ClusterIP工作原理和请求链路
clusterip跟kube-apiserver有什么关系之问,此问来自我的brother。
答:跟kube-apiserver没有什么关系。
转自: https://blog.csdn.net/soshow2011/article/details/117565125
前言
Goolgle百度了半天,社区都没发现有cluster ip深入原理的讲解。小结了cluster ip的原理和访问链路, 简单写个博客希望对社区的小伙伴有用。
K8S从入门到欣赏,必须感谢几位好朋友:
感谢Hao泉、Gui源、Zhi君的经常性技术支持和讲解。 感谢社区各个兴趣群大佬的指点和吐槽.
Cluster IP 基础
Service主要分为 ClusterIP/NodePort/Loadbalancer三种常见访问方式, 其中后两者非常相似。理解了ClusterIP工作原理后基本Service你就能非常容易理解, 也会十分有利于运维日常的排错。基础可参考这里,本文不作过多基础说明: https://kubernetes.io/zh/docs/concepts/services-networking/service/#proxy-mode-ipvs
先说结论
Cluster IP 访问链路(下文会有详细说明)
kube-proxy:有点小惊讶,一直以为kube-proxy (ipvs) 是处理 in入流量的, 没想到居然是处理out出流量的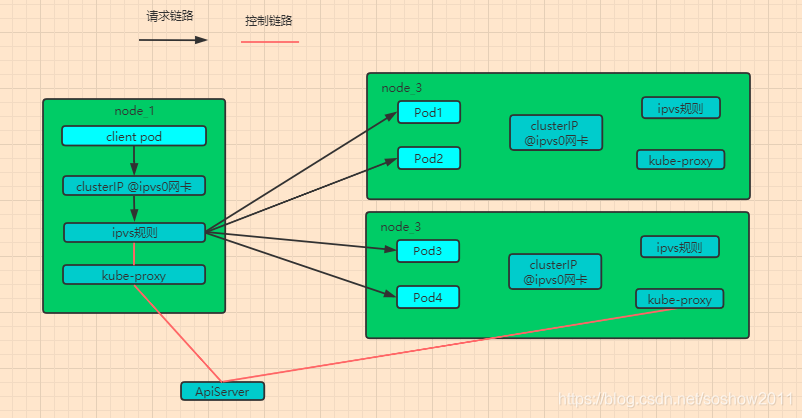
K8S独一无二的LB架构设计
常规的LB链路:client -> LB -> server
K8S的LB链路: (client -> LB) -> server # Client和LB合并在一个node上
常规Client和LB是分开,但K8S设计的ipvs规则很有想法(Client和LB合并在一个node上), 直接把ipvs规则放在client node上。
client的请求还没有出node, 发现本地网卡ipvs0上就有cluster ip,且命中了本地的ipvs规则,根据ipvs转发到backend pod。
- 每台Node都配置了ClusterIP(如CIP_1)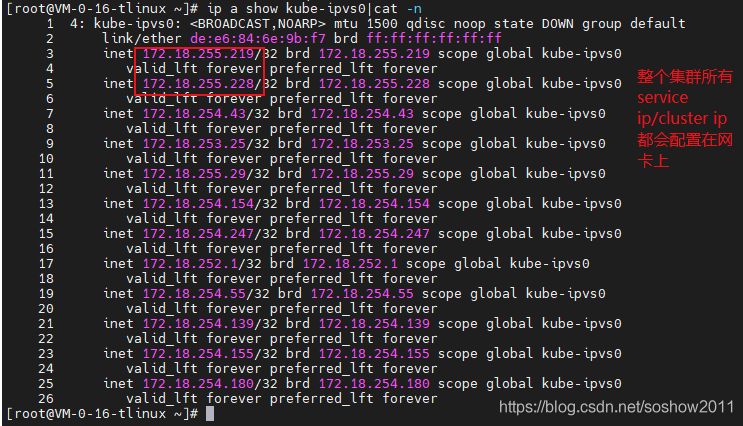
- 每台Node都配置了IPVS规则(如CIP_1对应4个pod_{1,2,3,4})
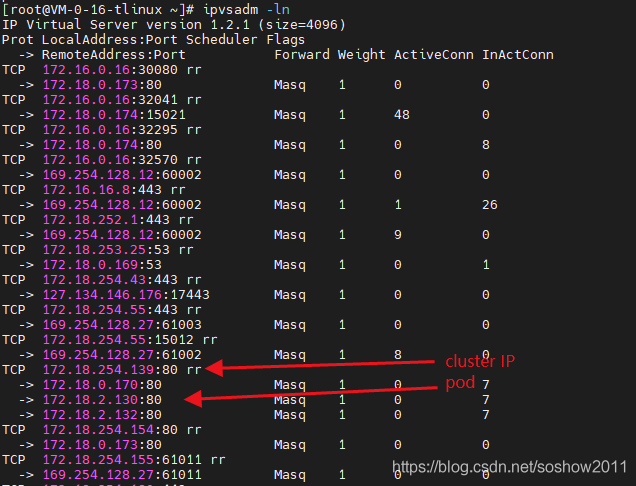
小结:
t1) client pod@node1发起请求cluster ip (172.18.254.139)
t2) 请求还没出node1,发现172.18.254.139就在node1 ipvs0网卡,且匹配到了ipvs规则返现后端了3个pod
t3) 根据ipvs规则,转发给了pod1(服务端)172.18.0.170
t4) 第二个请求,重复步骤t1-t3, 匹配到ipvs规则后转发给了pod2 172.18.2.130
t5) 第n个请求,如此类推,轮训ipvs下各个后端server pod
优点:
传统架构: 假设1000个client,中间经LB设备,转发到后端server。 这LB的负载就会很高
K8S架构:去中心化, 将ipvs规则写到集群内所有的node中, 1000个client都自带ipvs规则, client自己做负载均衡连接后端server,中间不经过LB单点设备。解放了LB,可理解为直连
缺点:
service越多,node上的clusterIP就会越多,大厂通常都有500-数千个service, node上clusterIP会非常多。
nodePort 模式:
原理跟Cluster IP模式非常类似,都是node上绑定了全部svc的ipvs规则.
验证
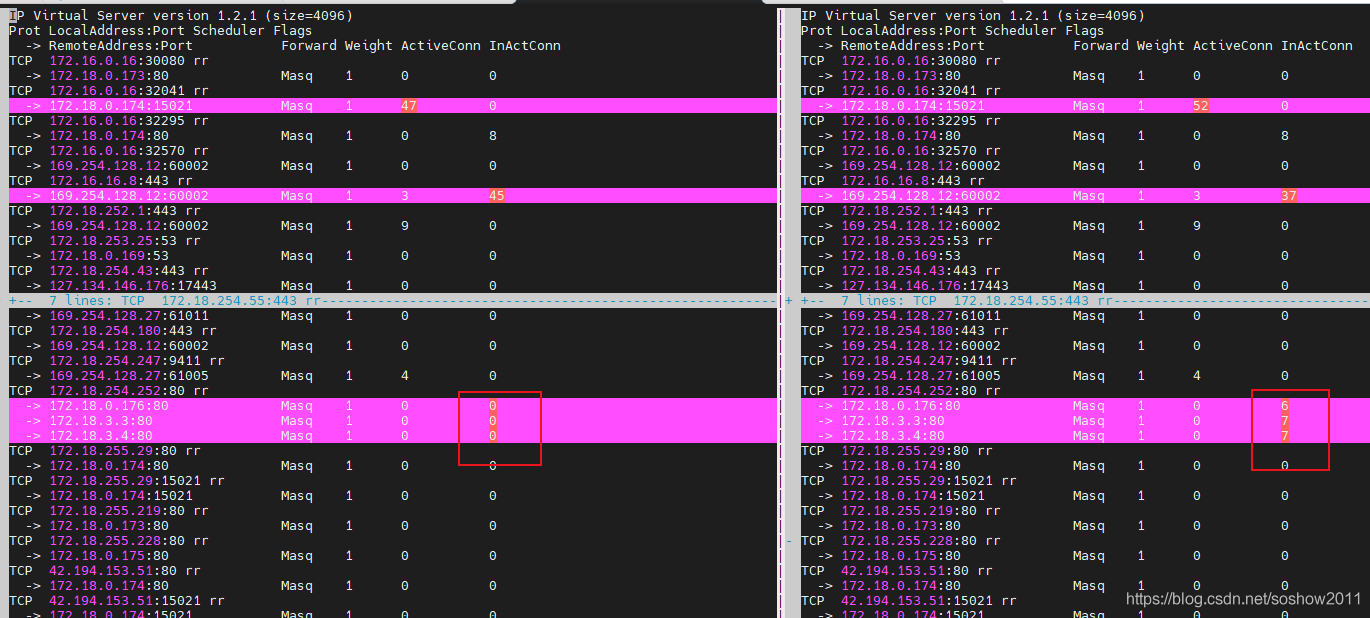
client 发起请求cluster IP (172.18.254.252), 172.18.254.252对应backend部分pod在node1上,部分pod在node1上
图2: 发起请求后, 全部匹配到node1上的ipvs规则, 说明了请求还没出node1就被负载均衡,分配到各个后端了。 而非请求到了node2之后才被node2 ipvs规则匹配.
图1:发起20个请求
图1
图2 匹配到client所在node1的ipvs规则