bh, bi, bj, bk, bl, bm, bn, bo, bp, bq, br, bs, bt, bu, bv, bw, bx, by, bz, bA, bB, bC, bD, bE, bF, bG, bH, bI, bJ, bK, bL, bM, bN, bO, bP, bQ, bR, bS, bT, bU, bV, bW, bX, bY, bZ, b_, b$, ca, cb, cc, cd, ce, cf, cg, ch, ci, cj, ck, cl, cm, cn, co, cp, cq, cr, cs, ct, cu, cv, cw, cx, cy, cz, cA, cB, cC, cD, cE, cF, cG, cH, cI, cJ, cK, cL, cM, cN, cO, cP, cQ, cR, cS, cT, cU, cV, cW, cX, cY, cZ, c_, c$, da, db, dc, dd, de, df, dg, dh, di, dj, dk, dl, dm, dn, do0, dp, dq, dr, ds, dt, du, dv, dw, dx, dy, dz, dA, dB, dC, dD, dE, dF, dG, dH, dI, dJ, dK, dL, dM, dN, dO, dP, dQ, dR, dS, dT, dU, dV, dW, dX, dY, dZ, d_, d$, ea, eb, ec, ed, ee, ef, eg, eh, ei, ej, ek, el, em, en, eo, ep, eq, er, es, et, eu, ev, ew, ex, ey, ez, eA, eB, eC, eD, eE, eF, eG, eH, eI, eJ, eK, eL, eM, eN, eO, eP, eQ, eR, eS, eT, eU, eV, eW, eX, eY, eZ, e_, e$, fa, fb, fc, fd, fe, ff, fg, fh, fi, fj, fk, fl, fm, fn, fo, fp, fq, fr, fs, ft, fu, fv, fw, fx, fy, fz, fA, fB, fC, fD, fE, fF, fG, fH, fI, fJ, fK, fL, fM, fN, fO, fP, fQ, fR, fS, fT, fU, fV, fW, fX, fY, fZ, f_, f$, ga, gb, gc, gd, ge, gf, gg, gh, gi, gj, gk, gl, gm, gn, go, gp, gq, gr, gs, gt, gu, gv, gw, gx, gy, gz, gA, gB, gC, gD, gE, gF, gG, gH, gI, gJ, gK, gL, gM, gN, gO, gP, gQ, gR, gS, gT, gU, gV, gW, gX, gY, gZ, g_, g$, ha, hb, hc, hd, he, hf, hg, hh, hi, hj, hk, hl, hm, hn, ho, hp, hq, hr, hs, ht, hu, hv, hw, hx, hy, hz, hA, hB, hC, hD, hE, hF, hG, hH, hI, hJ, hK, hL, hM, hN, hO, hP, hQ, hR, hS, hT, hU, hV, hW, hX, hY, hZ, h_, h$, ia, ib, ic, id, ie, if0, ig, ih, ii, ij, ik, il, im, in0, io, ip, iq, ir, is, it, iu, iv, iw, ix, iy, iz, iA, iB, iC, iD, iE, iF, iG, iH, iI, iJ, iK, iL, iM, iN, iO, iP, iQ, iR, iS, iT, iU, iV, iW, iX, iY, iZ, i_, i$, ja, jb, jc, jd, je, jf, jg, jh, ji, jj, jk, jl, jm, jn, jo, jp, jq, jr, js, jt, ju, jv, jw, jx, jy, jz, jA, jB, jC, jD, jE, jF, jG, jH, jI, jJ, jK, jL, jM, jN, jO, jP, jQ, jR, jS, jT, jU, jV, jW, jX, jY, jZ, j_, j$, ka, kb, kc, kd, ke, kf, kg, kh, ki, kj, kk, kl, km, kn, ko, kp, kq, kr, ks, kt, ku, kv, kw, kx, ky, kz, kA, kB, kC, kD, kE, kF, kG, kH, kI, kJ, kK, kL, kM, kN, kO, kP, kQ, kR, kS, kT, kU, kV, kW, kX, kY, kZ, k_, k$, la, lb, lc, ld, le, lf, lg, lh, li, lj, lk, ll, lm, ln, lo, lp, lq, lr, ls, lt, lu, lv, lw, lx, ly, lz, lA, lB, lC, lD, lE, lF, lG, lH, lI, lJ, lK, lL, lM, lN, lO, lP, lQ, lR, lS, lT, lU, lV, lW, lX, lY, lZ, l_, l$, ma, mb, mc, md, me, mf, mg, mh, mi, mj, mk, ml, mm, mn, mo, mp, mq, mr, ms, mt, mu, mv, mw, mx, my, mz, mA, mB, mC, mD, mE, mF, mG, mH, mI, mJ, mK, mL, mM, mN, mO, mP, mQ, mR, mS, mT, mU, mV, mW, mX, mY, mZ, m_, m$, na, nb, nc, nd, ne, nf, ng, nh, ni, nj, nk, nl, nm, nn, no, np, nq, nr, ns, nt, nu, nv, nw, nx, ny, nz, nA, nB, nC, nD, nE, nF, nG, nH, nI, nJ, nK, nL, nM, nN, nO, nP, nQ, nR, nS, nT, nU, nV, nW, nX, nY, nZ, n_, n$, oa, ob, oc, od, oe, of, og, oh, oi, oj, ok, ol, om, on, oo, op, oq, or, os, ot, ou, ov, ow, ox, oy, oz, oA, oB, oC, oD, oE, oF, oG, oH, oI, oJ, oK, oL, oM, oN, oO, oP, oQ, oR, oS, oT, oU, oV, oW, oX, oY, oZ, o_, o$, pa, pb, pc, pd, pe, pf, pg, ph, pi, pj, pk, pl, pm, pn, po, pp, pq, pr, ps, pt, pu, pv, pw, px, py, pz, pA, pB, pC, pD, pE, pF, pG, pH, pI, pJ"
a1 = a.split(', ')
b = '"", false, null, 0, "理工", "综合", true, "师范", "双一流", "211", "江苏", "985", "农业", "山东", "河南", "河北", "北京", "辽宁", "陕西", "四川", "广东", "湖北", "湖南", "浙江", "安徽", "江西", "黑龙江", "吉林", "上海", "福建", "山西", "云南", "广西", 2, "贵州", "甘肃", "内蒙古", "重庆", "天津", "新疆", 1, "467", "496", "2023-01-05T00:00:00+08:00", "2024,2023,2022,2021,2020", "林业", "5.8", "533", "23.1", "7.3", "海南", "37.9", "28.0", "4.3", "12.1", "16.8", "11.7", "3.7", "4.6", "297", "397", "21.8", "32.2", "16.6", "37.6", "24.6", "13.6", "13.9", "3.3", "5.2", "8.1", "3.9", "5.1", "5.6", "5.4", "2.6", "162", 93.5, 89.4, 11, 14, 10, 13, "宁夏", "青海", "西藏", "11.3", "35.2", "9.5", "35.0", "32.7", "23.7", "33.2", "9.2", "30.6", "8.5", "22.7", "26.3", "8.0", "10.9", "26.0", "3.2", "6.8", "5.7", "13.8", "6.5", "5.5", "5.0", "13.2", "13.3", "15.6", "18.3", "3.0", "21.3", "12.0", "22.8", "3.6", "3.4", "3.5", "95", "109", "117", "129", "138", "147", "159", "185", "191", "193", "196", "213", "232", "237", "240", "267", "275", "301", "309", "314", "318", "332", "334", "339", "341", "354", "365", "371", "378", "384", "388", "403", "416", "418", "420", "423", "430", "438", "444", "449", "452", "457", "461", "465", "474", "477", "485", "487", "491", "501", "508", "513", "518", "522", "528", 83.4, "538", "555", 2021, 7, "12.8", "42.9", "18.8", "36.6", "4.8", "40.0", "37.7", "11.9", "45.2", "31.8", "10.4", "40.3", "11.2", "30.9", "37.8", "16.1", "19.7", "11.1", "23.8", "29.1", "0.2", "24.0", "27.3", "24.9", "39.5", "20.5", "23.4", "9.0", "4.1", "25.6", "12.9", "6.4", "18.0", "24.2", "7.4", "29.7", "26.5", "22.6", "29.9", "28.6", "10.1", "16.2", "19.4", "19.5", "18.6", "27.4", "17.1", "16.0", "27.6", "7.9", "28.7", "19.3", "29.5", "38.2", "8.9", "3.8", "15.7", "13.5", "1.7", "16.9", "33.4", "132.7", "15.2", "8.7", "20.3", "5.3", "0.3", "4.0", "17.4", "2.7", "160", "161", "164", "165", "166", "167", "168", 130.6, 105.5, 4, 2024, 15, "中国大学排名(主榜)", 25, 12, "全部", "1", "88.0", 5, "2", "36.1", "25.9", "3", "34.3", 6, "4", "35.5", "21.6", "39.2", "5", "10.8", "4.9", "30.4", "6", "46.2", "7", "0.8", "42.1", "8", "32.1", "22.9", "31.3", "9", "43.0", "25.7", "10", "34.5", "10.0", "26.2", "46.5", "11", "47.0", "33.5", "35.8", "25.8", "12", "46.7", "13.7", "31.4", "33.3", "13", "34.8", "42.3", "13.4", "29.4", "14", "30.7", "15", "42.6", "26.7", "16", "12.5", "17", "12.4", "44.5", "44.8", "18", "10.3", "15.8", "19", "32.3", "19.2", "20", "21", "28.8", "9.6", "22", "45.0", "23", "30.8", "16.7", "16.3", "24", "25", "32.4", "26", "9.4", "27", "33.7", "18.5", "21.9", "28", "30.2", "31.0", "16.4", "29", "34.4", "41.2", "2.9", "30", "38.4", "6.6", "31", "4.4", "17.0", "32", "26.4", "33", "6.1", "34", "38.8", "17.7", "35", "36", "38.1", "11.5", "14.9", "37", "14.3", "18.9", "38", "13.0", "39", "27.8", "33.8", "3.1", "40", "41", "28.9", "42", "28.5", "38.0", "34.0", "1.5", "43", "15.1", "44", "31.2", "120.0", "14.4", "45", "149.8", "7.5", "46", "47", "38.6", "48", "49", "25.2", "50", "19.8", "51", "5.9", "6.7", "52", "4.2", "53", "1.6", "54", "55", "20.0", "56", "39.8", "18.1", "57", "35.6", "58", "10.5", "14.1", "59", "8.2", "60", "140.8", "12.6", "61", "62", "17.6", "63", "64", "1.1", "65", "20.9", "66", "67", "68", "2.1", "69", "123.9", "27.1", "70", "25.5", "37.4", "71", "72", "73", "74", "75", "76", "27.9", "7.0", "77", "78", "79", "80", "81", "82", "83", "84", "1.4", "85", "86", "87", "88", "89", "90", "91", "92", "93", "109.0", "94", 235.7, "97", "98", "99", "100", "101", "102", "103", "104", "105", "106", "107", "108", 223.8, "111", "112", "113", "114", "115", "116", 215.5, "119", "120", "121", "122", "123", "124", "125", "126", "127", "128", 206.7, "131", "132", "133", "134", "135", "136", "137", 201, "140", "141", "142", "143", "144", "145", "146", 194.6, "149", "150", "151", "152", "153", "154", "155", "156", "157", "158", 183.3, "169", "170", "171", "172", "173", "174", "175", "176", "177", "178", "179", "180", "181", "182", "183", "184", 169.6, "187", "188", "189", "190", 168.1, 167, "195", 165.5, "198", "199", "200", "201", "202", "203", "204", "205", "206", "207", "208", "209", "210", "212", 160.5, "215", "216", "217", "218", "219", "220", "221", "222", "223", "224", "225", "226", "227", "228", "229", "230", "231", 153.3, "234", "235", "236", 150.8, "239", 149.9, "242", "243", "244", "245", "246", "247", "248", "249", "250", "251", "252", "253", "254", "255", "256", "257", "258", "259", "260", "261", "262", "263", "264", "265", "266", 139.7, "269", "270", "271", "272", "273", "274", 137, "277", "278", "279", "280", "281", "282", "283", "284", "285", "286", "287", "288", "289", "290", "291", "292", "293", "294", "295", "296", "300", 130.2, "303", "304", "305", "306", "307", "308", 128.4, "311", "312", "313", 125.9, "316", "317", 124.9, "320", "321", "Wuyi University", "322", "323", "324", "325", "326", "327", "328", "329", "330", "331", 120.9, 120.8, "Taizhou University", "336", "337", "338", 119.9, 119.7, "343", "344", "345", "346", "347", "348", "349", "350", "351", "352", "353", 115.4, "356", "357", "358", "359", "360", "361", "362", "363", "364", 112.6, "367", "368", "369", "370", 111, "373", "374", "375", "376", "377", 109.4, "380", "381", "382", "383", 107.6, "386", "387", 107.1, "390", "391", "392", "393", "394", "395", "396", "400", "401", "402", 104.7, "405", "406", "407", "408", "409", "410", "411", "412", "413", "414", "415", 101.2, 101.1, 100.9, "422", 100.3, "425", "426", "427", "428", "429", 99, "432", "433", "434", "435", "436", "437", 97.6, "440", "441", "442", "443", 96.5, "446", "447", "448", 95.8, "451", 95.2, "454", "455", "456", 94.8, "459", "460", 94.3, "463", "464", 93.6, "472", "473", 92.3, "476", 91.7, "479", "480", "481", "482", "483", "484", 90.7, 90.6, "489", "490", 90.2, "493", "494", "495", 89.3, "503", "504", "505", "506", "507", 87.4, "510", "511", "512", 86.8, "515", "516", "517", 86.2, "520", "521", 85.8, "524", "525", "526", "527", 84.6, "530", "531", "532", "537", 82.8, "540", "541", "542", "543", "544", "545", "546", "547", "548", "549", "550", "551", "552", "553", "554", 78.1, "557", "558", "559", "560", "561", "562", "563", "564", "565", "566", "567", "568", "569", "570", "571", "572", "573", "574", "575", "576", "577", "578", "579", "580", "581", "582", 9, "2024-04-18T00:00:00+08:00", "logo\u002Fannual\u002Fbcur\u002F2024.png", "软科中国大学排名于2015年首次发布,多年来以专业、客观、透明的优势赢得了高等教育领域内外的广泛关注和认可,已经成为具有重要社会影响力和权威参考价值的中国大学排名领先品牌。软科中国大学排名以服务中国高等教育发展和进步为导向,采用数百项指标变量对中国大学进行全方位、分类别、监测式评价,向学生、家长和全社会提供及时、可靠、丰富的中国高校可比信息。", "学生、家长、高校管理人员、高教研究人员等", 2023, 2022, 2020, 2019, 2018, 2017, 2016, 2015, "logo\u002FindAnalysis\u002Fbcur.png", "中国大学排名", "国内", "大学"'
b1 = b.split(', ')
dict = {key: value for key, value in zip(a1, b1)}
# 对 data2 中的每个元素进行映射
new_data2 = []
for item in data2:
result_dict = item.groupdict()
for key, value in result_dict.items():
if key in ["type", "province", "ranking"]:
value = value.strip('"')
if value in dict:
result_dict[key] = dict[value]
new_data2.append(result_dict)
# 将 new_data2 赋值给 data2,实现永久改变
data2 = new_data2
# 现在无论在哪里输出 data2,都是映射后的结果
for item in data2:
print(item)
# 存储到文件里
with open('output.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = list(data2[0].keys()) if data2 else []
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for item in data2:
writer.writerow(item)
运行结果
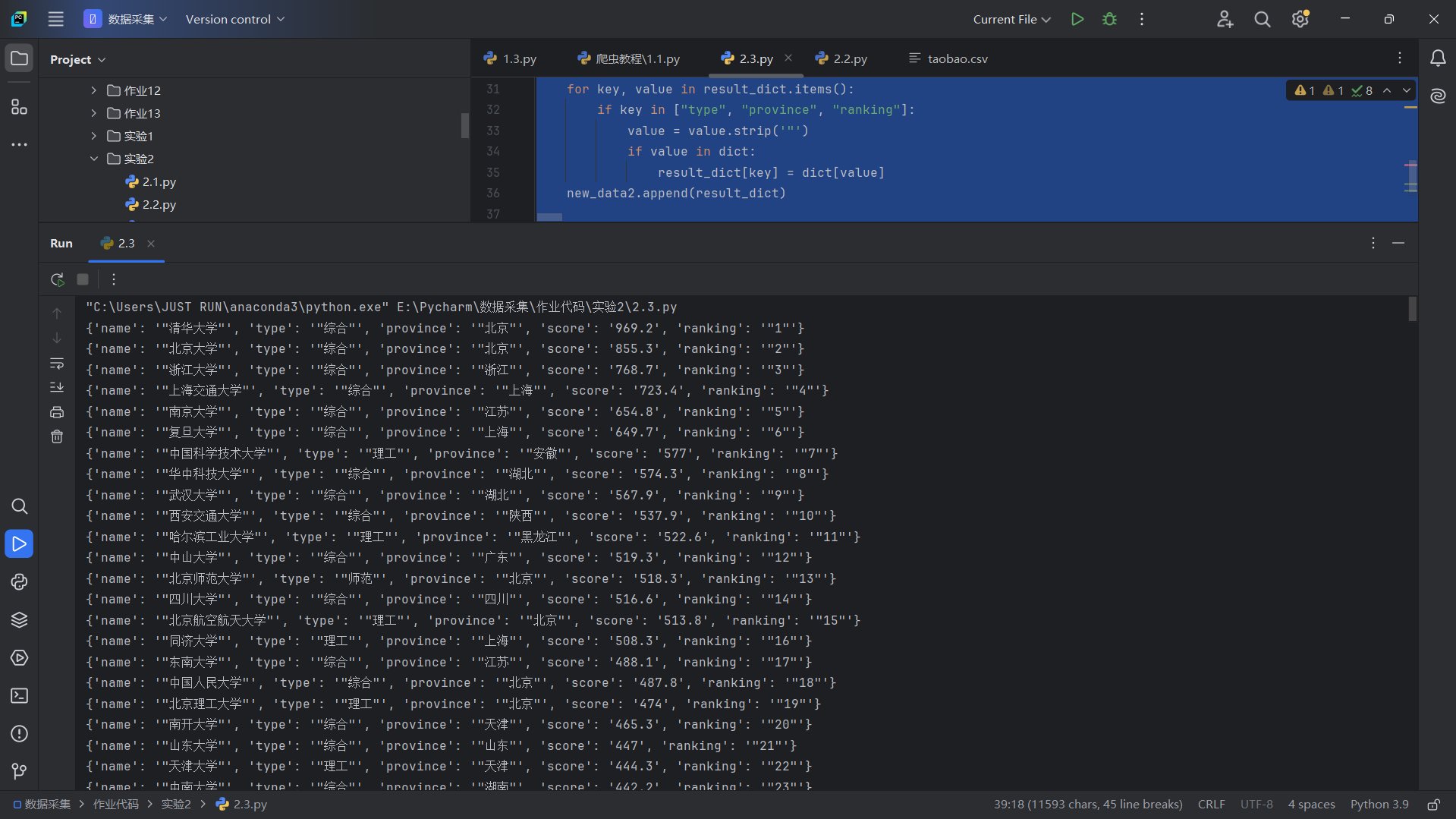
Gitee文件夹链接:https://gitee.com/liang-jinsheng-289668/project/tree/master/作业2/2.3
二、作业心得
完成这个作业,我懂得了有些数据并不能直接爬取使用,而是要通过解析数据文件对其进行解密,我也懂得了一个关于如何解密信息的套路,这让我能够更好地面对那些存在数据代指现象的网站进行数据爬取

