

es-v6版本
转:https://blog.csdn.net/weixin_43904316/article/details/109632736 docker容器安装elasticsearch:7.4.2
es可以更快的获得你想要搜索的数据,先对比一下和mysql的区别:
es中的索引就相当于一个数据库,而类型就是一张表,文档则表示一行数据,一列代表着属性。es在存储的时候则是以json的方式进行存储的。
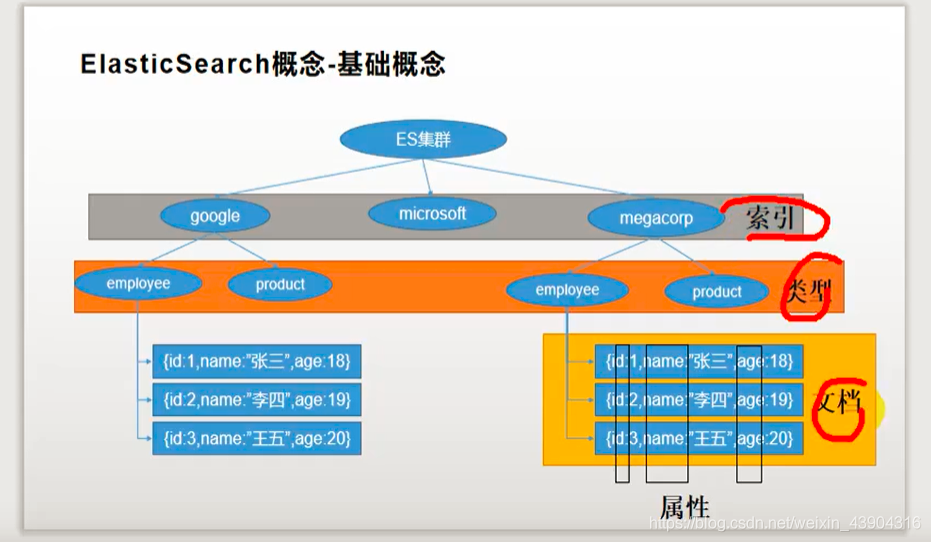
es之所以快是因为他维护了一张倒排索引表
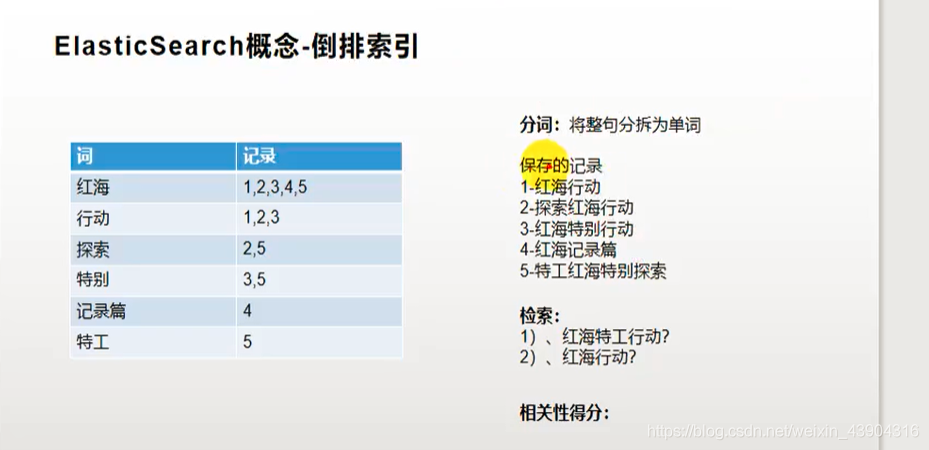
比如把以上5条记录保存到es中,就会维护一张倒排索引表。比如1:红海行动就会被拆分成红海和行动。红海和行动在倒排索引中分别记录着文档1。2:探索红海行动就会被拆分成探索,红海和行动。这样倒排索引中就会分别记录对应的文档2。当我们需要进行检索红海特工行动的时候就会去倒排索引中找到 第1,2,5行。然后看他们对应的文档是哪一个,然后根据相关性得分进行比较。这里3,5比较适合,但是3命中率更高。
安装请看:https://blog.csdn.net/weixin_43904316/article/details/109632736
文/朱季谦 转:https://www.cnblogs.com/zhujiqian/p/14981060.html
Elasticsearch的配置
Elasticsearch的配置比较重要有三个,分别是elasticsearch.yml,jvm.options,log4j2.properties,这些配置文件都默认放在/config/目录下。
- elasticsearch.yml:用于配置Elasticsearch基本信息,主要包括集群、节点、ip、端口等;
- jvm.options:配置Elasticsearch依赖的JVM信息,ES是Java写的,当然需要考虑堆大小的分配;
- log4j2.properties:用于配置Elasticsearch日志记录中的各个属性;
elasticsearch.yml关键参数
Elasticsearch是一个基于Lucene的搜索服务器。它提供一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,Elasticsearch是用Java语言开发的。
关于Elasticsearch系列笔记,主要从Elasticsearch的配置、核心组件、架构设计、使用语法这四个方面来记录学习;
本学习总结主要依赖《Elasticsearch实战与原理解析》一书的读书笔记,我把自己阅读过程当中整理的读书笔记做成了一张脑图,上传至了我的GitHub。

Elasticsearch的配置
Elasticsearch的配置比较重要有三个,分别是elasticsearch.yml,jvm.options,log4j2.properties,这些配置文件都默认放在/config/目录下。
- elasticsearch.yml:用于配置Elasticsearch基本信息,主要包括集群、节点、ip、端口等;
- jvm.options:配置Elasticsearch依赖的JVM信息,ES是Java写的,当然需要考虑堆大小的分配;
- log4j2.properties:用于配置Elasticsearch日志记录中的各个属性;
elasticsearch.yml关键参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | #集群名称,默认是elasticsearch,用于区分同一网段下的不同集群cluster.name: my-application#集群当中的节点名称,用于区分同一个集群下的不同节点node.name: node-1#存储index索引数据的路径,可以存储到多个路径,例如:path.data: /temp/data1,/temp/data2,/temp/data3,path.data: /temp/data#日志文件的存储路径path.logs: /temp/logs#当前节点的ip地址,允许通过外部服务器访问本地ES服务:network.host: 0.0.0.0#该节点有机会成为master节点node.master: true#该节点能够存储数据node.data: true#######################设置head插件能够访问es############设置可以跨域,默认为falsehttp.cors.enabled: true#支持所有域名访问http.cors.allow-origin: "*"#跨域允许设置的头信息,默认为X-Requested-With,Content-Type,Content-Lengthhttp.cors.allow-headers : X-Requested-With,Content-Type,Content-Length#端口http.port: 9250#设置集群主机列表,每个值应采用host:port,可实现主动发起ping集群主机信息discovery.zen.ping.unicast.hosts: ["host1","host2","host3"]#该参数表示只有足够的master候选节点时,才可以选举出一个master,该参数的值为master候选节点数量/2+1#例如:如果有3个master候选节点,100个数据节点。则quorum=3/2+1=2discovery.zen.minimum_master_nodes: 2#表示设置了节点与节点之间连接ping命令执行的超时时长。discovery.zen.fd.ping_timeout: 100sdiscovery.zen.ping.timeout: 100s#主动关闭多播模式discovery.zen.ping.multicast.enabled: false#默认90%,超过阈值后,所有索引都被修改为只读不可写状态cluster.routing.allocation.disk.watermark.flood_stage: 90%#默认90%,超过阈值后,索引的分片将不会被分配到该主机cluster.routing.allocation.disk.watermark.high: 90% |
elasticsearch.yml配置当中,discovery.zen相关的参数设置,主要是用来实现集群当中节点自动发现机制的,存在多播模式与单播模式。
- 多播模式:对某一个网络上的所有主机发送数据包。
- 单播模式:对特定的主机进行数据传送。
在Elasticsearch中,发现机制默认被配置为使用单播模式,以防止节点无意中加入集群。
jvm.options配置信息
Elasticsearch官方中文文档上介绍道:“你几乎可以不去调整 Java 虚拟机 (JVM) 参数,如何非要做的话,你最有可能去修改heap size。”
也就是说,这个配置文件里,一般只需要关注堆大小的设置即可,因为每一个运行环境服务器都不一样,可以根据服务器具体情况来调整jvm.options里的堆大小。
#最小堆的值 -Xms1024m #最大堆的值 -Xmx1024m #表示老年代占用75%时就会触发垃圾回收 -XX:CMSInitiatingOccupancyFraction=75
设置规则一般如下:
- 最小堆Xms与最大堆Xmx设置值相同,避免当堆大小不够时再进行动态调整出现不确定因素;
Elasticsearch性能调优与JVM性能调优类似,都是通过JVM参数来进行调整优化,至于如何能有效调整,后续我若在实践过程中涉及过,会补充这块的内容。
log4j2.properties配置信息
该配置是Elasticsearch日志记录中的各个属性设置,包括日志保存设置、日志保留天数、慢日志、日志滚动等。
比较需要关注的一条参数是:
#将日志滚动到路径后的数据里 appender.rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}-%d{yyyy-MM-dd}-%i.log.gz #使用基于时间的滚动策略 appender.rolling.policies.time.type = TimeBasedTriggeringPolicy # 每天滚动一次日志 appender.rolling.policies.time.interval = 1 # 日志文件每达到 1GB 大小进行一次滚动 appender.rolling.policies.size.size = 1GB
所谓滚动日志,就是将当天的日志整理成一个以某种各种命名(例如时间)的文件,可存储历史的日志文件记录。我们在服务器的log目录下,经常看到类似的历史日志被打包成压缩包形式,这类被打包成压缩包的历史日志文件,即为回滚日志。我们经常在mysql里听到过日志回滚,其实,回滚的,即是这些原来被回滚存放在log目录下的日志文件。
discovery.zen.minimum_master_nodes深度解析
discovery.zen.minimum_master_nodes对集群的稳定性至关重要,防止脑裂的出现。
脑裂:
如果网络的故障导致一个集群被划分成两片,每片都有多个node,以及一个master。因为master是维护集群状态,以及shard的分配。如果出现了两个master,可能导致数据破损。
discovery.zen.minimum_master_nodes的作用是只有足够的master候选节点时,才可以选举出一个master。该参数必须设置为集群中master候选节点的quorum数量。
quorum的算法=master候选节点数量/2+1
举例:
1、如果有10个节点,都是data node,也是master的候选节点。则quorum=10/2+1=6
2、如果有3个master候选节点,100个数据节点。则quorum=3/2+1=2
3、如果有2个节点,都是data node,也是master的候选节点。则quorum=2/2+1=2(有问题)
如果其中一个节点挂了,那么master的候选节点只有一个,无法满足quorum数量。即无法选举出master。此时只能将quorum设置成1,但是设置为1有可能出现脑裂。
总结:一般es集群的节点至少要有3个,quorum设置为2
使用例2的场景说明quorum是如何防止脑裂
假设集群中3个节点有一个节点与其他节点无法通信,
1、如果master是单独的节点,另外2个节点是master候选节点。那么此时单独的master节点因为没有指定数量的候选master node在自己当前所在的集群里。因此会取消当前的master角色,尝试重新选举(无法选举成功)
另外一个网络区域内的node因为无法连接到master,就会发起重新选举,有两个候选节点,满足quorum,成功选举出一个master。
2、如果master和一个node在一个网络区域(A),另一个node单独在一个网络区域(B)。
B区域只有一个node,因为连不上master,会尝试发起选举,但不满足quorum,无法选举
A区域master继续工作,当前网络也满足quorum,不发起选举。
discovery.zen.minimum_master_nodes除了在配置文件设置,也可以动态设置
PUT /_cluster/settings
{
"persistent":{
"discovery.zen.minimum_master_nodes":2
}
}
Elasticsearch节点类型(数据节点、候选节点)、主节点选举过程
节点类型、主节点选举过程
节点类型(数据节点、候选节点)
主节点选举过程(重要!!!)
节点类型(数据节点、候选节点)
在Elasticsearch中,每个节点可以有多个角色,节点既可以是候选主节点,也可以是数据节点
节点的角色配置在配置文件/config/elasticsearch.yml中设置即可,配置参数如下所示

在Elasticsearch中,默认都为true
数据节点 负责 数据的存储相关的操作,如对数据进行增、删、改、查和聚合等
数据节点 往往 对服务器的配置要求比较高,特别是对CPU、内存和I/O的需求很大
数据节点 梳理 通常随着 集群的扩大而弹性增加,以便保持Elasticsearch服务的高性能和高可用
候选主节点 是 被选举为主节点 的 节点
在集群中,只有候选主节点 才有 选举权和被选举权,其他节点不参与选举工作
一旦候选主节点 被选举为 主节点,则主节点 就要负责 创建索引、删除索引、追踪集群中节点的状态,以及 跟踪 哪些节点 是 群集的一部分,并决定 将哪些分片 分配给 相关的节点等
主节点选举过程(重要!!!)
配置单播模式后,集群构建及主节点选举过程如下:
节点启动后 先执行 ping命令(这里提及的ping命令不是Linux环境用的ping命令,而是Elasticsearch的一个RPC命令),如果discovery.zen.ping.unicast.hosts有设置,则ping设置中的host;否则尝试ping localhost的几个端口
ping命令的返回结果 会包含 该节点的基本信息 及 该节点认为的主节点
在选举开始时,主节点 先从 各节点认为的master中选,选举规则比较简单,即按照ID的字典序排序,取第一个
如果各节点 都没有认为的master,则从所有节点中选择,规则同上
需要注意的是,这里有个 集群中 节点梳理 最小值限制条件,即discovery.zen.minimum_master_nodes
如果节点数达不到最小值的限制,则循环上述过程,直到节点数超过最小限制值,才可以开始选举
最后选举出一个主节点,如果只有一个本地节点,则主节点就是它自己
如果当前节点是主节点,则开始等待节点数达到minimum_master_nodes,再提供服务
如果当前节点不是主节点,则尝试加入主节点所在集群
————————————————
版权声明:本文为CSDN博主「星光之子0317」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_38405646/article/details/121183990
##curl http://127.0.0.1:9200/_cat (查看候选节点等信息)
####curl http://127.0.0.1:9200/_cat/nodesv
##查看es健康状态
##curl http://10.212.2.94:19201/_cluster/health?pretty
##查看索引
##curl http://10.212.2.94:19201/_cat/indices\?v
##删除索引
##curl -XDELETE 'http://10.212.2.94:19201/dop_message_20211130'(删除多个索引用逗号隔开即可,慎用通配符*删除索引)
##关闭索引只读状态
##curl -XPUT -H "Content-Type: application/json" http://10.212.2.94:19201/_all/_settings -d '{"index.blocks.read_only_allow_delete": null}'


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2017-11-23 架构设计:负载均衡层设计方案(1)——负载场景和解决方式