
数据采集与融合技术作业1
102202143 梁锦盛
1.大学排名信息爬取
一、作业代码与展示
import requests
from bs4 import BeautifulSoup
import bs4
# 获取网页内容
def getText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('爬取失败!')
return None
# 将获取得网页筛选想要的内容,并添加到一个列表中
def needList(ulist, html):
try:
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
data = [tds[0].string, tds[1].text.strip(), tds[2].text.strip(), tds[3].text.strip(), tds[4].string]
# 去除每个数据项中的多余空格和换行符
cleaned_data = [item.replace(' ', '').replace('\n', '') if isinstance(item, str) else item for item in data]
ulist.append(cleaned_data)
except:
print('网页解析失败!')
# 输出
import sys
def printList(ulist, num):
try:
tplt = " {:^15}\t{:^10}\t{:^20}\t{:^15}\t{:^10}"
sys.stdout.write(tplt.format(" 排名 ",'学校名称 ','省市','类型','总分', chr(12288)))
print("")
for i in range(num):
u = ulist[i]
# 对每个数据项再次进行处理,确保没有多余空格和换行符
formatted_data = [item.replace(' ', '').replace('\n', '') if isinstance(item, str) else item for item in u]
line = tplt.format(*formatted_data)
print(line)
except:
print('输出发生问题!')
# 主函数
def main():
ulist =[]
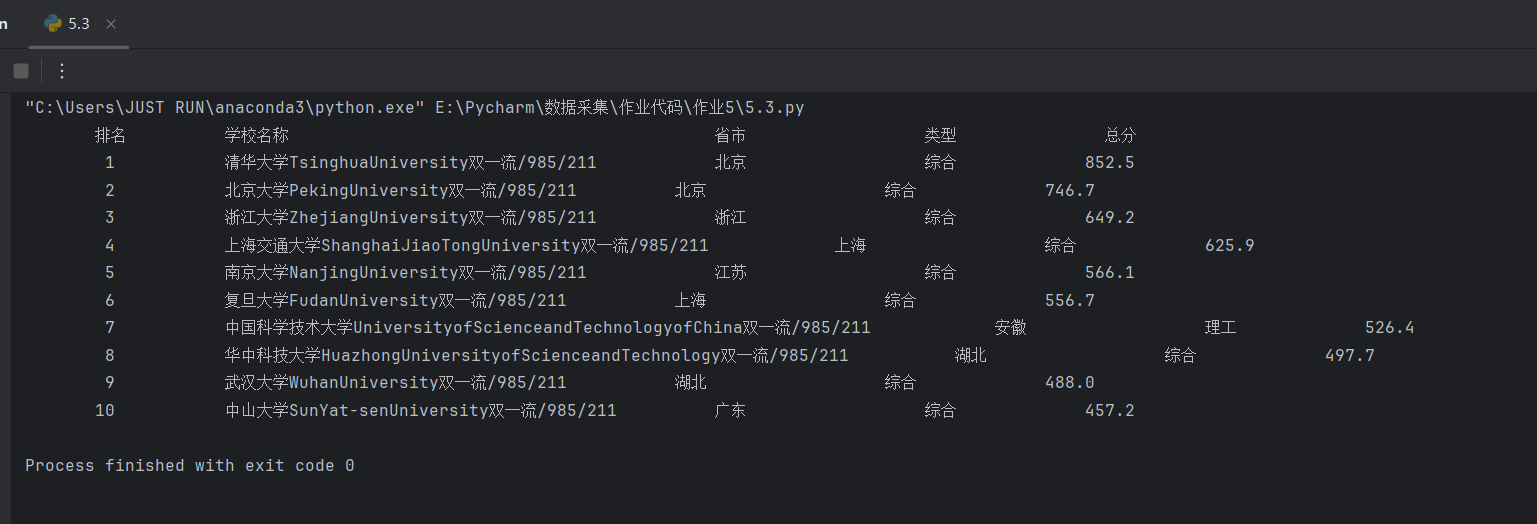
url ='http://www.shanghairanking.cn/rankings/bcur/2020'
html = getText(url)
needList(ulist, html)
printList(ulist, 10)
main()
二、作业心得
完成这个作业,我初步对requests和BeautifulSoup有了理解,不过在对爬取的信息输出格式的控制上仍缺经验。
2.商城商品比价
一、作业代码与展示
import requests
from bs4 import BeautifulSoup
import json
import pprint
import csv
import time
import random
import re
fieldnames = ['标题', '价格']
# 指定输出文件名称
filename = 'taobao.csv'
# 创建一个 DictWriter 对象
with open(filename, 'w', newline='', encoding='ANSI') as csvfile:
csvwriter = csv.DictWriter(csvfile, fieldnames=fieldnames)
# 写入表头
csvwriter.writeheader()
#淘宝搜索书包的URL
for page in range(1,2):
print("="*10+f'正在爬取第{page}页'+'='*10)
url = 'https://h5api.m.taobao.com/h5/mtop.relationrecommend.wirelessrecommend.recommend/2.0/?jsv=2.7.2&appKey=12574478&t=1727363862134&sign=ac4ef71a87891f622de7d7b801b0d452&api=mtop.relationrecommend.wirelessrecommend.recommend&v=2.0&type=jsonp&dataType=jsonp&callback=mtopjsonp9&data=%7B%22appId%22%3A%2243356%22%2C%22params%22%3A%22%7B%5C%22device%5C%22%3A%5C%22HMA-AL00%5C%22%2C%5C%22isBeta%5C%22%3A%5C%22false%5C%22%2C%5C%22grayHair%5C%22%3A%5C%22false%5C%22%2C%5C%22from%5C%22%3A%5C%22nt_history%5C%22%2C%5C%22brand%5C%22%3A%5C%22HUAWEI%5C%22%2C%5C%22info%5C%22%3A%5C%22wifi%5C%22%2C%5C%22index%5C%22%3A%5C%224%5C%22%2C%5C%22rainbow%5C%22%3A%5C%22%5C%22%2C%5C%22schemaType%5C%22%3A%5C%22auction%5C%22%2C%5C%22elderHome%5C%22%3A%5C%22false%5C%22%2C%5C%22isEnterSrpSearch%5C%22%3A%5C%22true%5C%22%2C%5C%22newSearch%5C%22%3A%5C%22false%5C%22%2C%5C%22network%5C%22%3A%5C%22wifi%5C%22%2C%5C%22subtype%5C%22%3A%5C%22%5C%22%2C%5C%22hasPreposeFilter%5C%22%3A%5C%22false%5C%22%2C%5C%22prepositionVersion%5C%22%3A%5C%22v2%5C%22%2C%5C%22client_os%5C%22%3A%5C%22Android%5C%22%2C%5C%22gpsEnabled%5C%22%3A%5C%22false%5C%22%2C%5C%22searchDoorFrom%5C%22%3A%5C%22srp%5C%22%2C%5C%22debug_rerankNewOpenCard%5C%22%3A%5C%22false%5C%22%2C%5C%22homePageVersion%5C%22%3A%5C%22v7%5C%22%2C%5C%22searchElderHomeOpen%5C%22%3A%5C%22false%5C%22%2C%5C%22search_action%5C%22%3A%5C%22initiative%5C%22%2C%5C%22sugg%5C%22%3A%5C%22_4_1%5C%22%2C%5C%22sversion%5C%22%3A%5C%2213.6%5C%22%2C%5C%22style%5C%22%3A%5C%22list%5C%22%2C%5C%22ttid%5C%22%3A%5C%22600000%40taobao_pc_10.7.0%5C%22%2C%5C%22needTabs%5C%22%3A%5C%22true%5C%22%2C%5C%22areaCode%5C%22%3A%5C%22CN%5C%22%2C%5C%22vm%5C%22%3A%5C%22nw%5C%22%2C%5C%22countryNum%5C%22%3A%5C%22156%5C%22%2C%5C%22m%5C%22%3A%5C%22pc_sem%5C%22%2C%5C%22page%5C%22%3A1%2C%5C%22n%5C%22%3A48%2C%5C%22q%5C%22%3A%5C%22%25E4%25B9%25A6%25E5%258C%2585%5C%22%2C%5C%22qSource%5C%22%3A%5C%22manual%5C%22%2C%5C%22pageSource%5C%22%3A%5C%22%5C%22%2C%5C%22tab%5C%22%3A%5C%22all%5C%22%2C%5C%22pageSize%5C%22%3A48%2C%5C%22totalPage%5C%22%3A100%2C%5C%22totalResults%5C%22%3A4800%2C%5C%22sourceS%5C%22%3A%5C%220%5C%22%2C%5C%22sort%5C%22%3A%5C%22_coefp%5C%22%2C%5C%22bcoffset%5C%22%3A%5C%22%5C%22%2C%5C%22ntoffset%5C%22%3A%5C%22%5C%22%2C%5C%22filterTag%5C%22%3A%5C%22%5C%22%2C%5C%22service%5C%22%3A%5C%22%5C%22%2C%5C%22prop%5C%22%3A%5C%22%5C%22%2C%5C%22loc%5C%22%3A%5C%22%5C%22%2C%5C%22start_price%5C%22%3Anull%2C%5C%22end_price%5C%22%3Anull%2C%5C%22startPrice%5C%22%3Anull%2C%5C%22endPrice%5C%22%3Anull%2C%5C%22itemIds%5C%22%3Anull%2C%5C%22p4pIds%5C%22%3Anull%2C%5C%22categoryp%5C%22%3A%5C%22%5C%22%2C%5C%22myCNA%5C%22%3A%5C%227quYG%2FCF2RoCAT3xxLm77uxZ%5C%22%2C%5C%22clk1%5C%22%3A%5C%22421763ad2ecf08612cf79b39becb6d6b%5C%22%2C%5C%22refpid%5C%22%3A%5C%22mm_2898300158_3078300397_115665800437%5C%22%7D%22%7D'
time.sleep(random.randint(1,4))
# 发送请求
headers = {
'cookie':'miid=998888041877421813; cna=7quYG/CF2RoCAT3xxLm77uxZ; cookie2=1a33978218effe37b4d1fe4510c5285a; t=9168da25855c14321e355d96603403b2; _tb_token_=eedb5f1e65e61; mtop_partitioned_detect=1; _m_h5_tk=07283c35a49ba0da148f0df2222df148_1727371394361; _m_h5_tk_enc=7c7b867d142ec6c14459643a6e67c243; thw=cn; xlly_s=1; tfstk=g5LEBBwDL23U_G0f11QPggYjsMQdlwDXxU65ZQAlO9XhOL_y4KB_PXQI2aJPQLBCAwXQzUWMibUI9DIlUpQh2H65dT7ywKlshqgX9BQRSxMjl9MqSFbRE4_olvxmIeMjhqgsx5brLxt51JZQ_s5cr6jlx1cNOs_ltMXn_OfPMu2HEacZ__5lZTflq1fGi_QlELjn_CcY-TXb7sSnGnaVuZhdpMWDtOz26E5hYkdhQz4k7HIFnr6arzYNTCEPPoUqVtxAdi6yIVaFzCfyQitE3yJyZIKlbUynOKvM4Lf9XYrP33ABD3jZt2AN89SNTMF34w-kpUSpY7hvswv9DtInXACwREsPHGyiKCONKi-ydAUldnRMQiT_Cr_DDd8PmZjyl8CGxKTJY8qPx1CNhflaNqOPvx6RQeq82MKO_tGK9uERx1CNhfla2uIpX1Wj9XC..; isg=BNjYegzlCk41AybKuEHgTWEvqQZqwTxLvxB56xLJDpPGrXmXstC027SL5eWdu_Qj',
'Referer': 'https://s.taobao.com/search?_input_charset=utf-8&commend=all&ie=utf8&initiative_id=tbindexz_20170306&localImgKey=&page=1&q=%E4%B9%A6%E5%8C%85&search_type=item&source=suggest&sourceId=tb.index&spm=a21bo.jianhua%2Fa.201856.d13&ssid=s5-e&suggest_query=&tab=all&wq=',
'Sec - Ch - Ua': '"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
'Sec - Ch - Ua - Mobile': '?0',
'Sec - Ch - Ua - Platform': '"Windows"',
'Sec - Fetch - Dest': 'script',
'Sec - Fetch - Mode': 'no-cors',
'Sec - Fetch - Site': 'same-site',
'User - Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
}
res = requests.get(url=url,headers=headers)
#价格
price = r'"SALEPRICE":"(\d+\.\d+)"'
pri_matches = re.findall(price, res.text)
# 名称
tit = r'"ADGTITLE":"(.*?)(?="|\\n)'
tit_matches = re.findall(tit, res.text)
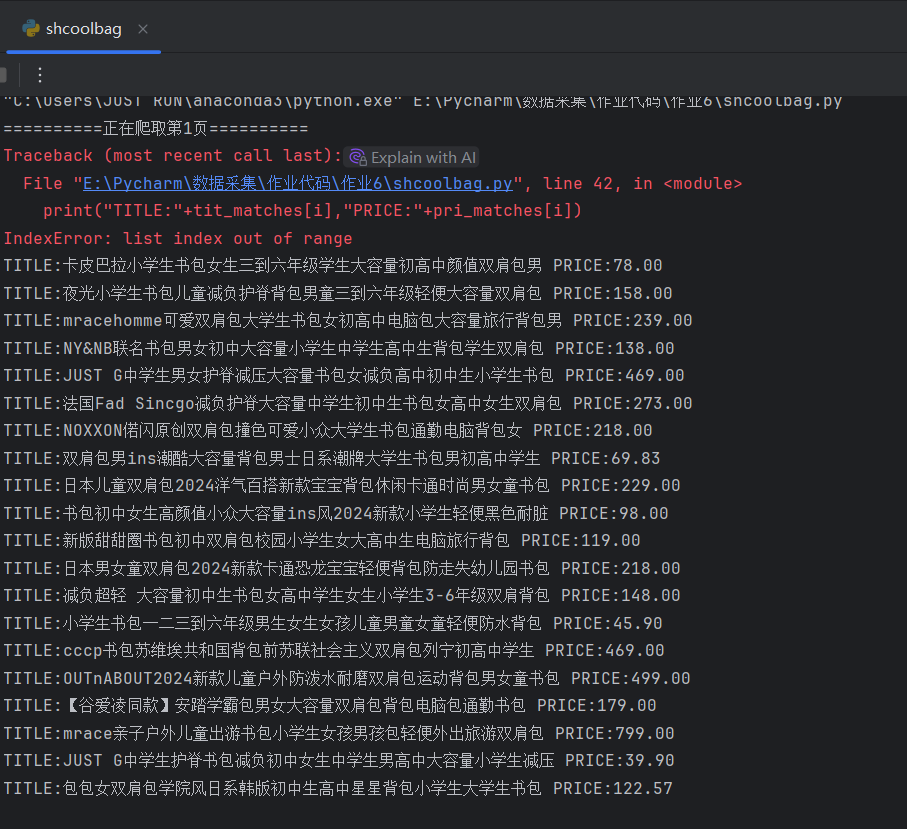
for i in range(21):
print("TITLE:"+tit_matches[i],"PRICE:"+pri_matches[i])
dict = {'标题':tit_matches[i],
'价格':pri_matches[i]
}
csvwriter.writerow(dict)
二、作业心得
完成这个作业让我对requests和re库的组合使用有了更深入的理解,开始尝试正则表达式来提取商品名称和价格的过程中还不太熟练,需要对网页结构有一定的分析能力,以构建准确的正则表达式模式。通过requests和re库的组合使用,对一些网页结构比较简单的信息的爬取也更方便快捷了。
3.网页图片爬取
一、作业代码与展示
import requests
import os
# 图片URL列表
image_urls = [
'https://news.fzu.edu.cn/__local/B/08/76/0025990608969DE31CE91B846DD_233367A9_30CC6.jpg',
'https://news.fzu.edu.cn/__local/3/1A/40/BD5C51D961F315A61C47FD0AEC9_70BA2916_3A880.jpg',
'https://news.fzu.edu.cn/images/footer_bg.jpg',
'https://news.fzu.edu.cn/__local/F/57/F8/F1AFE8DBDD62EFBDAC1F528E94F_A7EEE1A3_3E46DD.jpg',
'https://news.fzu.edu.cn/__local/E/7B/87/D7011C3D0D6BF10E4C0379DFB4D_FAE910D0_19083D.jpg',
'https://news.fzu.edu.cn/__local/1/7F/D7/E7DE91F8E67D7157427FE7C14FC_758B816C_4B21E.jpeg',
# 把所有Request URL都放在这个列表里
]
# 创建一个文件夹来保存下载的图片
if not os.path.exists('images'):
os.makedirs('images')
# 下载每一张图片
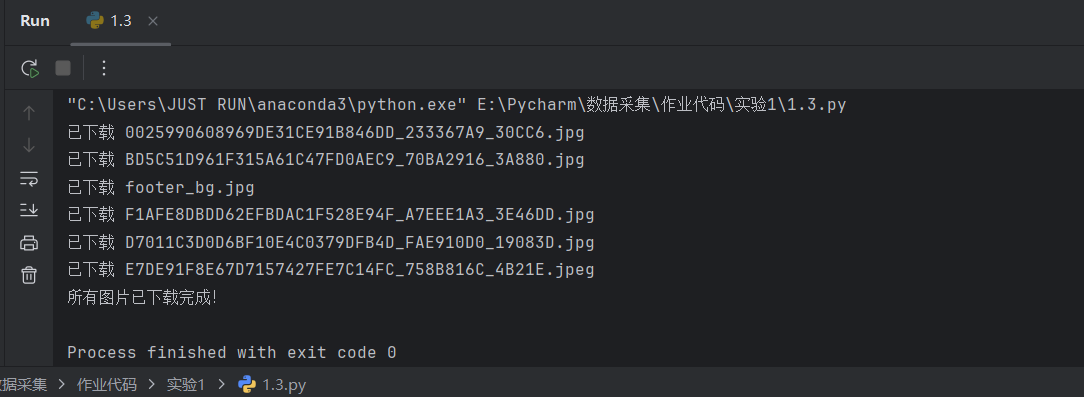
for url in image_urls:
# 获取图片的文件名
file_name = url.split('/')[-1]
# 请求图片数据
img_data = requests.get(url).content
# 保存图片
with open(f'images/{file_name}', 'wb') as img_file:
img_file.write(img_data)
print(f"已下载 {file_name}")
print("所有图片已下载完成!")
二、作业心得
完成这个作业,我更加明白网页是如何管理各种文件的,我们可以通过一些文件后缀检索到自己需要的信息,也学习了如何将一些爬取到的文件存储到对应的文件夹里。

