
【造数】Python批量生成测试数据
工程师开发完成后,常常需要制造大批量的伪数据,来测试数据中台的开发效果。利用Excel来造数,小批量的数据还是可以的,想了解Excel造数的朋友,可以看我之前的文章《造数常用的Excel表达式》,遇到大批量数据时,利用Python来造数会更高效。下面简单介绍一下具体的造数思路。
整体思路
确定有多少字段,样本内容,再给每个字段下填充数据用列表形式保存,在利用DataFrame通过字典的方式创建二维表,最后导出一张csv表格。
整体代码
# -*- coding: utf-8 -*-
import pandas as pd
from faker import Faker
import random
import numpy as np
fake = Faker("zh_CN") # 初始化,可生成中文数据
#设置字段
#index = []
for i in range(1,12):
exec('x'+str(i)+'=[]')
#设置样本
prod_cd = ['W00028','W00021','W00022']
prod_nm = ['微信支付','银联扫码支付','转账']
channel = ['APP','网银','短信']
year = ['2019','2020','2021']
#循环生成数据20行,具体多少行可以根据需求修改
for i in range(20):
date = random.choice(year)+fake.date()[4:]
x1.append('1'+str(fake.random_number(digits=8))) # 随机数字,参数digits设置生成的数字位数
x2.append(fake.name())
x3.append(fake.ssn()) # 身份证
x4.append(random.choice('男女'))
x5.append(random.randint(18,25))
x6.append(fake.job())
x7.append(random.randint(0,1000000))
x8.append(random.choice(prod_cd))
x9.append(random.choice(prod_nm))
x10.append(random.choice(channel))
x11.append(date)
#创建数据表
datas = pd.DataFrame({
'user_id':x1,
'name':x2,
'ID_card':x3,
'gender':x4,
'age':x5,
'job':x6,
'salary':x7,
'product_id':x8,
'product':x9,
'channel':x10,
'prt_dt':x11
})
#DataFrame类的to_csv()方法输出数据内容,不保存行索引和列名
datas.to_csv(r'C:\Users\ASUS2021\Desktop\customer.csv',encoding='utf-8',index=False,header=None)
运行结果

利用Python创建伪数据,主要用到的库是faker库。剩余涉及到的知识点:DataFrame类的to_csv()方法
其中还有比较陌生的几个函数:
exec('x'+str(i)+'=[]')exec函数可以动态运行代码段。fake.random_number(digits=8)生成随机数字,参数digits设置生成的数字位数。
可能会踩的坑
用Excel双击打开csv,乱码
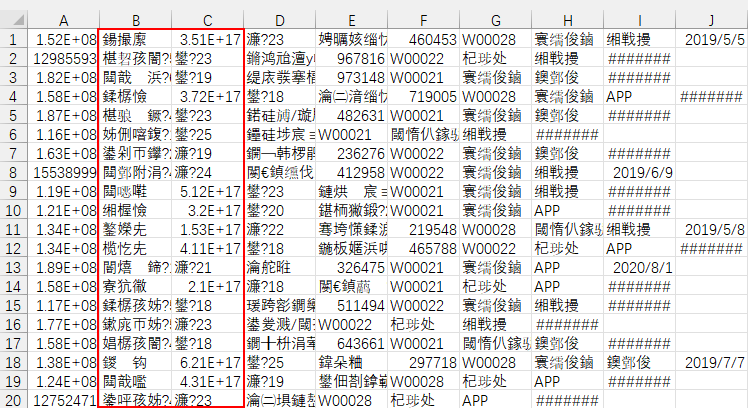
导出的UTF-8的csv文件,直接用Excel打开可能会出现乱码,这里要解释一下,出现乱码是由于excel默认是gb2312编码或其他形式,需要将其转为utf-8编码形式。
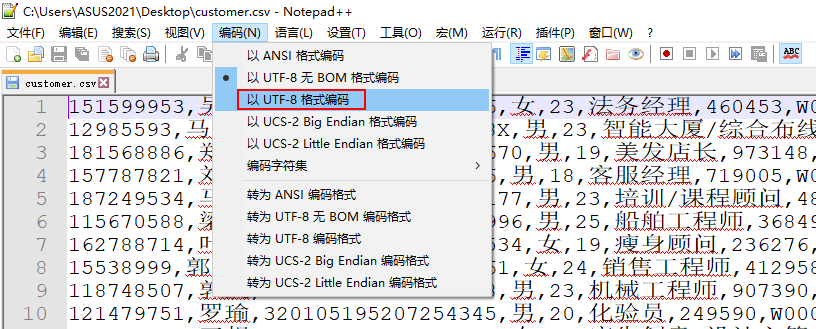
解决办法很简单, 将csv格式文件,用notepad++打开,然后另存为UTF-8格式的csv文件,再用Excel打开,则乱码问题解决。但是调整单元格间距会使分隔符变化,导致下次打开Excel出现问题。解决方法为复制内容到新的Excel中再保存。
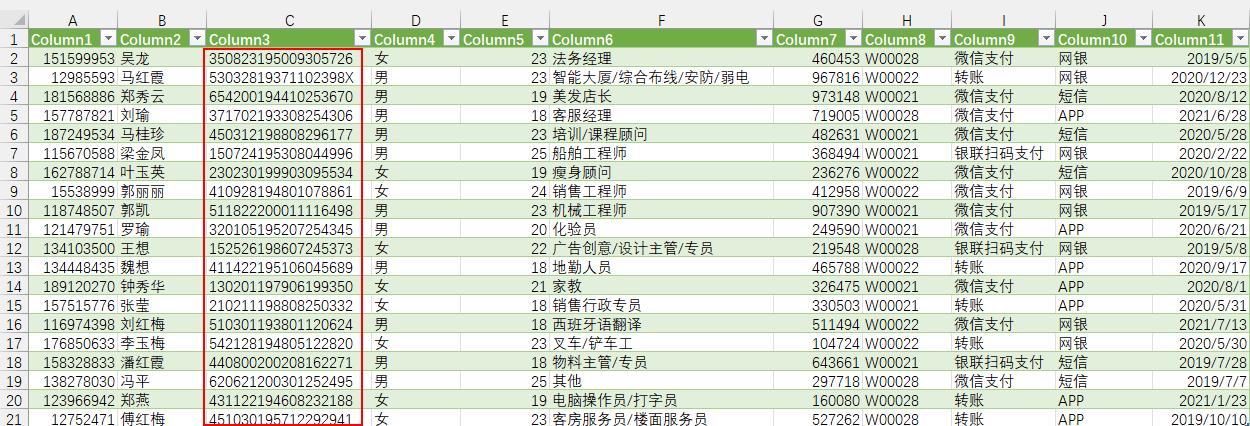
Excel打开csv,身份证号,变科学计数法
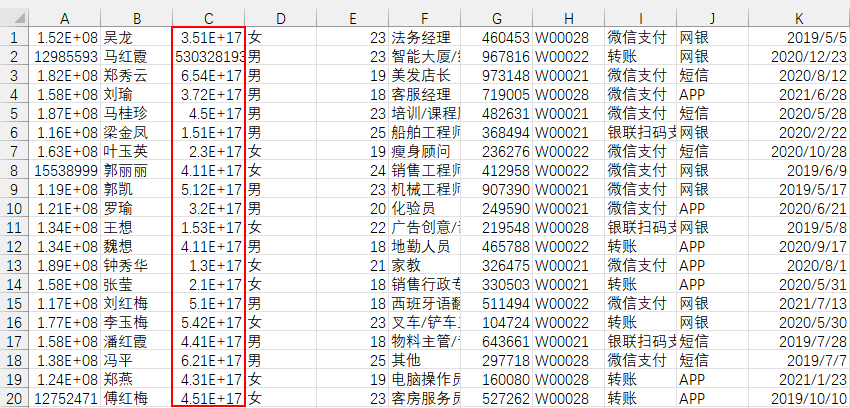
直接双击打开csv文件,身份证号码默认变成科学计数法,而且这一过程是不可逆的,即使你将单元格格式改为文本,身份证号码也不是原来的那串数字了。
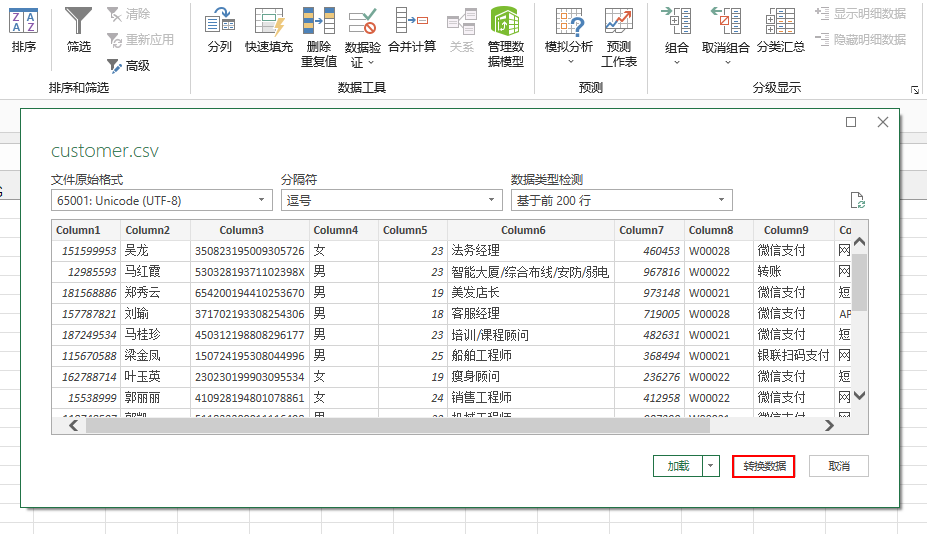
解决办法:
- 新建一个空白Excel文档,【数据】-【从文本/CSV】选择csv文件路径,导入csv文件
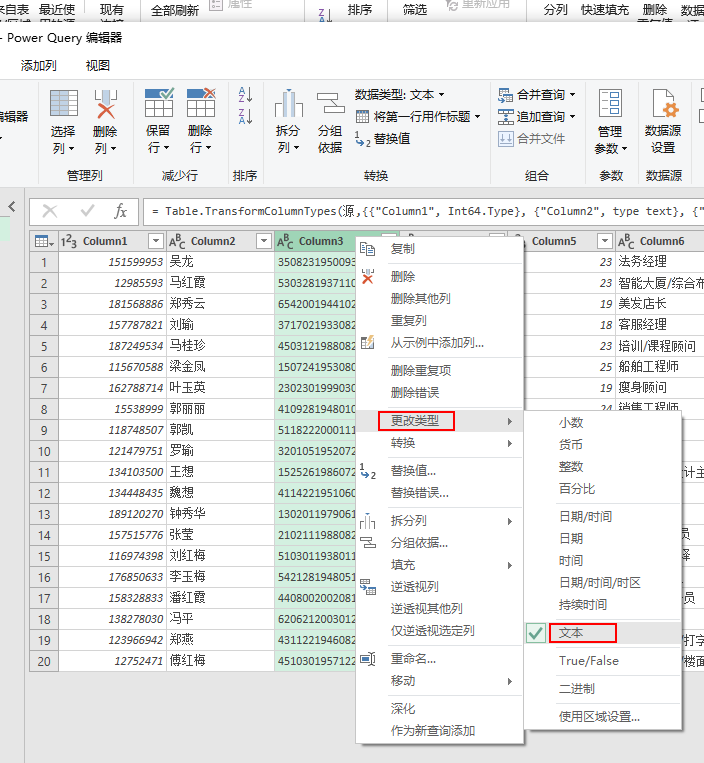
- 单击右下角的【转换数据】,加载进入到Power Query编辑器界面。
- 右键【更改类型】-【文本】
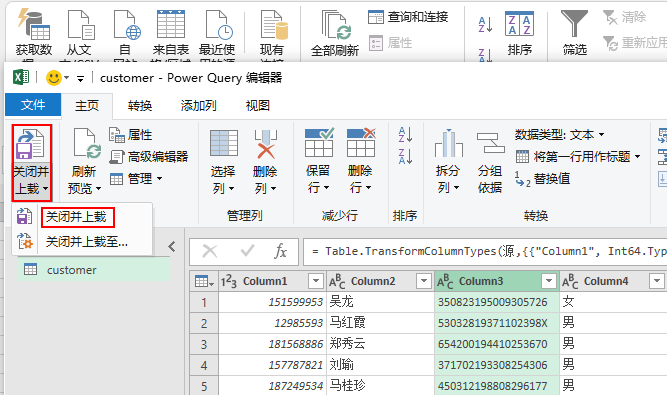
- 最后点击主页上的【关闭并上载】,就可以在Excel看到我们的csv数据了。
补充知识点
常用的几个faker库的方法
随机生成名字,地址,邮编,城市,省份等
from faker import Faker
fake = Faker(locale='zh_CN')
print(fake.address()) # 地址
print(fake.name()) # 名字
print(fake.password(special_chars=False)) # 密码
print(fake.ssn()) # 身份证
print(fake.email()) # 邮箱
print(fake.phone_number()) # 手机号码
print(fake.simple_profile()) # 个人信息
faker库的其他方法
伪装IP地址
ipv4():随机IP4地址
ipv6():随机IP6地址
mac_address():随机MAC地址
tld():网址域名后缀
uri():随机URI地址
uri_extension():网址文件后缀
uri_page():网址文件(不包含后缀)
uri_path():网址文件路径(不包含文件名)
url():随机URL地址
user_name():随机用户名
isbn10():随机ISBN(10位)
isbn13():随机ISBN(13位)
伪造自动评论
paragraph():随机生成一个段落
paragraphs():随机生成多个段落,通过参数nb来控制段落数,返回数组
sentence():随机生成一句话
sentences():随机生成多句话,与段落类似
text():随机生成一篇文章
word():随机生成词语
words():随机生成多个词语,用法与段落,句子,类似
binary():随机生成二进制编码
boolean():True/False
language_code():随机生成两位语言编码
locale():随机生成语言/国际 信息
伪装个人信息
msisdn():移动台国际用户识别码,即移动用户的ISDN号码
phone_number():随机生成手机号
phonenumber_prefix():随机生成手机号段
profile():随机生成档案信息
simple_profile():随机生成简单档案信息
first_name():随机姓
first_name_female():女性名
first_name_male():男性名
first_romanized_name():罗马名
last_name():姓
last_name_female():女
last_name_male():男
last_romanized_name():罗马姓氏
name():随机生成姓名
name_female():男性姓名
name_male():女性姓名
romanized_name():罗马名
msisdn():移动台国际用户识别码,即移动用户的ISDN号码
phone_number():随机生成手机号
phonenumber_prefix():随机生成手机号段
profile():随机生成档案信息
simple_profile():随机生成简单档案信息
email() :随机生成电邮地址
ascii_company_email():随机ASCII公司邮箱名
ascii_email():随机ASCII邮箱
ascii_free_email():随机ASCII免费邮箱
ascii_safe_email():随机ASCII安全邮箱
company_email():随机公司邮箱
domain_name():生成域名
domain_word():域词(即,不包含后缀)
free_email():免费邮箱
free_email_domain():免费邮箱域名
safe_email():安全邮箱
ssn() :生成身份证号
生成浏览器信息
chrome():生成Chrome的浏览器user_agent信息
firefox():生成FireFox的浏览器user_agent信息
internet_explorer():生成IE的浏览器user_agent信息
opera():生成Opera的浏览器user_agent信息
safari():生成Safari的浏览器user_agent信息
linux_platform_token():Linux信息
账户加密伪装
md5():随机生成MD5
null_boolean():NULL/True/False
password():随机生成密码,可选参数:length:密码长度;special_chars:是否能使用特殊字符;digits:是否包含数字;upper_case:是否包含大写字母;lower_case:是否包含小写字母
sha1():随机SHA1
sha256():随机SHA256
地理位置伪装
country():国家
province():省份
city_suffix():市,县
district():区
street_address():街道地址
street_name():街道名
street_suffix():街、路
country_code():国家编码
postcode():邮编
geo_coordinate():地理坐标
longitude():经度
latitude():纬度
am_pm():AM/PM
数字随机
numerify():生成三位随机数
random_digit():生成0~9随机数
random_digit_not_null():生成1~9的随机数
random_element():生成随机字母
random_int():随机数字,默认0~9999,可通过min,max参数修改
random_letter():随机字母
random_number():随机数字,参数digits设置生成的数字位数
颜色随机
color_name():随机颜色名
hex_color():随机HEX颜色
rgb_color():随机RGB颜色
safe_color_name():随机安全色名
safe_hex_color():随机安全HEX颜色
公司信息伪装
bs():随机公司服务名
company():随机公司名(长)
company_prefix():随机公司名(短)
company_suffix():公司性质
credit_card_expire():随机信用卡到期日
credit_card_full():生成完整信用卡信息
credit_card_number():信用卡号
credit_card_provider():信用卡类型
credit_card_security_code():信用卡安全码
currency_code():货币编码
时间
century():随机世纪
date():随机日期
date_between():随机生成指定范围内日期,参数:start_date,end_date
date_between_dates():随机生成指定范围内日期,用法同上
date_object():随机生成从1970-1-1到指定日期的随机日期。
date_this_month():随机生成当前月的某一日
date_this_year():随机生成今年的某一日
date_time():随机生成指定时间(1970年1月1日至今)
date_time_ad():生成公元1年到现在的随机时间
date_time_between():用法同dates
future_date():未来日期
future_datetime():未来时间
month():随机月份
month_name():随机月份(英文)
past_date():随机生成已经过去的日期
past_datetime():随机生成已经过去的时间
time():随机24小时时间
timedelta():随机获取时间差
time_object():随机24小时时间,time对象
time_series():随机TimeSeries对象
timezone():随机时区
unix_time():随机Unix时间
year():随机年份
扩展名伪装
file_extension():随机文件扩展名
file_name():随机文件名(包含扩展名,不包含路径)
file_path():随机文件路径(包含文件名,扩展名)
mime_type():随机mime Type
参考资料:
- exec相关可以看官方文档:https://docs.python.org/3/library/functions.html#exec
- 使用faker库生成随机数据:https://blog.csdn.net/adorable_/article/details/111997189
- Excel打开csv后身份证号码处理:https://zhuanlan.zhihu.com/p/388582211

 浙公网安备 33010602011771号
浙公网安备 33010602011771号