[Java复习] Spring Cloud - 服务注册中心 Eureka
Dubbo用ZooKeeper, Spring Cloud用Eureka作为各种的注册中心,为什么要这样设计?
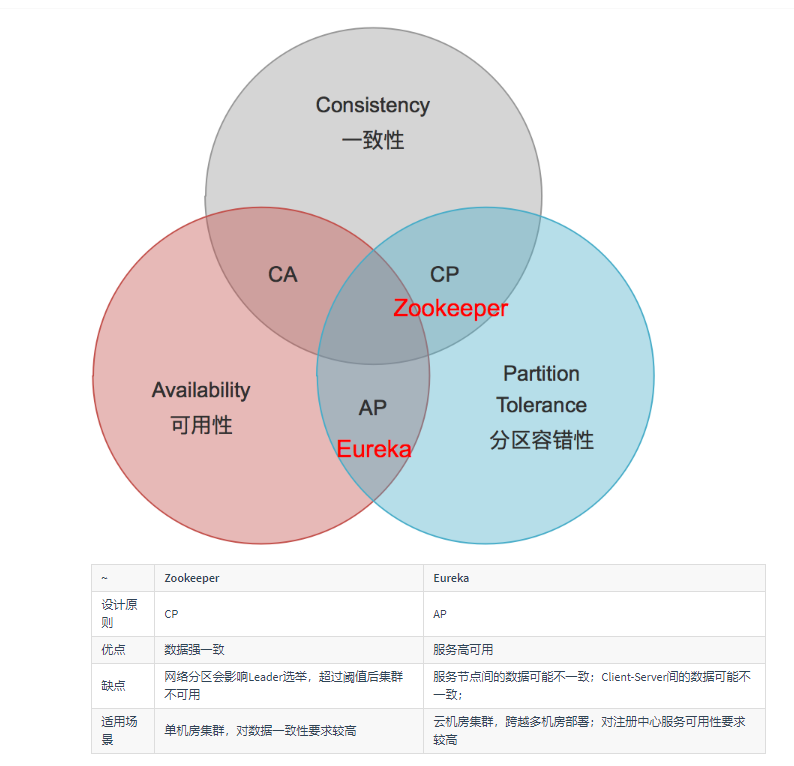
著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)。
由于分区容错性在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。在此Zookeeper保证的是CP, 而Eureka则是AP。
Zookeeper保证CP
Eureka保证AP
Zookeeper的设计理念就是分布式协调服务,保证数据(配置数据,状态数据)在多个服务系统之间保证一致性,这也不难看出Zookeeper是属于CP特性(Zookeeper的核心算法是Zab,保证分布式系统下,数据如何在多个服务之间保证数据同步)。Eureka是吸取Zookeeper问题的经验,先保证可用性。
Zookeeper作为服务发现的问题:
对于服务发现而言,就是返回了包含不及时的信息结果也比什么都不返回要好!
宁可返回某个服务5分钟之前在哪几个服务上可用的信息,也不能因为暂时的网络故障而找不到可用的服务器而不返回结果。
Zookeeper中,如果在同一个网络分区(partition)的节点数(nodes)数达不到Zookeeper选取leader节点的法定人数时,它们会从zookeeper中断开,同时也就不能提供服务发现了。
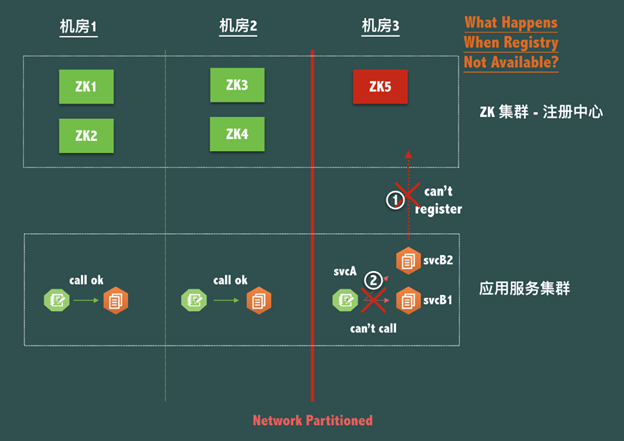
ZooKeeper三机房容灾5节点部署结构 (即2-2-1结构)
当同机房的ZK注册中心不可用,应用服务svcB无法注册到同机房ZK,就会访问ZK集群的其他节点,上图由于出现了网络分区故障,机房3无法与其他机房通信,所以svcB不能注册到任何ZK上,而且应用服务svcA也无法访问任何ZK,无法调用svcB;此时,当机房3出现网络分区(Network Partitioned)的时候,即机房3在网络上成了孤岛,我们知道虽然整体 ZooKeeper 服务是可用的,但是机房3的节点ZK5是不可写的,因为联系不上 Leader。
因为机房3节点ZK5不可写,这时候机房3的应用服务 svcB 是不可以新部署,重新启动,扩容或者缩容的,但是站在网络和服务调用的角度看,机房3的 svcA 虽然无法调用机房1和机房2的 svcB,但是与机房3的svcB之间的网络明明是 OK 的啊,为什么不让我调用本机房的服务?
现在因为注册中心自身为了保脑裂(P)下的数据一致性(C)而放弃了可用性,导致了同机房的服务之间出现了无法调用,这是绝对不允许的!可以说在实践中,注册中心不能因为自身的任何原因破坏服务之间本身的可连通性。
Eureka原理?Eureka对等怎么同步?路由策略?
分布式系统数据在多个副本之间的复制方式主要有:1. 主从复制(Master-Slave) 2. 对等复制(Peer to Peer)
Eureka数据同步方式: P2P
同步过程:
Eureka Server 本身依赖了 Eureka Client,也就是每个 Eureka Server 是作为其他 Eureka Server 的 Client。
Eureka Server 启动后,会通过 Eureka Client 请求其他 Eureka Server 节点中的一个节点,获取注册的服务信息,然后复制到其他 peer 节点。
Eureka Server 每当自己的信息变更后,例如 Client 向自己发起注册、续约、注销请求, 就会把自己的最新信息通知给其他 Eureka Server,保持数据同步。
怎么解决数据同步死循环?
Eureka Server 在执行复制操作的时候,使用 HEADER_REPLICATION 这个 http header 来区分普通应用实例的正常请求,说明这是一个复制请求,这样其他 peer 节点收到请求时,就不会再对其进行复制操作,从而避免死循环。
具体实现方式其实很简单,就是接收到Service Provider请求的Eureka Server,把请求再次转发到其它的Eureka Server,调用同样的接口,传入同样的参数,除了会在header中标记isReplication=true,从而避免重复的replicate。
怎么解决数据冲突?serverA向serverB发起同步请求,如果A数据比B数据旧,不可能接受,B如何知道A数据旧,A又应该怎么解决?
数据的新旧一般是通过版本号来定义的,Eureka 是通过 lastDirtyTimestamp 这个类似版本号的属性来实现的,表示此服务实例最近一次变更时间。
比如A向B复制数据,数据冲突有2种情况:
(1)A 的数据比 B 的新,B 返回 404,A 重新把这个应用实例注册到 B。
(2)A 的数据比 B 的旧,B 返回 409,要求 A 同步 B 的数据。
hearbeat心跳机制:
即续约操作,来进行数据的最终修复,因为节点间的复制可能会出错,通过心跳就可以发现错误,进行弥补。
例如发现某个应用实例数据与某个server不一致,则server放回404,实例重新注册即可。

Eureka数据存储结构
Eureka 的数据存储分了两层:数据存储层和缓存层。
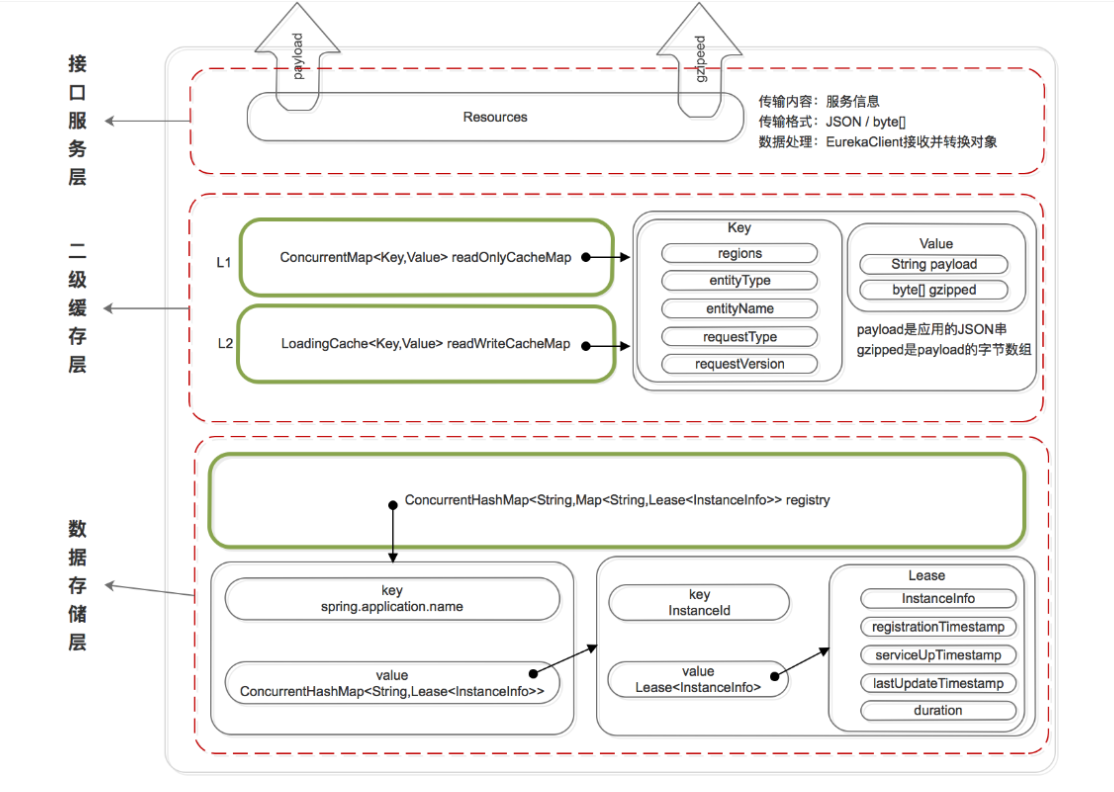
Eureka Client 在拉取服务信息时,先从缓存层获取(相当于 Redis),如果获取不到,先把数据存储层的数据加载到缓存中(相当于 Mysql),再从缓存中获取。值得注意的是,数据存储层的数据结构是服务信息,而缓存中保存的是经过处理加工过的、可以直接传输到 Eureka Client 的数据结构。
数据存储层:
因为 rigistry 本质上是一个双层的 ConcurrentHashMap,存储在内存中的,所以是存储层不是持久层。
第一层的 key 是spring.application.name(应用名),value 是第二层 ConcurrentHashMap;
第二层 ConcurrentHashMap 的 key 是服务的 InstanceId(实例id),value 是 Lease 对象;
Lease 对象包含了服务详情和服务治理相关的属性。
缓存层:
Eureka 实现了二级缓存来保存即将要对外传输的服务信息,数据结构完全相同。
一级缓存:ConcurrentHashMap<Key,Value> readOnlyCacheMap,本质上是 HashMap,无过期时间,保存服务信息的对外输出数据结构。
二级缓存:Loading<Key,Value> readWriteCacheMap,本质上是 guava 的缓存,包含失效机制,保存服务信息的对外输出数据结构。
缓存更新机制:
更新机制包含删除和加载两个部分,上图黑色箭头表示删除缓存的动作,绿色表示加载或触发加载的动作。
删除二级缓存:
Eureka Client 发送 register、renew 和 cancel 请求并更新 registry 注册表之后,删除二级缓存;
Eureka Server 自身的 Evict Task 剔除服务后,删除二级缓存;
二级缓存本身设置了 guava 的失效机制,隔一段时间后自己自动失效;
加载二级缓存:
Eureka Client 发送 getRegistry 请求后,如果二级缓存中没有,就触发 guava 的 load,即从 registry 中获取原始服务信息后进行处理加工,再加载到二级缓存中。
Eureka Server 更新一级缓存的时候,如果二级缓存没有数据,也会触发 guava 的 load。
更新一级缓存:
Eureka Server 内置了一个 TimerTask,定时将二级缓存中的数据同步到一级缓存(这个动作包括了删除和加载)。
服务注册机制:
服务提供者、服务消费者、以及服务注册中心自己,启动后都会向注册中心注册服务(如果配置了注册)。
注册中心服务接收到register请求后:
1. 保存服务信息,将服务信息保存到registry中;
2. 更新队列,将此事件添加到更新队列中,供Eureka Client增量同步服务信息使用。
3. 清空二级缓存,即readWriteCacheMap,用于保证数据的一致性。
4. 更新阈值,供剔除服务使用。
5. 同步服务信息,将此事件同步至其他的Eureka Server节点。
服务续约机制:
服务注册后,要定时(默认30S,可自己配置)向注册中心发送续约请求,告诉注册中心“我还活着”,即续约。
注册中心收到续约请求后:
1.更新服务对象的最近续约时间,即Lease对象的lastUpdateTimestamp;
2. 同步服务信息,将此事件同步至其他的Eureka Server节点。
服务注销机制:
服务正常停止之前会向注册中心发送注销请求,告诉注册中心“我要下线了”。
注册中心服务接收到cancel请求后:
1. 删除服务信息,将服务信息从registry中删除;
2. 更新队列,将此事件添加到更新队列中,供Eureka Client增量同步服务信息使用。
3. 清空二级缓存,即readWriteCacheMap,用于保证数据的一致性。
4. 更新阈值,供剔除服务使用。
5. 同步服务信息,将此事件同步至其他的Eureka Server节点。
服务剔除机制:
Eureka Server提供了服务剔除的机制,用于剔除没有正常下线的服务。
自我保护机制:
Eureka自我保护机制是为了防止误杀服务而提供的一个机制。
Eureka的自我保护机制“谦虚”的认为如果大量服务都续约失败,则认为是自己出问题了(如自己断网了),也就不剔除了;
反之,则是Eureka Client的问题,需要进行剔除。而自我保护阈值是区分Eureka Client还是Eureka Server出问题的临界值:
如果超出阈值就表示大量服务可用,少量服务不可用,则判定是Eureka Client出了问题。如果未超出阈值就表示大量服务不可用,则判定是Eureka Server出了问题。
剔除服务:
执行剔除服务后:
1. 删除服务信息,从registry中删除服务。
2. 更新队列,将当前剔除事件保存到更新队列中。
3. 清空二级缓存,保证数据的一致性。
服务同步机制:
Eureka Client获取服务有两种方式,全量同步和增量同步。
无论是全量同步还是增量同步,都是先从缓存中获取,如果缓存中没有,则先加载到缓存中,再从缓存中获取。Eureka Server启动后,遍历eurekaClient.getApplications获取服务信息,并将服务信息注册到自己的registry中。
启动时同步:
Eureka Server启动后,遍历eurekaClient.getApplications获取服务信息,并将服务信息注册到自己的registry中。
运行过程中同步:
当Eureka Server节点有register、renew、cancel请求进来时,会将这个请求封装成TaskHolder放到acceptorQueue队列中,然后经过一系列的处理,放到batchWorkQueue中。
TaskExecutor.BatchWorkerRunnable是个线程池,不断的从batchWorkQueue队列中poll出TaskHolder,然后向其他Eureka Server节点发送同步请求。
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号